


Titre de l'article :
DiffMap : Enhancing Map Segmentation with Map Prior Using Diffusion Model
Auteur de l'article :
Peijin Jia, Tuopu Wen, Ziang Luo, Mengmeng Yang, Kun Jiang, Zhiquan Lei, Xuewei Tang, Ziyuan Liu, Le Cui, Kehua Sheng, Bo Zhang, Diange Yang
Pour les véhicules autonomes, les cartes haute définition (HD) peuvent les aider à améliorer leur compréhension de l'environnement (perception) ) exactitude et précision de navigation. Cependant, la cartographie manuelle se heurte à des problèmes de complexité et de coût élevé. À cette fin, la recherche actuelle intègre la construction de cartes dans la tâche de perception BEV (bird's eye view). La construction d'une carte HD rastérisée dans l'espace BEV est considérée comme une tâche de segmentation, qui peut être comprise comme l'ajout de quelque chose de similaire au FCN. (plein volume) après obtention des fonctionnalités BEV (responsable de segmentation du réseau produit). Par exemple, HDMapNet encode les caractéristiques des capteurs via LSS (Lift, Splat, Shoot), puis utilise FCN multi-résolution pour la segmentation sémantique, la détection d'instances et la prédiction de direction afin de créer une carte.
Cependant, actuellement, ces méthodes (méthodes de classification basées sur les pixels) ont encore des limites inhérentes, notamment la possibilité d'ignorer certains attributs de classification, ce qui peut entraîner une distorsion et une interruption des terre-pleins, des passages pour piétons flous et d'autres types d'artefacts et bruit, comme le montre la figure 1 (a). Ces problèmes affectent non seulement la précision structurelle de la carte, mais peuvent également affecter directement le module de planification de trajet en aval du système de conduite autonome.
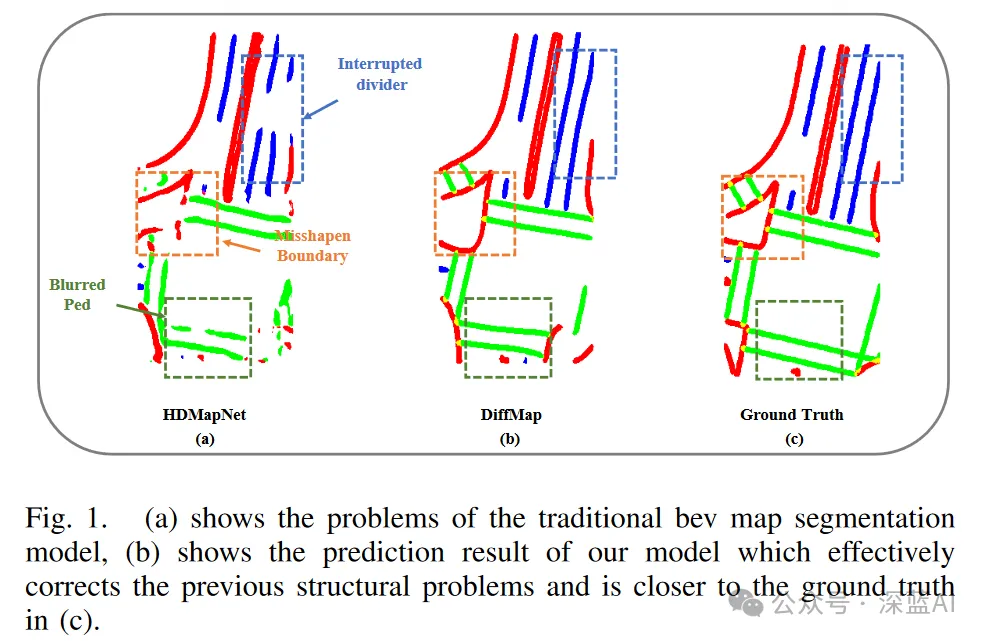
▲ Figure 1|Comparaison des effets de HDMapNet, DiffMap et GroundTruth
Par conséquent, il est préférable que le modèle prenne en compte les informations structurelles préalables de la carte HD, telles que les lignes parallèles et droites. caractéristiques des lignes de voies. Certains modèles génératifs ont cette capacité à capturer l’authenticité et les caractéristiques inhérentes des images. Par exemple, le LDM (Latent Diffusion Model) a montré un grand potentiel dans la génération d’images haute fidélité et a prouvé son efficacité dans les tâches liées à l’amélioration de la segmentation. De plus, des variables de contrôle peuvent être introduites pour guider davantage la génération d’images afin de répondre à des exigences de contrôle spécifiques. Par conséquent, l’application de modèles génératifs pour capturer les a priori de la structure de la carte devrait réduire les artefacts de segmentation et améliorer les performances de construction de la carte.
