The combination of large models and AI databases has become a magic weapon for cost reduction and efficiency improvement of large models and truly intelligent big data.

The wave of large models (LLM) has been surging for more than a year, especially with GPT-4, Gemini-1.5, Claude-3 The models represented by You Fang and I will appear on stage and become a well-deserved center of attention. On the LLM track, some research focuses on increasing model parameters, and some are crazy about multi-modality... Among them, LLM's ability to process context length has become an important indicator for evaluating models. A stronger context means that the model Have stronger retrieval performance. For example, the ability of some models to process up to 1 million tokens in one go has led many researchers to think about whether the RAG (Retrieval-Augmented Generation) method is still necessary? Some people think that RAG will be killed by the long context model, but this view has been refuted by many researchers and architects. They believe that on the one hand, data structures are complex, change regularly, and many data have important time dimensions, which may be too complex for LLM. On the other hand, it is unrealistic to put all the massive heterogeneous data of enterprises and industries into the context window. The combination of large models and AI databases injects professional, accurate and real-time information into the generative AI system, greatly reducing illusions and improving the practicality of the system. At the same time, the Data-centric LLM method can also take advantage of the massive data management and query capabilities of AI databases to significantly reduce the cost of large model training and fine-tuning, and support small sample tuning in different scenarios of the system. In summary, the combination of large models and AI databases not only reduces costs and increases efficiency for large models, but also makes big data truly intelligent. After several years of development and iteration, MyScaleDB is finally open sourceThe emergence of RAG makes LLM can accurately extract information from large-scale knowledge bases and generate real-time, professional, and insightful answers. Along with this, the vector database, the core function of the RAG system, has also developed rapidly. According to the design concept of vector database, we can roughly divide it into three categories: dedicated vector database, retrieval system combining keywords and vectors, and SQL vector database.
- Specialized vector databases represented by Pinecone/Weaviate/Milvus were designed and built for vector retrieval from the beginning. The vector retrieval performance is excellent, but it is not universal. The data management function is weak.
- Keyword and vector retrieval systems represented by Elasticsearch/OpenSearch are widely used in production because of their complete keyword retrieval functions. However, they occupy a lot of system resources, and keywords and vectors The accuracy and performance of the joint query are not satisfactory.
- SQL vector databases represented by pgvector (vector search plug-in for PostgreSQL) and MyScale AI database are based on SQL and have powerful data management functions. However, due to the disadvantages of PostgreSQL row storage and the limitations of vector algorithms, pgvector has low accuracy in complex vector queries.
