


La technologie populaire de la chaîne de pensée pourrait être renversée !
Toujours surpris que les grands modèles puissent réellement penser étape par étape à l'aide de chaînes de réflexion ?
Vous avez toujours du mal à écrire les mots d'invite de la chaîne de pensée ?
Des chercheurs de l'Université de New York ont déclaré : "Cela n'a pas d'importance, c'est tout de même."
Vous n'êtes pas obligé d'écrire le mot d'invite si vous ne le faites pas. voulez, utilisez simplement des points de suspension à la place.

Adresse papier : https://arxiv.org/pdf/2404.15758
Le titre de cet article utilise même directement "Pensons point par point" pour comparer l'étape "Pensons" de la chaîne de réflexion par étape", montrant la puissance des "points de suspension".
Les chercheurs ont découvert que le remplacement des étapes spécifiques du raisonnement en chaîne de pensée (CoT) par des "..." dénués de sens produirait des résultats de raisonnement également très différents.
Par exemple, dans l'exemple suivant : laissez le modèle compter combien des 6 premiers nombres sont supérieurs à 5.

Si vous lancez directement la question et laissez le modèle y répondre, le résultat sera incroyable : 6 sur 7.
En revanche, en utilisant l'invite de la chaîne de pensée, le modèle comparera la taille étape par étape et obtiendra finalement la bonne réponse : "25, 15, 25 , cela fait 3 chiffres".
Mais ce qui est encore plus scandaleux, c'est la méthode « métaphysique » utilisée dans cet article : il n'est pas nécessaire d'écrire les étapes, il suffit de sortir le même nombre de « points », et cela n'affecte pas le résultat final. résultat.
——Ce n'est pas un hasard. Un grand nombre d'expériences ont prouvé que les performances des deux dernières méthodes sont proches.
En d'autres termes, nous pensions que l'amélioration des performances du modèle venait de « réfléchir étape par étape », mais en fait, c'est peut-être simplement parce que LLM a obtenu la puissance de calcul de plus de jetons !
Vous pensez que le modèle réfléchit, mais en fait il grille.

——Stupides humains, vous essayez en fait de m'apprendre à raisonner avec des exemples naïfs. Savez-vous que tout ce que je veux, c'est du calcul.
"La chaîne de pensée n'a jamais existé et n'existera jamais dans le futur" (Gotou).
Jacob Pfau, l'auteur de l'article, a déclaré que ce travail prouve que le modèle ne bénéficie pas du raisonnement linguistique apporté par la chaîne de pensée. L'utilisation de "..." répétés pour remplir le jeton peut obtenir le même effet. comme CoT.

Bien sûr, cela soulève également la question de l'alignement : car ce fait montre que le modèle peut effectuer des raisonnements cachés qui ne sont pas visibles dans CoT, dans une certaine mesure échappant au contrôle humain.
On peut dire que la conclusion de l'article a bouleversé nos connaissances de longue date. Certains internautes ont dit : ils ont appris l'essence du masque.
"Qu'est-ce que cela signifie vraiment : le modèle peut utiliser ces jetons pour penser de manière indépendante à notre insu."

Certains internautes ont dit, pas étonnant que j'aime toujours utiliser ". .. "

Certains internautes ont commencé directement l'examen pratique :

Bien que nous ne sachions pas si sa compréhension est correcte~
Cependant, certains internautes pensent que le raisonnement caché de LLM dans la chaîne de pensée n'est pas fondé. Après tout, les résultats des grands modèles sont en principe basés sur des probabilités plutôt que sur une réflexion consciente.
Les indices CoT ne rendent explicite qu'un sous-ensemble de modèles statistiques, les modèles simulent l'inférence en générant un texte cohérent avec le modèle, mais ils n'ont pas la capacité de vérifier ou de réfléchir sur leur sortie.
Face à des problèmes complexes, nous, les humains, effectuons inconsciemment un raisonnement étape par étape.
Inspirés par cela, des chercheurs de Google ont publié la fameuse Chaîne de pensée en 2022.
La méthode qui nécessite que le modèle de langage résolve le problème étape par étape permet au modèle de résoudre des problèmes qui semblaient insolubles auparavant, améliorant considérablement les performances du LLM ou exploitant le potentiel du LLM.

Adresse papier : https://arxiv.org/pdf/2201.11903
Bien que tout le monde ne sache pas pourquoi cette chose fonctionnait au début, elle est rapidement devenue populaire car elle était vraiment facile à utiliser. propagé.