Dans cet article, l'auteur a mentionné le réseau DiffMap. Pour la première fois, ce réseau effectue une modélisation préalable structurée par carte sur les modèles de segmentation existants et prend en charge le plug-and-play en utilisant le LDM amélioré comme module d'amélioration. DiffMap apprend non seulement la carte au préalable grâce au processus d'ajout et de suppression de bruit pour garantir que la sortie correspond à l'observation de la trame actuelle, mais il peut également intégrer des fonctionnalités BEV en tant que signal de contrôle pour garantir que la sortie correspond à l'observation de la trame actuelle. Les résultats expérimentaux montrent que DiffMap peut générer efficacement des résultats de segmentation de carte plus fluides et plus raisonnables, tout en réduisant considérablement les artefacts et en améliorant les performances globales de construction de cartes.
2.1 Construction de cartes sémantiques
Dans la construction traditionnelle de cartes haute définition (HD), les cartes sémantiques sont généralement annotées manuellement ou semi-automatiquement sur la base de nuages de points lidar. Généralement, une carte globalement cohérente est construite sur la base de l'algorithme SLAM et des annotations sémantiques sont ajoutées manuellement à la carte. Cependant, cette approche prend du temps et demande beaucoup de travail et présente également des défis importants en matière de mise à jour de la carte, limitant ainsi son évolutivité et ses performances en temps réel.
HDMapNet propose une méthode pour construire dynamiquement des cartes sémantiques locales à l'aide de capteurs embarqués. Il encode les caractéristiques du nuage de points lidar et des images panoramiques dans l'espace Bird's Eye View (BEV) et les décode à l'aide de trois têtes différentes, produisant finalement une carte sémantique locale vectorisée. SuperFusion se concentre sur la création de cartes sémantiques de haute précision à longue portée, en utilisant les informations de profondeur lidar pour améliorer l'estimation de la profondeur de l'image et en utilisant les caractéristiques de l'image pour guider la prédiction des caractéristiques lidar à longue portée. Ensuite, une tête de détection de carte similaire à HDMapNet est utilisée pour obtenir la carte sémantique. MachMap divise la tâche en détection de polylignes et segmentation d'instances de polygones, et utilise le post-traitement pour affiner le masque afin d'obtenir le résultat final. Les recherches ultérieures se concentrent sur la cartographie en ligne de bout en bout pour obtenir directement des cartes vectorielles haute définition. La construction dynamique de cartes sémantiques sans annotation manuelle réduit efficacement les coûts de construction.
2.2 Modèle de diffusion appliqué à la segmentation et à la détection
Les modèles probabilistes de diffusion de débruitage (DDPM) sont un type de modèle génératif basé sur des chaînes de Markov, qui montrent d'excellentes performances dans des domaines tels que la génération d'images, et progressivement étendu à diverses tâches telles que la segmentation et la détection. SegDiff applique le modèle de diffusion à la tâche de segmentation d'image, où l'encodeur UNet utilisé est en outre découplé en trois modules : E, F et G. Les modules G et F codent respectivement l'image d'entrée I et la carte de segmentation, qui sont ensuite fusionnées de manière additive dans E pour affiner de manière itérative la carte de segmentation. DDPMS utilise un modèle de segmentation de base pour générer un a priori de prédiction initial et un modèle de diffusion pour affiner l'a priori. DiffusionDet étend le modèle de diffusion au cadre de détection de cible, modélisant la détection de cible comme un processus de diffusion débruitant de la boîte de bruit à la boîte cible.
Les modèles de diffusion sont également utilisés dans le domaine de la conduite autonome, comme MagicDrive utilisant des contraintes géométriques pour synthétiser des scènes de rue, et Motiondiffuser étendant le modèle de diffusion à des problèmes de prédiction de mouvement multi-agents.
