


Les méthodes actuelles de contrôle décisionnel peuvent être divisées en trois catégories : la planification séquentielle, la planification sensible au comportement et la planification de bout en bout.
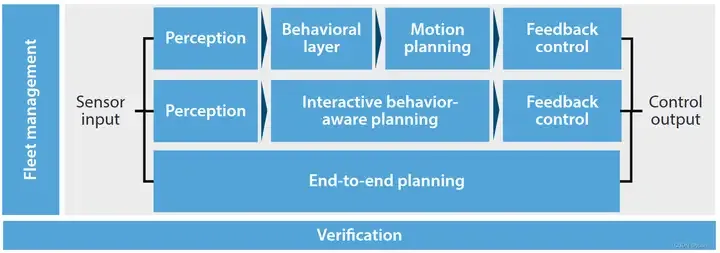
Cet article présentera la planification séquentielle, décrira le processus de contrôle de perception des véhicules autonomes selon l'ensemble de la séquence de contrôle décisionnel, et enfin résumera brièvement les problèmes à résoudre mentionnés ci-dessus. "Architecture de contrôle pour les véhicules automatisés" décrite dans cet article La planification appartient aux première et troisième étapes.
et path-veloc méthode de décomposition de l'entité , par rapport au premier type, la vitesse de déplacement est moins difficile, elle est donc plus couramment utilisée. 2.1 Types de planification de chemin
La planification de chemin peut être divisée en quatre grandes catégories : les algorithmes basés sur le  sampling
sampling
recherche représentée par A* et D*, La génération de trajectoire algorithme basé sur interpolation
ajustement représenté par la courbe β-spline, et l'algorithme de contrôleoptimal pour la planification de chemin local représenté par MPC. Cette section sera expliquée dans l'ordre ci-dessus :
3.1.1 Algorithme de base PRM et RRT(1) PRM
Algorithme PRM (Feuille de route probabiliste). Le PRM se compose principalement de deux étapes, l’une est l’étape d’apprentissage et l’autre est l’étape de requête. 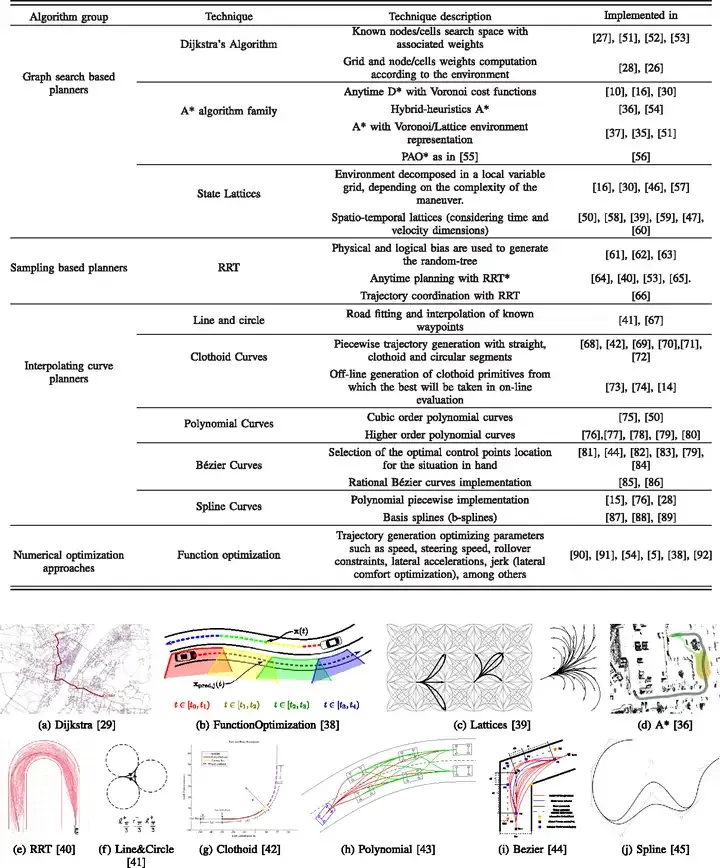
(2) Algorithme RRT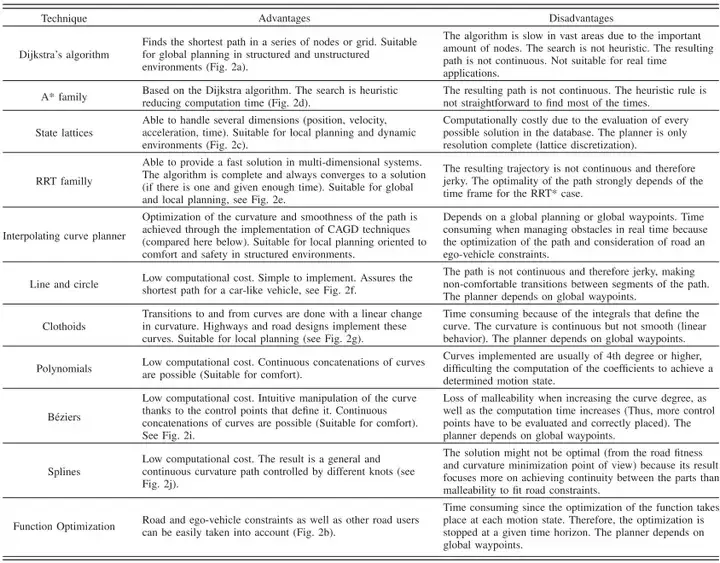
② Croissance de l'arbre : échantillonnez aléatoirement l'espace d'états. Lorsque le point d'échantillonnage se trouve dans la zone de sécurité de l'espace d'états, sélectionnez le nœud le plus proche du point d'échantillonnage dans l'arbre actuel et étendez-le jusqu'au point d'échantillonnage généré ; la trajectoire n'est pas connectée à l'obstacle Si un objet entre en collision, la trajectoire est ajoutée à l'ensemble de bords de l'arbre et le point final de la trajectoire est ajouté à l'ensemble de nœuds de l'arbre
③ Répétez l'étape ② jusqu'à ce qu'elle soit développée à l'ensemble d'états cibles. Par rapport au graphe non orienté de PRM, RRT Ce qui est construit est une structure arborescente avec l'état initial comme nœud racine et l'état cible comme nœud feuille. Pour différents états initial et cible, différents arbres doivent être construits. être construit.
