


Comment créer un programme front-end Web efficace est une question que je réfléchis inconsciemment à chaque fois que je fais du développement front-end. Il y a quelques années, les formidables ingénieurs front-end de Yahoo ont publié un livre sur l'amélioration des performances du front-end Web, qui a fait sensation dans l'ensemble de la communauté technologique du développement Web. Le mystérieux problème d'optimisation du front-end Web est devenu un problème courant sur le marché. Street et l'optimisation frontale du Web sont devenues des questions simples auxquelles les débutants et les experts peuvent répondre. Lorsque l'ensemble du secteur connaît la réponse secrète choquante, la technologie d'optimisation existante ne peut plus produire un saut qualitatif dans le site Web que vous développez. rendre le site Web que nous développons plus performant que les autres Pour améliorer notre site Web, nous devons réfléchir plus profondément de manière indépendante et réserver de meilleures compétences.
Le système d'événements en Javascript est le premier point révolutionnaire qui me vient à l'esprit. Pourquoi s'agit-il d'un système d'événements JavaScript ? Nous savons tous que le front-end Web comprend trois technologies : html, css et javascript. La manière dont html et css sont combinés est très claire : style, class, id et balises html. Il n'y a pas grand chose à dire à ce sujet, mais comment. javascript se place-t-il au milieu du html et du css, que diriez-vous d'intégrer les trois ? Enfin, j'ai découvert que ce point d'entrée est le système d'événements de JavaScript. Peu importe la longueur ou la complexité du code JavaScript que nous écrivons, il finira par être reflété en HTML et CSS via le système d'événements. est le point d'entrée pour l'intégration des trois points, alors il y aura inévitablement un grand nombre d'opérations d'événements dans une page, en particulier dans les pages Web de plus en plus complexes d'aujourd'hui, sans ces événements, notre code javascript soigneusement écrit ne sera stocké que dans le base de données, et le héros sera inutile. Puisqu'il y aura un grand nombre de fonctions événementielles sur la page, y aura-t-il des problèmes affectant l'efficacité si nous écrivons des fonctions événementielles selon nos habitudes ? La réponse que j'ai recherchée est qu'il existe un véritable problème d'efficacité, et qu'il s'agit également d'un grave problème d'efficacité.
Afin d'expliquer clairement ma réponse, je dois d'abord expliquer le système d'événements JavaScript en détail.
Le système d'événements est le point d'entrée pour l'intégration de javascript, html et css. Ce point d'entrée est comme la fonction principale de Java. Alors, comment le navigateur complète-t-il cette entrée ? J'ai recherché un total de 3 façons, ce sont :
Méthode 1 : traitement des événements HTML
Le traitement des événements HTML consiste à écrire la fonction d'événement directement dans la balise html. Parce que cette méthode d'écriture est étroitement couplée à la balise html, elle est appelée traitement d'événements html. Par exemple, le code suivant :
Si la fonction d'événement click est compliquée, écrire le code comme celui-ci causera certainement des désagréments, nous écrivons donc souvent la fonction en externe, et onclick appelle directement le nom de la fonction, par exemple :
La méthode d'écriture ci-dessus est une très belle méthode d'écriture, donc beaucoup de gens l'utilisent encore inconsciemment de nos jours, mais peut-être que beaucoup de gens ne savent pas que cette dernière méthode d'écriture n'est en fait pas aussi robuste que la première. Il n'y a pas longtemps. Problèmes rencontrés lors de l'étude de la technologie des scripts de chargement non bloquants, car selon le principe de l'optimisation front-end, le code javascript se situe souvent en bas de page. Lorsque la page est bloquée par des scripts, les fonctions référencées. dans la balise html n'a peut-être pas encore été exécuté. À ce moment-là, lorsque nous cliquons sur le bouton de la page, le résultat sera "Erreur non définie de la fonction XXX". En JavaScript, ces erreurs seront capturées par try and catch. pour rendre le code plus robuste, nous allons le réécrire comme suit :
En voyant le code ci-dessus, je ne peux pas décrire à quel point c'est dégoûtant.
Méthode 2 : traitement des événements DOM niveau 0
Le traitement des événements au niveau DOM0 est un traitement des événements pris en charge par tous les navigateurs aujourd'hui. Il n'y a aucun problème de compatibilité. Voir une telle phrase enthousiasmera tous ceux qui travaillent sur le front-end Web. Les règles de traitement des événements DOM0 sont les suivantes : chaque élément DOM possède son propre attribut de traitement d'événements, auquel peut être attribué une fonction, comme le code suivant :
Regardez à nouveau le code suivant :
Troisième méthode : traitement des événements DOM2 et traitement des événements IE
Le traitement des événements DOM2 est une solution de traitement des événements standardisée, mais le navigateur IE a développé son propre ensemble. Les fonctions sont similaires au traitement des événements DOM2, mais le code est différent.