2.3 Carte préalable
Il existe actuellement plusieurs méthodes pour améliorer la robustesse du modèle et réduire la charge des capteurs du véhicule en utilisant des informations préalables (y compris des informations cartographiques standard explicites et des informations temporelles implicites) Incertitude. MapLite2.0 prend la carte préalable en définition standard (SD) comme point de départ et la combine avec des capteurs embarqués pour déduire des cartes locales haute définition en temps réel. MapEx et SMERF exploitent les données cartographiques standard pour améliorer la connaissance des voies et la compréhension topologique. SMERF adopte un encodeur de carte standard basé sur Transformer pour encoder les lignes et les types de voies, puis calcule l'attention croisée entre les informations cartographiques standard et les fonctionnalités de vue à vol d'oiseau (BEV) basées sur un capteur pour intégrer les informations cartographiques standard. NMP offre des capacités de mémoire à long terme pour les véhicules autonomes en combinant les données cartographiques antérieures avec les données de perception actuelles. MapPrior combine des modèles discriminatifs et génératifs, codant les prédictions préliminaires générées sur la base de modèles existants comme a priori pendant la phase de prédiction, injectant l'espace latent discret du modèle génératif, puis utilisant le modèle génératif pour affiner les prédictions. PreSight utilise les données de voyages précédents pour optimiser le champ de rayonnement neuronal à l'échelle de la ville, générer des priorités neuronales et améliorer la perception en ligne lors de la navigation ultérieure.
3.1 Préparation


3.2 Architecture globale
Comme le montre la figure 2. En tant que décodeur, DiffMap intègre le modèle de diffusion dans le modèle de segmentation de carte sémantique, qui prend en entrée les images multi-vues environnantes et les nuages de points LiDAR, les code dans l'espace BEV et obtient les caractéristiques BEV fusionnées. Ensuite, DiffMap est utilisé comme décodeur pour générer des cartes de segmentation. Dans le module DiffMap, les fonctionnalités BEV sont utilisées comme conditions pour guider le processus de débruitage.
 ▲ Figure 2|Architecture DiffMap ©️[Deep Blue AI] compilée
▲ Figure 2|Architecture DiffMap ©️[Deep Blue AI] compilée
◆Base de référence pour la construction de cartes sémantiques : La base de référence suit principalement le paradigme de l'encodeur-décodeur BEV. La partie encodeur est chargée d’extraire les caractéristiques des données d’entrée (données LiDAR et/ou caméra) et de les convertir en une représentation haute dimension. Dans le même temps, le décodeur agit généralement comme une tête de segmentation pour mapper les représentations de caractéristiques de grande dimension aux cartes de segmentation correspondantes. Baseline joue deux rôles principaux dans le cadre global : superviseur et contrôleur. En tant que superviseur, la référence génère des résultats de segmentation en tant que supervision auxiliaire. Dans le même temps, en tant que contrôleur, il fournit des caractéristiques BEV intermédiaires comme variables de contrôle conditionnelles pour guider le processus de génération du modèle de diffusion.
◆Module DiffMap : Après LDM, l'auteur introduit le module DiffMap comme décodeur dans le framework de base. LDM se compose principalement de deux parties : un module de compression sensible aux images (tel que VQVAE) et un modèle de diffusion construit à l'aide de UNet. Tout d’abord, l’encodeur code la vérité terrain de segmentation cartographique dans l’espace latent, où représente la faible dimension de l’espace latent. Ensuite, la diffusion et le débruitage sont effectués dans un espace variable latent de faible dimension, et un décodeur est utilisé pour restaurer l'espace latent dans l'espace de pixels d'origine.
Ajoutez d'abord du bruit via un processus de diffusion et obtenez une carte de potentiel de bruit à chaque pas de temps, où . Ensuite, pendant le processus de débruitage, UNet sert de réseau fédérateur pour la prédiction du bruit. Afin d'améliorer la partie supervision des résultats de segmentation, il est prévu que le modèle DiffMap fournisse directement des fonctionnalités sémantiques pour les prédictions liées aux instances lors de la formation. Par conséquent, l'auteur divise la structure du réseau UNet en deux branches, une branche est utilisée pour prédire le bruit, comme le modèle de diffusion traditionnel, et l'autre branche est utilisée pour prédire le bruit dans l'espace latent.
Comme le montre la figure 3. Après avoir obtenu la prédiction de carte latente, elle est décodée dans l’espace de pixels d’origine sous forme de carte de caractéristiques sémantiques. Ensuite, les prédictions d'instance peuvent en être obtenues selon la méthode proposée par HDMapNet, et les prédictions de trois têtes différentes peuvent être générées : segmentation sémantique, intégration d'instance et direction de voie. Ces prédictions sont ensuite utilisées dans une étape de post-traitement pour vectoriser la carte.