RRT ne nécessite pas de connexions précises entre les états et est plus adapté à la résolution de problèmes de dynamique de mouvement tels que la planification de mouvements de véhicules sans pilote.
Résoudre l'efficacité et savoir si c'est la solution optimale. La raison pour laquelle PRM et RRT ont une exhaustivité probabiliste est qu'ils traverseront presque toutes les positions dans l'espace de configuration.
(1) Efficacité de résolution
En termes d'amélioration de efficacité de résolution, l'idée centrale de l'optimisation du RRT est de guider l'arbre vers la zone ouverte, c'est-à-dire d'essayer de rester à l'écart obstacles et éviter les contrôles répétés des nœuds au niveau des obstacles. Cela améliore l'efficacité. La solution principale :
① Échantillonnage uniforme
L'algorithme RRT standard échantillonne l'espace d'état de manière uniforme et aléatoire. La probabilité qu'un nœud dans l'arbre actuel obtienne une expansion est proportionnelle à sa zone de région de Voronoi, donc l'arbre se déplacera vers l'état. Les régions vides de l'espace grandissent, remplissant uniformément les régions libres de l'espace d'état. L'algorithme
RRT-connect construit simultanément deux arbres à partir de état initialet cibleétat respectivement Lorsque les deux arbres grandissent ensemble, une solution réalisable est trouvée. Go-biaing insère l'état cible dans une certaine proportion dans la séquence d'échantillonnage aléatoire, guidant l'arbre pour qu'il se développe vers l'état cible, accélérant la solution et améliorant la qualité de la solution.
heuristic RRT utilise une fonction heuristique pour augmenter la probabilité d'échantillonner des nœuds avec de faibles coûts d'expansion et calculer le coût de chaque nœud de l'arborescence. Cependant, dans des environnements complexes, la définition de la fonction de coût est difficile à résoudre. f La méthode d'échantillonnage biaisé discrétise d'abord l'espace d'état dans une grille, puis utilise l'algorithme de Dijkstra pour calculer le coût sur chaque grille. La valeur du coût des points dans la zone de la grille est égale à cette valeur. , construisant ainsi une fonction heuristique.
