


Tout le monde sait à quel point la syntaxe de JavaScript est pitoyable.
Prenons d'abord une photo
Le code est le suivant :
Je crois que la plupart des enfants qui n'étudient pas les compilateurs JavaScript ne peuvent pas du tout le comprendre. (Au moins, je trouve ça incroyable)
Plus tard, je suis allé rendre visite à ma mère, et je m'en suis soudain rendu compte !
Ensuite, jetons un œil à ce code :
Et ce code ?
Évidemment non ! Si nous y réfléchissons attentivement, nous réaliserons qu’il s’agit d’un bloc d’instructions.
Pour résoudre ce problème, la méthode d'ECMA est très simple et grossière : lors de l'analyse grammaticale, si une instruction commence par "{", elle ne sera interprétée que comme un bloc d'instructions.
C'est vraiment une façon de tricher de gérer cela !
Puisqu'il s'agit tous de blocs d'instructions, pourquoi {a:1} n'a-t-il aucune erreur grammaticale ?
En fait, ici, a est compris par l'analyseur comme une balise. Les étiquettes sont utilisées avec les instructions break et continue pour effectuer des sauts directionnels.
Par conséquent, écrire comme ceci lèvera une exception :
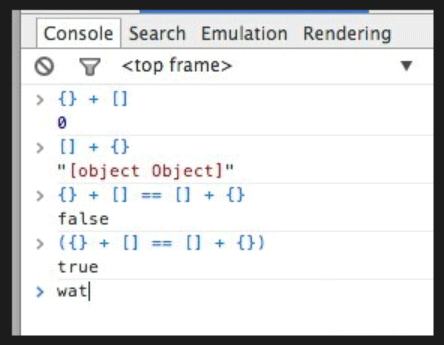
À ce stade, tout le monde devrait avoir une idée de base de l'étrange traitement de {}. Revenons sur les phrases évoquées en début d'article :
Deuxièmement, puisque {} n'est pas au début de l'instruction, il s'agit d'une quantité directe d'objet normal. Le tableau vide et l'objet vide sont ajoutés directement et "[object Object]" est renvoyé.
Compris les premier et deuxième éléments, le troisième élément n'a plus besoin d'explication.
Le quatrième, parce qu'il commence par (), le premier {} est analysé comme un objet littéral, donc les deux formules sont égales et renvoient vrai.
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



