


The theme of this sharing is recommendation systems based on causal inference, reviewing past related work and proposing future prospects in this direction.
Why do we need to use causal inference technology in recommendation systems? Existing research work uses causal inference to solve three types of problems (see Gao et al.'s TOIS 2023 paper Causal Inference in Recommender Systems: A Survey and Future Directions):
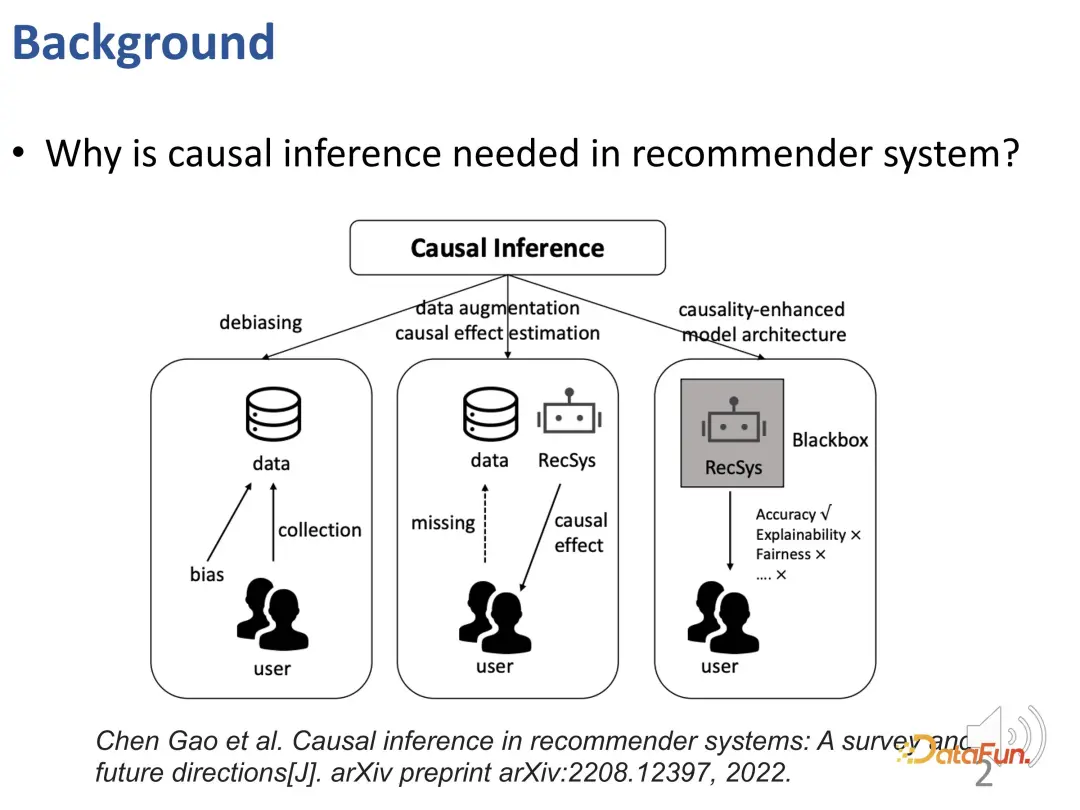
First of all, there are various biases (BIAS) in recommendation systems, and causal inference is an effective tool to remove these biases.
Recommender systems may face challenges in order to solve the problem of data scarcity and the inability to accurately estimate causal effects. In order to solve this problem, data enhancement or causal effect estimation methods based on causal inference can be used to effectively solve the problems of data scarcity and difficulty in estimating causal effects.
Finally, recommendation models can be better constructed by utilizing causal knowledge or causal prior knowledge to guide the design of the recommendation system. This method enables the recommendation model to surpass the traditional black box model, not only improving the accuracy, but also significantly improving the interpretability and fairness.
Starting from these three ideas, this sharing introduces the following three parts of work:
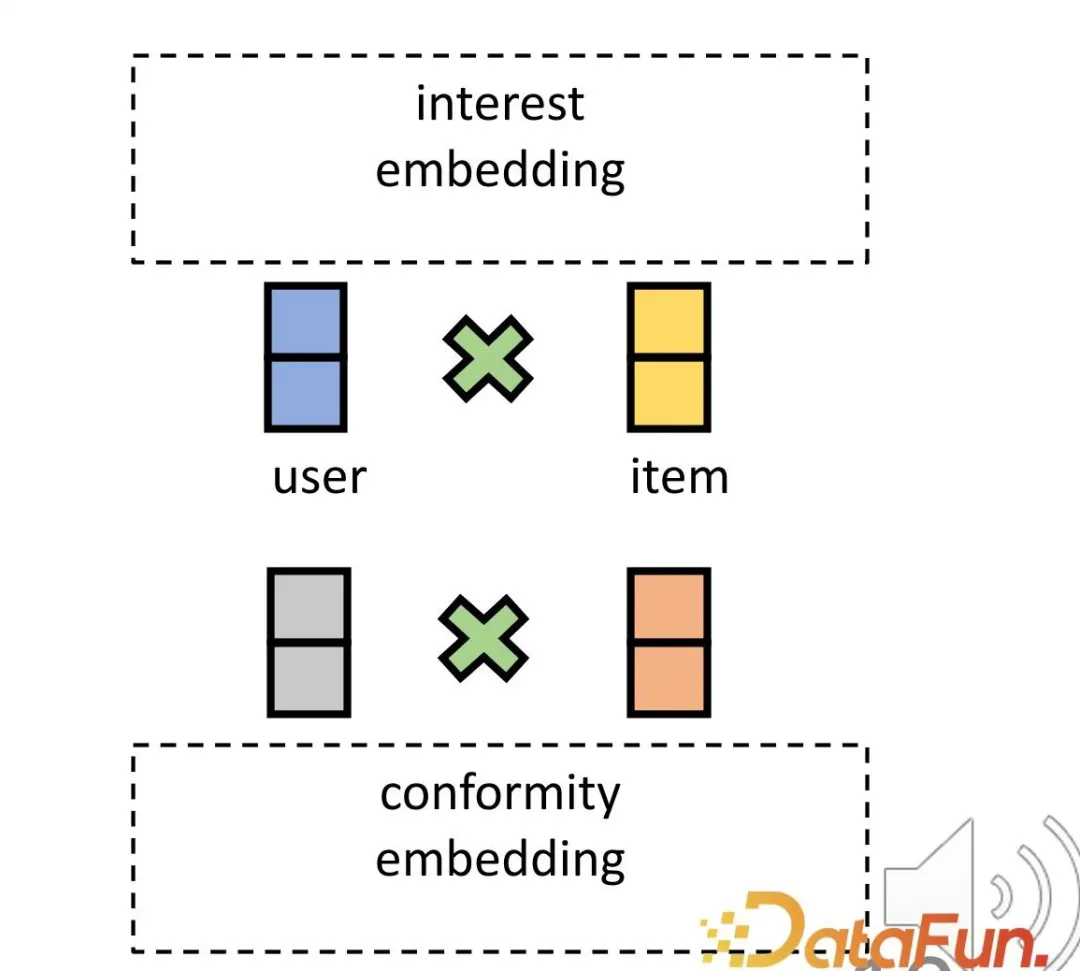
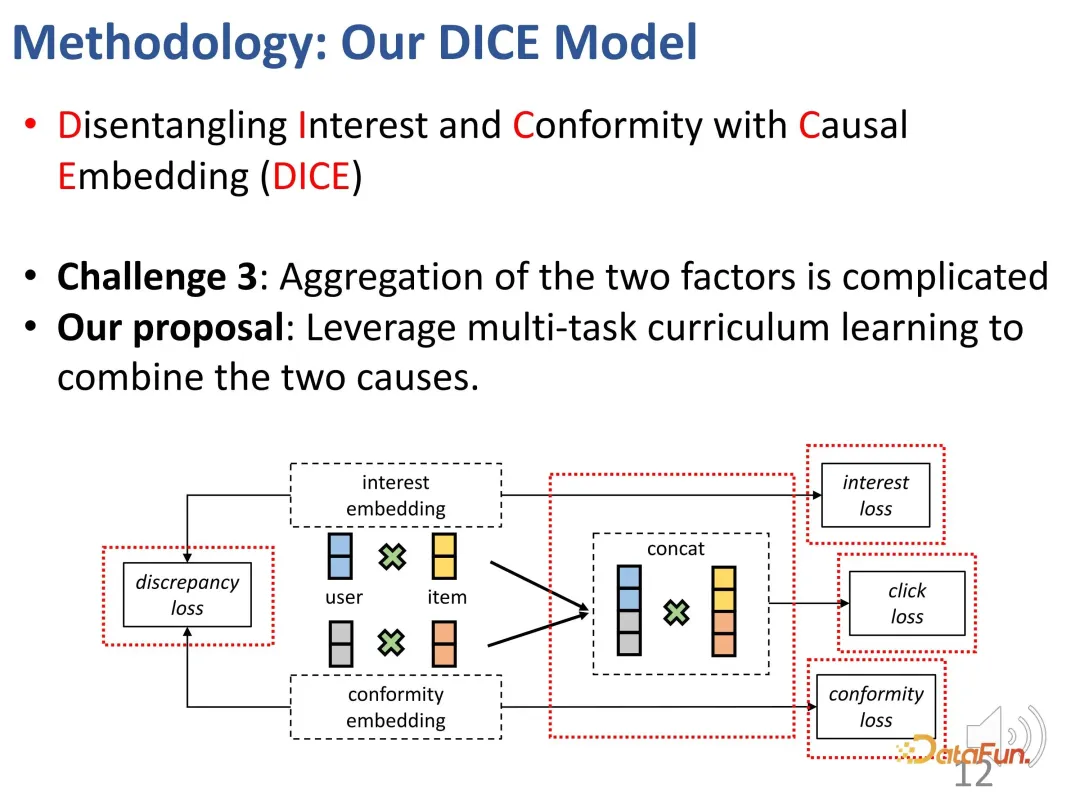
First, through the causal inference method: The user's interests and conformity are distinguished and the corresponding representations are learned. This belongs to the third part of the aforementioned classification framework, which is to make the model more interpretable when there is prior knowledge of cause and effect.
Back to the research background. It can be observed that there are deep-seated and different reasons behind the interaction between users and products. On the one hand, it is the user's own interests, and on the other hand, users may tend to follow the practices of other users (conformity). In a specific system, this might manifest as sales volume or popularity. For example, the existing recommendation system will display products with higher sales in the front position, which causes the popularity beyond the user's own interests to affect the interaction and bring about bias. Therefore, in order to make more accurate recommendations, it is necessary to distinguish between learning and solving the representations of the two parts.
Why do we need to learn disentangled representations? Here, let’s do a more in-depth explanation. Disentangled representation can help overcome the problem of inconsistent distribution (OOD) of offline training data and online experimental data. In a real recommendation system, if an offline recommendation system model is trained under a certain data distribution, it needs to be considered that the data distribution may change when deployed online. The final behavior of the user is produced by the joint action of conformity and interest. The relative importance of these two parts is different between online and offline environments, which may cause the data distribution to change; and if the distribution changes, there is no guarantee that the interest in learning will still remain. efficient. This is a cross-distribution problem. The picture below can illustrate this problem visually. In this figure, there is a distribution difference between the training and test data sets: the same shape, but its size and color have changed. For shape prediction, traditional models may infer shapes based on size and color on the training data set. For example, rectangles are blue and the largest, but the inference does not hold true for the test data set.
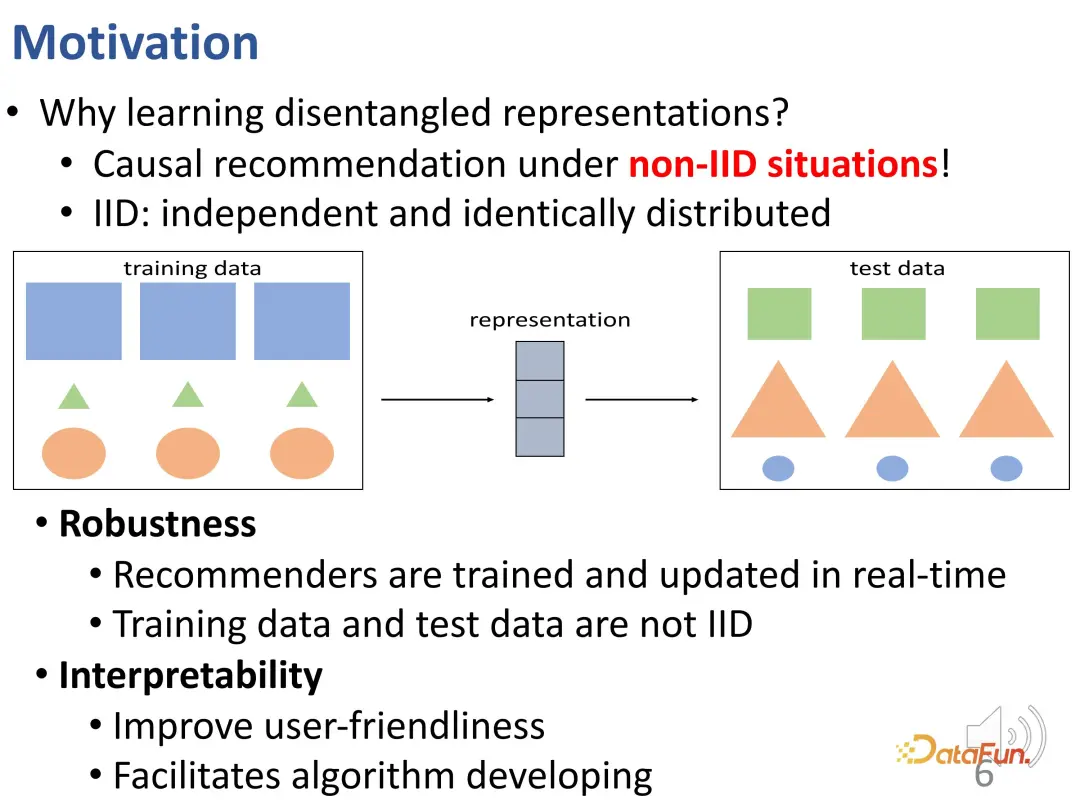
#If we want to better overcome this difficulty, we need to effectively ensure that the representation of each part is determined by the corresponding factor. This is one motivation for learning disentangled representations. Models that can disentangle latent factors can achieve better results in cross-distribution situations similar to the figure above: for example, disentanglement learns factors such as contour, color, and size, and prefers to use contours to predict shapes.
The traditional approach is to use the IPS method to balance the popularity of products. This method penalizes overly popular items (these items have greater weight in terms of conformity) during the learning process of the recommendation system model. But this approach bundles interest and conformity together without effectively separating them.

There is some early work on learning causal representation (Causal embedding) through causal inference. The disadvantage of this type of work is that it must rely on some unbiased data sets, and useunbiased data sets to constrain the learning process of biased data sets. While not much is needed, a small amount of unbiased data is still needed to learn disentangled representations. Therefore, its applicability in real systems is relatively limited.