② Métrique de distance optimisée
La distance est utilisée pour mesurer le coût du chemin entre deux configurations, aide à générer une fonction de coût heuristique et guide la direction de l'arbre. Cependant, le calcul de la distance est difficile lorsque les obstacles sont pris en compte. La définition de la distance dans la planification de mouvement adopte une définition similaire à la distance euclidienne. RG-RRT (RRT guidé par rechabilité) peut éliminer l'impact d'une distance inexacte sur la capacité d'exploration RRT. Il doit calculer l'ensemble de nœuds accessible dans l'arborescence lorsque la distance entre le point d'échantillonnage et le nœud est supérieure à l'ensemble de nœuds accessible. le nœud, la distance, le nœud peut être sélectionné pour l'expansion.
③ Réduire le nombre de contrôles de collision
L'un des goulots d'étranglement d'efficacité de la méthode d'échantillonnage des contrôles de collision est que l'approche habituelle consiste à discrétiser le chemin à distances égales, puis à effectuer des contrôles de collision sur la configuration à chaque indiquer. résolution complète RRT obtient la probabilité d'expansion en réduisant les nœuds proches des obstacles Il discrétise l'espace d'entrée et ne l'utilise qu'une seule fois pour une certaine entrée de nœud si la trajectoire correspondant à une certaine entrée entre en collision avec un obstacle, alors le A correspondant ; Une valeur de pénalité est ajoutée au nœud. Plus la valeur de pénalité est élevée, plus la probabilité que le nœud soit étendu est faible. Le domaine dynamique RRT et le domaine dynamique adaptatif RRT limitent la zone d'échantillonnage à l'espace local où se trouve l'arborescence actuelle pour empêcher les nœuds proches des obstacles d'échecs d'expansion répétés et améliorer l'efficacité de l'algorithme.
④ Améliorer les performances en temps réel
À tout moment, RRT crée d'abord rapidement un RRT, obtient une solution réalisable et enregistre son coût, puis continue l'échantillonnage, mais insère uniquement les nœuds bénéfiques pour réduire le coût de la solution réalisable dans l'arbre, obtenant ainsi progressivement une meilleure solution réalisable. La replanification décompose l'ensemble de la tâche de planification en un certain nombre de séquences de sous-tâches de même durée et planifie la tâche suivante tout en exécutant la tâche en cours.
(2) Il existe principalement les méthodes suivantes pour résoudre le problème de l'optimalité :
Algorithme RGG (graphe géométrique aléatoire) : un PRM avec des propriétés asymptotiques optimales qui est amélioré par rapport au PRM et RRT standard basé sur la théorie des graphes géométriques aléatoires Les algorithmes RRG et RRT échantillonnent aléatoirement n points dans l'espace d'état et connectent les points dont la distance est inférieure à r(n) pour former RGG.
Algorithme RRT* : introduisez l'étape de "reconnexion" basée sur RRG pour vérifier si le nœud nouvellement inséré en tant que nœud parent de son point adjacent réduira le coût de son point adjacent. Si c'est le cas, supprimez le parent et l'enfant d'origine de. le point adjacent. Relation, prenant le point d'insertion actuel comme nœud parent, c'est l'algorithme RRT*.
Algorithme LBT-RRT : Un grand nombre de connexions de nœuds et d'ajustements locaux rendent PRM et RRT très inefficaces. L'algorithme LBT-RRT combine les algorithmes RRG et RRT* pour obtenir une efficacité plus élevée sur la base de l'obtention d'une optimalité asymptotique.
L'idée de base est de discrétiser l'espace d'état dans un graphe d'une certaine manière, puis d'utiliser divers algorithmes de recherche heuristiques pour rechercher des solutions réalisablesou même solutions optimales , cet algorithme de catégorie est relativement mature.