Avant d'expliquer la troisième méthode, je dois ajouter quelques concepts, sinon je ne pourrai pas expliquer clairement la connotation de la troisième méthode.Le premier concept est : le flux des événements
Dans le développement de pages, nous rencontrons souvent une telle situation. La zone de travail d'une page peut être représentée par un document en JavaScript. Il y a un div dans la page. Le div équivaut à couvrir l'élément de document. un élément bouton dans le div. L'élément bouton couvre le div, ce qui équivaut également à couvrir le document, donc le problème est que lorsque nous cliquons sur le bouton, le comportement de clic ne se produit pas seulement sur le bouton, mais l'opération de clic est appliqué à la fois au div et au document. Ces trois éléments de logique peuvent déclencher des événements de clic, et le flux d'événements est le concept qui décrit le scénario ci-dessus : l'ordre dans lequel les événements sont reçus de la page.
Le deuxième concept : le bouillonnement d'événements et la capture d'événements
Le bouillonnement d'événements est une solution proposée par Microsoft pour résoudre le problème de flux d'événements, tandis que la capture d'événements est une solution de flux d'événements proposée par Netscape. Leurs principes sont les suivants :
L'événement bouillonnant commence par le div, suivi du corps, et enfin du document. La capture de l'événement est inversée, avec le document d'abord, puis le corps, et enfin l'élément cible div. En comparaison, la solution de Microsoft est plus. conviviale Conformément aux habitudes de fonctionnement des gens, la solution de Netscape est très délicate. C'est la conséquence de la guerre des navigateurs. Netscape a été une étape trop lente pour résoudre le problème du flux d'événements avec un code qui sacrifiait les habitudes des utilisateurs. 
.
Après l'exécution, les deux boîtes de dialogue peuvent apparaître normalement. Cette méthode nous permet d'ajouter plusieurs événements de clic différents aux éléments DOM. Et si nous ne voulons pas d’événement ? Que devons-nous faire ? Internet Explorer fournit la méthode detachEvent pour supprimer des événements. La liste des paramètres est la même que celle de attachEvent. Si nous voulons supprimer un événement de clic, il nous suffit de transmettre les mêmes paramètres que l'événement d'ajout, comme indiqué. dans le code suivant :
Lorsque nous l'exécutons, les conséquences sont très graves. Nous sommes très confus. Le deuxième clic n'est pas supprimé. J'ai mentionné plus tôt que la suppression d'événements nécessite les mêmes paramètres que l'ajout d'événements, mais dans la fonction anonyme de JavaScript, même si le code des deux fonctions anonymes est exactement le même, JavaScript utilisera des variables différentes pour le stocker en interne. le phénomène que nous voyons ne peut pas être Supprimer l'événement de clic, notre code doit donc être écrit comme ceci :
La méthode d'ajout et la méthode de suppression pointent vers le même objet, donc l'événement est supprimé avec succès. La scène ici nous dit que nous devrions avoir de bonnes habitudes lors de l'écriture d'événements, c'est-à-dire que les fonctions opérationnelles doivent être définies indépendamment et ne pas utiliser de fonctions anonymes comme habitude.
L'étape suivante est le traitement des événements DOM2. Son principe est présenté dans la figure ci-dessous :
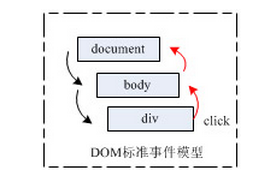
DOM2 est un événement standardisé. En utilisant les événements DOM2, la transmission des événements commence d'abord à partir de la méthode de capture, c'est-à-dire du document, vers le corps. Le div est un point intermédiaire. Lorsque l'événement atteint le point intermédiaire, l'événement. est dans l'étape cible, et l'événement entre dans l'étape cible. Après cela, l'événement commence à bouillonner et finalement l'événement se termine sur le document. (Le point de départ de l'événement de capture et le point final de l'événement de bouillonnement sont tous pointés vers le document. La situation réelle est que certains navigateurs commenceront la capture à partir de la fenêtre et mettront fin au bouillonnement. Cependant, je pense que peu importe la façon dont le le navigateur lui-même est défini pendant le développement, nous prêtons attention au document est plus significatif pour le développement, j'utilise donc toujours le document ici). Les gens ont l'habitude de classer l'étape cible comme faisant partie du bouillonnement, principalement parce que les événements de bouillonnement sont plus largement utilisés dans le développement.