MyScale AI Database (MyScaleDB) Based on a high-performance SQL column storage database, self-developed with high performance and high data density Vector index algorithm, and the retrieval and storage engine have been deeply developed and optimized for joint queries of SQL and vectors. is the world's first SQL vector database product whose comprehensive performance and cost-effectiveness greatly exceeds that of a dedicated vector database. Thanks to the long-term polishing of SQL database in massive structured data scenarios, MyScaleDB supports both massive vector and structured data, including strings, Efficient storage and query of multiple data types such as JSON, space, time series, etc., and will launch powerful inverted table and keyword retrieval functions in the near future to further improve the accuracy of the RAG system and replace systems such as Elasticsearch. 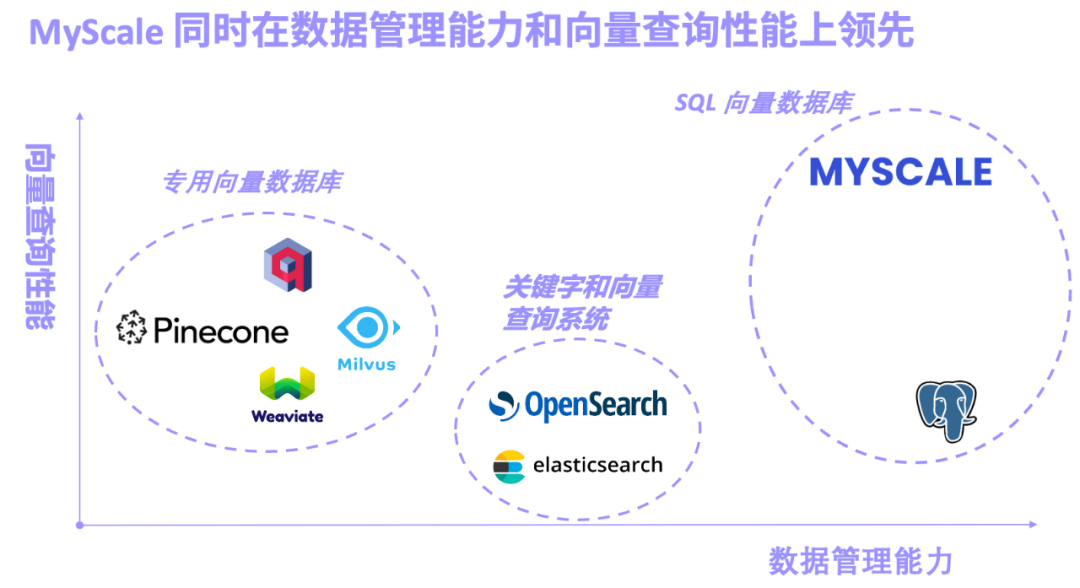
After nearly 6 years of development and several version iterations, MyScaleDB has recently been open sourced. All developers and enterprise users are welcome to star on GitHub and open up a new way of using SQL to build production-level AI applications! Project address: https://github.com/myscale/myscaledbFully compatible with SQL, improved accuracy , cost reductionWith the help of complete SQL data management capabilities, powerful and efficient structured, vector and heterogeneous data storage and query capabilities, MyScaleDB is expected to become the first An AI database that is truly oriented to large models and big data. Native compatibility with SQL and vectorsHalf a century since the birth of SQL , despite experiencing waves such as NoSQL and big data, the ever-evolving SQL database still occupies a major share of the data management market, and even retrieval and big data systems such as Elasticsearch and Spark have successively supported SQL interfaces. Although dedicated vector databases have been optimized and system designed for vectors, their query interfaces usually lack standardization and do not have advanced query languages. This results in weak generalization capabilities of the interface. For example, Pinecone’s query interface does not even include specifying the fields to be retrieved, let alone common database functions such as paging and aggregation.
#The weak generalization ability of the interface means that it changes frequently, which increases the learning cost. The MyScale team believes that
the systematically optimized SQL and vector system can maintain complete SQL support while ensuring high performance of vector retrieval, and the results of their open source evaluation have fully demonstrated this. .
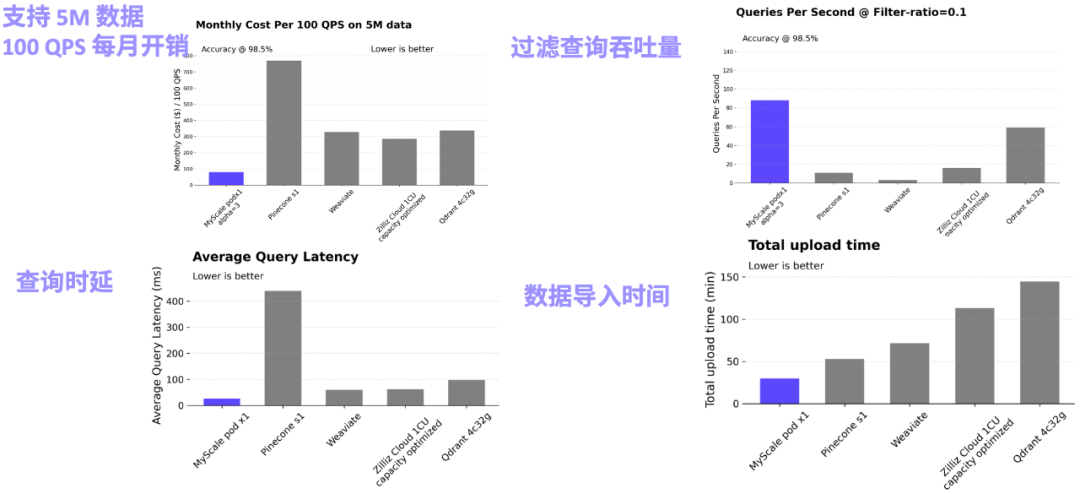
In actual complex AI application scenarios, the combination of SQL and vectors can greatly increase the flexibility of data modeling and simplify the development process. For example, in the Science Navigator project cooperating between the MyScale team and the Beijing Institute of Scientific Intelligence, MyScaleDB is used to retrieve massive scientific literature data and perform intelligent question answering. There are more than 10 main SQL table structures, many of which establish vectors. And