


Introduction de base

Tout d’abord, commençons par un concept important : le « modèle ». D'une manière générale, un modèle sur le Web est une page qui peut générer un fichier après avoir rempli des données. À proprement parler, il devrait s'agir du moteur de modèles qui utilise des fichiers dans un format spécifique et les données fournies pour compiler et générer des pages. Les modèles sont grossièrement divisés en modèles front-end (tels que ejs) et modèles back-end (tels que freemarker), qui sont compilés respectivement côté navigateur et côté serveur.
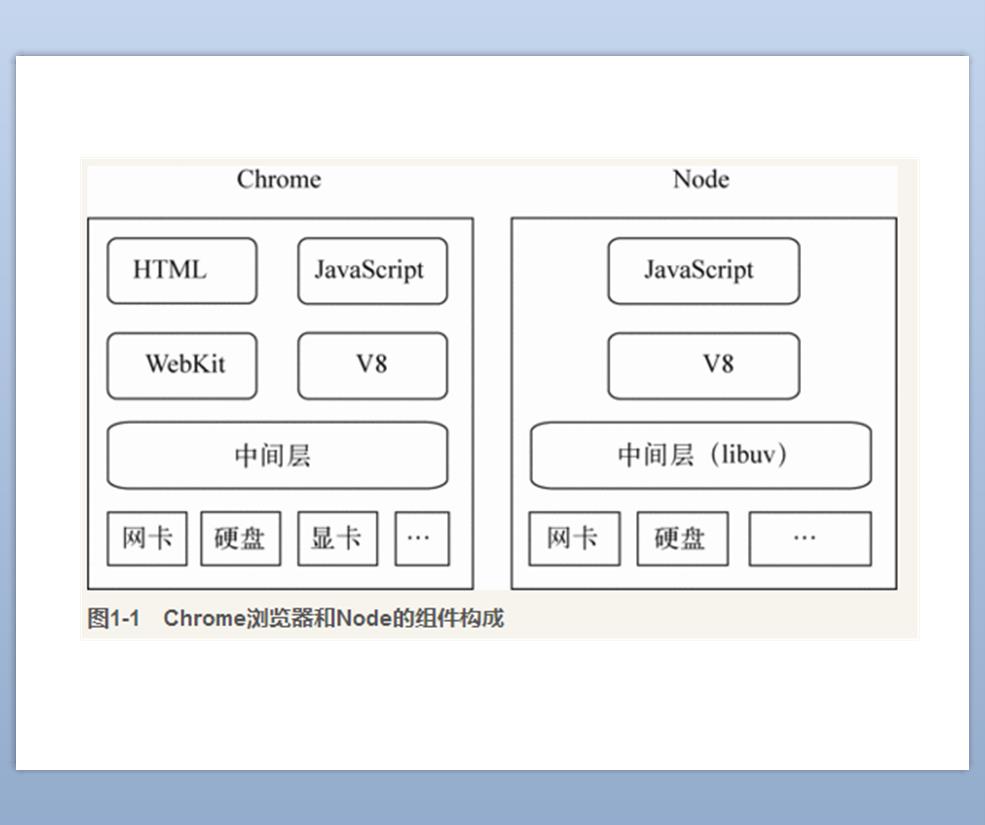
Étant donné que certains étudiants présents sur place ne connaissaient pas grand chose sur node.js, voici quelques connaissances supplémentaires sur node.js. La définition donnée sur le site officiel est événementielle, asynchrone, etc. Ici, j'emprunte une image à Pu Lingshu pour expliquer la structure de node.js. Si vous connaissez Java, vous pouvez le comprendre comme la version js de jvm. Les navigateurs incluent généralement un moteur de rendu et un moteur de script js. En prenant le navigateur Chrome comme exemple, il utilise le moteur de rendu du noyau Webkit et le moteur de script V8, tandis que node.js utilise le moteur v8. Dans l'ensemble, il s'agit d'un environnement d'exécution js, tout comme l'outil de débogage F12 du navigateur, sauf que node.js n'a pas de DOM ni de BOM.