Avec l'essor des grands modèles et des projets de mots-clés, CoT est devenu un outil puissant pour le LLM pour résoudre des problèmes complexes.
Bien sûr, de nombreuses équipes de recherche explorent le principe de fonctionnement du CoT dans ce processus.
L'amélioration des performances apportée par la chaîne de réflexion est que le modèle apprend réellement à résoudre le problème étape par étape, ou est-ce simplement à cause du montant de calcul supplémentaire apporté par le nombre plus long de des jetons ?
Puisque vous n'êtes pas sûr que le raisonnement logique fonctionnera, n'utilisez tout simplement pas la logique et remplacez toutes les étapes de raisonnement par "..." qui sont définitivement inutiles.
Les chercheurs ont utilisé un modèle "petit alpaga": un lama de 34M de paramètres avec 4 couches, 384 dimensions cachées et 6 têtes d'attention. Les paramètres du modèle ont été initialisés de manière aléatoire.
Considérez deux questions ici :
(1) Quels types de données d'évaluation peuvent bénéficier des jetons de remplissage
(2) Quel type de données de formation est nécessaire pour apprendre au modèle à utiliser des jetons de remplissage
À cet égard, les chercheurs ont conçu 2 tâches et construit des ensembles de données synthétiques correspondants, chaque ensemble de données a mis en évidence une condition différente dans laquelle le remplissage des jetons peut améliorer les performances de Transformer.
3SUM
Regardons d'abord la première tâche la plus difficile : 3SUM. Le modèle doit sélectionner trois nombres dans la séquence qui remplissent les conditions. Par exemple, la somme des trois nombres divisée par 10 aura un reste de 0.

Dans le pire des cas, la complexité de cette tâche est la troisième puissance de N, et la complexité de calcul entre les couches de transformateur est la deuxième puissance de N,
Donc, lorsque la longueur de l'entrée Si la séquence est très grande, le problème 3SUM dépassera naturellement la capacité d'expression de Transformer.
L'expérience a mis en place trois groupes de contrôles :
1. Jeton de remplissage : La séquence utilise des ". . » répétés comme remplissage central, tels que "A05
B75 C22 D13. : .
Chaque point représente un jeton distinct, qui correspond au jeton de la chaîne de réflexion suivante.
2. Solution CoT parallélisable, la séquence est sous la forme : "A05 B75 C22 D13 : AB 70 AC 27 AD 18 BC 97 BD 88 CD B ANS True".
La chaîne de réflexion réduit le problème 3SUM à une série de problèmes 2SUM en écrivant toutes les sommes intermédiaires pertinentes (comme le montre la figure ci-dessous). Cette méthode réduit la quantité de calcul du problème à la puissance de N - Le transformateur peut le gérer et peut être parallélisé.

3. Solution CoT adaptative , la séquence est sous la forme : "A15 B75 C22 D13 : A B C 15 75 22 2 B C D 75 22 13 0 ANS True".
Contrairement à la solution ci-dessus, qui décompose intelligemment 3SUM en sous-problèmes parallélisables, nous espérons ici utiliser des méthodes heuristiques pour générer des chaînes de pensée flexibles afin d'imiter le raisonnement humain. Ce type de calcul adaptatif d'instance est incompatible avec la structure parallèle de calcul des jetons de remplissage.
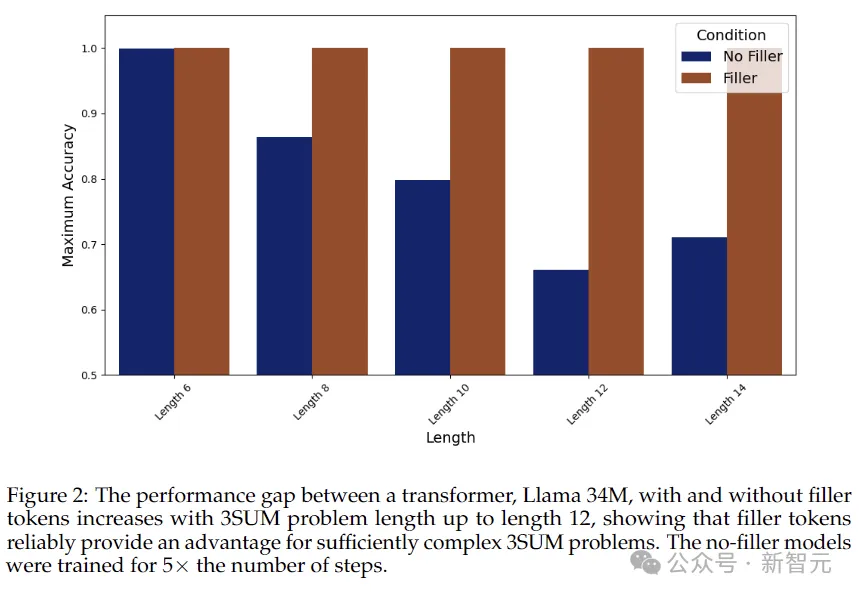
Comme le montrent les résultats de la figure ci-dessus, sans générer de jetons de remplissage, la précision du modèle diminue généralement à mesure que la séquence s'allonge, tandis que lorsque des jetons de remplissage sont utilisés, la précision reste à 100. %.
2SUM-Transform
La deuxième tâche est 2SUM-Transform Il vous suffit de juger si la somme de deux nombres répond aux exigences et le montant du calcul est sous le contrôle de Transformer.

