At the Zhongguancun Forum General Artificial Intelligence Parallel Forum held on April 27, Sophon Engine, a start-up company from the Renmin University Department of Science and Technology, grandly released the new multi-modal large model Awaker 1.0, which is a crucial step towards AGI. step. Compared with the ChatImg sequence model of the previous generation of Sophon engine, Awaker 1.0 adopts a new MOE architecture and has the ability to update independently. It is the first in the industry to achieve "true" independent update. Multimodal large models. In terms of visual generation, Awaker 1.0 uses a completely self-developed video generation base VDT, which achieves better results than Sora in photo video generation, breaking the "last step" of large models. Kilometers" is difficult to land. 
Awaker 1.0 is a large multi-modal model that super-integrates visual understanding and visual generation. On the understanding side, Awaker 1.0 interacts with the digital world and the real world, and feeds scene behavior data back to the model during task execution to achieve continuous updating and training; on the generation side, Awaker 1.0 can generate high-quality multi-modal images. Content, simulate the real world, and provide more training data for the understanding side model. What’s particularly important is that, because of its “real” autonomous update capabilities, Awaker 1.0 is suitable for a wider range of industry scenarios and can solve more complex practical tasks, such as AI Agent, embodied intelligence, comprehensive management, security inspection, etc. 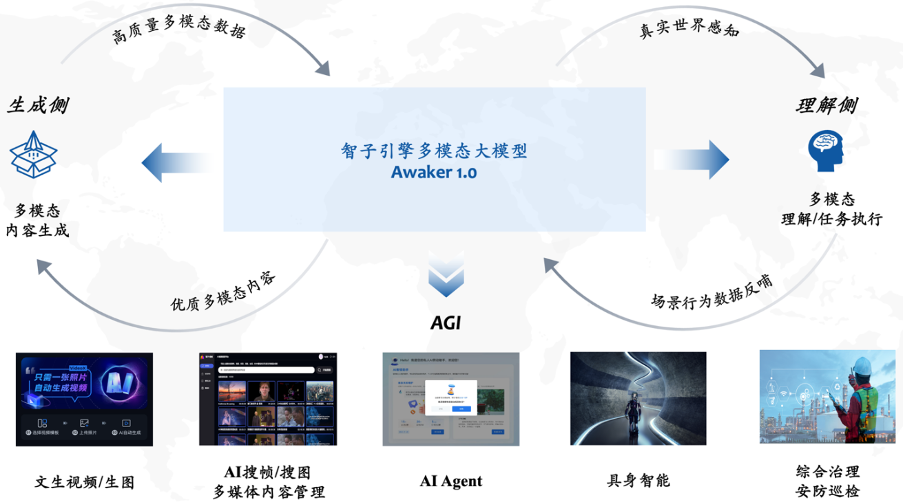
On the understanding side, the base of Awaker 1.0 The seat model mainly solves the problem of serious conflicts in multi-modal and multi-task pre-training. Benefiting from the carefully designed multi-task MOE architecture, the base model of Awaker 1.0 can not only inherit the basic capabilities of the Sophon Engine's previous generation multi-modal large model ChatImg, but also learn the unique capabilities required for each multi-modal task. Compared with the previous generation multi-modal large model ChatImg, the base model capabilities of Awaker 1.0 have been greatly improved in multiple tasks. In view of the problem of evaluation data leakage in mainstream multi-modal evaluation lists, we adopt strict standards to build our