Cette image décrit quelques informations autour de node.js, comme npm, un excellent gestionnaire de paquets, la communauté cnode et github, qui ont dans une certaine mesure favorisé la prospérité de node.js et fourni un support technique.

Les grandes entreprises sont généralement le fleuron de la technologie. Par exemple, Angular de Google et React de Facebook sont désormais très populaires. Seules trois grandes entreprises sont citées ici à titre d’exemple. Inutile de dire que l'architecture Midway de Taobao, Pu Ling, le pionnier du node.js domestique, vient de Taobao. Qunar a également développé un framework technique qui devrait s'appeler « QTX ». L'équipe 75 dirigée par 360 Yueying a mis au point un framework de serveur Web basé sur ES6/ES7 - thinkjs. À cette époque, notre directeur technique était très optimiste à ce sujet. Cependant, comme je n'avais pas le temps d'apprendre ES6 et le plug-. les ins n'étaient pas assez riches, j'ai quand même choisi l'Express plus mature.

Pour en revenir au sujet, ce tableau répertorie les trois méthodes de développement de séparation front-end et back-end que j'ai rencontrées. Le premier est l'utilisation la plus courante de modèles de langage back-end tels que Java. Il est optimisé pour le référencement, a une meilleure utilisation du cache et réduit la charge de rendu du navigateur. Le plus gros problème est que le degré de couplage du fichier modèle est trop élevé. peut se tromper ?Ils ne veulent pas le résoudre.Le personnel front-end ne peut pas voir les données, le personnel back-end ne comprend pas la page et le fichier modèle est comme une patate chaude. Le second est le plan de mise en œuvre actuel pour le côté mobile de notre projet, qui utilise un framework comme angulaire (les instructions angulaires peuvent être considérées comme des modèles front-end) et un serveur proxy inverse comme nginx pour découpler complètement le front-end et le back-end et seulement interagir avec les données via ajax. Cette solution présente exactement les avantages et les inconvénients opposés à la précédente. Les performances des modèles front-end sont toujours un problème, en particulier du côté mobile, et surtout sur les appareils mobiles bas de gamme. La dernière consiste à utiliser node.js comme serveur frontal pour les nouveaux projets. Elle divise les responsabilités frontales du navigateur à la couche modèle, ce qui résout tous les problèmes ci-dessus. Cependant, il existe effectivement de nouveaux problèmes, qui. sera discuté plus tard.

Bien sûr, le développement full-stack est également très adapté aux petits projets. Pour le développement jsp/php traditionnel, le coût de communication du développement full-stack est inférieur et les développeurs peuvent comprendre plus facilement l'ensemble du module fonctionnel, rétablissant ainsi mieux la conception du produit. Surtout le développement full-stack actuel basé sur le langage js : meteor et la technologie MEAN, qui permet de réaliser le développement front-end et back-end directement dans un seul langage. Couplées à Mongodb, les données peuvent être utilisées directement du navigateur vers la base de données. sans s'échapper. Il n'est pas nécessaire d'écrire du SQL et les coûts de développement sont considérablement réduits.

Certains plug-ins utilisés pour construire le serveur node.js cette fois. Le célèbre express n’a pas besoin d’être présenté davantage, il s’agit d’un framework de serveur Web léger. C'est une coïncidence si le moteur de modèle de guidon est utilisé parce qu'express4 est par défaut un moteur de modèle à « logique faible ». Il préconise de réduire la logique du modèle et d'essayer d'utiliser uniquement des variables et une pagination. Je n'ai développé que deux assistants. Article spécifique : https://yalishizhude.github.io/2016/01/22/handlebars/Superagent est toujours utilisé à cause d'express4, car son code de test utilise supertest, et supertest est basé sur superagent, donc Superagent est utilisé pour transmettre et lancer des demandes. Le superagent est encore trop faible et les connexions longues ne peuvent pas être établies. Le plug-in de requête est toujours recommandé. Il n'y a pas grand-chose à présenter sur restfuleAPI. Les serveurs et navigateurs front-end, les serveurs front-end et les serveurs back-end utilisent tous cet ensemble de spécifications. Fondamentalement, l'URL pointe vers la ressource, l'ajout, la suppression, la modification et la requête. représenté par des méthodes de requête spécifiques, et les codes d'état représentent les résultats, etc. ~ L'outil de packaging gulp, webpack, a été étudié depuis longtemps, et j'ai découvert qu'à chaque fois que j'ajoute une page, je dois modifier le fichier de configuration. c'est trop douloureux, alors j'ai abandonné.