Le traitement des événements DOM2 est très gênant. Chaque fois qu'un événement est déclenché, tous les éléments seront parcourus deux fois. Par rapport aux événements IE, les performances d'IE ne sont que des bulles, donc IE n'a besoin de parcourir qu'une seule fois, mais la traversée. Son absence ne signifie pas que le système d'événements d'IE est plus efficace du point de vue du développement et de la conception, la prise en charge des deux systèmes d'événements apportera une plus grande flexibilité à notre développement. De ce point de vue, les événements DOM2 sont toujours très prometteurs. Le code de l'événement DOM2 est le suivant :
Pour ajouter des événements dans le traitement des événements DOM2, addEventListener est utilisé. Il reçoit trois paramètres et un de plus que le traitement des événements ie. Les deux premiers ont la même signification que les deux paramètres de la méthode de traitement des événements ie. premier paramètre. Le préfixe on doit être supprimé. Le troisième paramètre est une valeur booléenne. Si sa valeur est vraie, alors l'événement sera traité selon la méthode de capture. Si la valeur est fausse, l'événement sera traité selon. bouillonnant. Avec le troisième paramètre, nous pouvons comprendre pourquoi l'élément événementiel doit être exécuté deux fois dans le traitement des événements DOM2. Le but est d'être compatible avec les deux modèles d'événements. Cependant, veuillez noter ici que peu importe que nous choisissions de capturer ou de créer des bulles. deux traversées seront effectuées pour toujours.Si nous choisissons une méthode de traitement d'événement, alors aucune fonction de traitement d'événement ne sera déclenchée dans un autre processus de traitement d'événement, ce qui est le même qu'une voiture qui tourne au ralenti au point mort. Grâce à la conception de la méthode d'événement DOM2, nous savons que les événements DOM2 ne peuvent exécuter qu'une des deux méthodes de traitement d'événement au moment de l'exécution. Il est donc impossible que deux systèmes de flux d'événements se déclenchent en même temps, même si l'élément est traversé deux fois. , la fonction événementielle ne sera jamais déclenchée deux fois. Notez que lorsque je dis non déclenchée deux fois, cela fait référence à une fonction événementielle. En fait, on peut simuler l'exécution simultanée de deux modèles de flux d'événements, comme le code suivant : <.>
DOM2 fournit également une fonction pour supprimer des événements. Cette fonction est removeEventListener, qui s'écrit comme suit :
Exécutez-le et constatez que l'événement n'a pas été supprimé avec succès.
La dernière chose que je veux dire est que le traitement des événements DOM2 est bien pris en charge dans ie9, y compris les événements ie9 et supérieurs ne sont pas pris en charge sous ie8.
Comparons les trois méthodes événementielles comme suit :
Comparaison 1 : La méthode 1 est comparée aux deux autres méthodes
La méthode 1 est écrite en combinant HTML et JavaScript. Il y a moi en vous et vous en moi. Pour approfondir cette méthode, c'est le développement mixte de HTML et JavaScript Exprimé dans un terme logiciel, c'est le couplage de code. Ce n'est pas bon, et c'est très mauvais. C'est le niveau d'un programmeur débutant, donc la première méthode est complètement vaincue et les deux autres méthodes sont complètement vaincues.
Comparaison 2 : Méthode 2 et Méthode 3
Les deux méthodes d'écriture sont similaires. Parfois, il est vraiment difficile de dire laquelle est la meilleure et laquelle est la pire. En regardant le contenu ci-dessus, nous constatons que la plus grande différence entre la méthode deux et la méthode trois est : lors de l'utilisation de la méthode. Deuxièmement, un élément DOM peut avoir un certain événement et une seule fois.La troisième méthode permet à un certain événement d'un élément DOM d'avoir plusieurs fonctions de traitement d'événements.Dans le traitement des événements DOM2, la troisième méthode nous permet également de contrôler avec précision le flux des événements. la méthode trois est plus puissante que la méthode deux, donc en comparaison, la méthode trois est légèrement meilleure.
Ce qui suit est le sujet de cet article : le problème de performances du système d'événements. Pour résoudre le problème de performances, nous devons trouver un point central. Ici, je réfléchis aux problèmes de performances du système d'événements à partir de deux points centraux. : réduisant le nombre de parcours et la consommation de mémoire.