La base de l'algorithme basé sur la recherche est le réseau d'états. Le réseau d'états est une discrétisation de l'espace d'états et une primitive de mouvement qui part du nœud et atteint le nœud adjacent. Un nœud d'état peut transmettre ses transformations primitives de mouvement à un autre nœud d'état. Le réseau d'états convertit l'espace d'états continu d'origine en un graphe de recherche. Le problème de planification de mouvement consiste à rechercher une série de primitives de mouvement qui transforment l'état initial en état cible dans le graphe. Après avoir construit le réseau d'états, vous pouvez utiliser la recherche graphique. algorithme pour rechercher la trajectoire optimale.
L'algorithme de Dijkstra parcourt tout l'espace de configuration, trouve la distance entre chacune des deux grilles et sélectionne enfin le chemin le plus court du point de départ au point cible, avec la largeur La nature prioritaire conduit à une très faible efficacité. L'ajout d'une fonction heuristique à cet algorithme, c'est-à-dire la distance entre le nœud recherché et le nœud cible, et une nouvelle recherche basée sur cela peut éviter l'inefficacité causée par la recherche globale. , comme le montre la figure ci-dessous, le rouge est la zone de recherche.
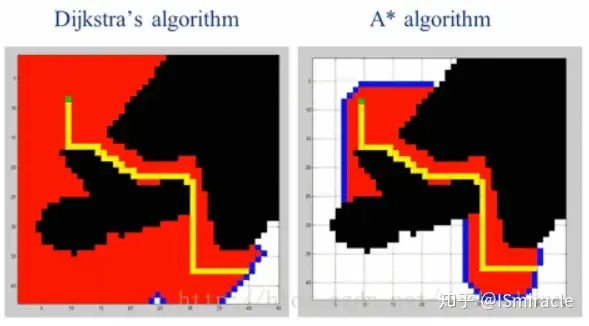
Figure 6 : Comparaison des effets des algorithmes A* et Dijkstra
Tout comme les algorithmes basés sur l'échantillonnage, ce type d'algorithme doit également être efficace et optimisation sexuelle optimale.
En termes d'amélioration de l'efficacité, A* lui-même est un algorithme de planification statique. Une extension de l'algorithme A* est pondérée A*, qui guide davantage la direction de recherche vers le nœud cible en augmentant le poids de la fonction heuristique. la vitesse est très rapide, mais il est facile de tomber dans les minima locaux et ne peut garantir la solution globale optimale.
Pour les véhicules en mouvement, l’utilisation de l’algorithme dérivé D de A* (A dynamique) peut grandement améliorer l’efficacité. LPA est également basé sur la programmation dynamique. Cet algorithme peut gérer la situation dans laquelle le coût des primitives de mouvement de la grille d'état varie dans le temps. Lorsque l'environnement change, un nouveau plan optimal peut être planifié en recherchant un plus petit nombre de. nœuds. Développé sur la base du LPA, D*-Lite peut atteindre les mêmes résultats que D*, mais avec une efficacité supérieure.
Lors de la recherche de solutions optimales, ARA* est un algorithme de recherche à tout moment développé sur la base de Weighted A*. Il appelle l'algorithme Weighted A* plusieurs fois et réduit le poids de la fonction heuristique à chaque appel, de sorte que l'algorithme. peut rapidement trouver une solution réalisable. En introduisant l'ensemble INCONS, chaque cycle peut continuer à utiliser les informations du cycle précédent pour optimiser le chemin et s'approcher progressivement de la solution optimale.
En termes d'équilibrage de l'efficacité et de l'optimalité de l'algorithme, Sandin Aine et al. ont proposé l'algorithme MHA*, qui a introduit plusieurs fonctions heuristiques pour garantir que l'une des fonctions heuristiques peut trouver la solution optimale lorsqu'elle est utilisée seule, donc par coordination. générés par différentes fonctions heuristiques peuvent prendre en compte l’efficacité et l’optimalité de l’algorithme. DMHA génère des fonctions heuristiques appropriées en ligne et en temps réel sur la base de MHA, évitant ainsi le problème du minimum local.