Processus de développement
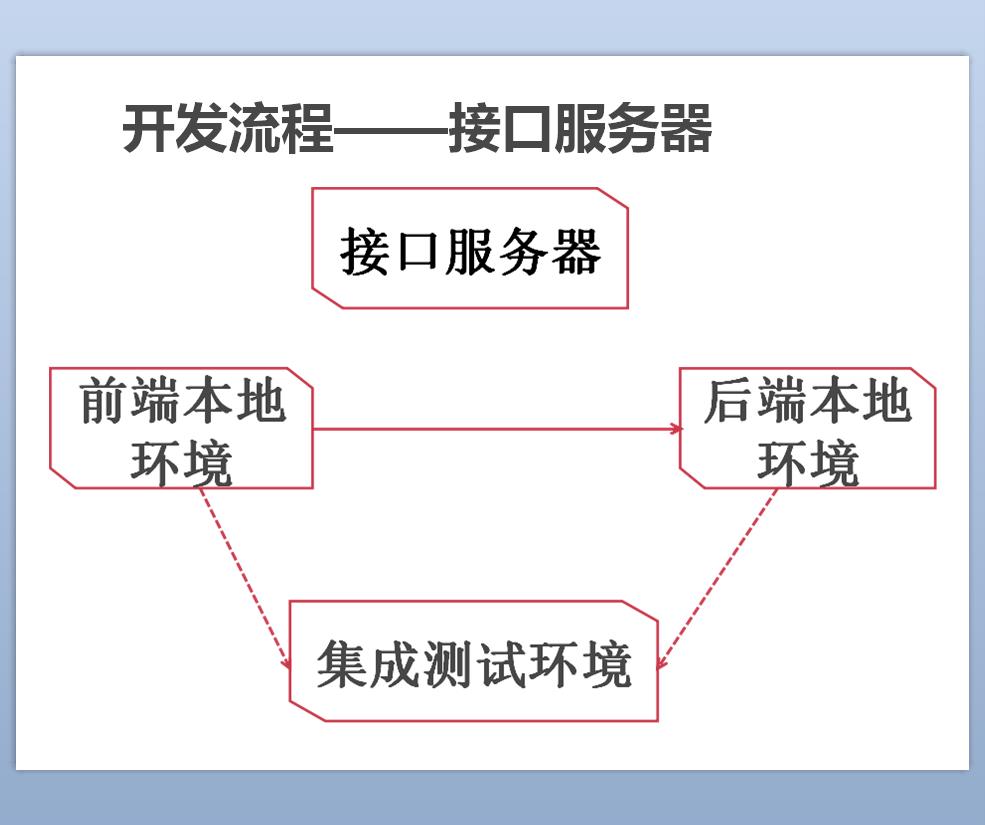
Si ce partage concerne principalement la façon d'utiliser node.js comme serveur frontal pour réaliser la séparation front-end et back-end, alors il n'y a rien à dire, lisez simplement l'article de Taobao UED. En fait, le plus gros problème lié à la séparation du front-end et du back-end est l’augmentation des coûts de communication, notamment la définition et le débogage des interfaces. Dans le processus de développement traditionnel illustré ci-dessus, la définition de l'interface sera placée dans le serveur d'interface, puis les front-ends et les back-ends effectueront un débogage local basé sur de fausses données du document d'interface, puis effectueront un débogage conjoint. C'est à ce moment-là que le front-end et le back-end commencent à se battre. Ce paramètre est faux et la valeur de retour est fausse. Bref, c'est une perte de temps. Voyons comment ce problème est résolu dans notre projet~