▲Figure 3|Module de débruitage
L'ensemble du processus est un processus de génération conditionnelle et les résultats de segmentation de la carte sont obtenus en fonction de l'entrée actuelle du capteur. La distribution de probabilité du résultat peut être modélisée comme suit : où représente le résultat de la segmentation de la carte et représente la variable de contrôle conditionnelle, c'est-à-dire la fonctionnalité BEV. L'auteur utilise ici deux méthodes pour intégrer les variables de contrôle. Premièrement, étant donné que les caractéristiques BEV et BEV ont la même catégorie et la même échelle dans le domaine spatial, elles seront ajustées à la taille de l'espace latent, puis elles seront concaténées en tant qu'entrée du processus de débruitage, comme le montre l'équation 5.
Deuxièmement, le mécanisme d'attention croisée est intégré dans chaque couche du réseau UNet, en tant que clé/valeur et requête. La formule du module d'attention croisée est la suivante :
3.3 Mise en œuvre spécifique
◆Formation :

◆Inférence :

4.1 Détails expérimentaux
◆ Ensemble de données : Validez DiffMap sur l'ensemble de données nuScenes. L'ensemble de données nuScenes contient des images multi-vues et des nuages de points de 1 000 scènes, dont 700 scènes sont utilisées pour la formation, 150 pour la validation et 150 pour les tests. L'ensemble de données nuScenes contient également des étiquettes sémantiques de carte HD annotées.
◆Architecture : Utilisez ResNet-101 comme réseau fédérateur de la branche caméra et utilisez PointPillars comme réseau fédérateur de branche LiDAR du modèle. La tête de segmentation dans le modèle de base est un réseau FCN basé sur ResNet-18. Pour l'encodeur automatique, VQVAE est utilisé et le modèle est pré-entraîné sur l'ensemble de données cartographiques segmentées nuScenes pour extraire les caractéristiques de la carte et compresser la carte dans un espace latent de base. Enfin, UNet est utilisé pour construire le réseau de diffusion.
◆Détails de la formation : Utilisez l'optimiseur AdamW pour entraîner le modèle VQVAE pendant 30 époques. Le planificateur de taux d'apprentissage utilisé est LambdaLR, qui réduit progressivement le taux d'apprentissage dans un mode de décroissance exponentielle avec un facteur de décroissance de 0,95. Le taux d'apprentissage initial est défini sur et la taille du lot est de 8. Ensuite, le modèle de diffusion a été formé à partir de zéro à l'aide de l'optimiseur AdamW pendant 30 époques avec un taux d'apprentissage initial de 2e-4. Le planificateur MultiStepLR est adopté, qui ajuste le taux d'apprentissage en fonction de points temporels spécifiés (0,7, 0,9, 1,0) et d'un facteur d'échelle de 1/3 à différentes étapes de formation. Enfin, le résultat de la segmentation BEV est défini sur une résolution de 0,15 m et le nuage de points LiDAR est voxélisé. La plage de détection de HDMapNet est de [-30 m, 30 m] × [-15 m, 15 m] m, donc la taille de la carte BEV correspondante est de 400 × 200, tandis que Superfusion utilise [0 m, 90 m] × [-15 m, 15 m] et obtient 600 × 200 résultats. En raison des contraintes de dimensionnalité du LDM (sous-échantillonnage 8x dans VAE et UNet), la taille de la carte de vérité sémantique terrain doit être complétée jusqu'à un multiple de 64.
◆Détails de l'inférence : Les résultats de prédiction sont obtenus en effectuant le processus de débruitage sur la carte de bruit 20 fois dans les conditions actuelles des caractéristiques BEV. La moyenne de 3 échantillons est utilisée comme résultat final de la prédiction.
4.2 Les indicateurs d'évaluation
sont principalement évalués pour les tâches de segmentation sémantique de carte et de détection d'instances. Et il se concentre principalement sur trois éléments cartographiques statiques : les limites de voies, les séparateurs de voies et les passages pour piétons.


4.3 Résultats de l'évaluation
Le tableau 1 montre la comparaison des scores IoU pour la segmentation de la carte sémantique. DiffMap montre des améliorations significatives dans tous les intervalles, obtenant les meilleurs résultats en particulier sur les séparateurs de voies et les passages pour piétons.