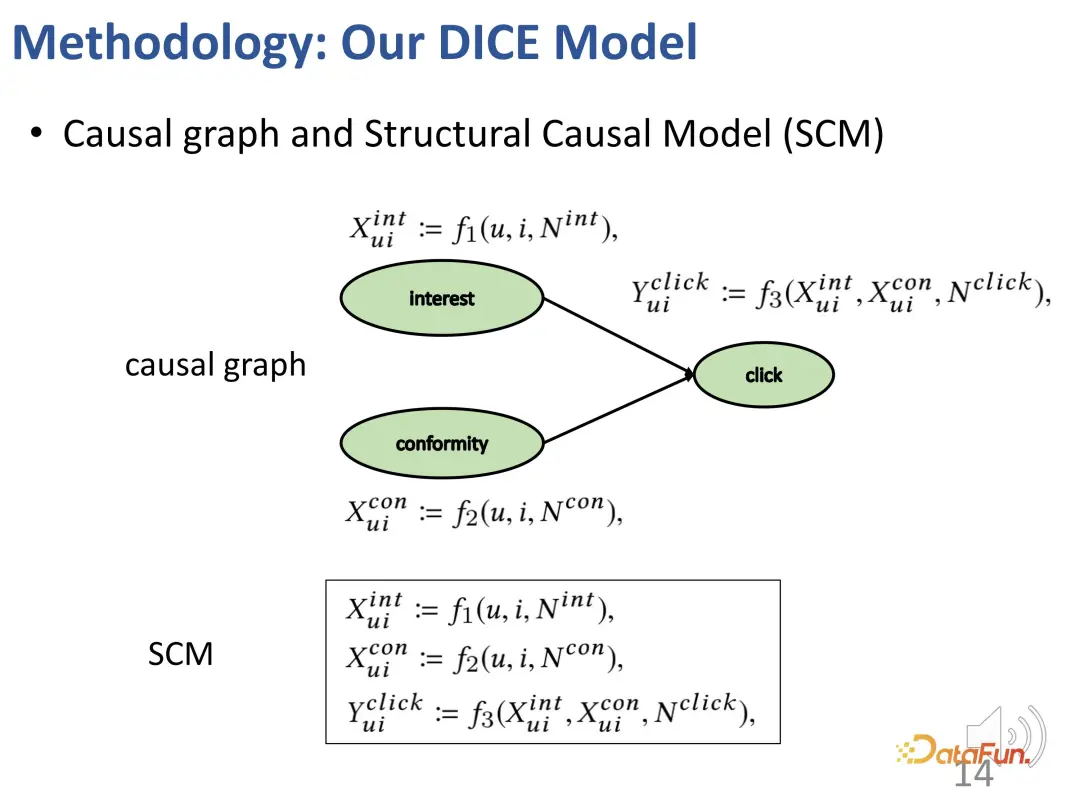
1. Causal embedding
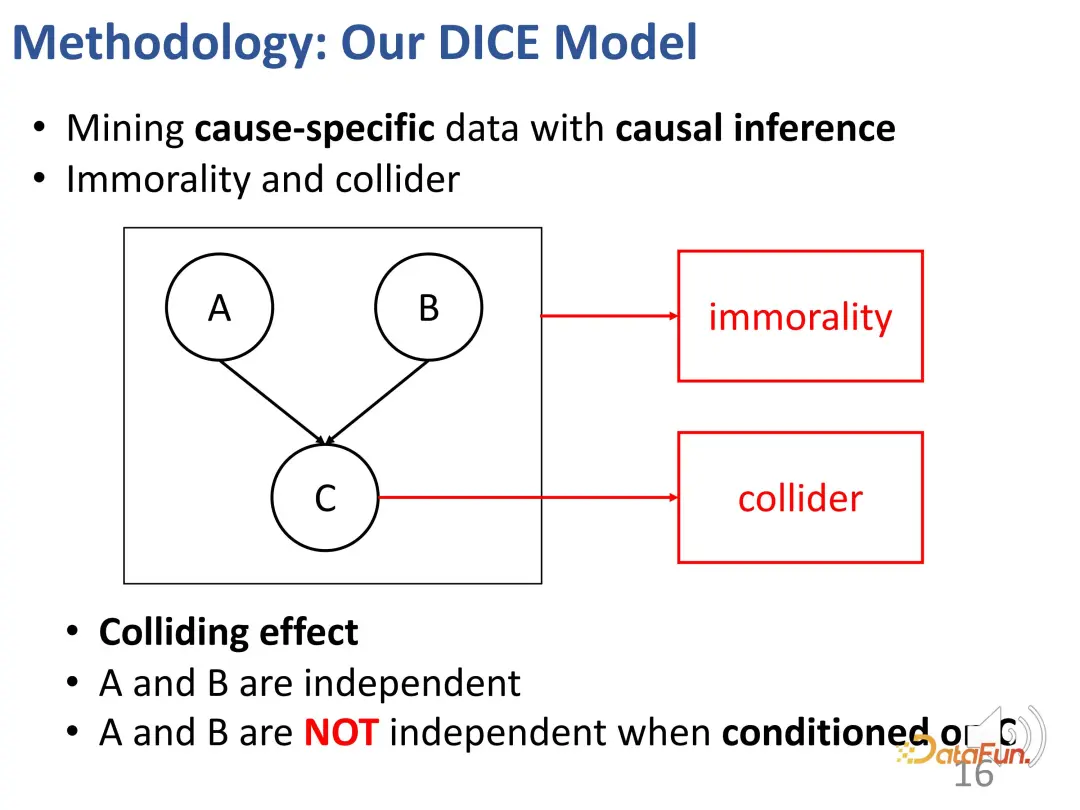
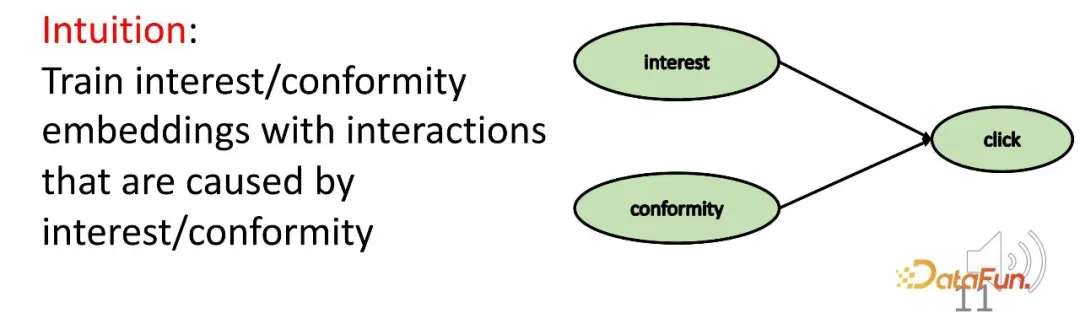
After given such a collision structure as above, when the condition c is fixed, a and b are actually not independent. Give an example to explain this effect: For example, a represents a student's talent, b represents the student's diligence, and c represents whether the student can pass an exam. If this student passes the exam and he does not have a particularly strong talent, then he must have worked very hard. Another student, he failed the exam, but he is very talented, then this classmate may not work hard enough.
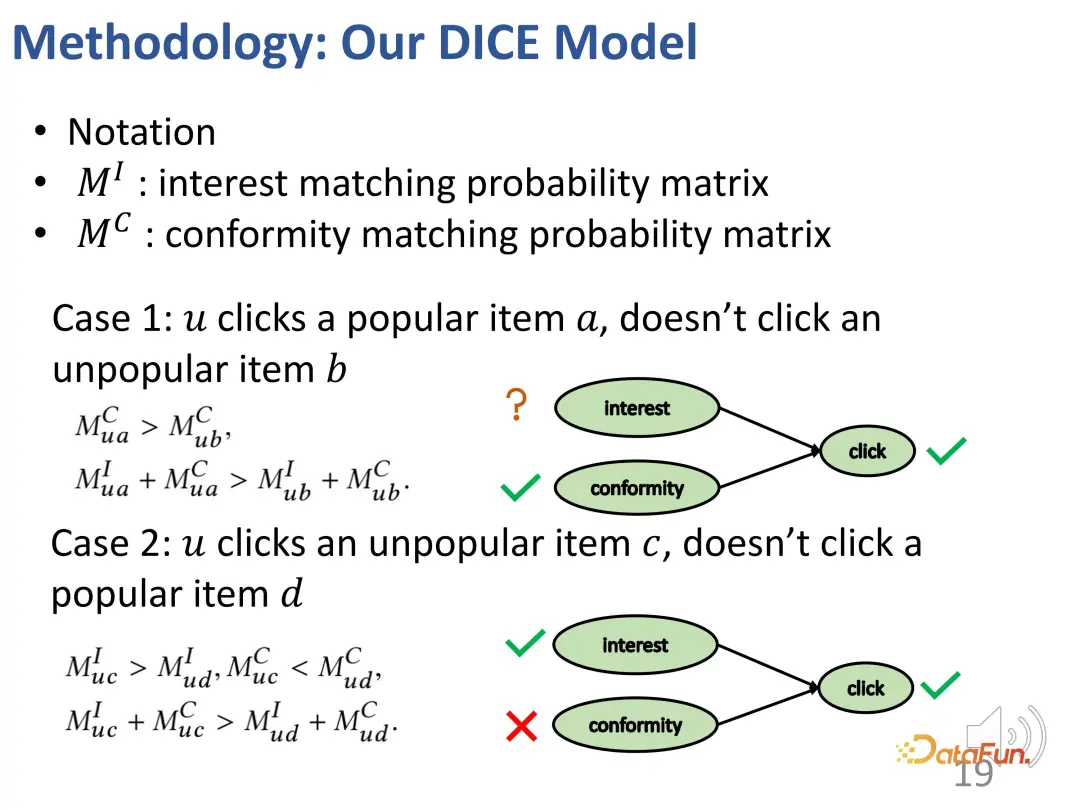
Based on this idea, the method is designed to divide the matching of interest and the matching of conformity, and use the popularity of the product as a proxy for conformity.
The first case: If a user clicks on a more popular item a, but does not click on another less popular item b, similar to the example just now, there will be the following picture Such an interest relationship: a's conformity to users is greater than b (because a is more popular than b), and a's overall appeal to users (interest conformity) is greater than b (because the user clicked on a but not on b).
The second case: a user clicked on an unpopular item c, but did not click on a popular item d, resulting in the following relationship: c's conformity to the user is less than d (because d is more popular than c), but the overall attractiveness (interest conformity) of c to users is greater than d (because the user clicked c but not d), so the user's interest in c is greater than d (because of the collision relationship , as mentioned above).
Generally speaking, two sets are constructed through the above method: one is those negative samples that are less popular than positive samples (users’ positive and negative The contrasting relationship between the interests of the samples is unknown), and the second is those negative samples that are more popular than positive samples (users are more interested in positive samples than negative samples). On these two parts, the relationship of contrastive learning can be constructed to train the representation vectors of the two parts in a targeted manner.
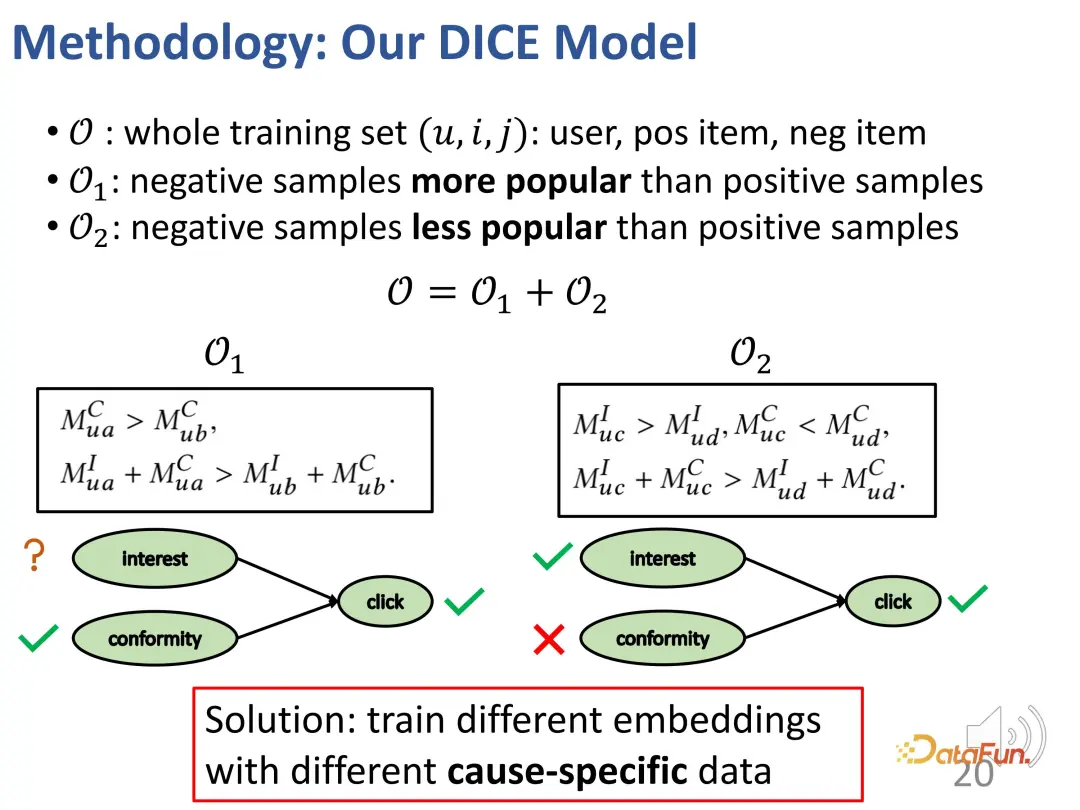
Of course, in the actual training process, the main goal is still to fit the observed interaction behavior. Like most recommendation systems, BPR loss is used to predict click behavior. (u: user, i: positive sample product, j: negative sample product).
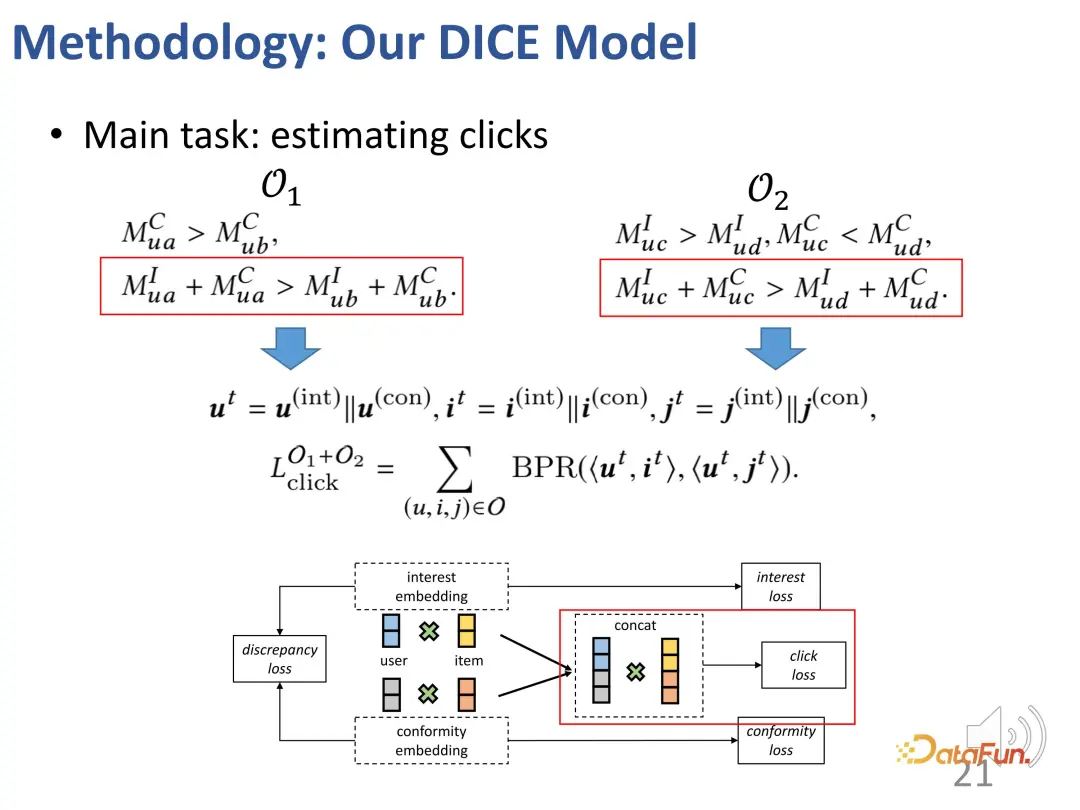
In addition, based on the above ideas, we also designed two parts of contrastive learning methods, introduced the loss function of contrastive learning, and introduced two additional parts. Constraints on the representation vector to optimize the two parts of the representation vector
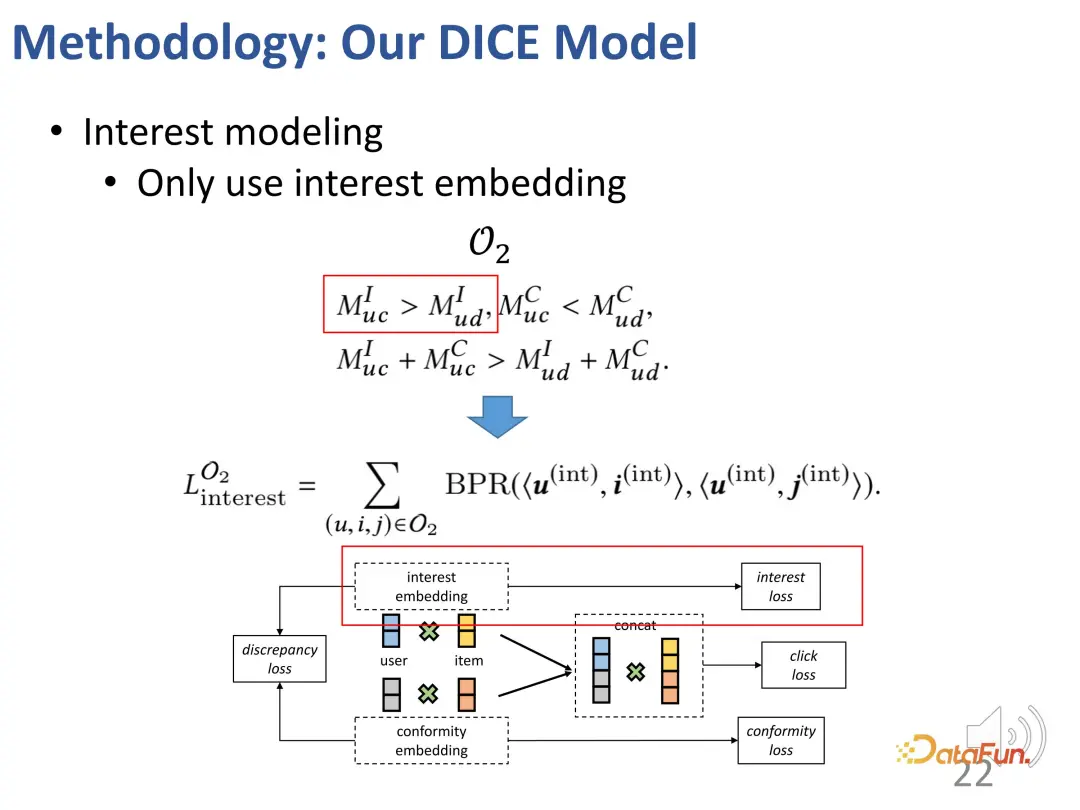
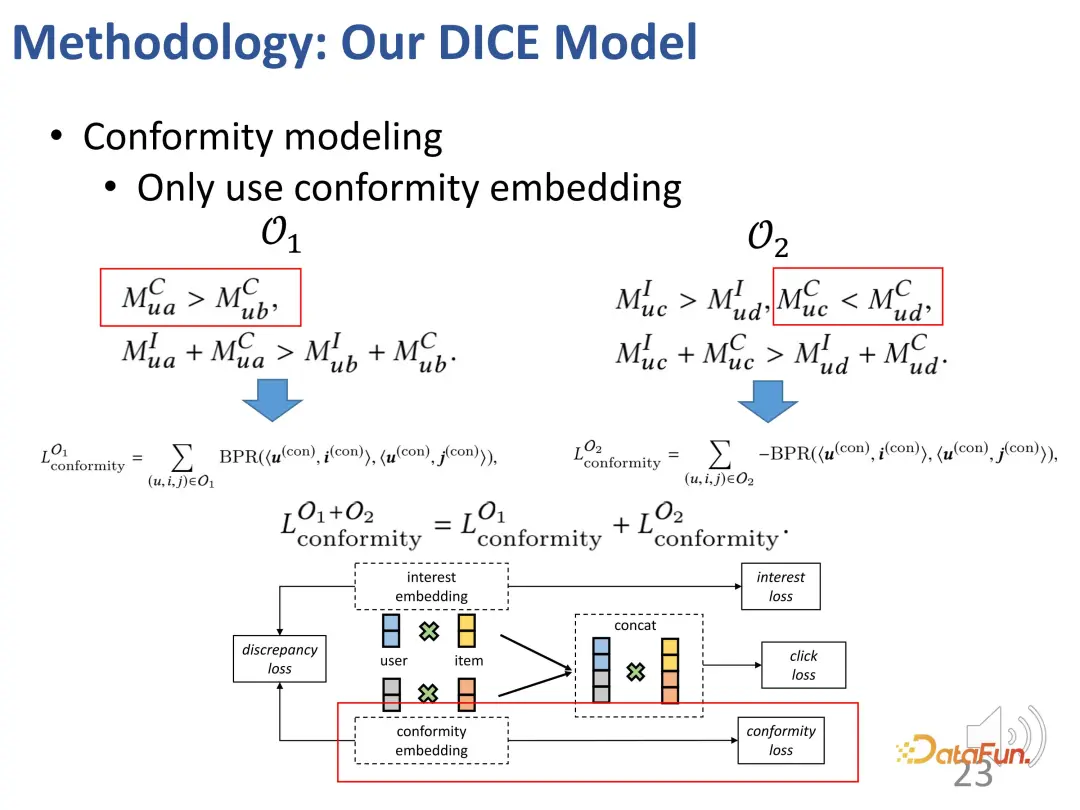
In addition, we must also constrain these two parts The representation vectors of the parts are as far away from each other as possible. This is because they can lose distinction if they are too close. Therefore, an additional loss function is introduced to constrain the distance between the two partial representation vectors.
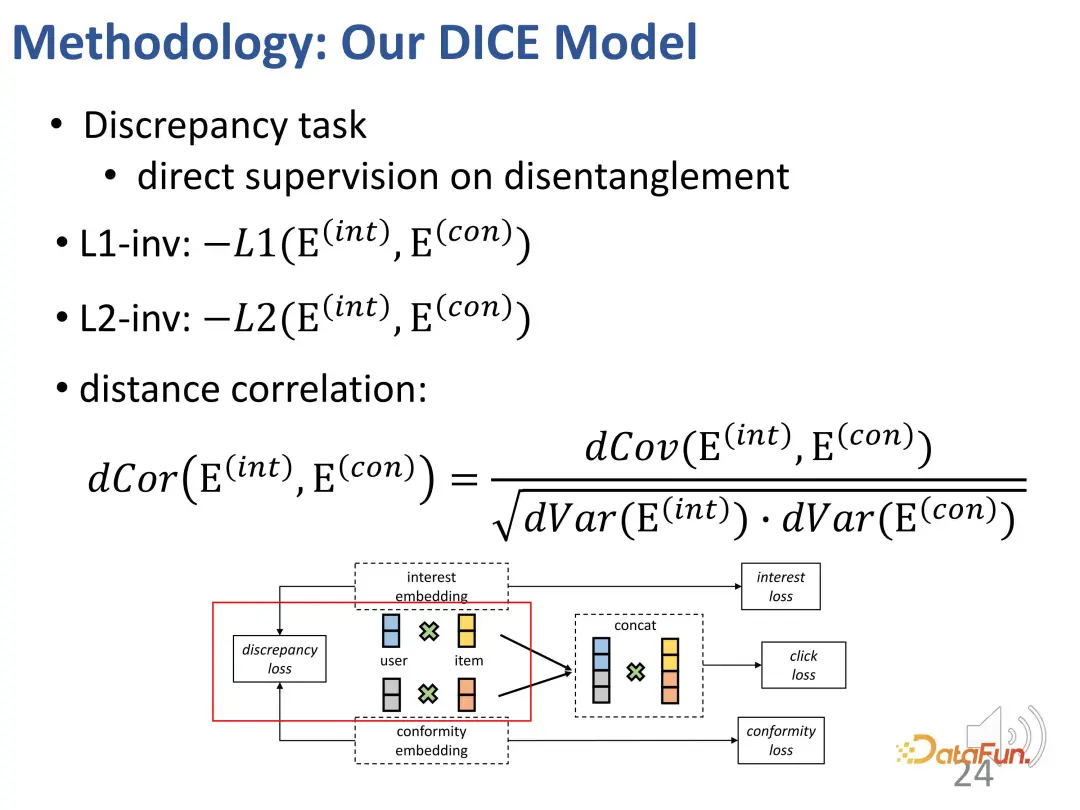
Ultimately, multi-task learning will integrate multiple goals together. During this process, a strategy was designed to ensure a gradual transition from easy to difficult in terms of learning difficulty. At the beginning of training, samples with less discrimination are used to guide the model parameters to be optimized in the correct general direction, and then gradually find difficult samples for learning to further fine-tune the model parameters. (Negative samples with a large difference in popularity from positive samples are regarded as simple samples, and those with a small difference are regarded as difficult samples).