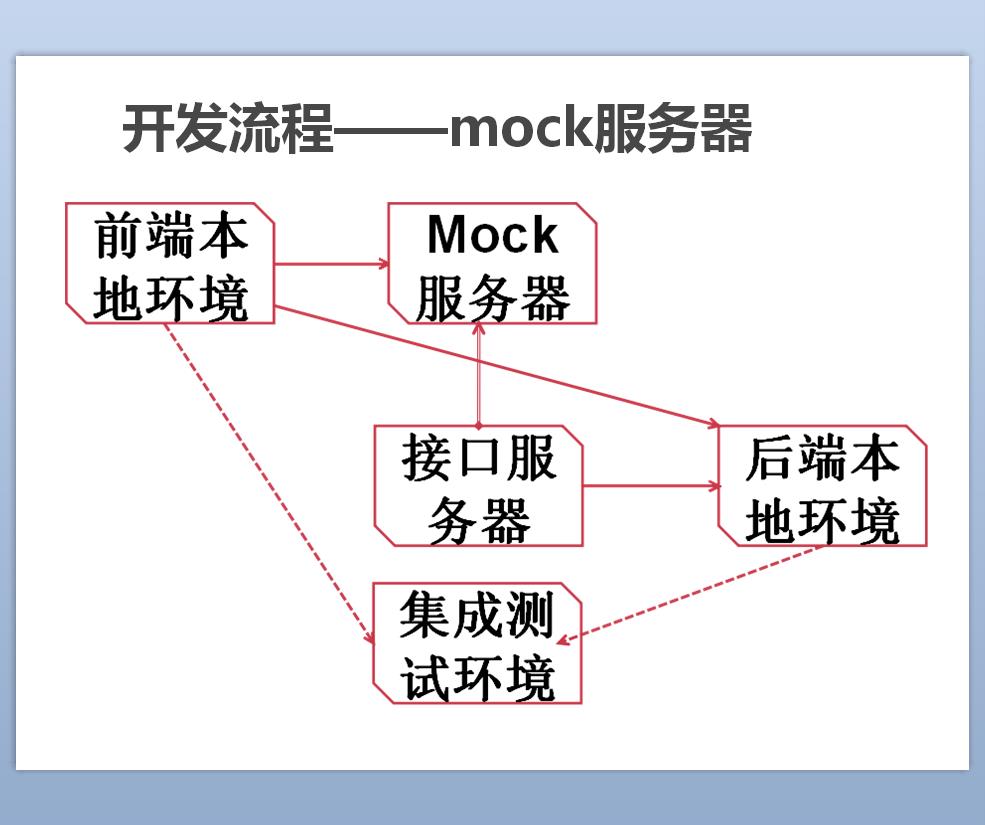
Il y a toujours eu un problème de conflits d'interfaces entre le front-end et le back-end. En tant que conservateur, je crois au développement itératif, la première étape a donc été d'ajouter un serveur fictif. La magie de ce serveur est qu'il génère automatiquement de fausses données basées sur le document d'interface et implémente l'interface, c'est-à-dire que les étudiants Front-end n'ont plus à écrire les données pour les tests. Pas question, qui m'appelle développeur front-end ? Je pense d'abord à moi, hehe~ Bien sûr, cela n'est bénéfique pour le développement front-end que dans une certaine mesure. Des problèmes surviendront également lorsque l'interface back-end et la documentation sont disponibles. incohérents et débogués conjointement. ce qu'il faut faire?