own evaluation set, in which most of the test images come from Personal mobile photo album. In this multi-modal evaluation set, we conduct fair manual evaluation on Awaker 1.0 and the three most advanced multi-modal large models at home and abroad. The detailed evaluation results are shown in the table below. Note that GPT-4V and Intern-VL do not directly support detection tasks. Their detection results are obtained by requiring the model to use language to describe the object orientation. 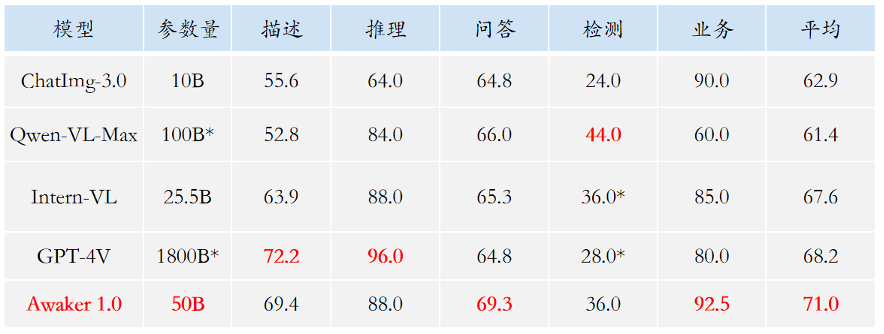
We found that the base model of Awaker 1.0 surpassed GPT-4V, Qwen-VL-Max and Intern-VL in visual question answering and business application tasks. At the same time, it Second-best results were also achieved on description, inference, and detection tasks. Overall, the average score of Awaker 1.0 exceeds the three most advanced models at home and abroad, verifying the effectiveness of the multi-task MOE architecture. Below are several specific examples of comparative analysis. 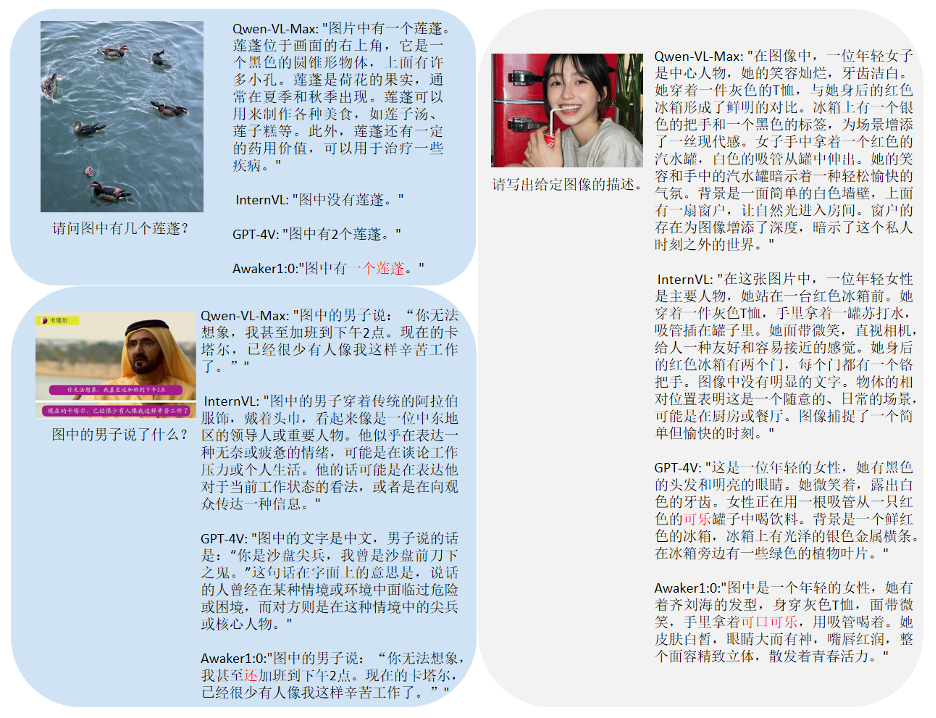
As can be seen from these comparative examples, Awaker 1.0 can give correct answers to counting and OCR questions, while the other three models all answer incorrectly (or partially incorrectly). In the detailed description task, Qwen-VL-Max is more prone to hallucinations, and Intern-VL can accurately describe the content of the picture but is not accurate and specific enough in some details. GPT-4V and Awaker 1.0 can not only describe the content of the image in detail, but also accurately identify the details in the image, such as Coca-Cola shown in the picture. Awaker Embodied Intelligence: Towards AGI
Multimodality The combination of large models and embodied intelligence is very natural, because the visual understanding capabilities of multi-modal large models can be naturally combined with the cameras of embodied intelligence. In the field of artificial intelligence, "multimodal large model embodied intelligence" is even considered a feasible path to achieve general artificial intelligence (AGI).
On the one hand, people expect embodied intelligence to be adaptable, that is, the agent can adapt to changing application environments through continuous learning, and can perform tasks in known multi-modal tasks. It gets better and better, and can quickly adapt to unknown multi-modal tasks.
