


Language models reason about text. Text is usually in the form of strings, but the input of the model can only be numbers, so the text needs to be converted into numerical form.
Tokenization is a basic task of natural language processing. It can divide a continuous text sequence (such as sentences, paragraphs, etc.) into a character sequence (such as words, phrases, characters, punctuation, etc.) according to specific needs. unit), where the units are called tokens or words.
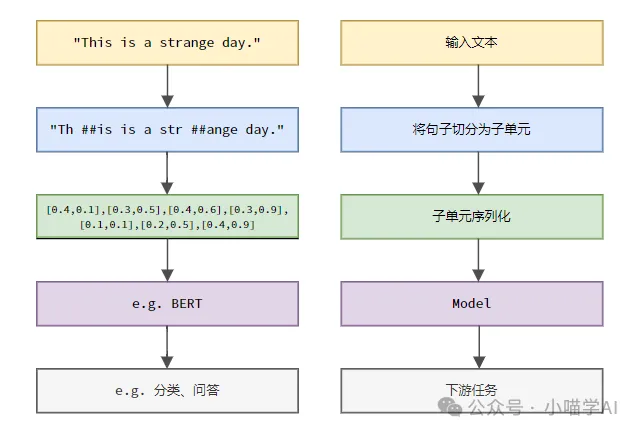
According to the specific process shown in the figure below, first divide the text sentences into units, then digitize the single elements (map them into vectors), then input these vectors into the model for encoding, and finally output them to Downstream tasks further obtain the final result.
According to the granularity of text segmentation, Tokenization can be divided into three categories: word granular Tokenization, character granular Tokenization, and subword granular Tokenization.
Word granularity Tokenization is the most intuitive word segmentation method, which means to segment the text according to vocabulary words. For example:
The quick brown fox jumps over the lazy dog.词粒度Tokenized结果:['The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog', '.']
In this example, the text is divided into independent words, each word is used as a token, and the punctuation mark '.' is also regarded as an independent token. .
Chinese text is usually segmented according to the standard vocabulary collection included in the dictionary or the phrases, idioms, proper nouns, etc. recognized through the word segmentation algorithm.
我喜欢吃苹果。词粒度Tokenized结果:['我', '喜欢', '吃', '苹果', '。']
This Chinese text is divided into five words: "I", "like", "eat", "apple" and period ".", each word serves as a token.
Character granularity Tokenization divides the text into the smallest character unit, that is, each character is treated as a separate token. For example:
Hello, world!字符粒度Tokenized结果:['H', 'e', 'l', 'l', 'o', ',', ' ', 'w', 'o', 'r', 'l', 'd', '!']
Character granularity Tokenization in Chinese is to segment the text according to each independent Chinese character.
我喜欢吃苹果。字符粒度Tokenized结果:['我', '喜', '欢', '吃', '苹', '果', '。']
subword granularity Tokenization is between word granularity and character granularity. It divides the text into between words and characters. Subwords serve as tokens. Common subword Tokenization methods include Byte Pair Encoding (BPE), WordPiece, etc. These methods automatically generate a word segmentation dictionary by counting substring frequencies in text data, which can effectively deal with the problem of out-of-service words (OOV) while maintaining a certain semantic integrity.
helloworld
Assume that after training with the BPE algorithm, the generated subword dictionary contains the following entries:
h, e, l, o, w, r, d, hel, low, wor, orld
Subword granularity Tokenized results:
['hel', 'low', 'orld']
Here, "helloworld" is divided into three sub-words "hel", "low", and "orld", which are high-frequency substring combinations that have appeared in the dictionary. This segmentation method can not only handle unknown words (for example, "helloworld" is not a standard English word), but also retain certain semantic information (the combination of sub-words can restore the original word).
In Chinese, subword granular Tokenization also divides the text into subwords between Chinese characters and words as tokens. For example:
我喜欢吃苹果
Assume that after training with the BPE algorithm, the generated subword dictionary contains the following entries:
我, 喜, 欢, 吃, 苹, 果, 我喜欢, 吃苹果
Subword granularity Tokenized results:
['我', '喜欢', '吃', '苹果']
In this example, "I like to eat apples" is divided into four sub-words "I", "like", "eat" and "apple". These sub-words All appear in the dictionary. Although Chinese characters are not further combined like English sub-words, the sub-word Tokenization method has considered high-frequency word combinations, such as "I like" and "eat apples" when generating the dictionary. This segmentation method maintains word-level semantic information while processing unknown words.
Assume that the corpus or vocabulary has been created as follows.
vocabulary = {'我': 0,'喜欢': 1,'吃': 2,'苹果': 3,'。': 4}You can find the index of each token in the sequence in the vocabulary.
indexed_tokens = [vocabulary[token] for token in token_sequence]print(indexed_tokens)
Output: [0, 1, 2, 3, 4].
The above is the detailed content of Understand Tokenization in one article!. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