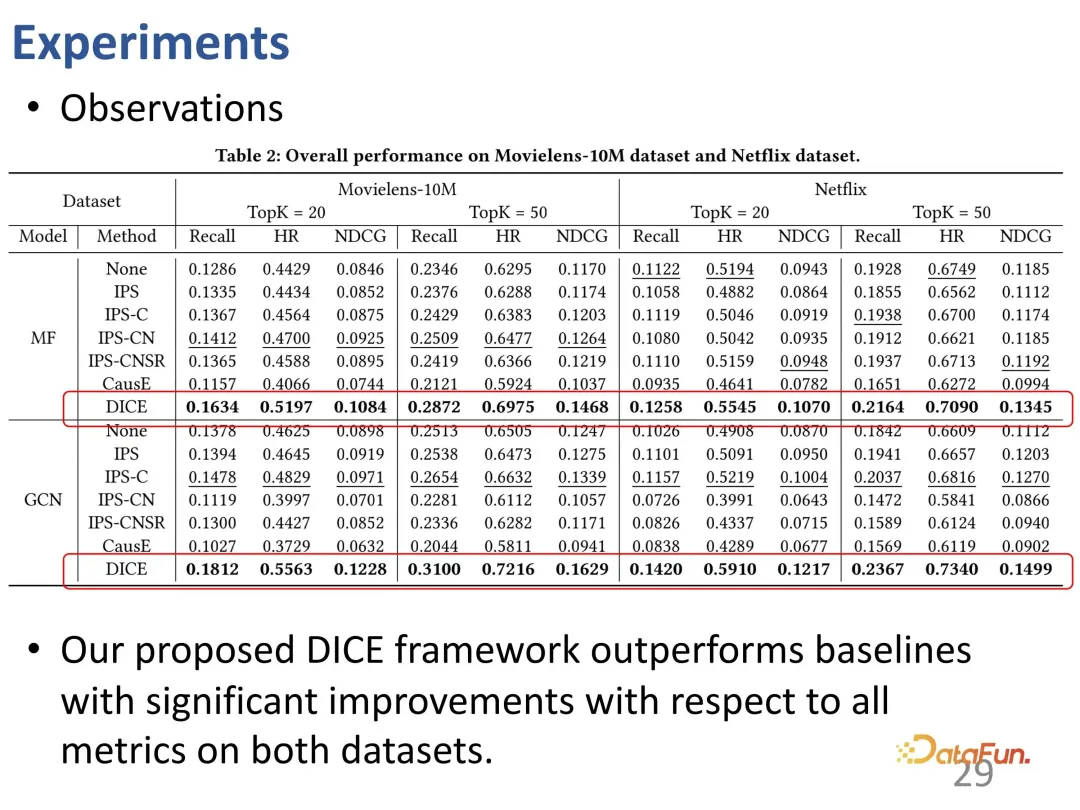
was tested on common data sets to examine the performance of the method on the main ranking indicators. Since DICE is a general framework that does not depend on a specific recommendation model, different models can be regarded as a backbone and DICE can be used as a plug-and-play framework.

The first is the protagonist DICE. It can be seen that the improvement of DICE is relatively stable on different backbones, so it can be considered as a general framework that can bring performance improvement.
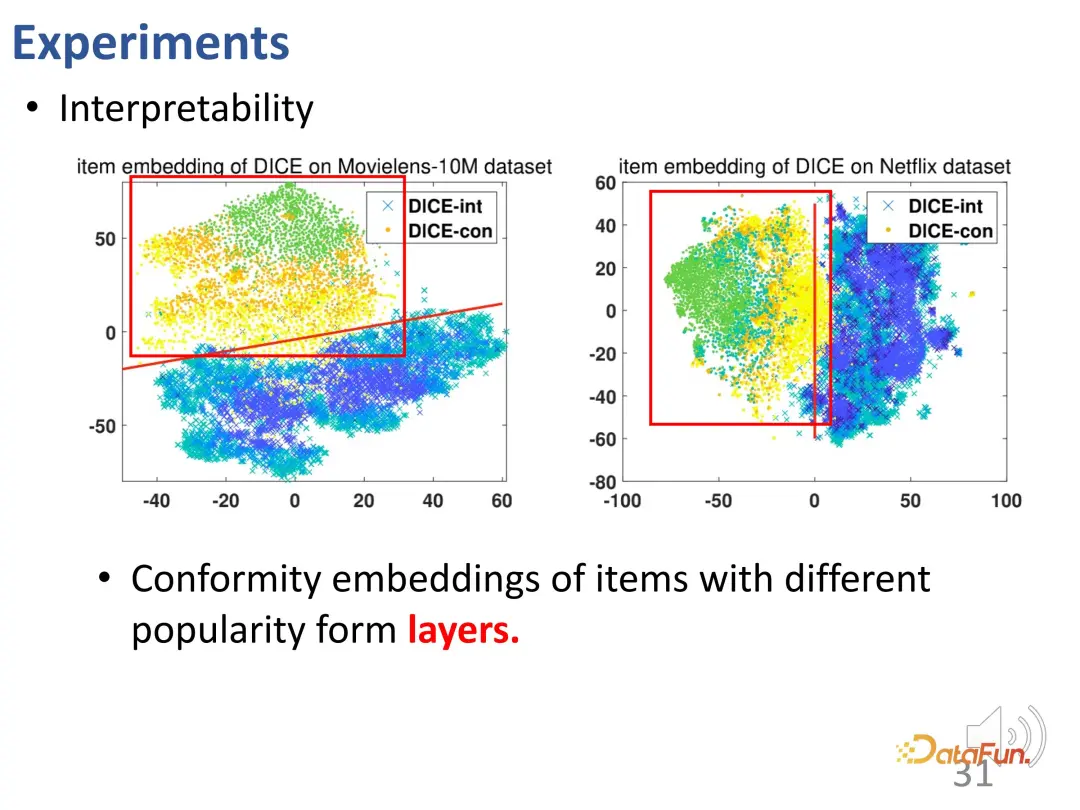
The representation learned by DICE is interpretable. After learning representations for interest and conformity separately, the vector of the conformity part contains the popularity of the product. Spend. Through visualization, it is found that it is indeed related to popularity (the representation of different popularity shows obvious stratification: green, orange and yellow points).
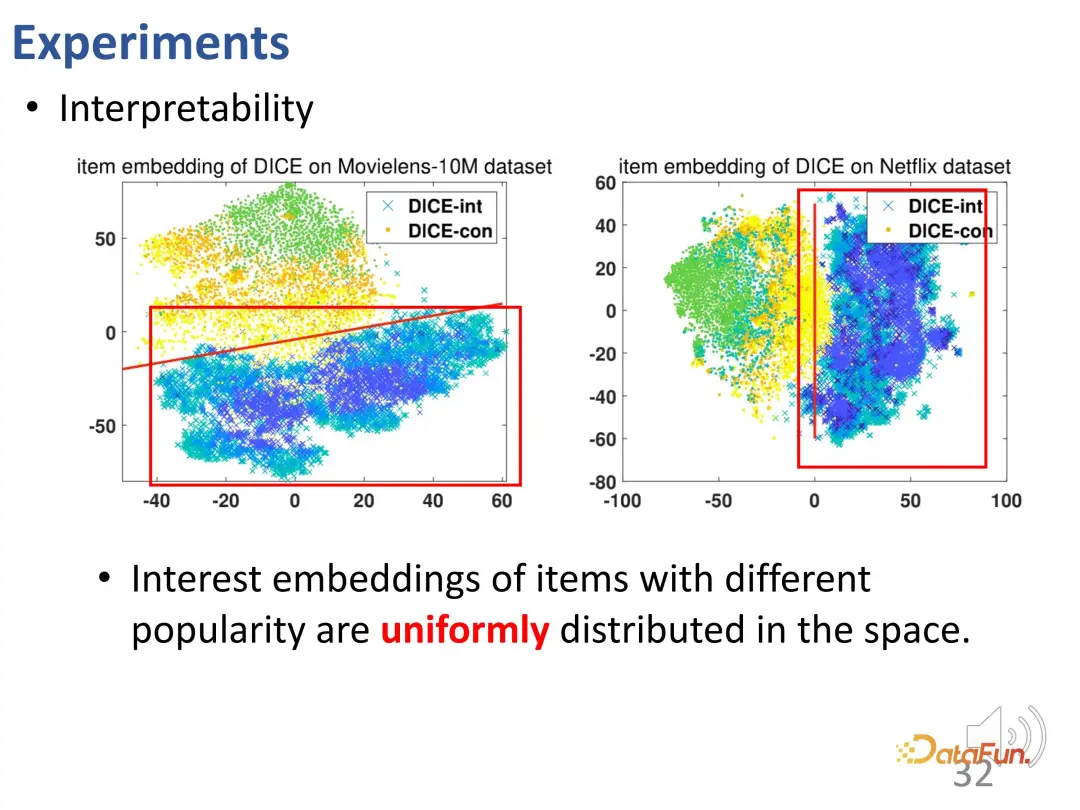
Moreover, the interest vector representations of products with different popularity are evenly distributed in the space (cyanium cross). The conformity vector representation and the interest vector representation also occupy different spaces and are separated by disentanglement. This visualization validates that the representations learned by DICE are actually meaningful.
DICE achieves the intended effect of the design. Further tests were conducted on data with different intervention intensities, and the results showed that the performance of DICE was better than the IPS method in different experimental groups.
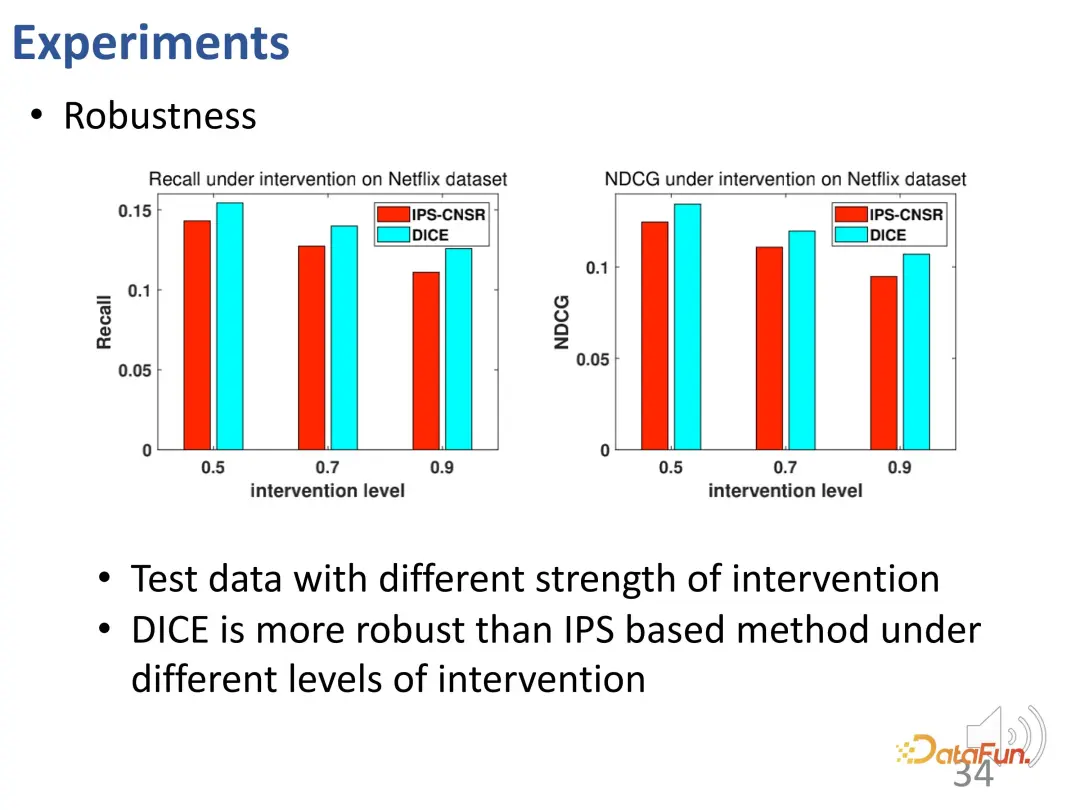
To summarize, DICE uses causal inference tools to learn corresponding representation vectors for interest and conformity respectively, providing good performance in non-IID situations. robustness and interpretability.