inverted table index, and use the primary key and foreign key to make the association. In actual queries, the system will also involve joint queries of structured, vector and keyword data, as well as related queries of several tables. These modeling and correlations are difficult to achieve in a dedicated vector database, which will also lead to slow iteration of the final system, inefficient querying and difficult maintenance. Science Navigator main table structure diagram (bold columns establish vector indexes or inverted indexes) Support joint query of structured, vector and keyword dataIn the actual RAG system, the accuracy and effect of retrieval are the main bottlenecks restricting its implementation. This requires the AI database to efficiently support joint queries of structured, vector and keyword data to comprehensively improve retrieval accuracy. For example, in a financial scenario, the user needs to query the document library "What is the revenue of a certain company's global businesses in 2023?", "A certain company", "2023 Year" and other structured meta-information cannot be well captured by vectors, and may not even be directly reflected in the corresponding paragraphs. Performing vector retrieval directly on the entire database will obtain a large amount of noise information and reduce the final accuracy of the system. On the other hand, company name, year, etc. can usually be obtained as meta-information of the document. We can use WHERE year=2023 AND company ILIKE "%%" as the filter condition of vector query to accurately locate Relevant information is obtained, which greatly improves the reliability of the system. In finance, manufacturing, scientific research and other scenarios, the MyScale team has observed the power of heterogeneous data modeling and related queries. In many scenarios, the accuracy is even 60% to 90% improvement. Although traditional database products have gradually realized the importance of vector queries in the AI era and have begun to add vector capabilities to the database, there are still significant problems with the accuracy of their joint queries. . For example, in the scenario of filtering queries, when the filtering ratio is 0.1, the QPS of Elasticsearch will drop to only about 5, while the retrieval accuracy of PostgresSQL (using the pgvector plug-in) is only about 50% when the filtering ratio is 0.01, making the query unstable. Accuracy/performance greatly restricts its application scenarios. And MyScale only uses 36% of the cost of pgvector and 12% of the cost of ElasticSearch, to achieve high performance and high precision queries in various scenarios with different filtering ratios.
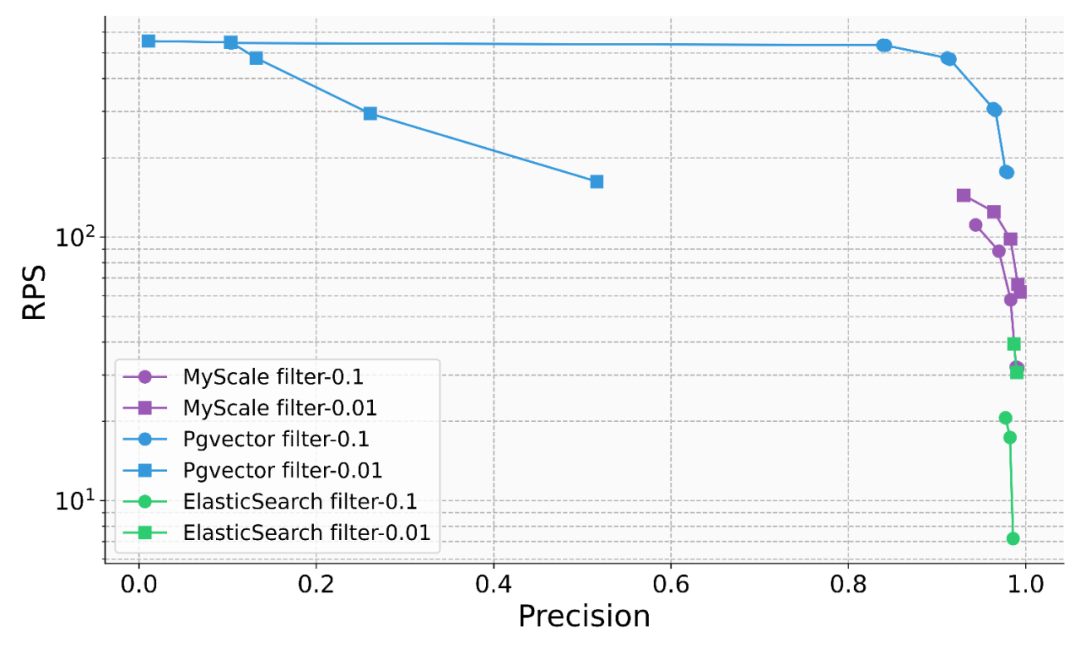
In different filtering proportion scenarios, myscale achieves high precision and high performance query The balance between performance and cost in real scenarios
Because of the importance and high attention of vector retrieval in large model applications, more and more The team invested in the vector database track. Everyone’s initial focus was on improving QPS in pure vector search scenarios, but pure vector search is far from enough
! In actual combat scenarios, data modeling, query flexibility and accuracy, and balancing data density, query performance and cost are more important issues.
