


Est-ce à cela que ressemblera l'avenir de la communication entre les gens ?
Récemment, un projet de synthèse vocale appelé ChatTTS est devenu populaire, attirant une grande attention de la part de tous. En seulement trois jours, il a gagné 9,2 000 étoiles sur GitHub.
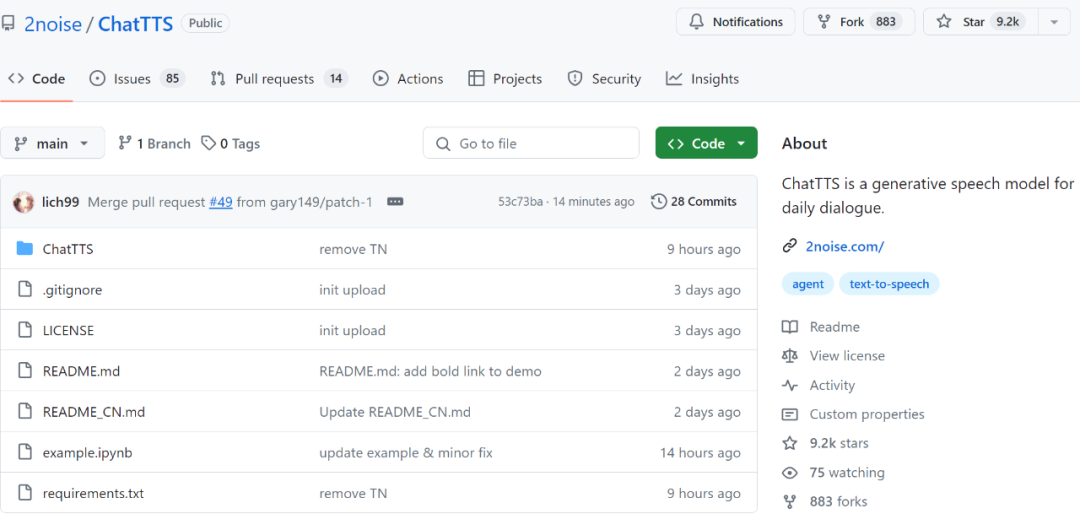
Adresse du projet : https://github.com/2noise/ChatTTS/tree/main
L'auteur lui-même a également déclaré sur x que ChatTTS avait franchi le plafond de l'open source. Cependant, ce qui est actuellement open source n’est que le modèle de base, qui n’a pas été supervisé et affiné par SFT.
Ce projet convertit le texte en parole. L'effet est le suivant :  ChatTTS peut non seulement parler chinois, mais aussi anglais. Il prend également en charge un contrôle précis, ce qui vous permet d'ajouter des rires et des rires pendant. parlant, ainsi que les particules modales, sont très jouables.
ChatTTS peut non seulement parler chinois, mais aussi anglais. Il prend également en charge un contrôle précis, ce qui vous permet d'ajouter des rires et des rires pendant. parlant, ainsi que les particules modales, sont très jouables.  Il peut reproduire les voix épuisées de personnes décédées. Si vous souhaitez réentendre la conférence sur le développement de Steve Jobs, vous pouvez le faire à tout moment. En l'écoutant en imitant le timbre de Swift, que ce soit l'intonation ou le changement de ton, c'est très proche de la personne, et il n'y a presque aucune saveur d'IA.
Il peut reproduire les voix épuisées de personnes décédées. Si vous souhaitez réentendre la conférence sur le développement de Steve Jobs, vous pouvez le faire à tout moment. En l'écoutant en imitant le timbre de Swift, que ce soit l'intonation ou le changement de ton, c'est très proche de la personne, et il n'y a presque aucune saveur d'IA.  Vous pouvez également bien parler chinois et anglais. Avec cet accent mi-anglais et mi-chinois, vous êtes assez courageux pour entrer dans le cercle. Les capacités linguistiques de ChatTTS ont atteint le niveau supérieur.站 L'audio ci-dessus provient de la station B : https://www.bilibili.com/video/bv1zn4y1o7iv/?share_source=copy_web&vd_source=983EC32A3036999E4FDBCE3C28
Vous pouvez également bien parler chinois et anglais. Avec cet accent mi-anglais et mi-chinois, vous êtes assez courageux pour entrer dans le cercle. Les capacités linguistiques de ChatTTS ont atteint le niveau supérieur.站 L'audio ci-dessus provient de la station B : https://www.bilibili.com/video/bv1zn4y1o7iv/?share_source=copy_web&vd_source=983EC32A3036999E4FDBCE3C28 Décrit la description ci-dessus. Pendant l'affichage, nous pouvons voir que Chattts peut atteindre une fluidité naturelle de la parole. la synthèse prend en charge plusieurs locuteurs en même temps ; elle peut également prédire et contrôler des caractéristiques prosodiques fines, notamment les rires, les pauses et les mots insérés ; ChatTTS surpasse la plupart des modèles TTS open source en termes de prosodie.
Décrit la description ci-dessus. Pendant l'affichage, nous pouvons voir que Chattts peut atteindre une fluidité naturelle de la parole. la synthèse prend en charge plusieurs locuteurs en même temps ; elle peut également prédire et contrôler des caractéristiques prosodiques fines, notamment les rires, les pauses et les mots insérés ; ChatTTS surpasse la plupart des modèles TTS open source en termes de prosodie.
 Certaines personnes utilisent GPT pour générer du texte et laissent ChatTTS le "lire". La différence entre le ton et l'intonation de vraies personnes est très petite :
Certaines personnes utilisent GPT pour générer du texte et laissent ChatTTS le "lire". La différence entre le ton et l'intonation de vraies personnes est très petite : 
 L'effet est tellement bon. , naturellement je veux l'essayer. Comment utiliser ChatTTS comme substitut buccal ? Vous pouvez vous référer aux méthodes suivantes pour fonctionner.
L'effet est tellement bon. , naturellement je veux l'essayer. Comment utiliser ChatTTS comme substitut buccal ? Vous pouvez vous référer aux méthodes suivantes pour fonctionner.  Adresse de l'expérience en ligne : https://huggingface.co/spaces/Dzkaka/ChatTTS
Adresse de l'expérience en ligne : https://huggingface.co/spaces/Dzkaka/ChatTTS
ChatTTS a principalement deux fonctions principales, la première est la synthèse vocale et la seconde est le dialogue vocal en temps réel avec un grand modèle de langage. En plus de ces fonctions, vous pouvez ajuster le timbre du haut-parleur spécifié numériquement dans « Audio Seed », ou lancer les dés pour en générer un de manière aléatoire. Cependant, de nombreux testeurs ont déclaré que si les mêmes paramètres sont utilisés à chaque fois, la tonalité générée n'est pas nécessairement fixe.

