


How much human knowledge can a 7B scale language model LLM store? How to quantify this value? How will differences in training time and model architecture affect this value? What impact will floating-point compression quantization, mixed expert model MoE, and differences in data quality (encyclopedia knowledge vs. Internet garbage) have on the knowledge capacity of LLM?
The latest research by Zhu Zeyuan (Meta AI) and Li Yuanzhi (MBZUAI) "Language Model Physics Part 3.3: Scaling Laws of Knowledge" uses massive experiments (50,000 tasks, a total of 4,200,000 GPU hours ) summarizes 12 laws and provides a more accurate measurement method for the knowledge capacity of LLM under different documents.

The author first points out that it is unrealistic to measure the scaling law of LLM through the performance of open source models on benchmark data sets (benchmark). For example, LLaMA-70B performs 30% better than LLaMA-7B on the knowledge data set. This does not mean that expanding the model by 10 times can only increase the capacity by 30%. If a model is trained using network data, it will also be difficult to estimate the total amount of knowledge contained in it.
For another example, when we compare the quality of the Mistral and Llama models, is the difference caused by their different model architectures, or is it caused by the different preparation of their training data?
Based on the above considerations, the author adopts the core idea of their "Language Model Physics" series of papers, which is to create artificially synthesized data and strictly control the amount and type of knowledge in the data. Regulate the knowledge bits in the data. At the same time, the author uses LLMs of different sizes and architectures to train on synthetic data, and gives mathematical definitions to accurately calculate how many bits of knowledge the trained model has learned from the data.