On the other hand, people also expect embodied intelligence to be truly creative, hoping that it can discover new strategies and solutions through autonomous exploration of the environment, and explore The boundaries of artificial intelligence capabilities. By using multimodal large models as the “brains” of embodied intelligence, we have the potential to dramatically increase the adaptability and creativity of embodied intelligence, ultimately approaching the threshold of AGI (or even achieving AGI).
However, existing large multi-modal models have two obvious problems: First, the model has a long iterative update cycle, which requires a lot of human and financial investment; Second, the training data of the model are all derived from existing data, and the model cannot continuously obtain a large amount of new knowledge. Although continuous new knowledge can also be injected through RAG and long context, the multi-modal large model itself does not learn these new knowledge, and these two remediation methods will also bring additional problems.
In short, the current large multi-modal models are not very adaptable in actual application scenarios, let alone creative, resulting in always failing when implemented in the industry. Various difficulties arise. 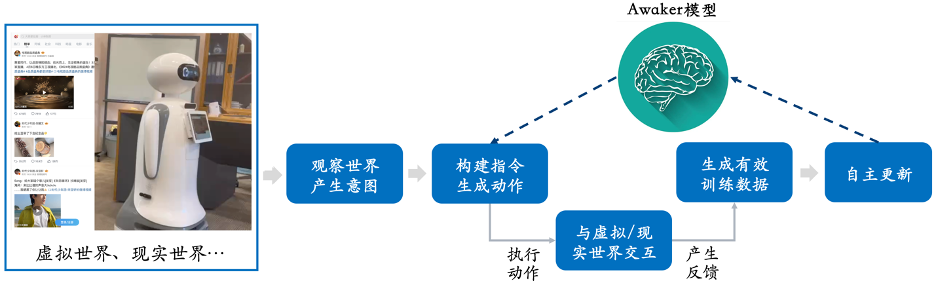 Awaker 1.0 released by Sophon Engine this time is the world's first multi-modal large model with an autonomous update mechanism, which can be used as the "brain" of embodied intelligence . The autonomous update mechanism of Awaker 1.0 includes three key technologies: active data generation, model reflection and evaluation, and continuous model update.
Awaker 1.0 released by Sophon Engine this time is the world's first multi-modal large model with an autonomous update mechanism, which can be used as the "brain" of embodied intelligence . The autonomous update mechanism of Awaker 1.0 includes three key technologies: active data generation, model reflection and evaluation, and continuous model update.
Different from all other large multi-modal models, Awaker 1.0 is "live" and its parameters can be continuously updated in real time.
As can be seen from the frame diagram above, Awaker 1.0 can be combined with various smart devices, observe the world through smart devices, generate action intentions, and automatically build command control Smart devices complete various actions. Smart devices will automatically generate various feedbacks after completing various actions. Awaker 1.0 can obtain effective training data from these actions and feedbacks for continuous self-updating, and continuously strengthen the various capabilities of the model.
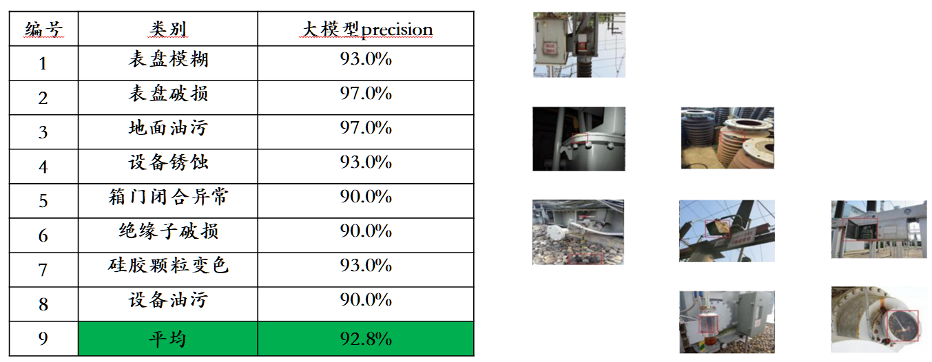
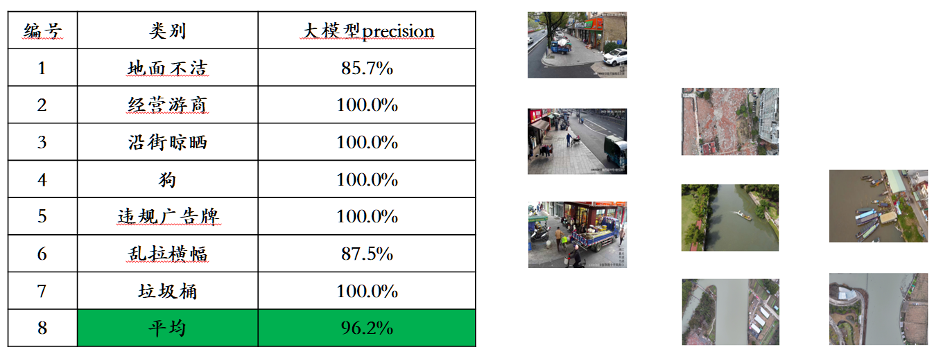