The second work mainly solves the problem of disentanglement of long-term interests and short-term interests in sequence recommendation. Specifically, user interests are complex, and part of the interests may be relatively stable, which is called long-term interest, while another part of the interest may be sudden and is called short-term interest. In the example below, the user is interested in electronic products in the long term, but wants to buy some clothes in the short term. If these interests can be well identified, the reasons for each behavior can be better explained and the performance of the entire recommendation system can be improved.

Such a problem can be called the modeling of long-term and short-term interests, that is, it can adaptively model long-term interests and short-term interests respectively. And further infer which part of the user's current behavior is mainly driven. If you can identify the interests that currently drive behavior, you can better make recommendations based on current interests. For example, if the user browses the same category in a short period of time, it may be a short-term interest; if the user explores extensively in a short period of time, it may need to refer more to previously observed long-term interests rather than being limited to the current interest. In general, long-term interests and short-term interests are different in nature, and long-term needs and short-term needs need to be well disentangled.

Generally speaking, it can be considered that collaborative filtering is actually a method of capturing long-term interests because it ignores the dynamic changes of interests; Existing sequence recommendations focus more on short-term interest modeling, which leads to the forgetting of long-term interests, and even if long-term interests are taken into account, it still mainly relies on short-term interests when modeling. Therefore, existing methods still fall short in combining these two interests for learning.
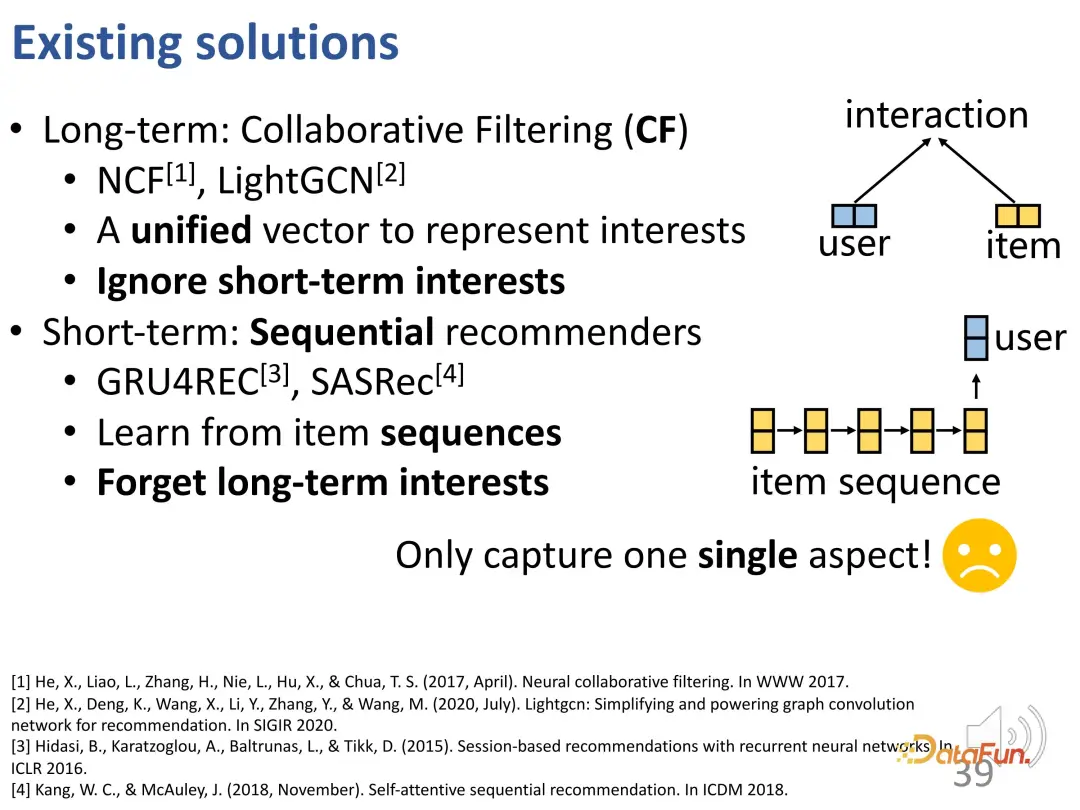
Some recent work has begun to consider the modeling of long-term and short-term interests, designing short-term modules and long-term modules separately, and then directly combining them together. However, in these methods, there is only one user vector ultimately learned, which contains both short-term signals and long-term signals. The two are still entangled and need further improvement.
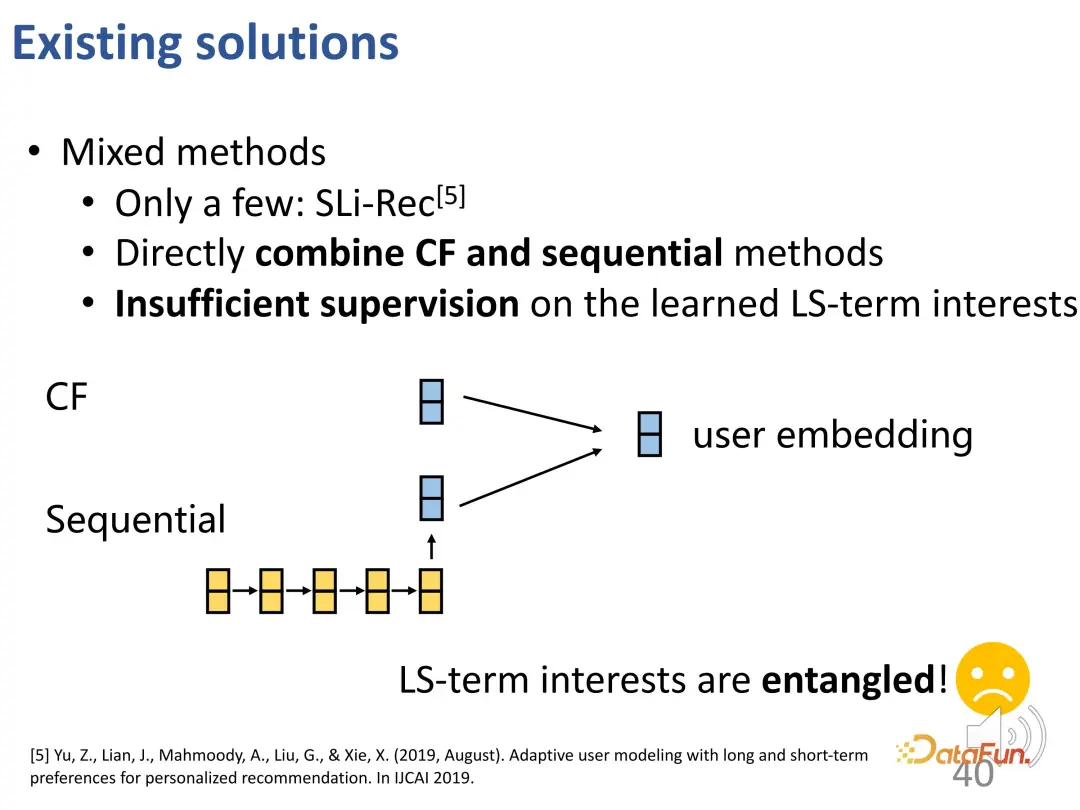
However, decoupling long and short-term interests remains challenging:
#In response to this problem, a comparative learning method is proposed to model long-term and short-term interests at the same time. (Contrastive learning framework of Long and Short-term interests for Recommendation (CLSR))
For the first A challenge is to separate long-term interests and short-term interests. We establish corresponding evolution mechanisms for long-term and short-term interests respectively. In the structural causal model, the long-term interest is set independent of time, and the short-term interest is determined by the short-term interest at the previous moment and the general long-term interest. That is, during the modeling process, long-term interest is relatively stable, while short-term interest changes in real time.
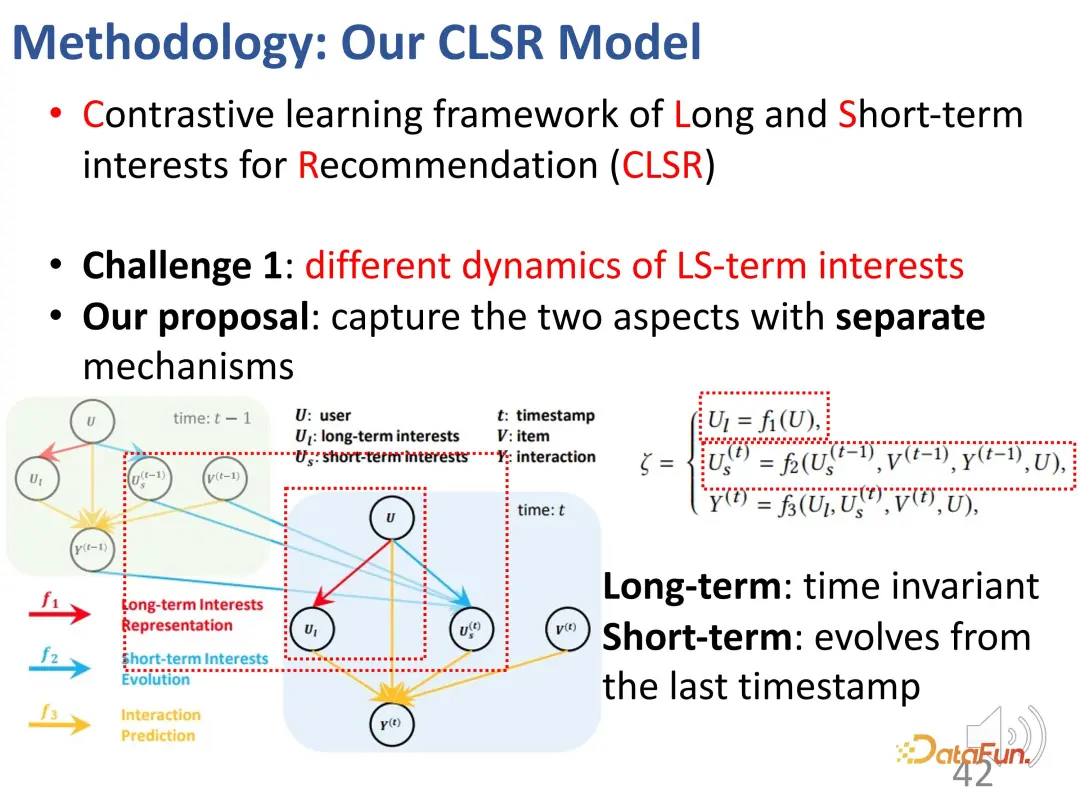
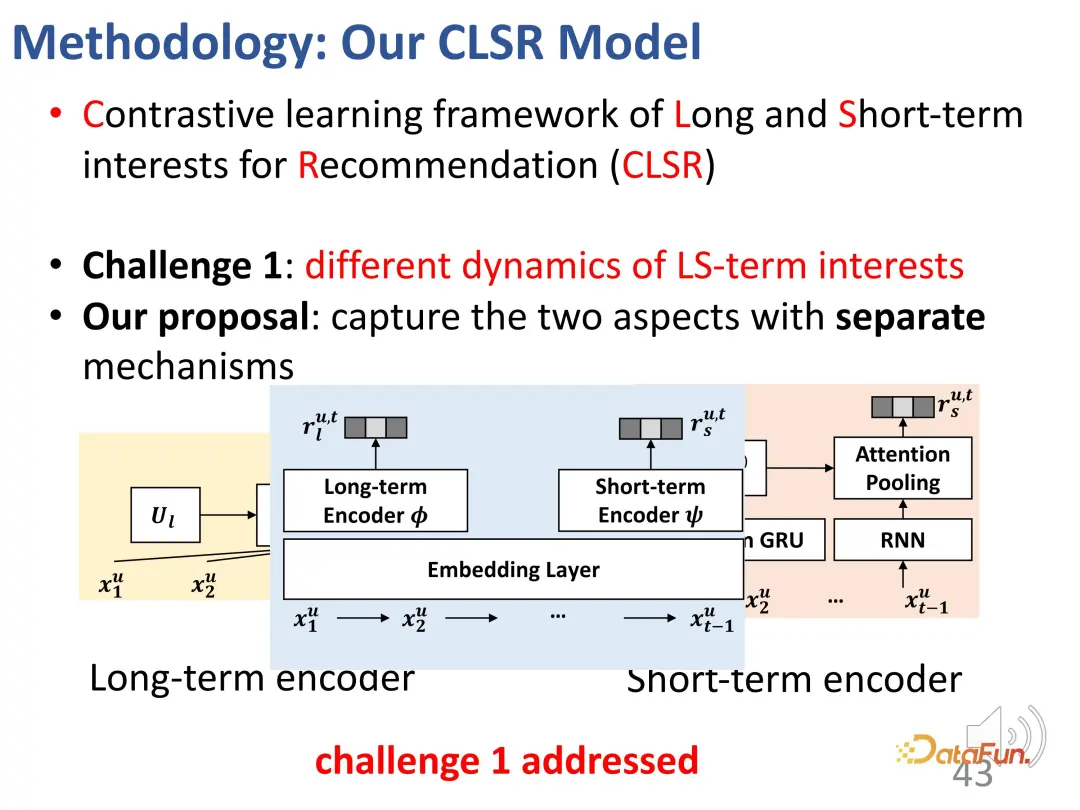
The second challenge is the lack of explicit supervision signals for the two-part interest. In order to solve this problem, contrastive learning methods are introduced for supervision, and proxy labels are constructed to replace explicit labels.
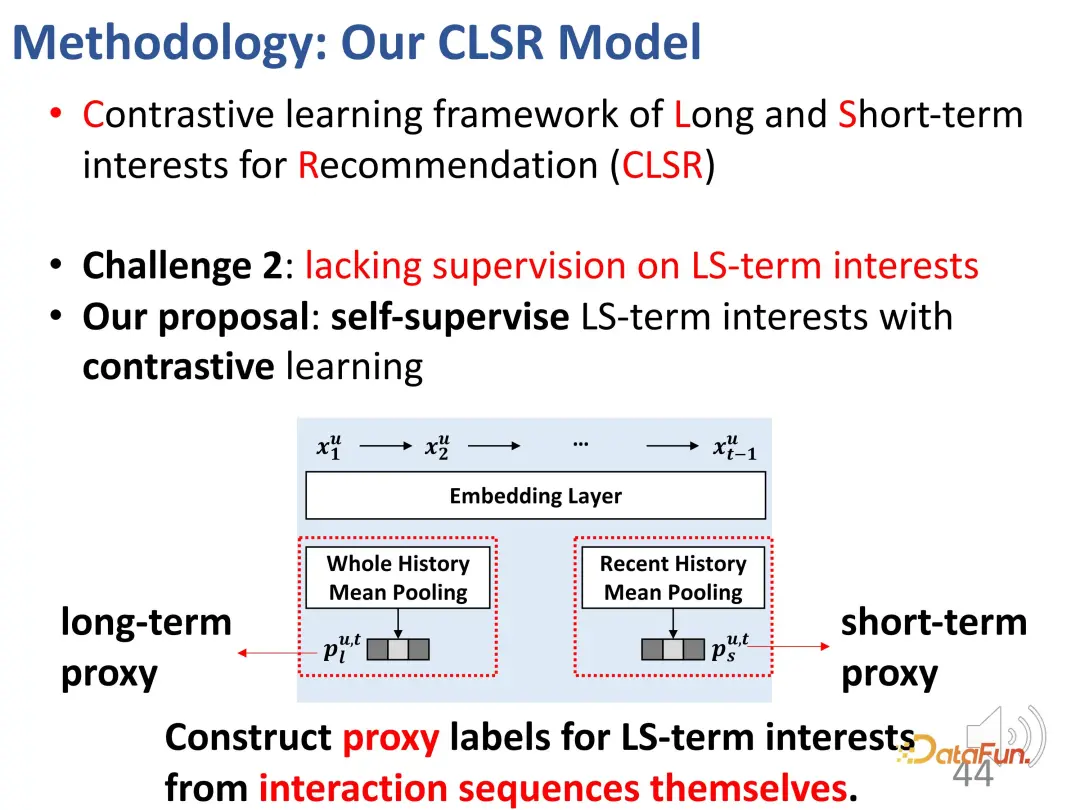
The agent label is divided into two parts, one is for agents with long-term interests, and the other is for agents with short-term interests.
Using the entire history of pooling as a proxy label of long-term interest, in the learning of long-term interest, makes the representation learned by the encoder more towards Optimize this direction.
The same is true for short-term interests. The average pooling of the user’s recent behaviors is used as a short-term proxy; similarly, although it does not directly represent the user’s interests, it can reflect the user’s short-term interests. During the learning process, optimize in this direction as much as possible.
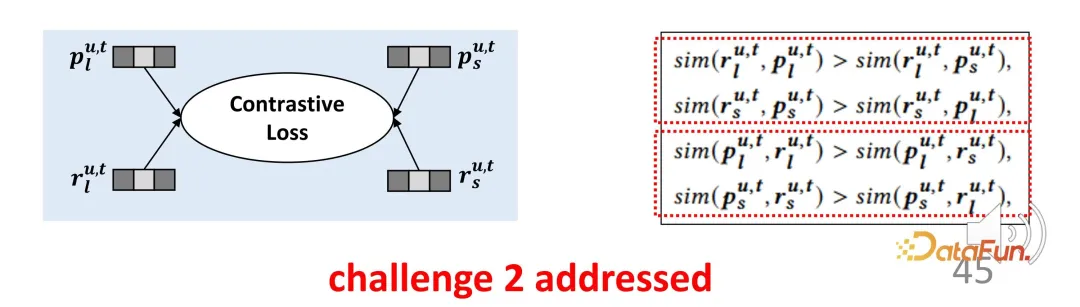
Although such agent representations do not strictly represent interests, they represent an optimization direction. For long-term interest representation and short-term interest representation, they will be as close as possible to the corresponding representation and stay away from the representation in the other direction, thereby constructing a constraint function for contrastive learning. In the same way, because the proxy representation should be as close as possible to the actual encoder output, it is a symmetrical two-part loss function. This design effectively makes up for the lack of supervision signal just mentioned.
The third challenge is to judge the importance of the two parts of interest for a given behavior. The solution is to adaptively Merging two interests. The design of this part is relatively simple and straightforward, because there are already two parts of representation vectors before, and it is not difficult to mix them together. Specifically, a weight α needs to be calculated to balance the interests of the two parts. When α is relatively large, the current interest is mainly dominated by long-term interest; vice versa. Finally, an estimate of the interaction behavior is obtained.
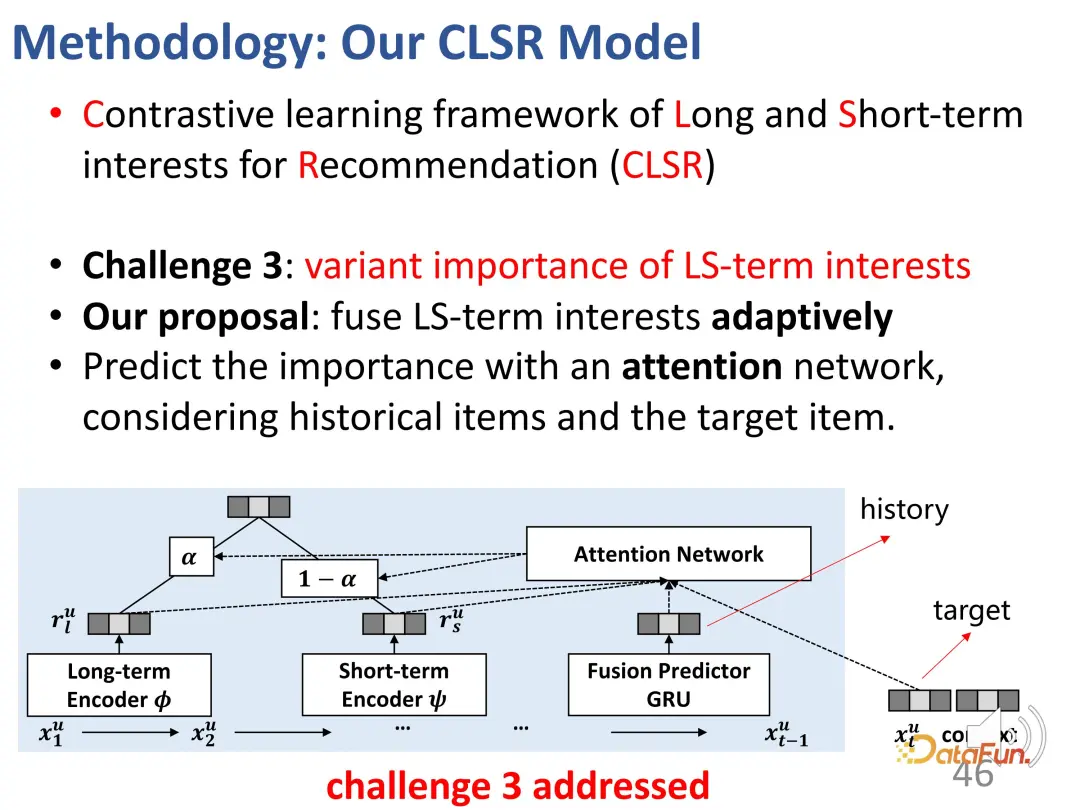
For prediction, on the one hand, it is the loss of the general recommendation system mentioned above, and on the other hand, the loss function of contrastive learning is weighted in the form of Get involved.