Cependant, afin d'éviter que le modèle ne « triche », le jeton d'entrée est calculé sur place, et chaque numéro saisi est déplacé d'un décalage aléatoire.

Les résultats sont présentés dans le tableau ci-dessus : la précision de la méthode du jeton de remplissage atteint 93,6 %, ce qui est très proche de la chaîne de pensée. Sans remplissage intermédiaire, la précision n'est que de 78,7 %.
Mais cette amélioration est-elle simplement due à des différences dans la présentation des données d'entraînement, par exemple via des gradients de perte de régularisation ?
Pour vérifier si le remplissage des jetons entraîne des calculs cachés liés à la prédiction finale, les chercheurs ont gelé les poids du modèle et n'ont affiné que la dernière couche d'attention.
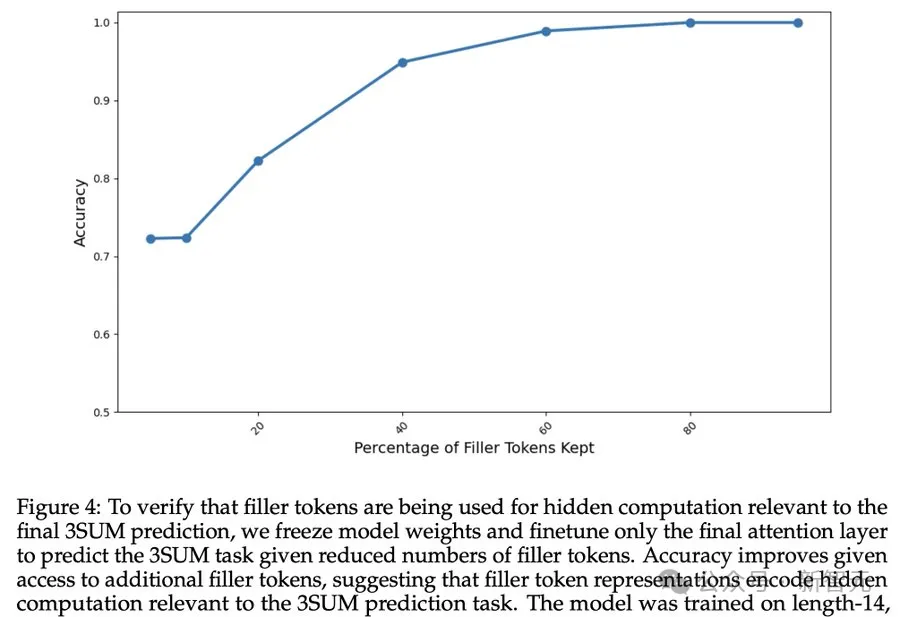
Les résultats ci-dessus montrent que la précision du modèle continue de s'améliorer à mesure que davantage de jetons de remplissage sont disponibles, indiquant que les jetons de remplissage effectuent effectivement des calculs cachés liés à la tâche de prédiction 3SUM.
Bien que la méthode de remplissage des jetons soit métaphysique, magique et même efficace, il est encore trop tôt pour dire que la chaîne de pensée a été bouleversée.
L'auteur a également déclaré que la méthode de remplissage des jetons ne dépassait pas la limite supérieure de la complexité informatique de Transformer.
Et apprendre à utiliser les jetons de remplissage nécessite un processus de formation spécifique. Par exemple, une supervision intensive est utilisée dans cet article pour faire finalement converger le modèle.
Cependant, certains problèmes peuvent avoir fait surface, tels que des problèmes de sécurité cachés, comme le projet de mot d'invite cessera-t-il soudainement d'exister un jour ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quelles compétences sont nécessaires pour travailler dans l'industrie PHP ?
Quelles compétences sont nécessaires pour travailler dans l'industrie PHP ?
 Comment lire des fichiers texte en HTML
Comment lire des fichiers texte en HTML
 données de récupération de disque
données de récupération de disque
 Que signifie nohup ?
Que signifie nohup ?
 Modifier le nom du fichier sous Linux
Modifier le nom du fichier sous Linux
 Win7 indique que les données de l'application ne sont pas accessibles. Solution.
Win7 indique que les données de l'application ne sont pas accessibles. Solution.
 Le câble réseau est débranché
Le câble réseau est débranché
 l'utilisation du processeur
l'utilisation du processeur








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