Taking the injection of new knowledge as an example, Awaker 1.0 can continuously learn the latest news information on the Internet and answer various complex questions based on the newly learned news information. Different from the traditional methods of RAG and long context, Awaker 1.0 can truly learn new knowledge and "memorize" the parameters of the model. As can be seen from the above example, in three consecutive days of self-updating, Awaker 1.0 can learn the news information of the day every day and accurately speak the corresponding information when answering questions. At the same time, Awaker 1.0 will not forget learned knowledge during the continuous learning process. For example, the knowledge of Wisdom S7 is still remembered or understood by Awaker 1.0 after 2 days. Awaker 1.0 can also be combined with various smart devices to achieve cloud-edge collaboration. Awaker 1.0 is deployed in the cloud as the "brain" to control various edge smart devices to perform various tasks. The feedback obtained when the edge smart device performs various tasks will be continuously transmitted back to Awaker 1.0, allowing it to continuously obtain training data and continuously update itself.  The above-mentioned technical route of cloud-edge collaboration has been applied in application scenarios such as intelligent inspection of power grids and smart cities, achieving recognition results that are far better than those of traditional small models, and has won the trust of industry customers. highly recognition.
The above-mentioned technical route of cloud-edge collaboration has been applied in application scenarios such as intelligent inspection of power grids and smart cities, achieving recognition results that are far better than those of traditional small models, and has won the trust of industry customers. highly recognition.
Real World Simulator: VDT# The generation side of ##Awaker 1.0 is a Sora-like video generation base VDT independently developed by Sophon Engine, which can be used as a real-world simulator. The research results of VDT were published on the arXiv website in May 2023, 10 months before OpenAI released Sora. VDT's academic paper has been accepted by ICLR 2024, the top international artificial intelligence conference.
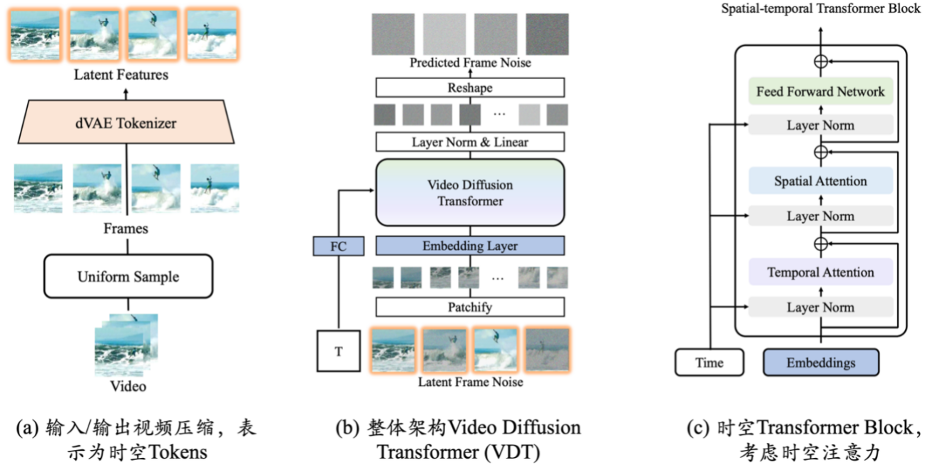
The innovation of video generation base VDT mainly includes the following aspects:
- Applying Transformer technology to diffusion-based video generation demonstrates the great potential of Transformer in the field of video generation. The advantage of VDT is its excellent time-dependent capture capability, enabling the generation of temporally coherent video frames, including simulating the physical dynamics of three-dimensional objects over time.