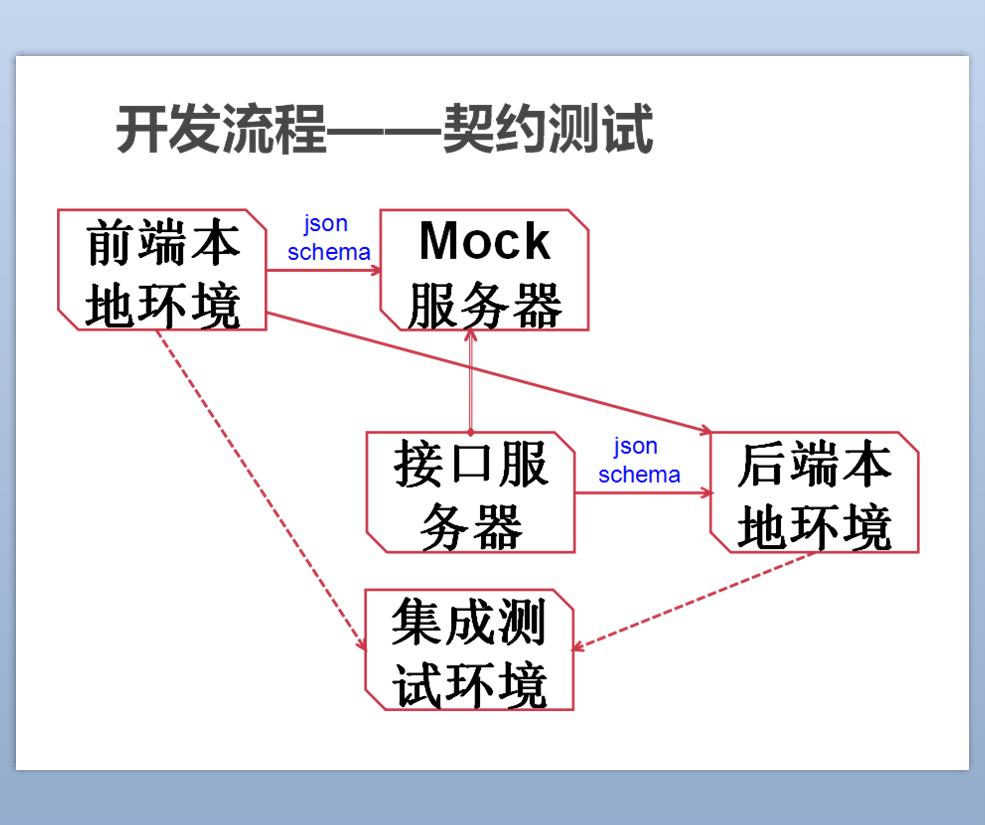
Par hasard, j'ai vu un article de Lao Ma sur le blog de Maître Polang qui parle de la séparation du front-end et du back-end. L'un des concepts importants est le test contractuel, également appelé test bilatéral. Le concept principal est de résoudre le problème du débogage commun à distance. Vérifiez les paramètres du front-end et du back-end et demandez à chacun de développer selon les documents d'interface. Inspiré par cela, j'ai ajouté des règles json-schema pour implémenter la vérification des paramètres des requêtes http. Toute personne qui ne respecte pas les règles les modifiera.
Ce Redmine est notre premier gestionnaire de documents d'interface. Il n'a pas d'autre fonction que les fonctions d'enregistrement et de visualisation.
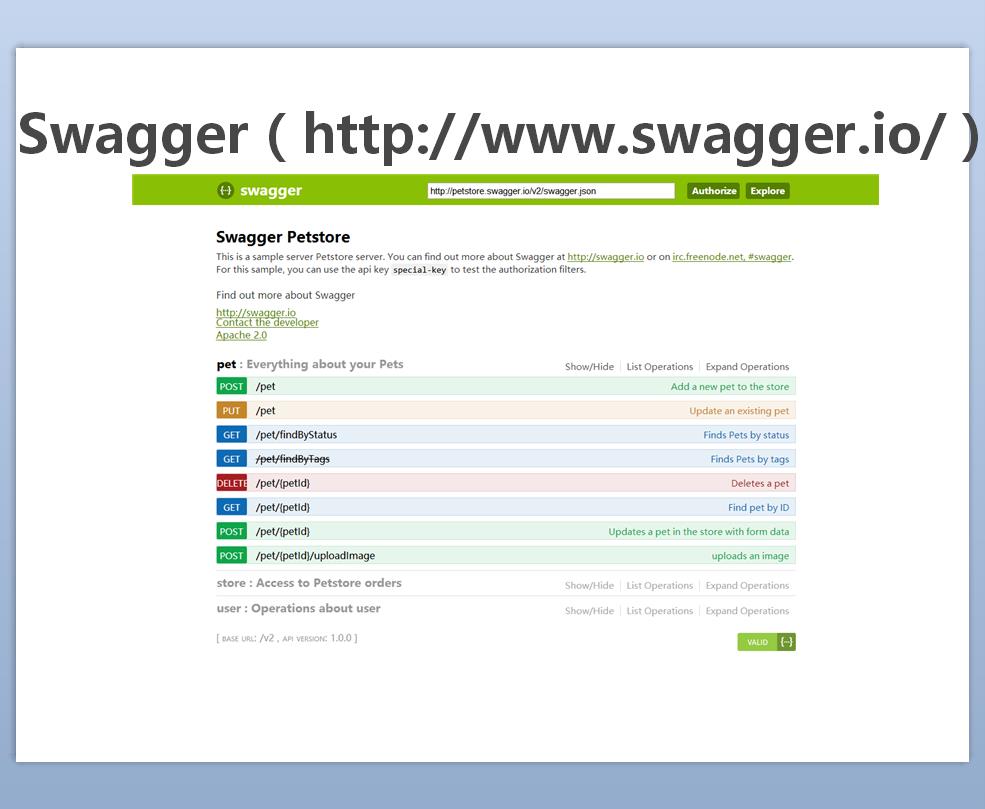
Swagger est connu comme le serveur de documents d'interface le plus populaire au monde. Il possède une belle interface et de nombreux plug-ins. Il peut générer directement du code de test pour les langages back-end. Cependant, je ne l'ai jamais compris lors du déploiement, et le format yaml n'était pas aussi bon que json, j'ai donc abandonné.
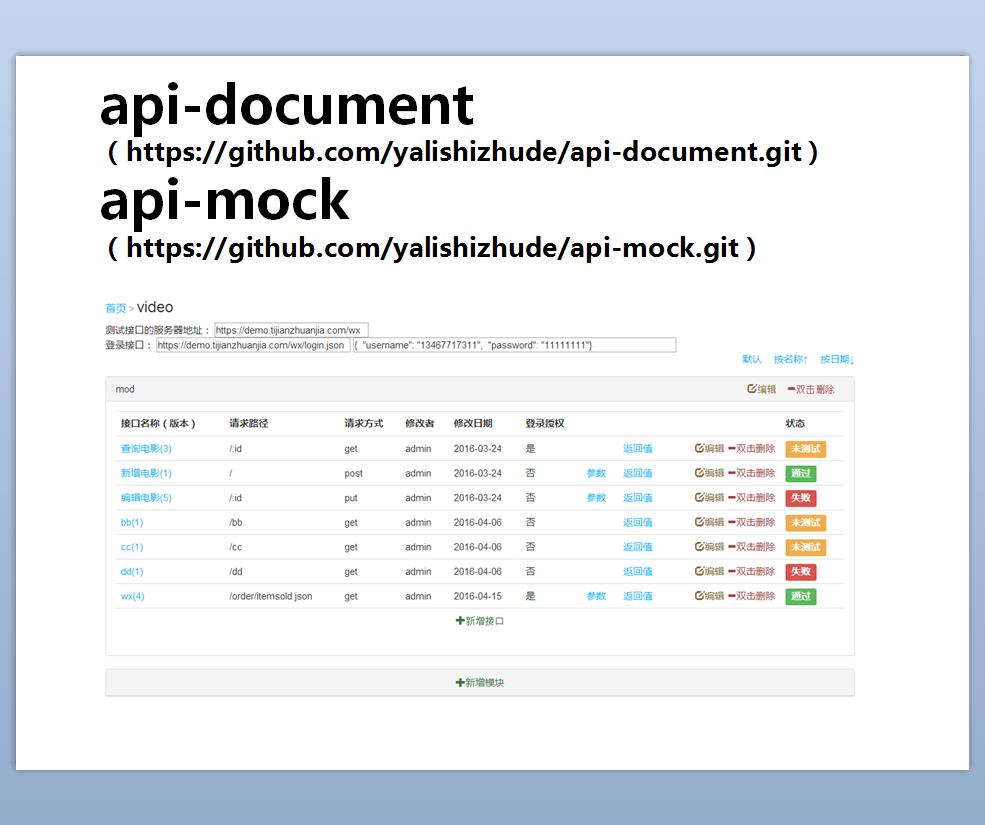
Il s'agit du serveur de documents et du serveur fictif actuellement utilisés dans notre projet, un serveur basé sur la technologie MEAN, fonctions de base :