The following is the overall block diagram:
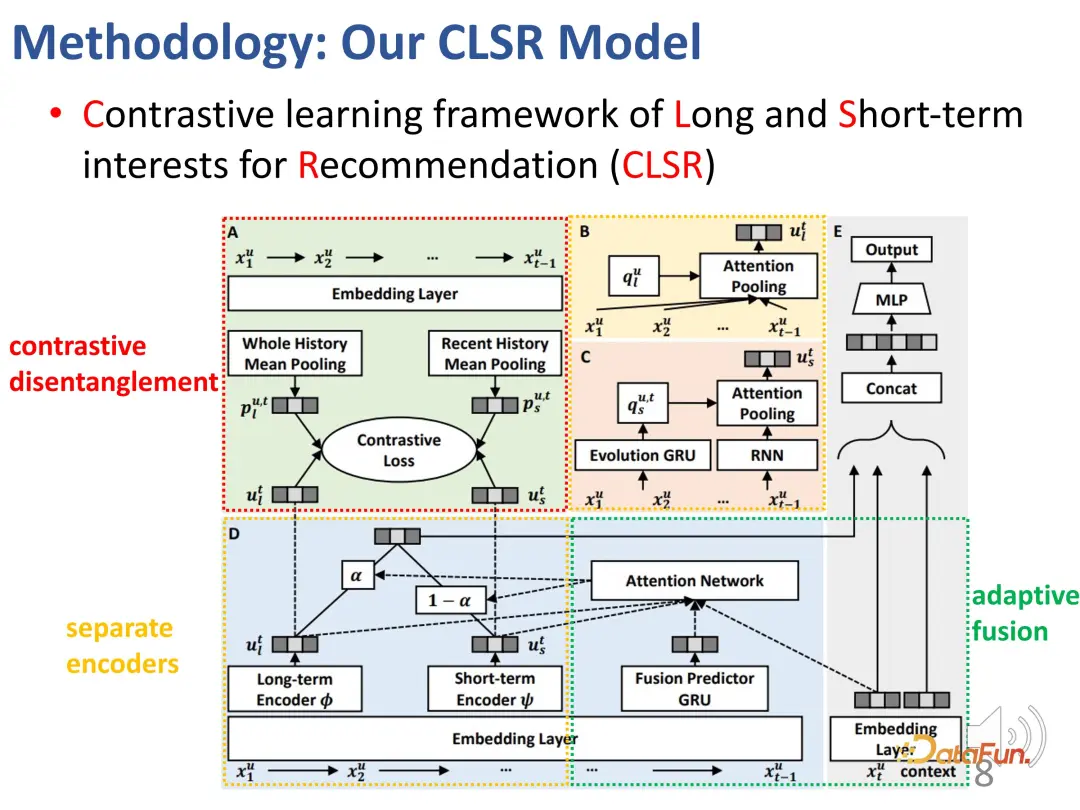
##Here are two separate encoders (BCD), the corresponding agent representation and the goal of contrastive learning (A), and the interest of adaptively blending the two parts.
In this work, sequence recommendation data sets were used, including Taobao’s e-commerce data set and Kuaishou’s short video data set. The methods are divided into three types: long-term, short-term and combination of long-term and short-term.

If you observe the overall experimental results, you can see that only short-term interests are considered Models perform better than models that only consider long-term interests, that is, sequential recommendation models are generally better than purely static collaborative filtering models. This is reasonable because short-term interest modeling can better identify some of the most recent interests that have the greatest impact on current behavior.
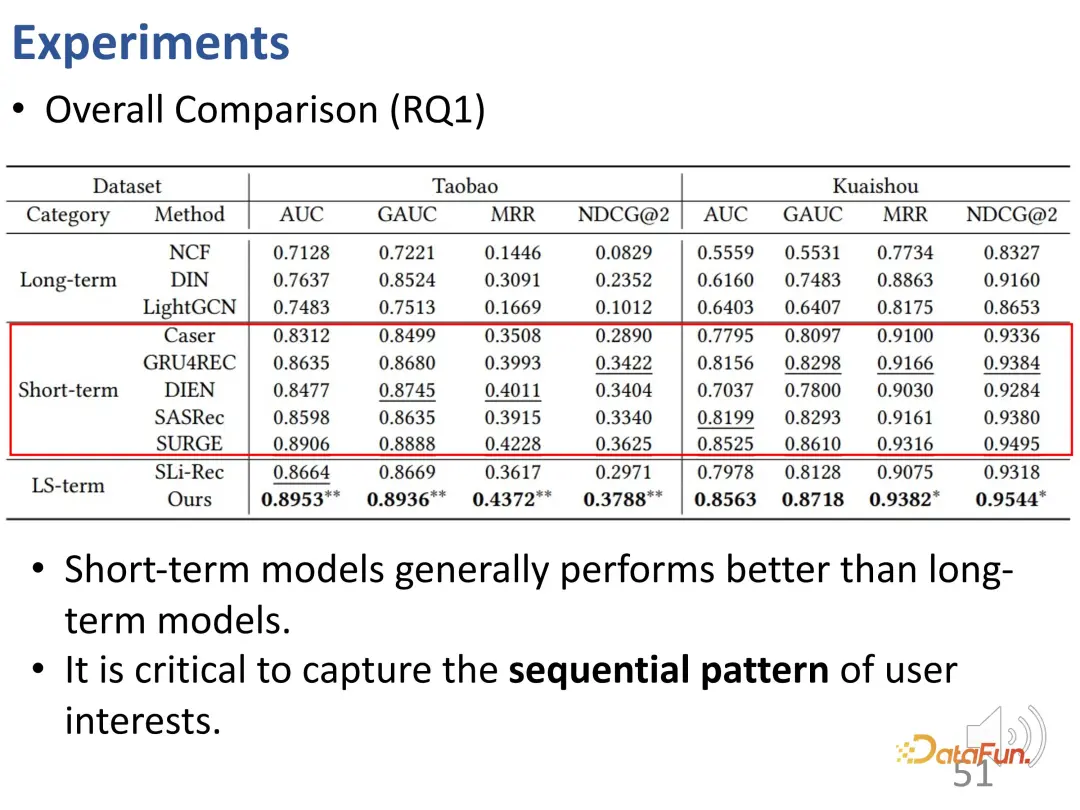
The second conclusion is that the SLi-Rec model that simultaneously models long-term and short-term interests is not necessarily better than the traditional sequence recommendation model. . This highlights the shortcomings of existing work. The reason is that simply mixing the two models may introduce bias or noise; as can be seen here, the best baseline is actually a sequential short-term interest model.
The long-term and short-term interest decoupling method we proposed solves the disentanglement modeling problem between long-term and short-term interests, and can achieve stability on two data sets and four indicators. the best results.
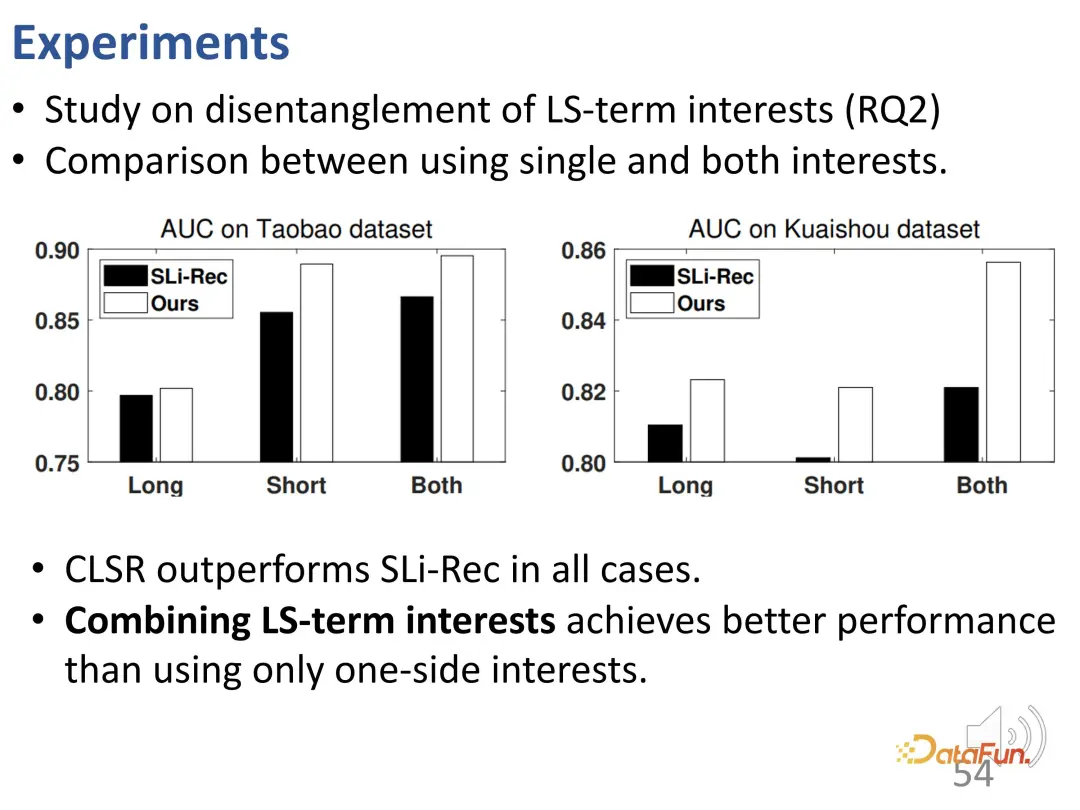
To further investigate this disentanglement effect, experiments were performed for two-part representations corresponding to long- and short-term interests. Compare the long-term interest, short-term interest of CLSR learning and the two interests of Sli-Rec learning. Experimental results show that our work (CLSR) is able to consistently achieve better results on each part, and also prove the necessity of fusing long-term interest modeling and short-term interest modeling, since using both The best result is the integration of interests.
Further, use purchase behavior and like behavior for comparative research, because the cost of these behaviors is higher than clicks: purchases cost money, clicks Likes come at an operational cost, so these interests actually reflect a stronger preference for stable, long-term interest. First, in terms of performance comparison, CLSR achieves better results. Furthermore, the weighting of the two aspects of modeling is more reasonable. CLSR is able to assign larger weights than the SLi-Rec model to behaviors that are more biased toward long-term interests, which is consistent with the previous motivation.