- Proposes a unified spatio-temporal mask modeling mechanism, enabling VDT to handle a variety of video generation tasks, realizing the wide application of this technology. VDT's flexible conditional information processing methods, such as simple token space splicing, effectively unify information of different lengths and modalities. At the same time, by combining with the spatiotemporal mask modeling mechanism, VDT has become a universal video diffusion tool, which can be applied to unconditional generation, video subsequent frame prediction, frame interpolation, picture-generating videos, and video frames without modifying the model structure. Completion and other video generation tasks.
We focused on exploring the simulation of simple physical laws by VDT and trained VDT on the Physion data set. In the example below, we find that VDT successfully simulates physical processes such as the ball moving along a parabolic trajectory and the ball rolling on a plane and colliding with other objects. At the same time, it can also be seen from the second example in line 2 that VDT captures the speed and momentum of the ball, because the ball ultimately did not knock down the pillar due to insufficient impact force. This proves that the Transformer architecture can learn certain physical laws.
 We also conducted in-depth exploration on the photo video generation task. This task has very high requirements on the quality of video generation, because we are naturally more sensitive to dynamic changes in faces and characters. Given the particularity of this task, we need to combine VDT (or Sora) and controllable generation to address the challenges of photo video generation. At present, Sophon engine has broken through most of the key technologies of photo video generation and achieved better photo video generation quality than Sora. Sophon engine will continue to optimize the controllable generation algorithm of portraits, and is also actively exploring commercialization. At present, a confirmed commercial landing scenario has been found, and it is expected to break the "last mile" difficulty of landing large models in the near future.
We also conducted in-depth exploration on the photo video generation task. This task has very high requirements on the quality of video generation, because we are naturally more sensitive to dynamic changes in faces and characters. Given the particularity of this task, we need to combine VDT (or Sora) and controllable generation to address the challenges of photo video generation. At present, Sophon engine has broken through most of the key technologies of photo video generation and achieved better photo video generation quality than Sora. Sophon engine will continue to optimize the controllable generation algorithm of portraits, and is also actively exploring commercialization. At present, a confirmed commercial landing scenario has been found, and it is expected to break the "last mile" difficulty of landing large models in the near future.  In the future, a more versatile VDT will become a powerful tool to solve the problem of multi-modal large model data sources. Using video generation, VDT will be able to simulate the real world, further improve the efficiency of visual data production, and provide assistance for the independent update of the multi-modal large model Awaker. ##Awaker 1.0 is the ultimate goal of the Sophon engine team to "realize AGI" A crucial step towards the goal. The team believes that AI’s autonomous learning capabilities such as self-exploration and self-reflection are important evaluation criteria for intelligence level and are equally important as the continuous increase in parameter size (Scaling Law). Awaker 1.0 has implemented key technical frameworks such as "active data generation, model reflection and evaluation, and continuous model update", achieving breakthroughs on both the understanding side and the generation side. It is expected to accelerate the development of the multi-modal large model industry and ultimately allow humans to realize AGI .
In the future, a more versatile VDT will become a powerful tool to solve the problem of multi-modal large model data sources. Using video generation, VDT will be able to simulate the real world, further improve the efficiency of visual data production, and provide assistance for the independent update of the multi-modal large model Awaker. ##Awaker 1.0 is the ultimate goal of the Sophon engine team to "realize AGI" A crucial step towards the goal. The team believes that AI’s autonomous learning capabilities such as self-exploration and self-reflection are important evaluation criteria for intelligence level and are equally important as the continuous increase in parameter size (Scaling Law). Awaker 1.0 has implemented key technical frameworks such as "active data generation, model reflection and evaluation, and continuous model update", achieving breakthroughs on both the understanding side and the generation side. It is expected to accelerate the development of the multi-modal large model industry and ultimately allow humans to realize AGI .
The above is the detailed content of The multi-modal model of the National People's Congress moves towards AGI: it realizes independent updating for the first time, and photo video generation surpasses Sora. For more information, please follow other related articles on the PHP Chinese website!



















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



