Dans le domaine de l'IA, les lois de mise à l'échelle sont un outil puissant pour comprendre les tendances de mise à l'échelle du LM. Elles fournissent une ligne directrice aux chercheurs. Cette loi constitue un guide important pour comprendre comment les performances des modèles de langage changent avec l'échelle. Mais malheureusement, l'analyse de mise à l'échelle n'est pas courante dans de nombreuses études comparatives et post-formation car la plupart des chercheurs ne disposent pas des ressources informatiques nécessaires pour créer des lois de mise à l'échelle à partir de zéro, et les échelles de formation des modèles ouverts sont trop peu nombreuses pour les rendre fiables. prévisions d’expansion. Des chercheurs de l'Université Stanford, de l'Université de Toronto et d'autres institutions ont proposé une méthode d'observation alternative : les lois d'échelle observationnelles, qui combinent les fonctions des modèles de langage (LM) avec les performances en aval de plusieurs familles de modèles, plutôt que simplement au sein d'un série unique comme c'est le cas avec les lois d'expansion informatiques standard. Cette méthode contourne la formation des modèles et construit à la place des lois de mise à l'échelle basées sur environ 80 modèles accessibles au public. Mais cela conduit à un autre problème. La construction d’une loi d’expansion unique à partir de plusieurs familles de modèles est confrontée à d’énormes défis en raison des grandes différences d’efficacité et de capacités de calcul entre les différents modèles. Néanmoins, l'étude montre que ces changements sont cohérents avec une loi d'échelle simple et généralisée dans laquelle les performances du modèle de langage sont fonction d'un espace de capacités de faible dimension, et l'ensemble de la famille de modèles ne diffère que par l'efficacité de la conversion de la formation. calculs en capacités. En utilisant la méthode ci-dessus, cette étude démontre l'étonnante prévisibilité de nombreux autres types d'études d'extension, ils ont découvert que : certains phénomènes émergents suivent un comportement sigmoïdal fluide et peuvent être prédits à partir de petits modèles comme GPT-4 ; de peuvent être prédits avec précision à partir de références non-agents plus simples. De plus, l'étude montre comment prédire l'impact des interventions post-formation telles que les chaînes de pensée sur le modèle. La recherche montre que même lorsqu'elles sont ajustées à l'aide d'un petit modèle sous-GPT-3, les lois d'expansion observables prédisent avec précision des phénomènes complexes tels que la capacité émergente, la performance des agents et l'expansion des méthodes post-formation telles que la chaîne de réflexion). Il y a trois auteurs de le journal, parmi lequel Yangjun Ruan est un auteur chinois. Il est diplômé de l'Université du Zhejiang avec un baccalauréat. Cet article a également reçu un commentaire transmis de Jason Wei, le proposant de la chaîne de réflexion. Jason Wei a déclaré qu'il aimait beaucoup cette recherche.
L'étude a observé qu'il existe actuellement des centaines de modèles ouverts, avec différentes échelles et capacités. Cependant, les chercheurs ne peuvent pas utiliser directement ces modèles pour calculer les lois d'expansion (car l'efficacité informatique de la formation varie considérablement entre les familles de modèles), mais les chercheurs espèrent qu'il existe une loi d'expansion plus générale qui s'applique aux familles de modèles.
En particulier, cet article suppose que les performances en aval des LM sont fonction de l'espace des capacités de faible dimension (comme la compréhension du langage naturel, le raisonnement et la génération de code), et que les familles de modèles ne varient que par leur efficacité. dans la conversion des calculs de formation en ces capacités. Si cette relation est vraie, cela signifierait qu'il existe une relation log-linéaire entre les capacités de faible dimension et les capacités en aval dans les familles de modèles (ce qui permettrait aux chercheurs d'établir des lois d'échelle à l'aide des modèles existants) (Figure 1). Cette étude a obtenu des prédictions d'extension à faible coût et haute résolution en utilisant près de 80 LM accessibles au public (à droite).

En analysant les références LM standard (par exemple, Open LLM Leaderboard), les chercheurs ont découvert certaines de ces mesures de capacité, qui ont une relation de loi d'expansion avec la quantité de calcul au sein de la famille de modèles (R ^ 2 > 0,9) (voir Figure 3 ci-dessous), et cette relation existe également entre différentes familles de modèles et indicateurs en aval. Cet article appelle cette relation d’expansion la loi d’expansion observable.
