


Recommendation systems are important to address the challenge of information overload as they provide customized recommendations based on users’ personal preferences. In recent years, deep learning technology has greatly promoted the development of recommendation systems and improved insights into user behavior and preferences.
However, traditional supervised learning methods face challenges in practical applications due to data sparsity issues, which limits their ability to effectively learn user performance.
To protect and overcome this problem, self-supervised learning (SSL) technology is applied to students, which uses the inherent structure of the data to generate supervision signals and does not rely entirely on labeled data.
This method uses a recommendation system that can extract meaningful information from unlabeled data and make accurate predictions and recommendations even when data is scarce.

Article address: https://arxiv.org/abs/2404.03354
Open source database : https://github.com/HKUDS/Awesome-SSLRec-Papers
Open source code base: https://github.com/HKUDS/SSLRec
This article reviews self-supervised learning frameworks designed for recommender systems and conducts an in-depth analysis of more than 170 related papers. We explored nine different application scenarios to gain a comprehensive understanding of how SSL can enhance recommendation systems in different scenarios.
For each domain, we discuss different self-supervised learning paradigms in detail, including contrastive learning, generative learning, and adversarial learning, showing how SSL can improve recommendation systems in different situations. performance.
The research on recommender system covers various tasks in different scenarios, such as collaborative filtering and sequence recommendation and multi-behavior recommendations, etc. These tasks have different data paradigms and goals. Here, we first provide a general definition without going into specific variations for different recommendation tasks. In the recommendation system, there are two main sets: the user set, denoted as 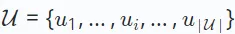 , and the item set, denoted as
, and the item set, denoted as 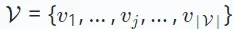 .
.
Then, use an interaction matrix 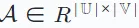 to represent the recorded interactions between the user and the item. In this matrix, the entry Ai,j of the matrix is assigned the value 1 if the user ui has interacted with the item vj, otherwise it is 0.
to represent the recorded interactions between the user and the item. In this matrix, the entry Ai,j of the matrix is assigned the value 1 if the user ui has interacted with the item vj, otherwise it is 0.
The definition of interaction can be adapted to different contexts and data sets (e.g., watching a movie, clicking on an e-commerce site, or making a purchase).
In addition, in different recommendation tasks, there are different auxiliary observation data, recorded as X. For example, in knowledge graph enhanced recommendation, X contains the knowledge graph containing external item attributes. , these attributes include different entity types and corresponding relationships.
In social recommendation, X includes user-level relationships, such as friendship. Based on the above definition, the recommendation model optimizes a prediction function f(⋅), aiming to accurately estimate the preference score between any user u and item v:
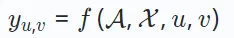
The preference score yu,v represents the possibility of user u interacting with item v.
Based on this score, the recommendation system can recommend uninteracted items to each user by providing a ranked list of items based on the estimated preference score. In the review, we further explore the data form of (A,X) in different recommendation scenarios and the role of self-supervised learning in it.
In the past few years, deep neural networks have performed well in supervised learning, which has been widely used in fields including computer vision, natural language processing and recommendation systems. It is reflected in all fields. However, due to its heavy reliance on labeled data, supervised learning faces challenges in dealing with label sparsity, which is also a common problem in recommender systems.
To address this limitation, self-supervised learning emerged as a promising method, which utilizes the data itself as labels for learning. Self-supervised learning in recommender systems includes three different paradigms: contrastive learning, generative learning, and adversarial learning.
##Contrastive Learning as a A prominent self-supervised learning method whose main goal is to maximize the consistency between different views enhanced from the data. In contrastive learning for recommender systems, the goal is to minimize the following loss function:
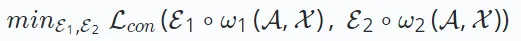
E∗∘ω∗ represents the comparison view creation operation. Different recommendation algorithms based on contrastive learning have different creation processes. The construction of each view consists of a data augmentation process ω∗ (which may involve nodes/edges in the augmented graph) and an embedding encoding process E∗.
The goal of minimization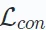 is to obtain a robust encoding function that maximizes the consistency between views. This consistency across views can be achieved through methods such as mutual information maximization or instance discrimination.
is to obtain a robust encoding function that maximizes the consistency between views. This consistency across views can be achieved through methods such as mutual information maximization or instance discrimination.
The goal of generative learning It is about understanding the structure and patterns of data to learn meaningful representations. It optimizes a deep encoder-decoder model that reconstructs missing or corrupted input data.