 ▲Tableau 1|Comparaison des scores IoU
▲Tableau 1|Comparaison des scores IoU
Comme le montre le tableau 2, la méthode DiffMap présente également une amélioration significative de la précision moyenne (AP), vérifiant l'efficacité de DiffMap.
 ▲Tableau 2|Comparaison des scores MAP
▲Tableau 2|Comparaison des scores MAP
Comme le montre le tableau 3, lorsque le paradigme DiffMap est intégré dans HDMapNet, on peut observer que DiffMap peut améliorer les performances de HDMapNet, que ce soit en utilisant uniquement la caméra ou la méthode de fusion caméra-lidar. Cela montre que la méthode DiffMap est efficace dans diverses tâches de segmentation, notamment la détection à longue et courte portée. Cependant, pour les frontières, DiffMap ne fonctionne pas bien car la structure de forme des frontières n'est pas fixe et il existe de nombreuses distorsions imprévisibles, ce qui rend difficile la capture de caractéristiques structurelles a priori.
 ▲Tableau 3|Résultats de l'analyse quantitative
▲Tableau 3|Résultats de l'analyse quantitative
4.4 Expérience d'ablation
Le tableau 4 montre l'impact de différents facteurs de sous-échantillonnage dans VQVAE sur les résultats de détection. En analysant le comportement de DiffMap lorsque le facteur de sous-échantillonnage est de 4, 8 et 16, nous pouvons voir que lorsque le facteur de sous-échantillonnage est défini sur 8x, les meilleurs résultats sont obtenus.
 ▲Tableau 4|Résultats de l'expérience d'ablation
▲Tableau 4|Résultats de l'expérience d'ablation
De plus, l'auteur a également mesuré l'impact de la suppression du module de prédiction lié à l'instance sur le modèle, comme le montre le tableau 5. Les expériences montrent que l'ajout de cette prédiction améliore encore l'IOU.

▲Tableau 5|Résultats de l'expérience d'ablation (y compris le module de prédiction)
4.5 Visualisation
La figure 4 montre la comparaison entre DiffMap et la ligne de base (fusion HDMapNet) dans des scènes complexes. Il est évident que les résultats de la segmentation de base ignorent les propriétés de forme et la cohérence au sein des éléments. En revanche, DiffMap démontre sa capacité à corriger ces problèmes, en produisant un résultat de segmentation bien aligné sur la spécification de la carte. Plus précisément, dans les cas (a), (b), (d), (e), (h) et (l), DiffMap corrige efficacement les passages pour piétons prédits de manière inexacte. Dans les cas (c), (d), (h), (i), (j) et (l), DiffMap complète ou supprime les limites inexactes, rendant les résultats plus proches de géométries de limites réalistes. De plus, dans les cas (b), (f), (g), (h), (k) et (l), DiffMap résout le problème des lignes de démarcation brisées et assure le parallélisme des éléments adjacents.
 ▲Figure 4|Résultats de l'analyse qualitative
▲Figure 4|Résultats de l'analyse qualitative
Dans cet article, le réseau DiffMap conçu par l'auteur est une nouvelle méthode qui utilise le modèle de diffusion latente pour apprendre les a priori de la structure de la carte, améliorant ainsi le modèle de segmentation de carte traditionnel est adopté. Cette méthode peut être utilisée comme outil auxiliaire pour tout modèle de segmentation de carte, et ses résultats de prédiction sont considérablement améliorés dans les scénarios de détection de loin et de près. Cette méthode étant hautement évolutive, elle convient à l’étude d’autres types d’informations a priori. Par exemple, la carte SD prior peut être intégrée au deuxième module de DiffMap pour améliorer ses performances. On s'attend à ce que les progrès dans la construction de cartes vectorielles se poursuivent à l'avenir.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Résumé des connaissances de base de Java
Résumé des connaissances de base de Java
 Solution à l'erreur de socket 10054
Solution à l'erreur de socket 10054
 Quelle plateforme est Fengxiangjia ?
Quelle plateforme est Fengxiangjia ?
 La différence entre la version familiale Win10 et la version professionnelle
La différence entre la version familiale Win10 et la version professionnelle
 Introduction à l'utilisation de Rowid dans Oracle
Introduction à l'utilisation de Rowid dans Oracle
 Comment utiliser Python pour la boucle
Comment utiliser Python pour la boucle
 Quel élément est li ?
Quel élément est li ?
 Comment créer un projet HTML avec vscode
Comment créer un projet HTML avec vscode








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