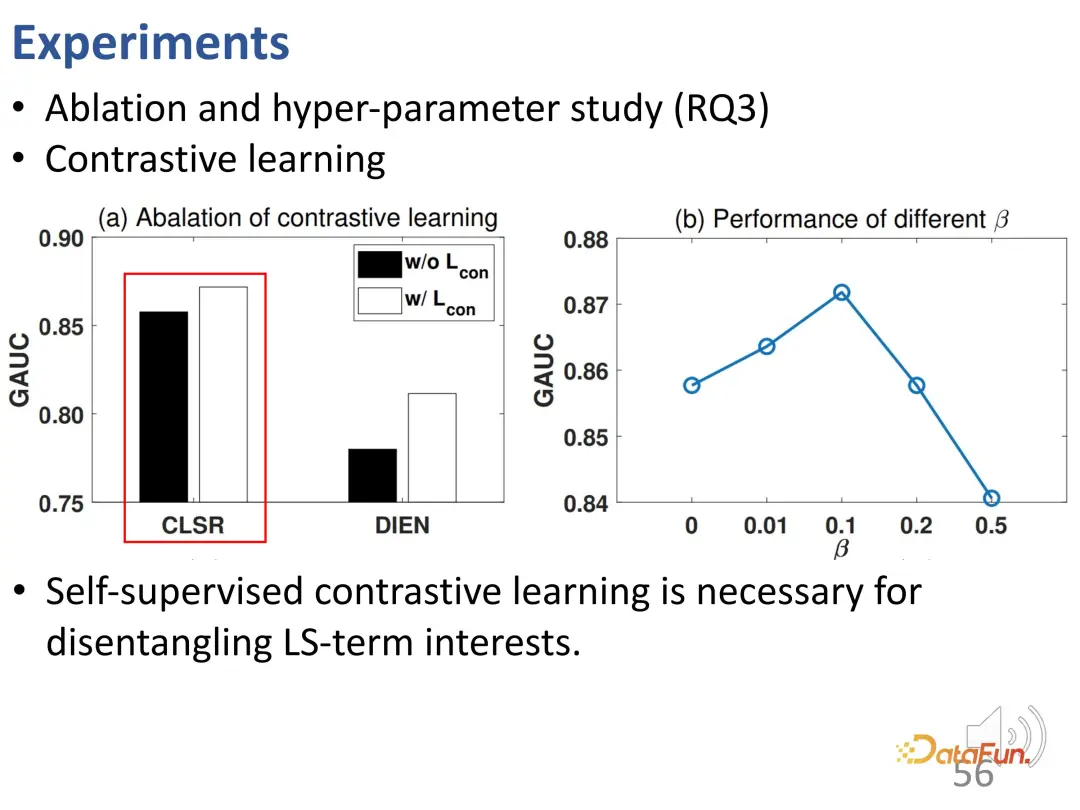
Further ablation experiments and hyperparameter experiments were conducted. First, the loss function of contrastive learning was removed and the performance was found to decrease, indicating that contrastive learning is very necessary to disentangle long-term interests and short-term interests. This experiment further proves that CLSR is a better general framework because it can also work on the basis of existing methods (self-supervised contrastive learning can improve the performance of DIEN) and is a plug-and-play method. Research on β found that a reasonable value is 0.1.
# Next, we will further study the relationship between adaptive fusion and simple fusion. Adaptive weight fusion performs stably and better than fixed weight fusion at all different α values, which verifies that each interaction behavior may be determined by weights of different sizes, and verifies that interest fusion is achieved through adaptive fusion and The need for final behavioral prediction.
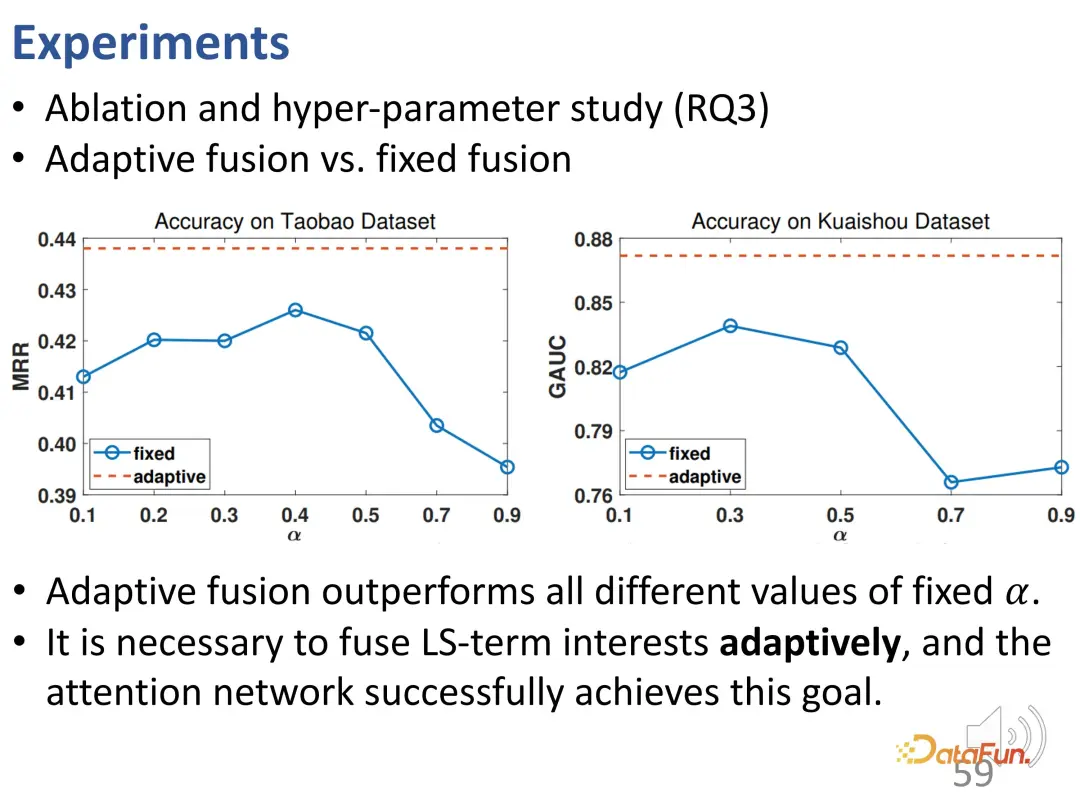
This work proposes a contrastive learning method to model long-term interest and short-term interest in sequence interests, learning the corresponding representation vectors respectively , to achieve disentanglement. Experimental results demonstrate the effectiveness of this method.

The two works introduced earlier focus on the disentanglement of interests. The third work focuses on behavioral correction of interest learning.
Short video recommendation has become a very important part of the recommendation system. However, existing short video recommendation systems still follow the previous paradigm of long video recommendation, and there may be some problems.
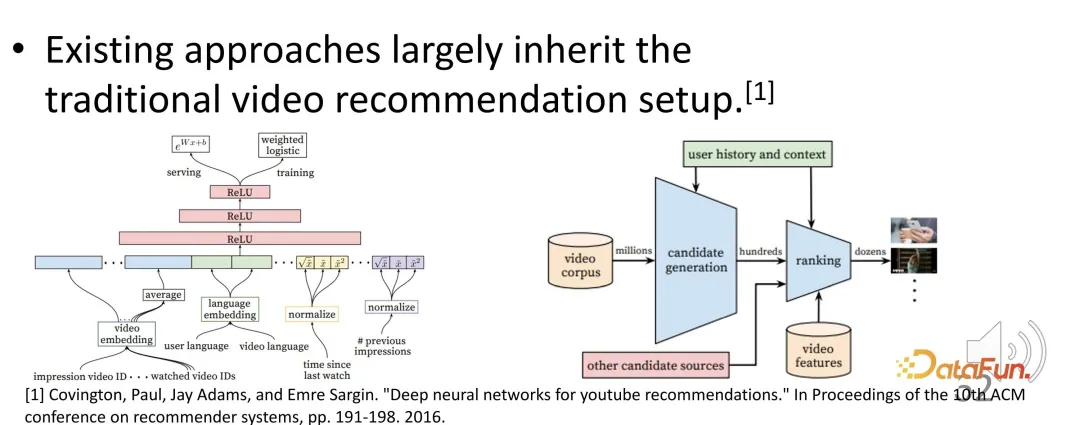
For example, how to evaluate user satisfaction and activity in short video recommendations? What is the optimization goal? Common optimization goals are watch time or watch progress. Short videos that are estimated to have higher completion rates and viewing times may be ranked higher by the recommendation system. It may be optimized based on the viewing time during training, and sorted based on the estimated viewing time during service, and videos with higher viewing time are recommended.
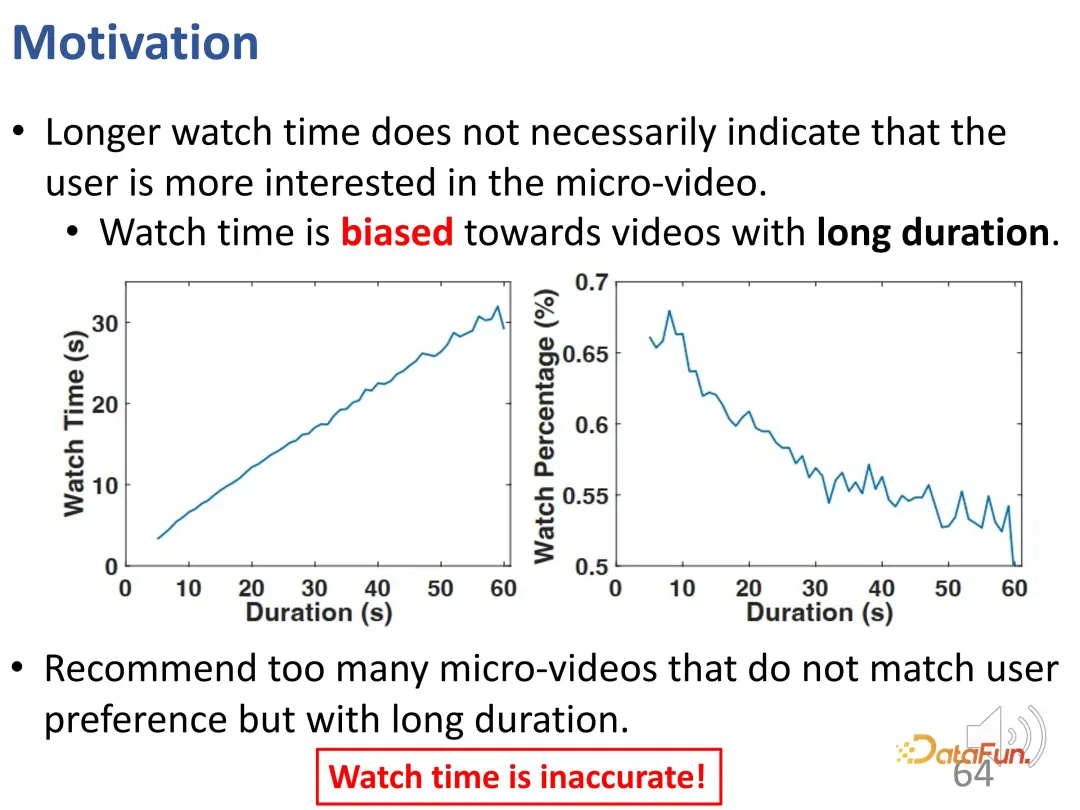
However, a problem in short video recommendation is that longer viewing time does not necessarily mean that the user is very interested in the short video, that is, the duration of the short video itself is a very Important deviations. In recommendation systems using the above optimization goals (viewing time or viewing progress), longer videos have a natural advantage. Recommending too many long videos of this kind may not match the user's interests, but due to the operational cost of users skipping the video, the actual online test or offline training evaluation will be very high. Therefore, relying solely on watch time is not enough.
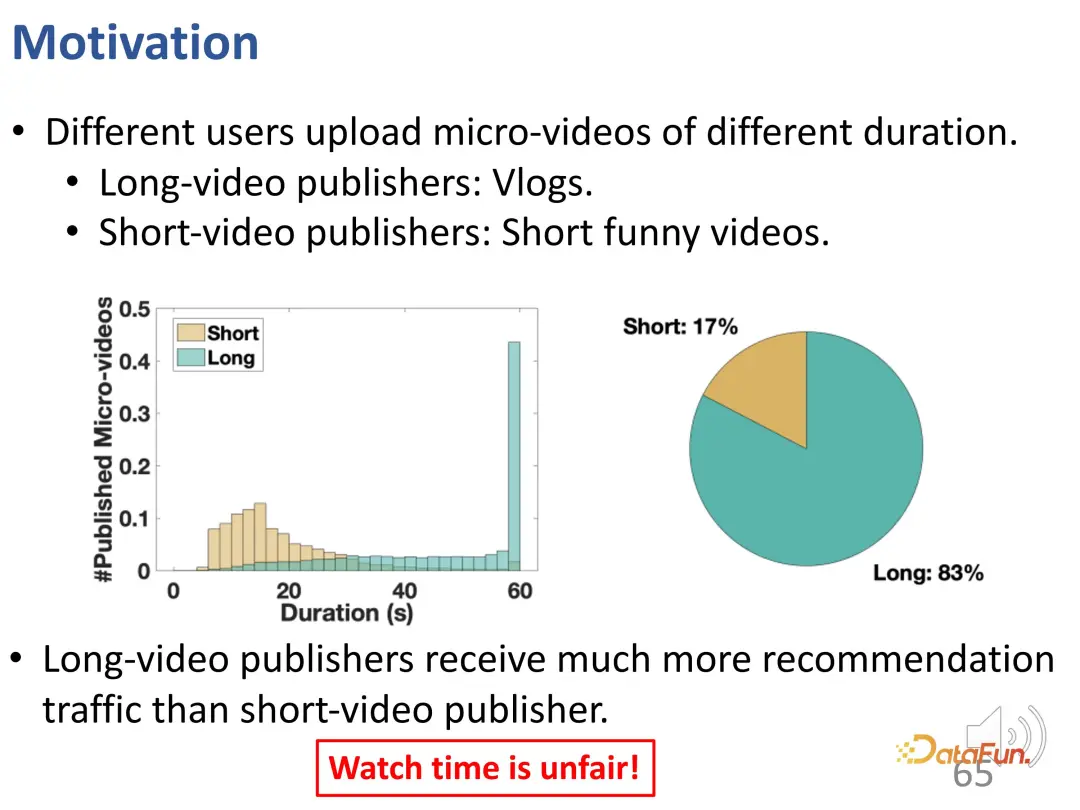
As you can see, there are two forms in the short video. One is longer videos like vlogs, while the other is shorter entertainment videos. After analyzing the real traffic, we found that users who publish long videos basically get more recommended traffic, and this ratio is very different. Using watch time alone to evaluate not only fails to meet users’ interests, but may also be unfair.
In this work, we hope to solve two problems:
#In fact, the core challenge is that short videos of different lengths cannot be directly compared. Since this problem is natural and ubiquitous in different recommender systems, and the structures of different recommender systems vary greatly, the designed method needs to be model-agnostic.
First, several representative methods were selected and simulated training was conducted using viewing duration.