Enfin, cette étude montre que l'utilisation de lois d'expansion observables est simple et peu coûteuse, car il existe quelques séries de modèles suffisants pour reproduire bon nombre des principales conclusions de l'étude. En utilisant cette approche, l'étude a révélé que la mise à l'échelle des prévisions pour les interventions de base et post-formation peut être facilement réalisée en évaluant seulement 10 à 20 modèles. Il y a eu un débat houleux sur la question de savoir si LM possède des capacités « émergentes » qui se produisent de manière discontinue à certains seuils de calcul, et si ces capacités peuvent être prédites à l'aide de petits modèles. Les lois d'expansion observables suggèrent que certains de ces phénomènes suivent des courbes lisses en forme de S et peuvent être prédits avec précision à l'aide de petits modèles sous Llama-2 7B. "Capacités de l'agent" Grâce à des lois d'échelle observables, l'étude prédit avec précision les performances de GPT-4 en utilisant uniquement un modèle plus faible (sous GPT-3.5) et identifie la capacité de programmation comme un facteur déterminant les performances de l'agent.
Il y a eu un débat houleux sur la question de savoir si LM possède des capacités « émergentes » qui se produisent de manière discontinue à certains seuils de calcul, et si ces capacités peuvent être prédites à l'aide de petits modèles. Les lois d'expansion observables suggèrent que certains de ces phénomènes suivent des courbes lisses en forme de S et peuvent être prédits avec précision à l'aide de petits modèles sous Llama-2 7B. "Capacités de l'agent" Grâce à des lois d'échelle observables, l'étude prédit avec précision les performances de GPT-4 en utilisant uniquement un modèle plus faible (sous GPT-3.5) et identifie la capacité de programmation comme un facteur déterminant les performances de l'agent. 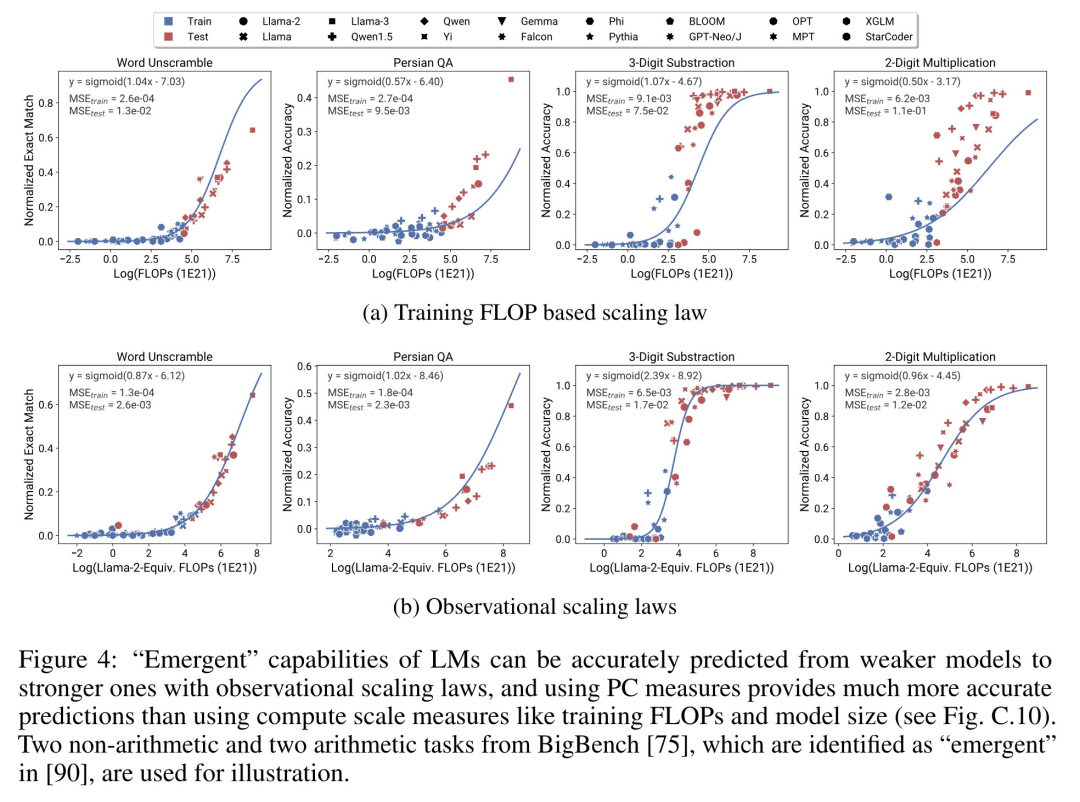 Expansion des méthodes post-entraînement Cette étude montre que la loi d'expansion peut prédire de manière fiable les méthodes post-entraînement même lorsqu'elle est adaptée à un modèle plus faible (sous Llama-2 7B) Avantages, tels que la chaîne -de-pensée, auto-cohérence, etc.