The encoder 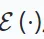 creates a latent representation from the input, while the decoder
creates a latent representation from the input, while the decoder 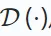 reconstructs the original data from the encoder output. The goal is to minimize the difference between the reconstructed and original data as follows:
reconstructs the original data from the encoder output. The goal is to minimize the difference between the reconstructed and original data as follows:
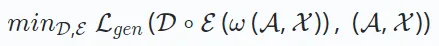
Here, ω represents operations such as masking or perturbation. D∘E represents the process of encoding and decoding to reconstruct the output. Recent research has also introduced a decoder-only architecture that efficiently reconstructs data without an encoder-decoder setup. This approach uses a single model (e.g., Transformer) for reconstruction and is typically applied to serialized recommendations based on generative learning. The format of the loss function 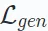 depends on the data type, such as mean square error for continuous data and cross-entropy loss for categorical data.
depends on the data type, such as mean square error for continuous data and cross-entropy loss for categorical data.
Adversarial learning is a training method that uses the generator G (⋅) generates high-quality output and contains a discriminator Ω(⋅) that determines whether a given sample is real or generated. Unlike generative learning, adversarial learning differs by including a discriminator that uses competitive interactions to improve the generator's ability to produce high-quality output in order to fool the discriminator.
Therefore, the learning goal of adversarial learning can be defined as follows:
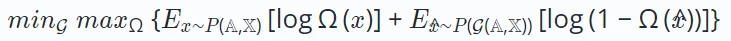
Here, the variable x represents the real sample obtained from the underlying data distribution, while  represents the one generated by the generator G(⋅) Synthetic samples. During training, both the generator and the discriminator improve their capabilities through competitive interactions. Ultimately, the generator strives to produce high-quality outputs that are beneficial for downstream tasks.
represents the one generated by the generator G(⋅) Synthetic samples. During training, both the generator and the discriminator improve their capabilities through competitive interactions. Ultimately, the generator strives to produce high-quality outputs that are beneficial for downstream tasks.
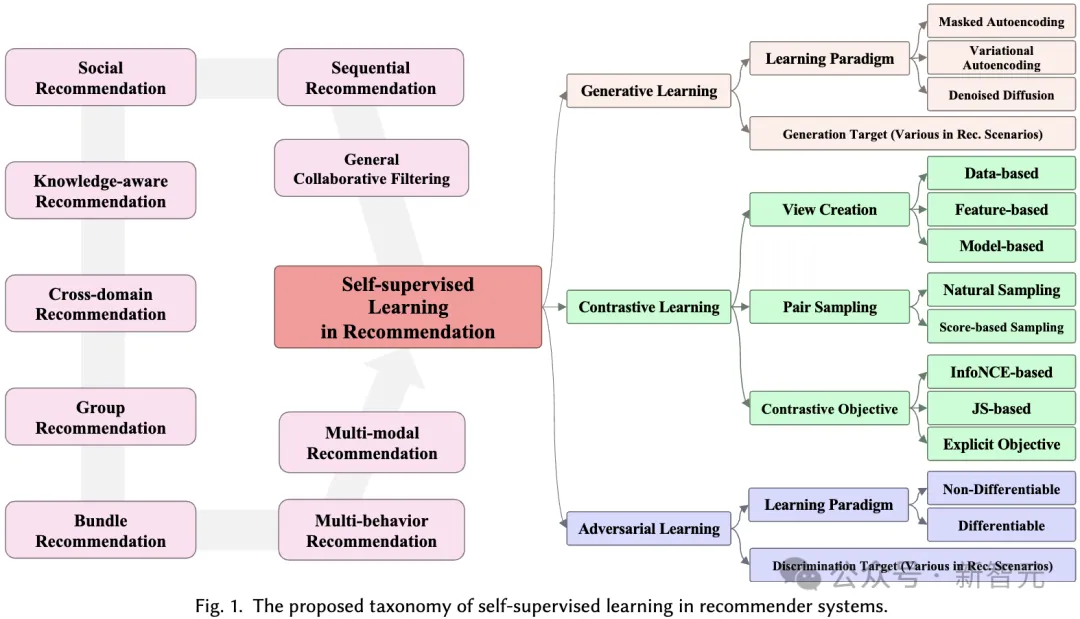
In this section, we propose the application of self-supervised learning in recommendation systems comprehensive classification system. As mentioned before, self-supervised learning paradigms can be divided into three categories: contrastive learning, generative learning, and adversarial learning. Therefore, our classification system is built based on these three categories, providing deeper insights into each category.
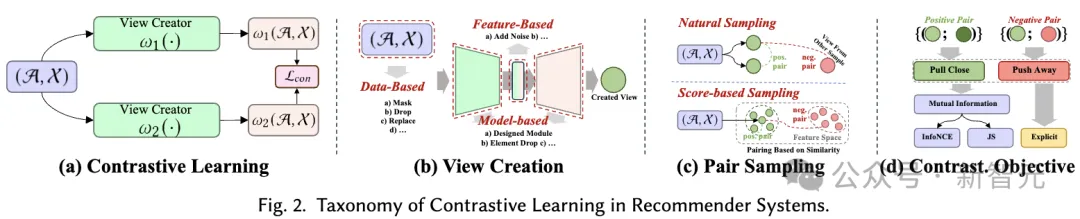
##The basic principle of contrastive learning (CL) is to maximize the consistency between different views. Therefore, we propose a view-centric taxonomy consisting of three key components to consider when applying contrastive learning: creating views, pairing views to maximize consistency, and optimizing consistency.