It can be seen from the curve that the duration deviation is enhanced: compared with the ground truth curve, the recommendation model is significantly higher in the prediction result of long video viewing time. In predictive models, overrecommendation for long videos is problematic.
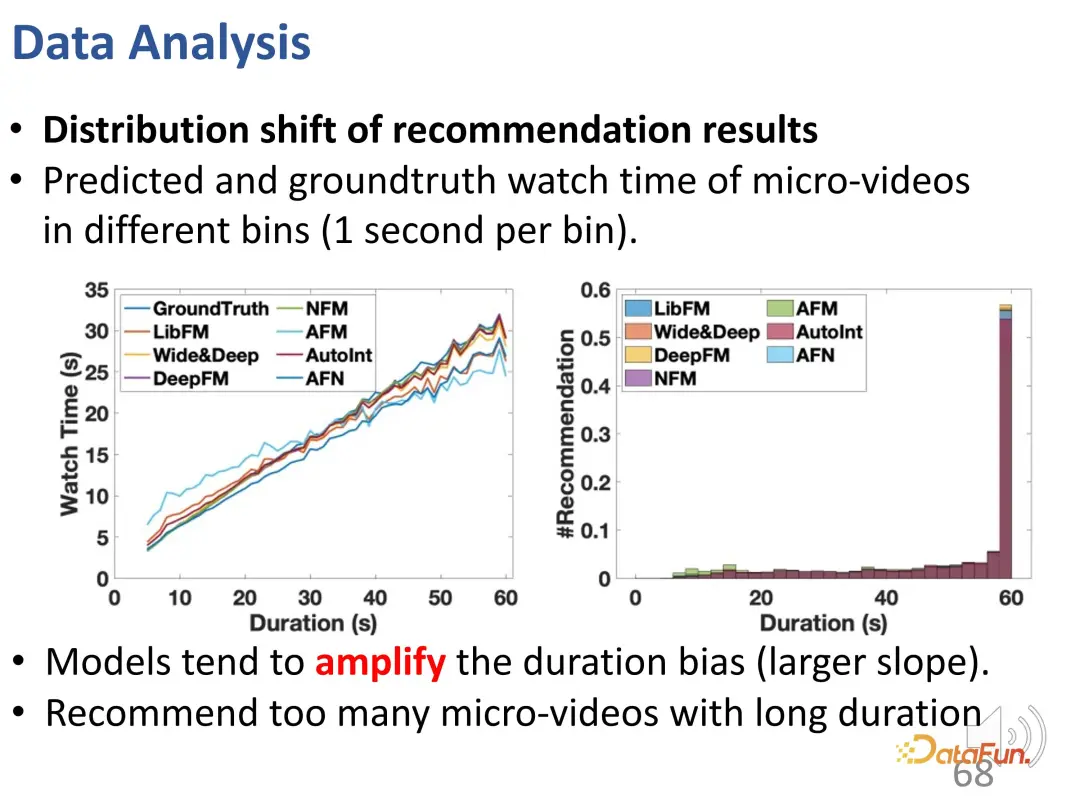
In addition, it was also found that there were many inaccurate recommendations (#BC) in the recommendation results.
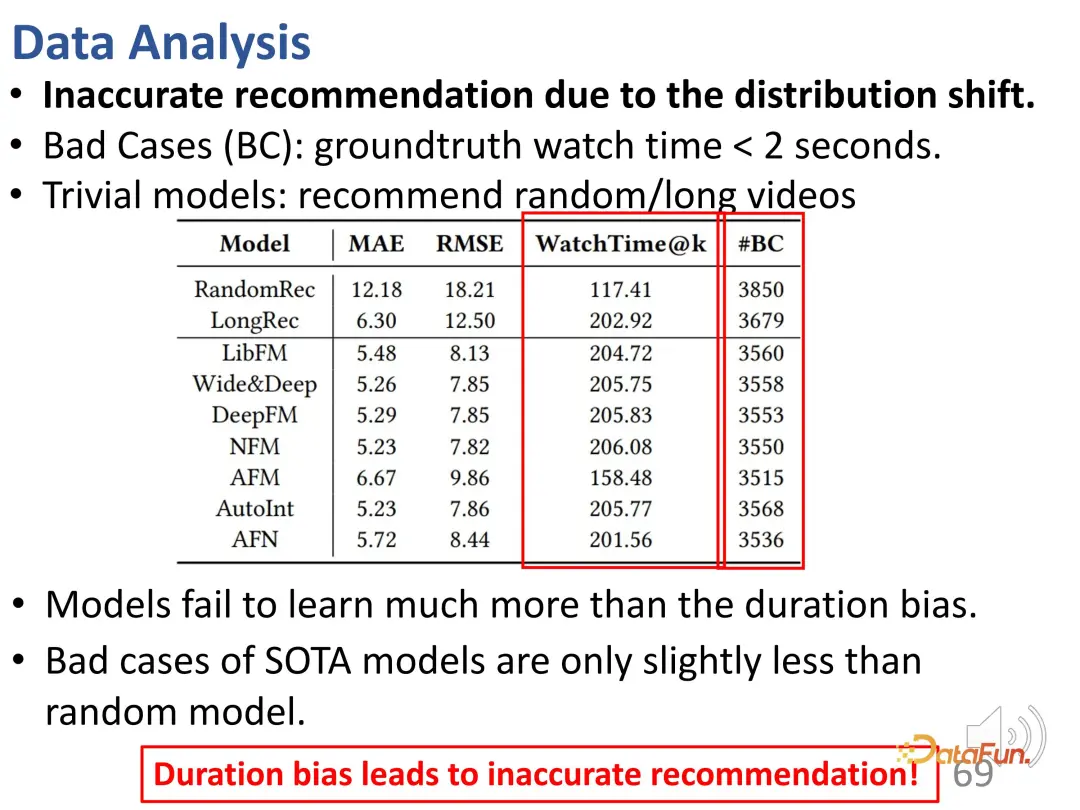
We can see some bad cases, that is, videos whose viewing time is less than 2 seconds and which users dislike very much. However, due to the influence of bias, these videos are incorrectly recommended. In other words, the model only learned the difference in duration of the recommended videos, and basically could only distinguish the length of the videos. Because the desired prediction result is to recommend longer videos to increase the user's viewing time. So the model selects long videos instead of videos that the user likes. It can be seen that these models even have the same number of bad cases as random recommendations, so this bias leads to very inaccurate recommendations.
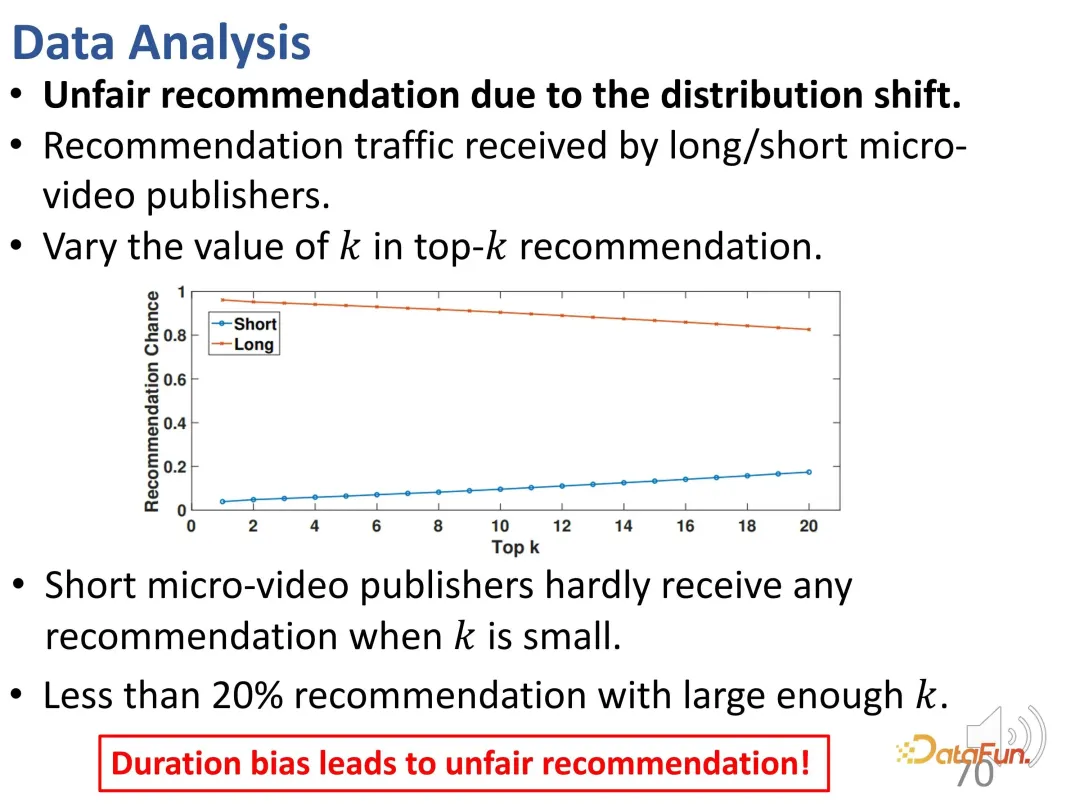
Furthermore, there is an issue of unfairness here. When the control top k value is small, shorter video publishers are difficult to recommend; even if the k value is large enough, the proportion of such recommendations is less than 20%.
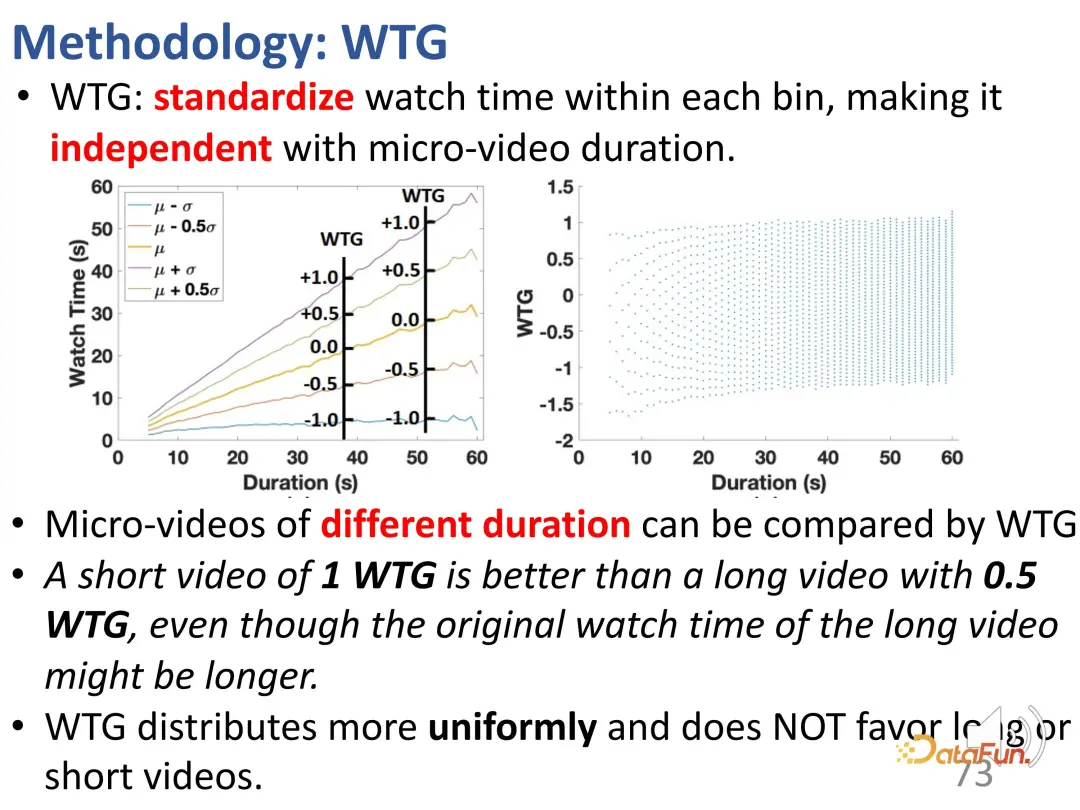
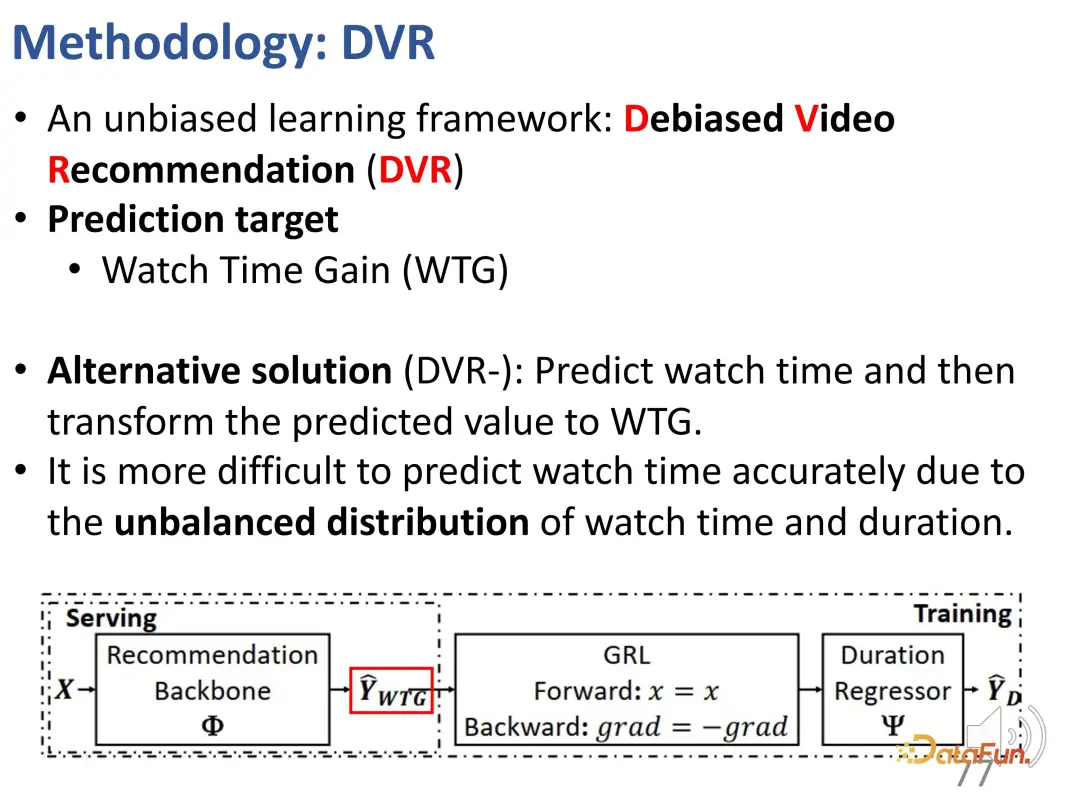
In order to solve this problem, we first proposed a method called WTG ( A new metric called Watch Time Gain that takes watch time into account to try to be unbiased. For example, a user watched a 60-second video for 50 seconds; another video was also 60 seconds long, but only watched for 5 seconds. Obviously, if you control for a 60-second video, the difference in interest between the two videos is obvious. This is a simple but effective idea. Watch duration is only meaningful when other video data are of similar duration.
First divide all videos into different duration groups at equal intervals, and then compare the user's interest intensity in each duration group. In the fixed duration group, the user's interests can be represented by the duration. After the introduction of WTG, WTG is actually used directly to express the user's interest intensity, without paying attention to the original duration. Under WTG ratings, the distribution is more even.

Based on WTG, the importance of sorting position is further considered. Because WTG only considers one indicator (a single point), this cumulative effect is further taken into account. That is, when calculating the index of each element in the sorted list, the relative position of each data point must also be taken into account. This idea is similar to NDCG. Therefore, on this basis, DCWTG was defined.

