



Last night Meta released the Llama 3 8B and 70B models. The Llama 3 command-tuned model has been fine-tuned and optimized for dialogue/chat use cases, outperforming common benchmarks. Many existing open source chat models. For example, Gemma 7B and Mistral 7B.
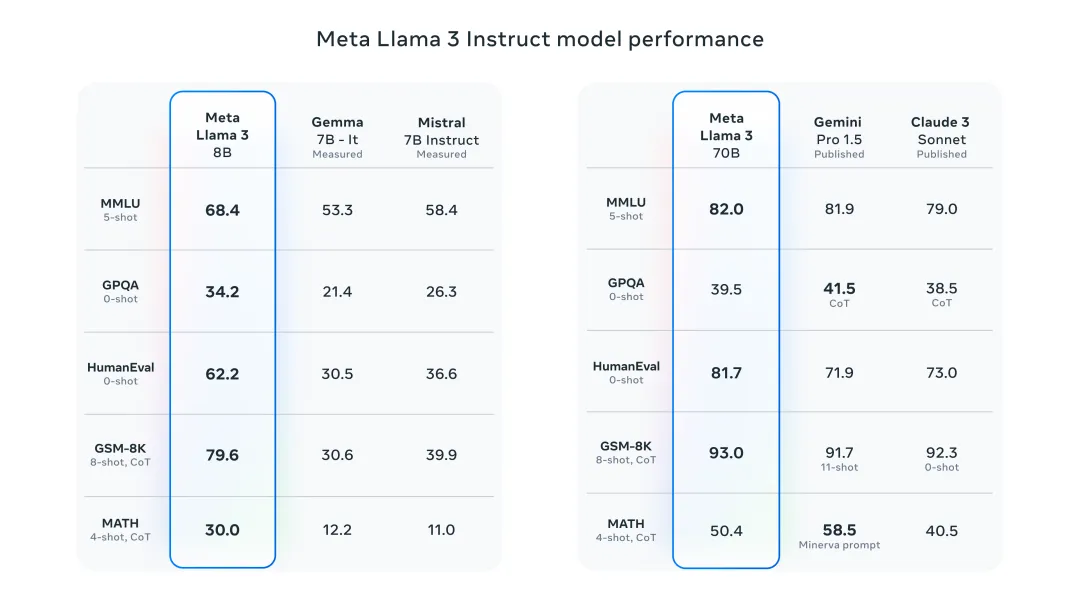
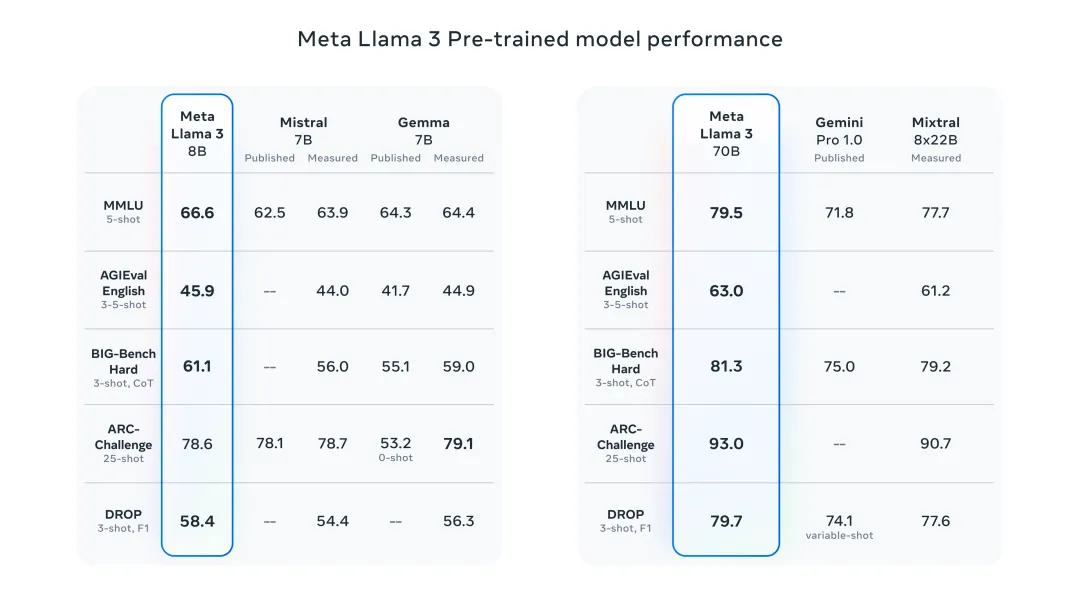
The Llama 3 model improves data and scale to new heights. It was trained on more than 15T tokens of data on two custom 24K GPU clusters recently released by Meta. This training dataset is 7 times larger than Llama 2 and contains 4 times more code. This brings the capabilities of the Llama model to the current highest level, supporting text lengths of more than 8K, twice that of Llama 2.
Below I will introduce 6 ways for you to quickly experience the newly released Llama 3!
https://www.llama2.ai/
https://lmstudio.ai/
https://marketplace.visualstudio.com/items?itemName=DanielSanMedium.dscodegpt&ssr=false
Before using CodeGPT, remember to use Ollama to pull the corresponding model. For example, to pull the llama3:8b model: ollama pull llama3:8b. If you have not installed ollama locally, you can read "Deploying a local large language model in just a few minutes!" This article.
Run Llama 3 8B model:
ollama run llama3
Run Llama 3 70B model:
ollama run llama3:70b

##https://pinokio.computer/item?uri=https:/ /github.com/cocktailpeanutlabs/open-webui.
The above is the detailed content of Six quick ways to experience the newly released Llama 3!. For more information, please follow other related articles on the PHP Chinese website!
 Build your own git server
Build your own git server
 The difference between git and svn
The difference between git and svn
 git undo submitted commit
git undo submitted commit
 Application of artificial intelligence in life
Application of artificial intelligence in life
 What is the basic concept of artificial intelligence
What is the basic concept of artificial intelligence
 How to undo git commit error
How to undo git commit error
 How to compare the file contents of two versions in git
How to compare the file contents of two versions in git
 The difference between executeupdate and execute
The difference between executeupdate and execute








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