2Noise a déclaré qu'il prend actuellement en charge le clonage du son, mais qu'il nécessite une plus grande quantité de données.
Après avoir saisi du texte dans la zone de texte, ChatTTS générera automatiquement des rimes et des pauses pour vous, et ajoutera également des particules modales telles que "puis". Si vous ajoutez [rire] et [uv_break] au texte lors de la saisie, vous pouvez contrôler manuellement ChatTTS pour produire du « rire » lorsque vous parlez. 
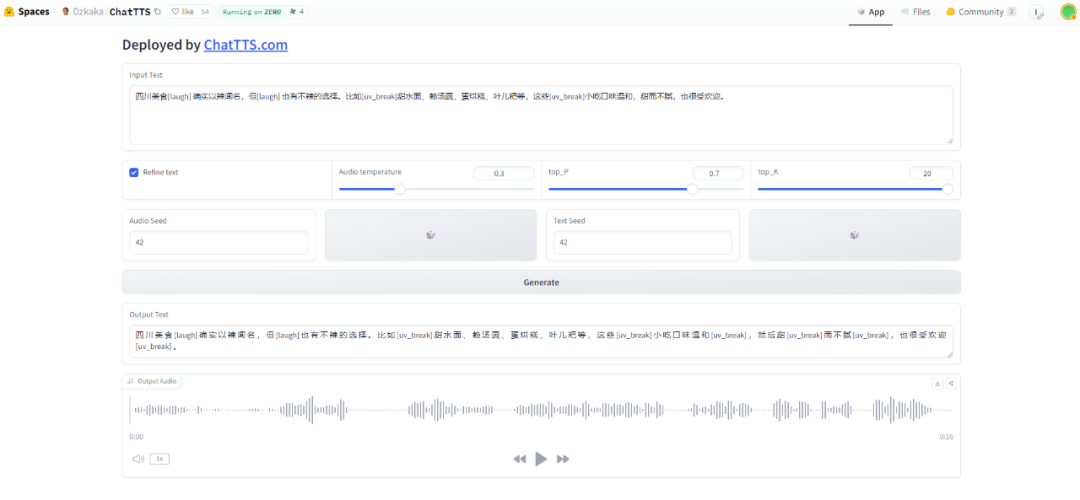
Cependant, ChatTTS ne peut pas encore gérer des textes relativement longs. Certains internautes lui ont demandé de contester les livres audio et ont constaté que la version initiale ne pouvait pas générer d'audio de plus de 30 secondes et devait être réparée manuellement. Lorsque vous rencontrez un texte relativement long, la segmentation des mots de ChatTTS posera également des problèmes.


Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment désactiver la protection en temps réel dans le Centre de sécurité Windows
Comment désactiver la protection en temps réel dans le Centre de sécurité Windows
 Comment modifier le texte sur l'image
Comment modifier le texte sur l'image
 Quelle est la différence entre WeChat et WeChat ?
Quelle est la différence entre WeChat et WeChat ?
 Comment résoudre l'erreur d'analyse
Comment résoudre l'erreur d'analyse
 Comment télécharger le panneau de configuration nvidia
Comment télécharger le panneau de configuration nvidia
 Avantages du système de contrôle PLC
Avantages du système de contrôle PLC
 Connecté mais impossible d'accéder à Internet
Connecté mais impossible d'accéder à Internet
 tutoriel ajax
tutoriel ajax








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