À l'aide du plug-in mockjs, vous pouvez générer dynamiquement des données aléatoires basées sur le schéma json, effectuer une vérification et des tests d'interface sur les paramètres d'interface, et enregistrer l'état du test et le temps de réponse de l'interface. L'éditeur json simple a une fonction de vérification de connexion. Vous pouvez déboguer l'interface après vous être connecté. Le serveur fictif répond aux demandes en fonction du serveur API, et il est automatiquement mis à jour lorsque l'interface est mise à jour
Quelques questions

Node.js ist die Flügel eines Front-End-Ingenieurs. Wird er ein Engel oder ein Teufel mit Flügeln? Dies hängt davon ab, ob die durch die Verwendung verursachten Probleme gelöst werden können.
Zuallererst wird die Arbeitsbelastung des Frontends zweifellos zunehmen, aber die Kommunikationskosten werden sinken. Die Single-Threaded-Serverstabilität von node.js ist zwar nicht gut genug, aber die Robustheit des Codes und der vollständigen Protokolle können dies effektiv vermeiden. Rückruf. Es gibt zu viele Lösungen für dieses Problem, einschließlich des q/async-Moduls von node.js und ES6/ES7. node.js-Debugging. Obwohl ich IDEs immer abgelehnt habe, muss ich zugeben, dass Webstorm zum Debuggen tatsächlich sehr praktisch ist. Der von mir verwendete Node-Inspector ist in Ordnung. Die Benutzeroberfläche ähnelt den Chrome-Entwicklertools und kommt mir recht bekannt vor.

Wenn Sie ein Back-End-Programmierer sind, sollten Sie node.js nutzen. Die Schnittstellenintegrationsarbeit wird zur Verarbeitung an den Front-End-Server übergeben. Gleichzeitig wird die Kopplung mit dem Front-End erheblich reduziert und der Arbeitsaufwand und die Arbeitseffizienz verringert.