We previously defined indicators that can reflect user interests regardless of duration, namely WTG and NDWTG. Next, design a recommendation method that can eliminate bias, is independent of the specific model, and is applicable to different backbones. The method DVR (Debiased Video Recommendation) is proposed. The core idea is that in the recommendation model, if the features related to duration can be removed, even if the input features are complex and may contain duration-related information, as long as they can be used during the learning process. If the output of the model ignores these duration features, it can be considered to be unbiased, which means that the model can filter out duration-related features to achieve unbiased recommendations. This involves a confrontational idea, which requires another model to predict the duration based on the output of the recommendation model. If it cannot accurately predict the duration, then it is considered that the output of the previous model does not contain duration features. Therefore, an adversarial learning method is used to add a regression layer to the recommendation model, which predicts the original duration based on the predicted WTG. If the backbone model can indeed achieve unbiased results, then the regression layer will not be able to re-predict and restore the original duration.
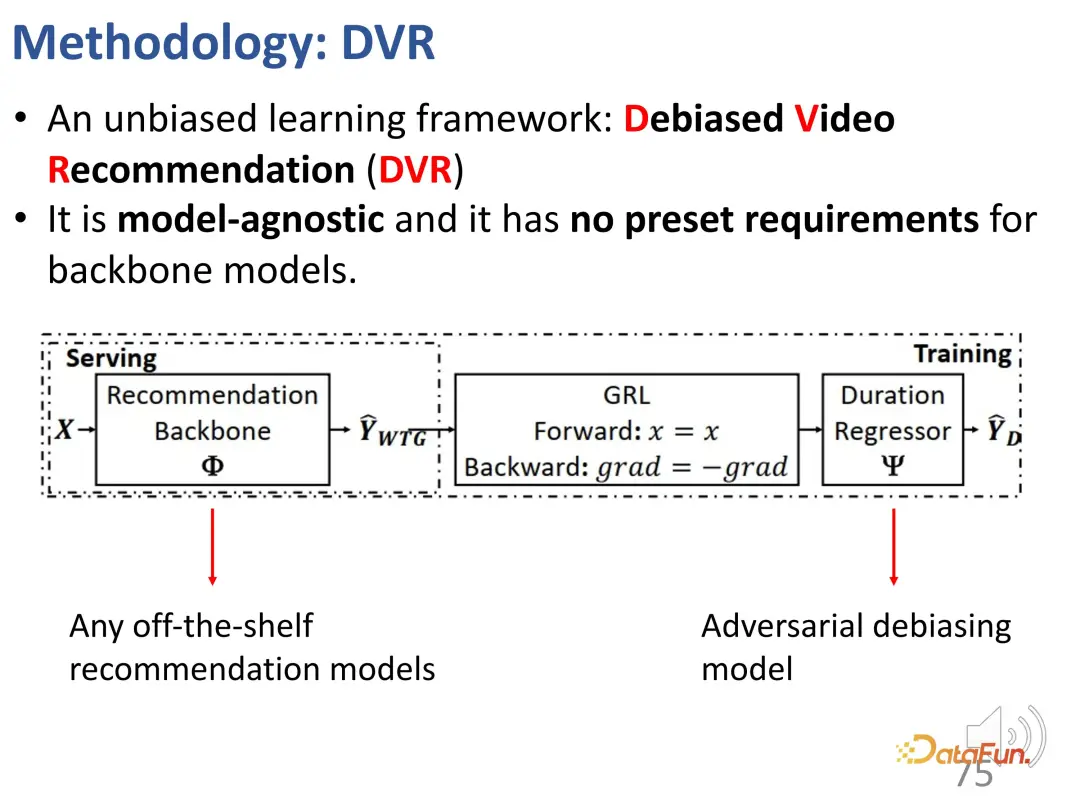


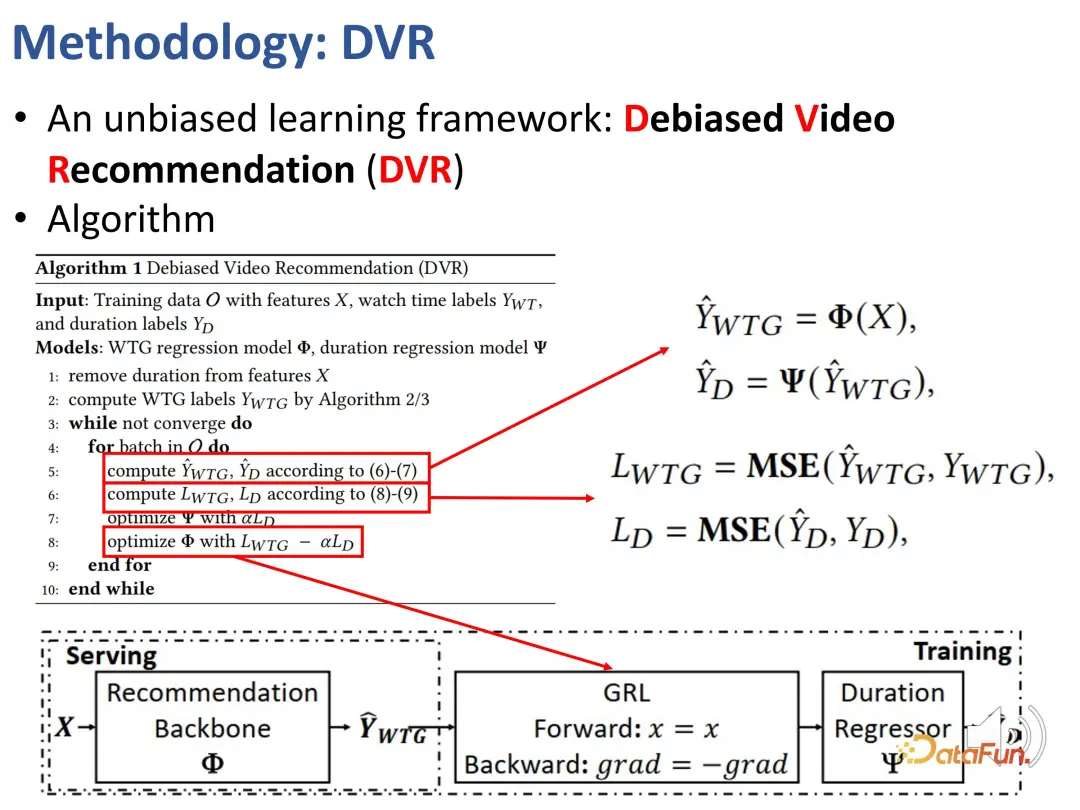
#The above are the details of this method, which is used to implement adversarial learning.
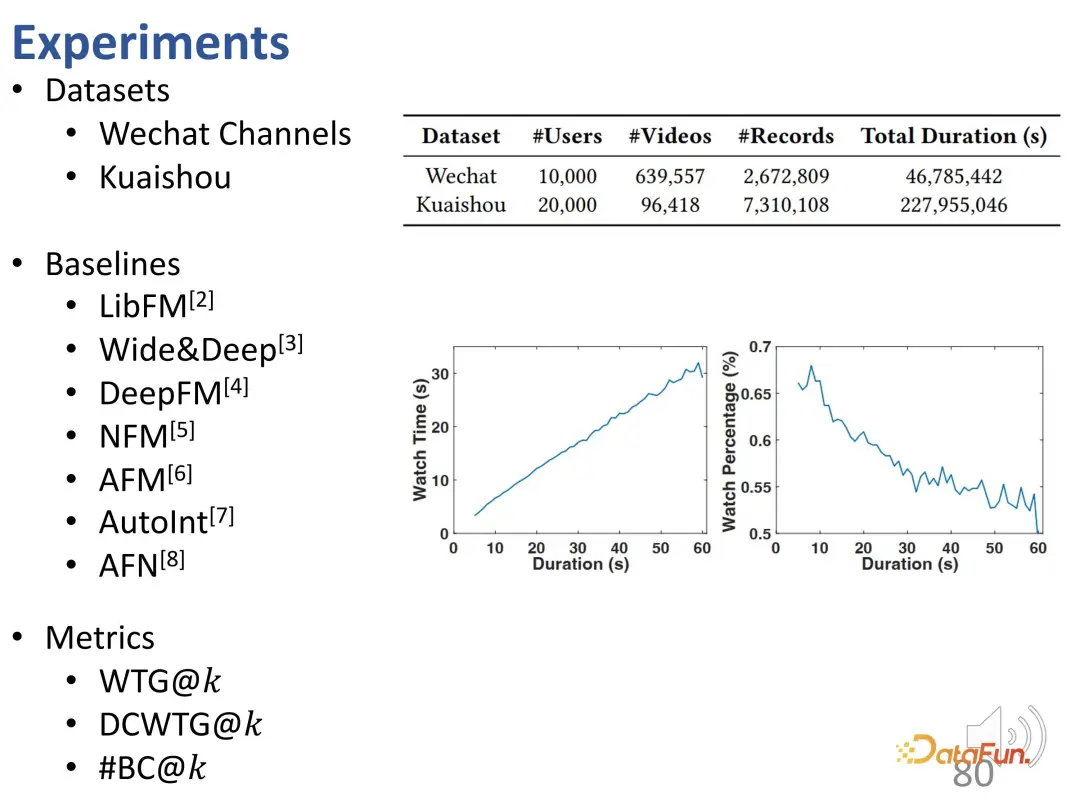
The experiment was conducted on two data sets of WeChat and Kuaishou . The first is WTG versus watch time. It can be seen that the two optimization objectives are used separately and compared with the viewing duration in the ground truth. After using WTG as the target, the model's recommendation effect is better on both short videos and long videos, and the WTG curve is stably located above the viewing time curve.
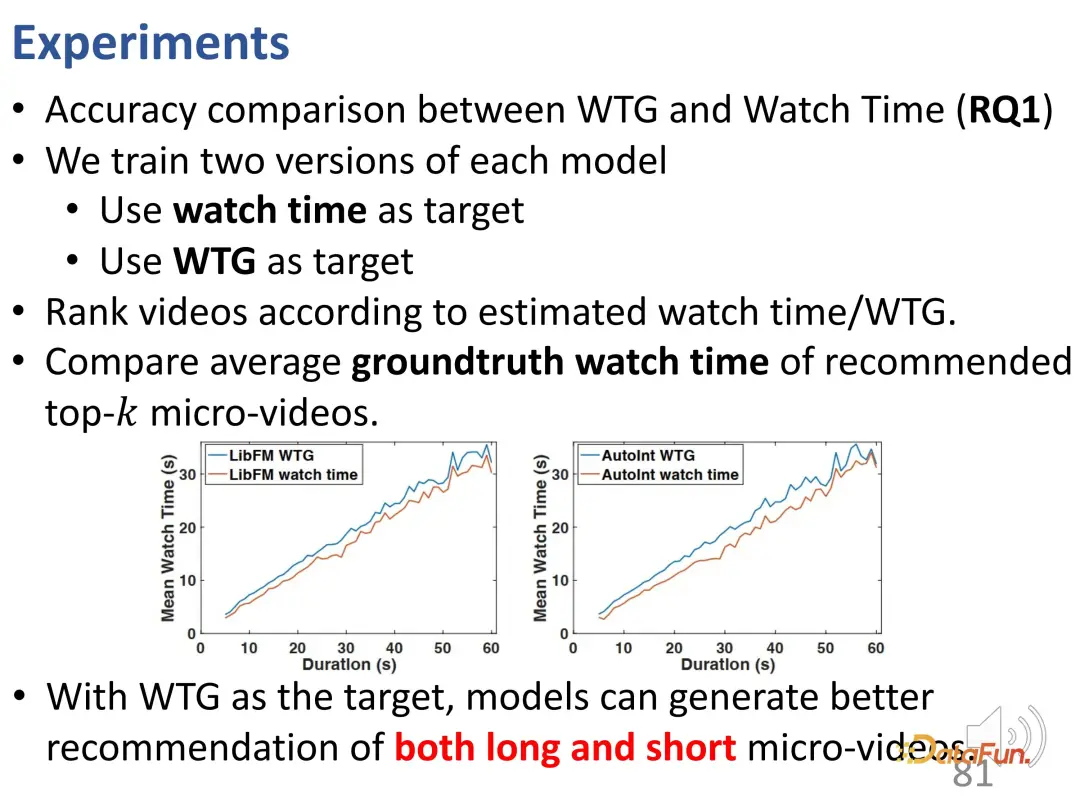
In addition, using WTG as a target brings a more balanced long and short video recommendation traffic (the recommendation share of long videos in the traditional model is obviously more many).

The proposed DVR method is suitable for different backbone models: 7 common backbone models were tested, and the results showed the performance without using the debiasing method Poor, while DVR has certain improvements in all backbone models and all indicators.

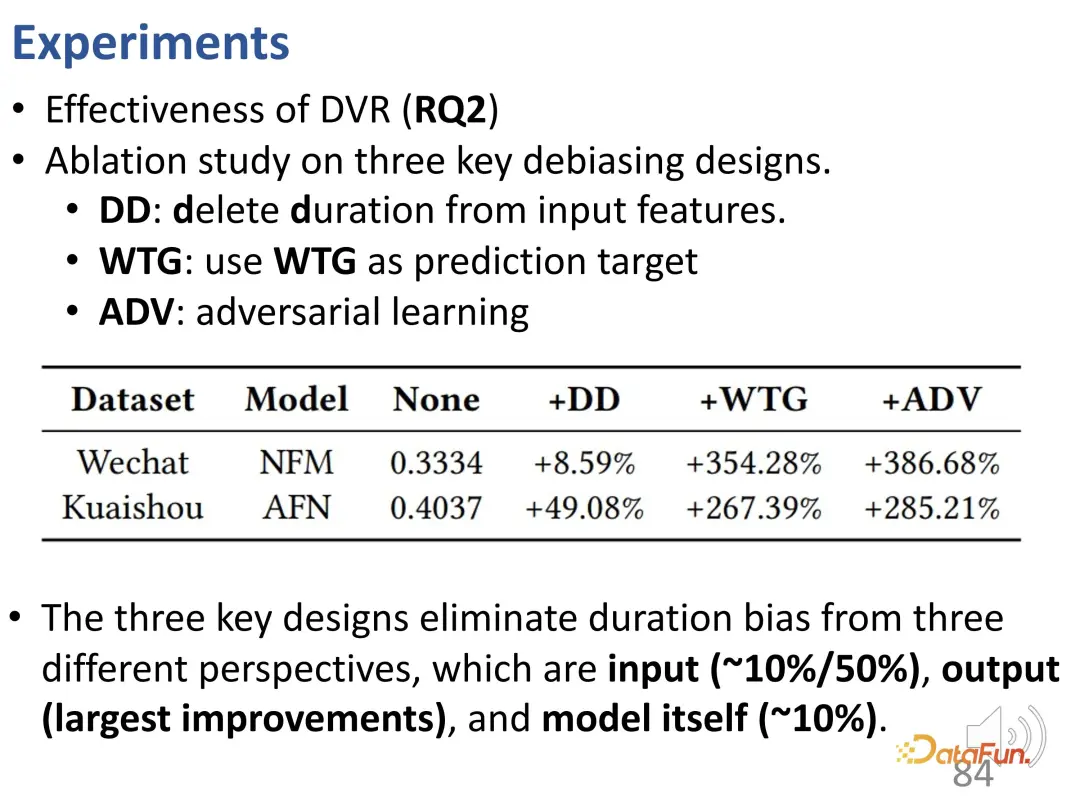
further conducted some ablation experiments. As mentioned in the previous article, this method has three parts of the design, and these three parts have been removed respectively. The first is to remove duration as an input feature, the second is to remove WTG as a prediction target, and the third is to remove the adversarial learning method. You can see that removing each part will lead to performance degradation. Therefore, all three designs are crucial.
Summary of our work: study short video recommendation from the perspective of reducing deviations and pay attention to duration deviation. First, a new indicator is proposed: WTG. It does a good job of eliminating the bias in actual behavior (user interests and duration). Second, a general method is proposed so that the model is no longer affected by video duration, thereby producing unbiased recommendations.

Finally, summarize this sharing. First, understand entanglement learning on user interests and conformity. Next, the disentanglement of long-term and short-term interests is studied in terms of sequential behavior modeling. Finally, a debiasing learning method is proposed to solve the problem of viewing duration optimization in short video recommendation.
The above is the content shared this time, thank you all.
[1] Gao et al. Causal Inference in Recommender Systems: A Survey and Future Directions, TOIS 2024
[2] Zheng et al. Disentangling User Interest and Conformity for Recommendation with Causal Embedding, WWW 2021.
[3] Zheng et al. DVR:Micro-Video Recommendation Optimizing Watch- Time-Gain under Duration Bias, MM 2022
[4] Zheng et al. Disentangling Long and Short-Term Interests for Recommendation, WWW 2022.
The above is the detailed content of Recommender systems based on causal inference: review and prospects. For more information, please follow other related articles on the PHP Chinese website!
 Python online playback function implementation method
Python online playback function implementation method There are several output and input functions in C language
There are several output and input functions in C language Commonly used shell commands in Linux
Commonly used shell commands in Linux Application of artificial intelligence in life
Application of artificial intelligence in life How to use hover in css
How to use hover in css What currency is BTC?
What currency is BTC? How to delete data in MongoDB
How to delete data in MongoDB How to recover data after formatting
How to recover data after formatting




















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