In the RAG scenario, pure vector query performance has a 10x excess, vectors occupy huge resources, lack of joint query functions, poor performance and accuracy are often the result of current proprietary vectors Database normality. MyScaleDB is committed to improving the comprehensive performance of AI databases in real massive data scenarios
. Its MyScale Vector Database Benchmark is also the first in the industry to compare mainstream vector database systems with a scale of five million vectors and different query scenarios. An open source evaluation system for performance and cost-effectiveness. Everyone is welcome to pay attention and raise issues. The MyScale team said that there is still a lot of room for optimization of the AI database in real application scenarios, and they also hope to continue to polish the product and improve the evaluation system in practice.
MyScale Vector Database Benchmark project address: https://github.com/myscale/vector-db-benchmark
Outlook: Big model big data Agent platform supported by AI database
Machine learning big data drives the Internet and the Internet The success of a generation of information systems, and in the context of the era of large models, the MyScale team is also committed to proposing a new generation of large model and big data solutions. With high-performance SQL vector database as a solid support, MyScaleDB provides the key capabilities of large-scale data processing, knowledge query, observability, data analysis and small sample learning, building an AI and data closed loop, Become the key base of the next generation big model big data Agent platform
. The MyScale team has already explored the implementation of this solution in scientific research, finance, industry, medical and other fields. 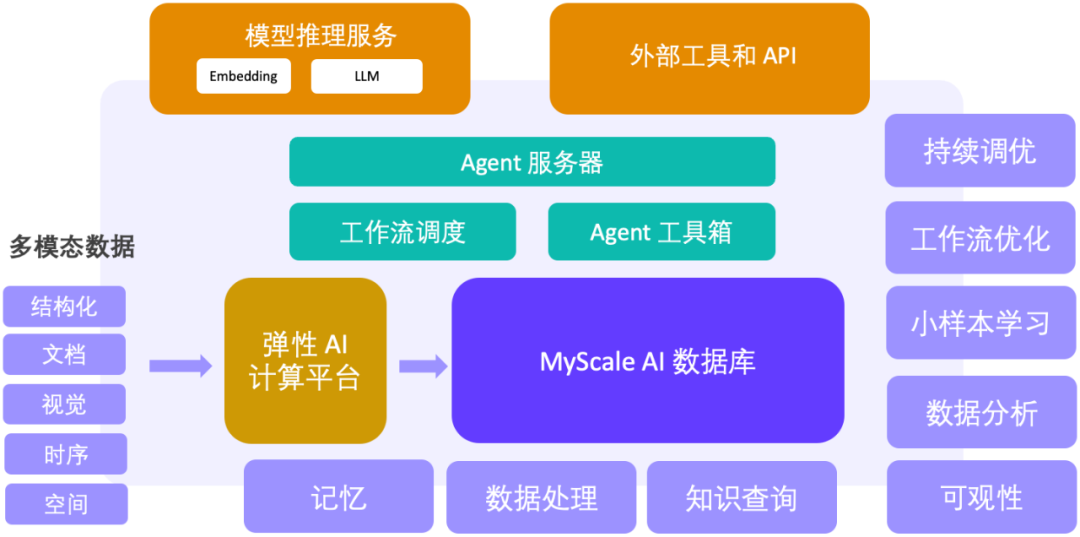
###With the rapid development of technology, some sense of artificial general intelligence (AGI) is expected to appear in the next 5-10 years. Regarding this issue, we can’t help but think: Is a large model that is static, virtual, and competitive with humans needed, or is there another more comprehensive solution? Data is undoubtedly an important link between large models, the world, and users. The MyScale team's vision is to organically combine large models and big data to create an AI system that is more professional, real-time, and efficient in collaboration, but also full of human warmth and value. ###
The above is the detailed content of Long text cannot kill RAG: SQL+ vector drives large models and the new paradigm of big data, MyScale AI database is officially open source. For more information, please follow other related articles on the PHP Chinese website!
































![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