Ich habe zwei Erfahrungspunkte
Obwohl die Verwendung von node.js mit einem gewissen Lernaufwand verbunden ist, ist sie für Front-End-Entwickler dennoch sehr benutzerfreundlich. Darüber hinaus werden durch den Einsatz von node.js im Frontend sowohl der technische Inhalt als auch der Arbeitsaufwand verbessert und somit die Bedeutung der Stelle erhöht. Nur wenn Front-End-Entwickler mehr Wert schaffen können, können sie höhere Gehälter verlangen. Bei der Arbeit wird empfohlen, weniger Vorschläge und praktikablere Lösungen zu machen und gleichzeitig technische Vorrecherchen durchzuführen, anstatt eine einfache zu schreiben hallowelt.
Zusammenfassung
Manche Leute sagen vielleicht, dass die von Ihnen eingeführten Dinge so kompliziert und zu mühsam in der Anwendung sind und dass es besser ist, persönlich zu kommunizieren. Für solche Zweifel kann ich nur ein Beispiel verwenden, das Yu Guo, ein leitender UI-Ingenieur bei Tencent, in „Selbstkultivierung von Web-Full-Stack-Ingenieuren“ erwähnt hat. Als er einmal den Front-End-Manager eines kleinen Unternehmens anrief und ihn fragte, wie er den Code verwalten solle, sagte die andere Person, dass er ihn direkt über FTP hochladen könne. Er beschwerte sich auch darüber, dass seine Untergebenen immer den falschen Code aktualisierten, und fragte Er sagte, es sei besser, es manuell zu aktualisieren. Die Wahrheit dieser Geschichte ist meine Antwort auf die Fragen~
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