Le premier est le nombre de parcours. Qu'il s'agisse d'un flux d'événements de capture ou d'un flux d'événements bouillonnants, les éléments seront parcourus, mais le parcours commencera à partir de la fenêtre supérieure ou du document s'il existe une relation parent-enfant entre les éléments. La page des éléments DOM est profonde, alors la traversée sera plus grande. Plus il y a d'éléments, comme le traitement des événements DOM2, plus le danger de traversée est grand. Comment résoudre ce problème de traversée du flux d'événements ? Ma réponse est non. Certains amis ici peuvent avoir des questions, comment se fait-il qu'il n'y en ait plus ? Il existe un objet événement dans le système d'événements, qui est événement. Cet objet a des méthodes pour empêcher la diffusion ou la capture d'événements. Comment puis-je dire que ce n'est pas le cas ? La question de cet ami est très raisonnable, mais si nous voulons utiliser cette méthode pour réduire le parcours, alors notre code doit gérer la relation entre les éléments parent et enfant, et la relation entre les éléments grand-père et petit-fils s'il y a de nombreux éléments imbriqués sur le. page, c'est une tâche impossible. Donc ma réponse est que vous ne pouvez pas changer le problème de traversée, vous pouvez seulement vous y adapter.
Il semble que la réduction des traversées ne puisse pas résoudre le problème de performances du système d'événements, donc maintenant la seule considération est la consommation de mémoire. J'entends souvent les gens dire que C# est facile à utiliser, mais qu'il est encore meilleur pour le développement web front-end. Nous pouvons directement faire glisser un bouton vers la page dans l'IDE C#. Une fois que le bouton atteint la page, le code javascript sera automatiquement affiché. ajoutez un événement au bouton. Bien sûr, la fonction d'événement à l'intérieur est une fonction vide, j'ai donc pensé que nous pourrions placer 100 boutons sur la page de cette manière, sans même un seul code, nous aurions 100 gestionnaires d'événements de boutons, ce qui est super. pratique. Enfin, nous avons ajouté un bouton spécifique à l'un des boutons permettant à la page de s'exécuter. En JavaScript, chaque fonction est un objet, et chaque objet consomme de la mémoire, donc ces 99 codes de fonction d'événement inutiles doivent consommer beaucoup de mémoire précieuse du navigateur. Bien sûr, nous ne ferions pas cela dans un environnement de développement réel, mais à l'ère d'aujourd'hui où ajax est populaire et où le développement sur une seule page est très populaire, il y a tellement d'événements sur une page Web, ce qui signifie que chacun de nos événements a un fonction d'événement. Mais chaque opération que nous effectuons ne déclenchera qu'un seul événement. À ce moment-là, d'autres événements se couchent et dorment, ce qui n'a aucun effet et consomme la mémoire de l'ordinateur.
Nous avons besoin d'une solution pour changer cette situation, et une telle solution existe effectivement dans la réalité. Afin de décrire clairement cette solution, je dois d'abord ajouter quelques connaissances de base. Lors de la description du traitement des événements DOM2, j'ai mentionné le concept d'objet cible. En mettant de côté la méthode de traitement des événements DOM2, il existe également le concept d'objet cible dans l'événement de capture. traitement et traitement des événements bouillonnants. , l'objet cible est l'élément DOM de l'opération spécifique de l'événement. Par exemple, dans une opération de clic sur un bouton, le bouton est l'objet cible, quelle que soit la méthode de traitement de l'événement, la fonction événementielle contiendra. un objet événement. L'objet événement a un attribut target, et la cible pointe toujours vers l'objet cible. L'objet événement a également une propriété appelée currentTarget, qui pointe vers l'élément DOM vers lequel l'événement capturé ou bouillonnant circule. D'après la description ci-dessus, nous savons que qu'il s'agisse d'un événement de capture ou d'un événement bouillonnant, le flux d'événements circulera vers le document. Si nous ajoutons un événement de clic au document, le bouton sur la page n'ajoute pas d'événement de clic. À ce moment-là, nous cliquons sur le bouton et nous savons que l'événement de clic sur le document sera déclenché. Un détail ici est que lorsque l'événement de clic sur le document est déclenché, la cible de l'événement est le bouton au lieu du document. peut écrire le code comme ceci :
Lorsque nous l'exécutons, nous constatons que l'effet est le même que si nous avions écrit l'événement du bouton séparément. Mais ses avantages sont évidents : une fonction gère les fonctions événementielles de la page entière, et aucune fonction événementielle n'est inactive. Cette solution a aussi un nom professionnel : délégation d'événements. La méthode déléguée de jQuery est basée sur ce principe. En fait, l'efficacité de la délégation d'événements ne se reflète pas seulement dans la réduction des fonctions d'événement, elle peut également réduire les opérations de traversée du DOM. Par exemple, dans l'exemple ci-dessus, nous ajoutons des fonctions au document. dans la page, et l'efficacité de sa lecture est très élevée, lorsqu'il s'agit d'événements d'objet spécifiques, nous n'utilisons pas d'opérations DOM mais utilisons l'attribut target de l'objet événement. Tout cela ne peut être résumé qu'en une seule phrase : C'est vraiment rapide, tellement rapide sans raison.