View Creation. Create views that emphasize the various aspects of the data that the model focuses on. It can combine global collaborative information to improve the recommendation system's ability to handle global relationships, or introduce random noise to enhance the robustness of the model.
We consider the enhancement of input data (e.g., graphs, sequences, input features) as view creation at the data level, while the enhancement of latent features during inference is regarded as the feature level View creation. We propose a hierarchical classification system that includes view creation techniques from the basic data level to the neural model level.
Pair Sampling. The view creation process generates at least two different views for each sample in the data. The core of contrastive learning is to maximize the alignment of certain views (i.e., bring them closer) while pushing other views away.
To do this, the key is to identify the positive sample pairs that should be brought closer, and identify other views that form negative sample pairs. This strategy is called paired sampling, which mainly consists of two paired sampling methods:
Contrastive Objective. The learning goal in contrastive learning is to maximize the mutual information between pairs of positive samples, which in turn can improve the performance of the learning recommendation model. Since it is not feasible to directly calculate mutual information, a feasible lower bound is usually used as the learning target in contrastive learning. However, there are also explicit goals of bringing positive pairs closer together.

In generative self-supervised learning, the main goal is to maximize the likelihood estimate of the real data distribution. This allows the learned, meaningful representations to capture the underlying structure and patterns in the data, which can then be used in downstream tasks. In our classification system, we consider two aspects to distinguish different generative learning-based recommendation methods: generative learning paradigm and generative goal.
Generative Learning Paradigm. In the context of recommendation, self-supervised methods employing generative learning can be classified into three paradigms:
#Generation Target. In generative learning, which pattern of data is considered as a generated label is another issue that needs to be considered to bring meaningful auxiliary self-supervised signals. In general, the generation goals vary for different methods and in different recommendation scenarios. For example, in sequence recommendation, the generation target can be the items in the sequence, with the purpose of simulating the relationship between items in the sequence. In interactive graph recommendation, the generation targets can be nodes/edges in the graph, aiming to capture high-level topological correlations in the graph.
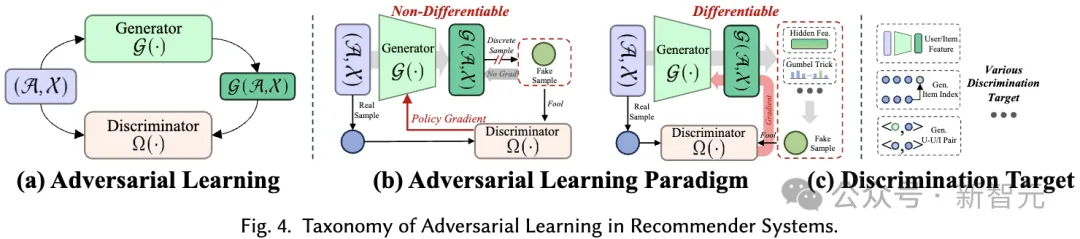
##In In adversarial learning of recommendation systems, the discriminator plays a crucial role in distinguishing generated false samples from real samples. Similar to generative learning, the classification system we propose covers adversarial learning methods in recommender systems from two perspectives: learning paradigm and discrimination goal:
Adversarial Learning Paradigm (Adversarial Learning Paradigm). In recommender systems, adversarial learning consists of two different paradigms, depending on whether the discriminative loss of the discriminator can be back-propagated to the generator in a differentiable manner.
Discrimination Target. Different recommendation algorithms cause the generator to generate different inputs, which are then fed to the discriminator for discrimination. This process aims to enhance the generator's ability to produce high-quality content that is closer to reality. Specific discrimination goals are designed based on specific recommendation tasks.
In this review, we An in-depth discussion of the design methods of different self-supervised learning methods from nine different recommendation scenarios. These nine recommendation scenarios are as follows (please read the article for details):
This article provides a comprehensive review of the application of self-supervised learning (SSL) in recommendation systems. More than 170 papers were analyzed. We proposed a self-supervised classification system covering nine recommendation scenarios, discussed three SSL paradigms of contrastive learning, generative learning and adversarial learning in detail, and discussed future research directions in the article.
We emphasize the importance of SSL in handling data sparsity and improving recommendation system performance, and point out the integration of large language models into recommendation systems, adaptive dynamic recommendation environments, and Potential research directions such as establishing a theoretical foundation for the SSL paradigm. We hope that this review can provide valuable resources for researchers, inspire new research ideas, and promote the further development of recommendation systems.
The above is the detailed content of Reviewing 170 'self-supervised learning' recommendation algorithms, HKU releases SSL4Rec: the code and database are fully open source!. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