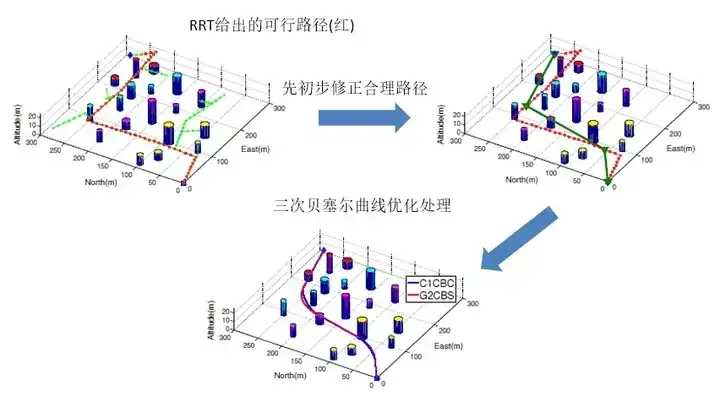
L'algorithme basé sur l'ajustement par interpolation peut être défini comme : basé sur une série connue d'ensembles de points utilisés pour décrire la feuille de route, en utilisant l'interpolation de données et Le La méthode d'ajustement de courbe crée le chemin sur lequel la voiture intelligente se déplacera, ce qui peut offrir une meilleurecontinuité et unedifférentiabilité plus élevée. La méthode spécifique est la suivante :
La courbe de Dubins et la courbe de Reeds et Sheep (RS) sont les chemins les plus courts reliant deux points quelconques de l'espace de configuration, correspondant respectivement aux situations sans inversion et avec inversion. Ils sont tous composés d'arcs et de lignes droites avec une courbure maximale. Il existe une discontinuité de courbure au niveau de la connexion entre l'arc et la ligne droite. Lorsqu'un véhicule réel suit une telle courbe, il doit s'arrêter et ajuster le volant au niveau de la discontinuité. de courbure pour continuer à rouler.La courbe d'interpolation polynomiale est la méthode la plus couramment utilisée. Elle peut définir des coefficients polynomiaux en répondant aux exigences des nœuds et obtenir une meilleure différentiabilité continue. Les polynômes du quatrième ordre sont souvent utilisés pour le contrôle des contraintes longitudinales, et les polynômes du cinquième ordre le sont souvent. utilisé pour le contrôle des contraintes longitudinales. Les polynômes sont souvent utilisés dans le contrôle des contraintes latérales, et les polynômes du troisième ordre sont également utilisés pour dépasser les trajectoires.
Courbe spline a une expression fermée et peut facilement assurer la continuité de la courbure. Les courbes β-spline peuvent assurer la continuité de la courbure, et les courbes de Bézier cubiques peuvent assurer la continuité et les limites de la courbure, et la quantité de calcul est relativement faible. La courbe η^3 [43] est une courbe spline du septième ordre, qui possède de très bonnes propriétés : continuité de courbure et continuité des dérivées de courbure, ce qui est très significatif pour les véhicules à grande vitesse.
Les algorithmes basés sur un contrôle optimal sont classés dans la planification de trajectoire, principalement parce que MPC peut effectuer une planification de trajectoire locale pour éviter les obstacles. De plus, MPC a principalement pour fonction de suivre la trajectoire. aux contraintes dynamiques et cinématiques nécessaires, les questions qu'il considère doivent également prendre en compte le confort, l'incertitude des informations sensorielles, l'incertitude de la communication inter-véhicules à l'avenir et lors de la planification d'une trajectoire locale, le conducteur peut également être inclus dans la boucle de contrôle. Les problèmes d'incertitude mentionnés ci-dessus et l'intégration du pilote dans la boucle de contrôle seront abordés dans la section 4. L'étude du MPC commence principalement par deux aspects : la théorie de l'optimisation et la pratique de l'ingénierie. Pour le premier, je recommande Convex Optimization Algorithms de Dimitri P. Bertsekas et Model Predictive Control: Theory, Computation, and Design de James B. Rawlings. Dans le domaine chinois, le livre d’optimisation du professeur Liu Haoyang estime personnellement qu’il est relativement clair et facile à comprendre. Pour ce dernier, tout d'abord, le livre MPC autonome du professeur Gong Jianwei est fortement recommandé. Il y avait des problèmes avec la démo dans l'ancienne version du livre, mais ils ont tous été résolus dans la nouvelle version.