Expansion des méthodes post-entraînement Cette étude montre que la loi d'expansion peut prédire de manière fiable les méthodes post-entraînement même lorsqu'elle est adaptée à un modèle plus faible (sous Llama-2 7B) Avantages, tels que la chaîne -de-pensée, auto-cohérence, etc.
Dans l'ensemble, la contribution de cette étude est de proposer une loi d'échelle observable qui exploite des relations log-linéaires prévisibles entre les calculs, les mesures de capabilité simples et les indicateurs complexes en aval.
Vérification des lois d'expansion observables
Les chercheurs ont vérifié l'utilité de ces lois d'expansion à travers des expériences. En outre, après la publication de l'article, les chercheurs ont également pré-enregistré des prédictions pour les futurs modèles afin de vérifier si la loi d'expansion surajustait le modèle actuel. Le code pertinent concernant le processus de mise en œuvre et la collecte de données a été publié sur GitHub :
Adresse GitHub : https://github.com/ryoungj/ObsScaling
Prévisibilité des capacités émergentes
La figure 4 ci-dessous montre les résultats de prédiction utilisant la mesure PC (capacité principale) et les résultats de base des performances de prédiction basées sur les FLOP d'entraînement. On peut constater que ces capacités peuvent être prédites avec précision à l’aide de notre métrique PC, même en utilisant uniquement un modèle peu performant.
En revanche, l'utilisation de FLOP d'entraînement entraîne une extrapolation nettement moins bonne sur l'ensemble de test et un ajustement nettement moins bon sur l'ensemble d'entraînement, comme le montrent les valeurs MSE plus élevées. Ces différences peuvent être causées par la formation des FLOP pour différentes familles de modèles.
Prévisibilité des capacités des agents
La figure 5 ci-dessous montre les résultats de prédiction de la loi d'expansion observable à l'aide de la métrique PC. On peut constater que sur les deux benchmarks d'agents, les performances du modèle hold-out (GPT-4 ou Claude-2) utilisant la métrique PC peuvent être prédites avec précision à partir du modèle avec des performances plus faibles (écart de plus de 10 %).