La délégation d'événements peut également nous apporter un excellent sous-produit. Les amis qui ont utilisé jQuery auraient dû utiliser la méthode live. La fonctionnalité de la méthode live est que vous pouvez ajouter des opérations d'événement aux éléments de la page, même si cet élément ne le fait pas. existe actuellement sur la page, vous pouvez également ajouter ses événements. Après avoir compris le mécanisme de délégation d'événements, le principe du live est facile à comprendre. En fait, le live de jQuery se fait via la délégation d'événements, et live est également un moyen efficace d'ajouter. événements.
Après avoir compris la délégation d'événements, nous constaterons que la méthode bind de jQuery est une méthode inefficace car elle utilise la méthode de définition d'événement d'origine, nous devons donc utiliser bind avec prudence. En fait, les développeurs de jQuery ont également remarqué ce problème. Il existe une méthode on dans jQuery. La méthode on inclut toutes les fonctions des méthodes bind, live et délégué, je suggère donc aux amis qui lisent cet article d'abandonner la méthode précédente d'ajout d'événements et d'utiliser la fonction on pour ajouter des événements.
La délégation d'événements a un autre avantage. Dans l'exemple de délégation d'événements ci-dessus, j'ai ajouté des événements au document. Ici, je veux faire une comparaison. Dans jQuery, nous avons l'habitude de mettre la définition des événements des éléments DOM dans la méthode ready. , comme suit Montré :
La fonction ready est exécutée après le chargement du document DOM de la page. Elle est exécutée avant la fonction onload. Cet avantage précoce présente de nombreux avantages. L'un des avantages est l'amélioration des performances, comme jQuery. Je crois que certains amis ont dû mettre certaines liaisons d'événements à l'extérieur et ont finalement découvert que le bouton serait invalide. Cette situation invalide dure parfois un moment, puis elle s'améliore. Par conséquent, nous ignorons souvent le principe de ce problème et le faisons. Ne le liez pas à la fonction ready Event, cette opération consiste en fait à lier l'événement avant le chargement du DOM. Pendant cette période, il est très probable que certains éléments n'aient pas été construits sur la page, donc la liaison d'événement sera. invalide. Par conséquent, le principe de la définition d'événements prêts est de s'assurer que l'événement de l'élément DOM est défini après le chargement de tous les éléments de la page. Cependant, les problèmes peuvent être évités lors de l'utilisation de la délégation d'événement, par exemple en liant l'événement au document. représente la page entière, donc l'heure à laquelle elle est chargée est la plus ancienne, donc dans le document En implémentant la délégation d'événement, il est difficile que l'événement soit invalide, et il est également difficile pour le navigateur de signaler « La fonction XXX n'est pas défini". Pour résumer cette fonctionnalité : le code de délégation d'événements peut s'exécuter à n'importe quelle étape du chargement de la page, ce qui offrira aux développeurs une plus grande liberté pour améliorer les performances des pages Web ou améliorer les effets des pages Web.
J’ai maintenant fini d’écrire cet article. Bonne nuit.
 Les avantages du trading OTC
Les avantages du trading OTC
 attributusage
attributusage
 Quelle est la différence entre passer par valeur et passer par référence en Java
Quelle est la différence entre passer par valeur et passer par référence en Java
 Comment faire fonctionner json avec jquery
Comment faire fonctionner json avec jquery
 Comment éliminer le code HTML
Comment éliminer le code HTML
 Win7 indique que les données de l'application ne sont pas accessibles. Solution.
Win7 indique que les données de l'application ne sont pas accessibles. Solution.
 Outils de gestion MySQL couramment utilisés
Outils de gestion MySQL couramment utilisés
 comment créer un site Web
comment créer un site Web








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