Il existe de nombreux modèles de prédiction utilisés par MPC : tels que le réseau de neurones convolutifs, le contrôle flou, l'espace d'état, etc. Parmi eux, la plus couramment utilisée est la méthode de l'espace d'état. MPC peut être brièvement exprimé comme suit : lorsque les contraintes dynamiques, cinématiques, etc. nécessaires sont remplies, la solution optimale du modèle est résolue par des moyens numériques. La solution optimale est la variable de contrôle de l'équation d'état, telle que l'angle du volant. , etc., et appliquer la quantité de contrôle au modèle de voiture pour obtenir les quantités d'état requises, telles que la vitesse, l'accélération, les coordonnées, etc.
Il ressort de la description ci-dessus que la clé du MPC réside dans l'établissement et la solution du modèle. Comment simplifier de manière équivalente l'établissement du modèle et améliorer l'efficacité de la solution est la priorité absolue. Le véhicule empruntera différentes trajectoires sous différentes entrées de contrôle, et chaque trajectoire correspond à une valeur de fonction objectif. Le véhicule sans pilote utilisera un algorithme de résolution pour trouver la quantité de contrôle correspondant à la valeur de fonction objectif minimale et l'appliquera au véhicule ci-dessus. , comme le montre la figure ci-dessous :
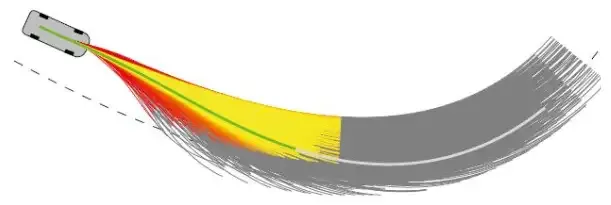
Afin de réduire la difficulté de modélisation, des modèles de champs d'énergie potentielle artificielle sont également utilisés pour la modélisation. L'idée de base des champs d'énergie potentielle artificielle est similaire à celle des champs électriques, et. les obstacles sur la route sont similaires aux sources de champ dans les champs électriques. Charges avec des polarités de charge différentes. L'énergie potentielle aux obstacles (dynamiques, statiques) est plus élevée et le véhicule sans pilote se déplacera vers une position à faible énergie potentielle.
Recommander un projet open source CppRobotics :
Le contexte d'apprentissage pour se lancer dans de nouveaux domaines est : Ingénierie, Théorie et Visiontroïka vont de pair, prenant la planification du chemin comme un exemple :
fait référence à la compréhension du contenu de chaque algorithme de planification de chemin, tout en comprenant le contenu de chaque algorithme de la largeur, et en même temps l'apprentissage des détails de chaque algorithme de la profondeur . Concernant les algorithmes dans le domaine de la planification de trajectoire, il n'existe actuellement aucun didacticiel complet, mais la planification de mouvement NMPC de Gong Jianwei peut être une référence.
fait référence à la compréhension des principes mathématiques qui soutiennent le fonctionnement de ces algorithmes et des raisons pour lesquelles ces algorithmes sont générés (perspective mathématique).
fait référence à la compréhension des principales applications de la planification de parcours dans la recherche scientifique et les entreprises, à l'aide de documents de recherche scientifique et de rapports de résultats, etc.
Cet article présente les grandes lignes de la planification actuelle des chemins et comprend les méthodes actuelles de planification des chemins. Le contenu est très complexe et il est difficile de tout apprendre en peu de temps sans une orientation pratique vers les applications. Vous ne pouvez vous concentrer sur l'apprentissage qu'en cas de besoin.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Caractéristiques du réseau
Caractéristiques du réseau
 Comment conserver le nombre de décimales en C++
Comment conserver le nombre de décimales en C++
 Comment configurer l'actualisation automatique d'une page Web
Comment configurer l'actualisation automatique d'une page Web
 Comment résoudre une syntaxe invalide en Python
Comment résoudre une syntaxe invalide en Python
 Comment devenir un ami proche sur TikTok
Comment devenir un ami proche sur TikTok
 barre de lancement gratuite
barre de lancement gratuite
 serveur Web
serveur Web
 À quel point Dimensity 9000 équivaut-il à Snapdragon ?
À quel point Dimensity 9000 équivaut-il à Snapdragon ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