Cela montre que les capacités d'agent plus complexes des LM sont étroitement liées à leurs capacités de modèle sous-jacentes et sont capables de faire des prédictions basées sur ces dernières. Cela illustre également qu'à mesure que les LM de base continuent de croître en termes d'échelle, les capacités des agents basés sur LM présentent de bonnes caractéristiques d'évolutivité. 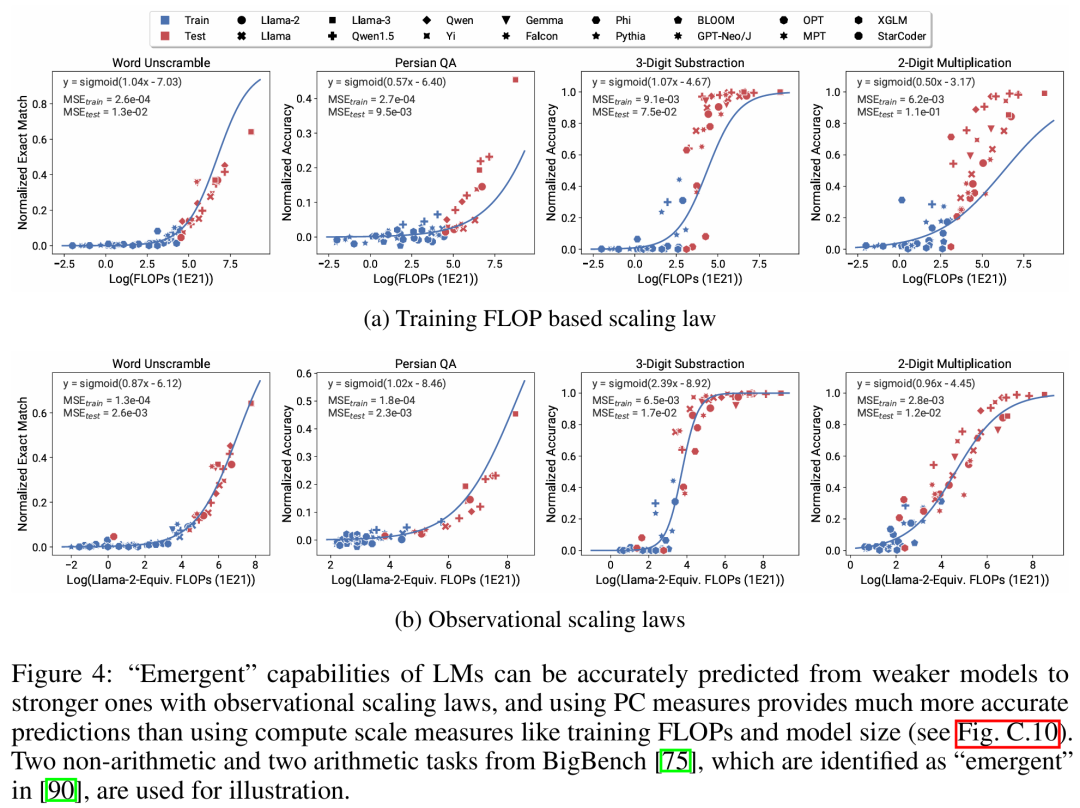
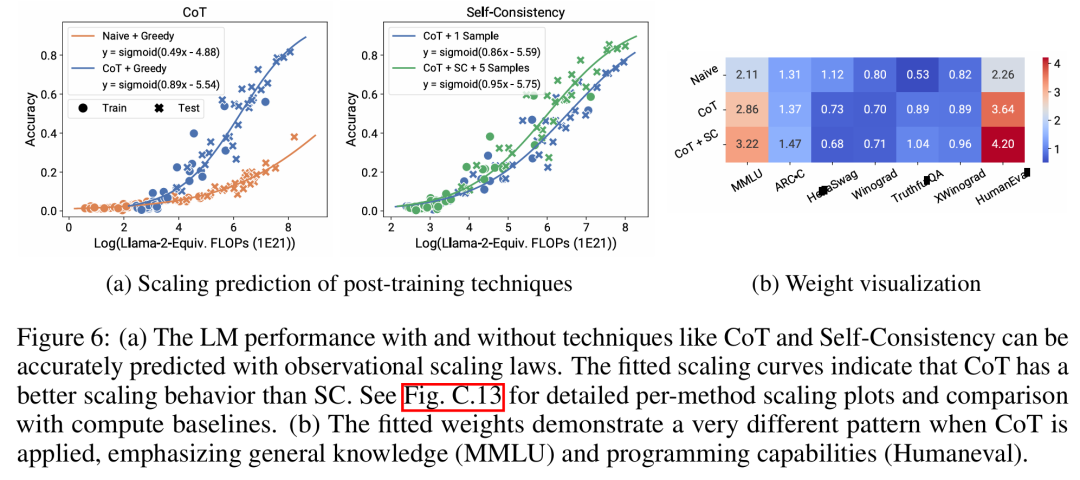
Impact des techniques post-formation
La figure 6a ci-dessous montre les résultats de prédiction d'expansion de CoT et SC (auto-cohérence, auto-cohérence) à l'aide de lois d'expansion observables. On peut constater que les performances de modèles plus forts et plus grands utilisant CoT et CoT+SC sans techniques de post-formation (naïves) peuvent être prédites avec précision à partir des modèles les plus faibles avec une échelle de calcul plus petite (telle que la taille du modèle et les FLOP d'entraînement).
Il convient de noter que les tendances de mise à l'échelle sont différentes entre les deux technologies, CoT montrant une tendance de mise à l'échelle plus évidente par rapport à l'utilisation de l'auto-cohérence de CoT.Veuillez vous référer au document original pour plus de détails techniques. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!




 Introduction aux caractéristiques de l'espace virtuel
Introduction aux caractéristiques de l'espace virtuel
 Utilisation de la valeur de retour Python
Utilisation de la valeur de retour Python
 Comment utiliser la monnaie numérique
Comment utiliser la monnaie numérique
 Que dois-je faire si des lettres anglaises apparaissent lorsque l'ordinateur est allumé et que l'ordinateur ne peut pas être allumé ?
Que dois-je faire si des lettres anglaises apparaissent lorsque l'ordinateur est allumé et que l'ordinateur ne peut pas être allumé ?
 La différence entre vue2.0 et 3.0
La différence entre vue2.0 et 3.0
 Comment changer de ville sur Douyin
Comment changer de ville sur Douyin
 pas de solution de fichier de ce type
pas de solution de fichier de ce type
 Comment configurer la passerelle par défaut
Comment configurer la passerelle par défaut








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