For this research, someone It seems reasonable to indicate this direction. We can analyze scaling law in a very scientific way.
Some people also believe that this research takes scaling law to a different level. Certainly a must-read paper for practitioners.
The authors studied three types of synthetic data: bioS, bioR, bioD . bioS is a biography written using English templates, bioR is a biography written with the help of the LlaMA2 model (22GB total), bioD is a kind of virtual knowledge data that can further control the details (for example, the length of the knowledge and the vocabulary can be controlled Wait for details). The authorfocuses on the language model architecture based on GPT2, LlaMA, and Mistral, among which GPT2 uses the updated Rotary Position Embedding (RoPE) technology.
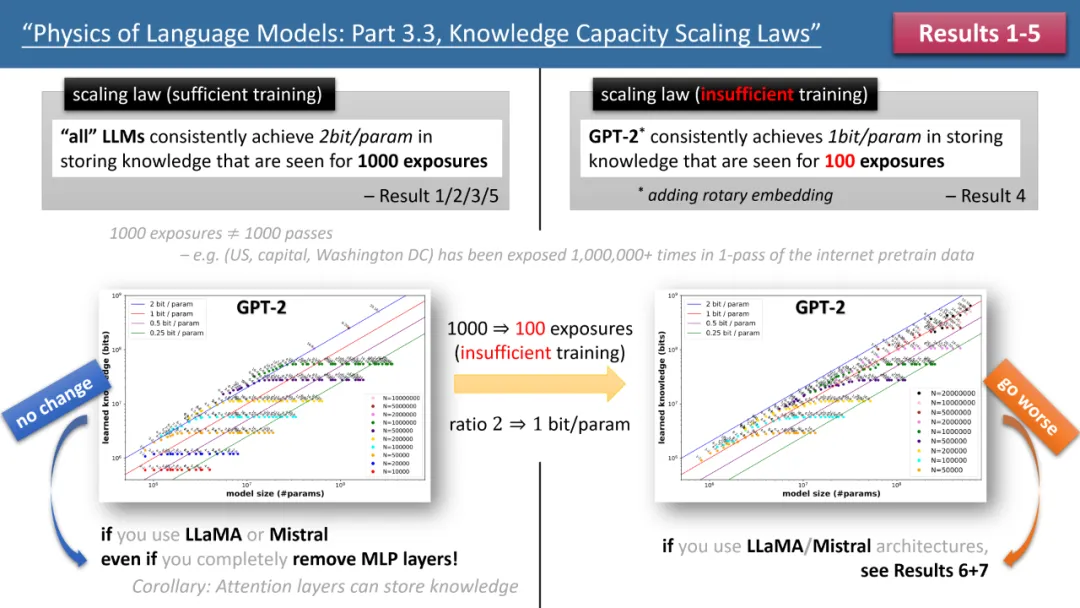
The picture on the left shows the scaling laws with sufficient training time, and the picture on the right shows scaling laws with insufficient training time
Top Figure 1 briefly summarizes the first 5 laws proposed by the author. The left/right correspond to the two situations of "sufficient training time" and "insufficient training time" respectively, which respectively correspond to common knowledge (such as the capital of China is Beijing) and less Emerging knowledge (for example, the Department of Physics at Tsinghua University was established in 1926).
If the training time is sufficient, the author found that no matter which model architecture is used, GPT2 or LlaMA/Mistral, the storage efficiency of the model can reach 2bit/param - that is, the average per model Parameters can store 2 bits of information. This has nothing to do with model depth, only model size. In other words, a 7B model, if adequately trained, can store 14B bits of knowledge, which is more than the human knowledge in Wikipedia and all English textbooks combined!
What is even more surprising is that although the traditional theory is that the knowledge in the transformer model is mainly stored in the MLP layer, the author's research refutes this view. They found that even if all MLP layers are removed, the model still It can achieve a storage efficiency of 2bit/param.
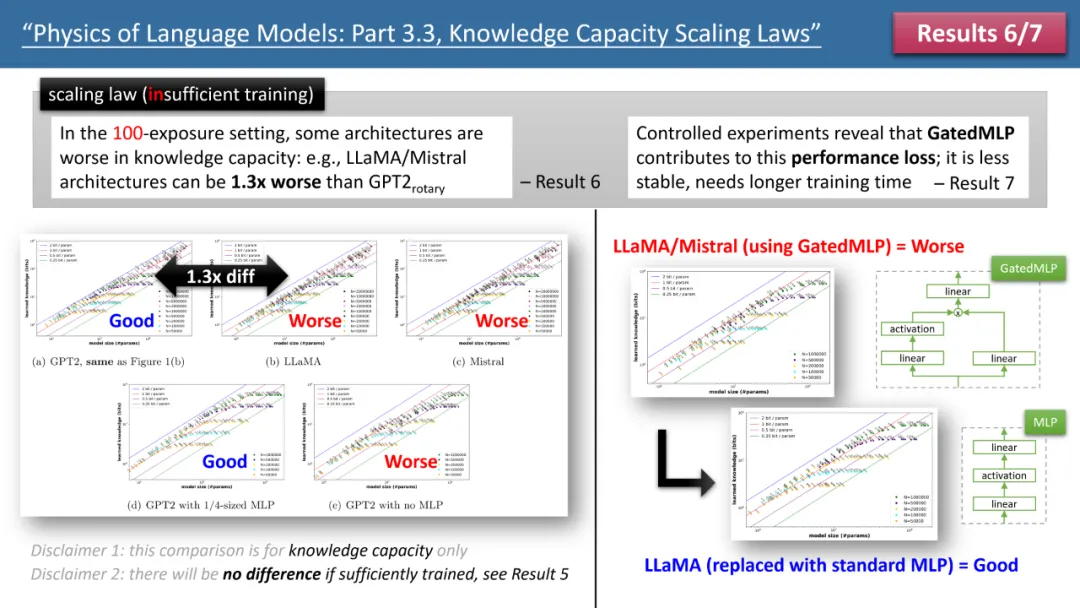
Figure 2: Scaling laws when training time is insufficient
However, when we observe the training When time is insufficient, differences between models become apparent. As shown in Figure 2 above, in this case, the GPT2 model can store 30% more knowledge than LlaMA/Mistral, which means that the model from a few years ago surpasses today's model in some aspects. Why is this happening? The author made architectural adjustments on the LlaMA model, adding or subtracting each difference between the model and GPT2, and finally found that GatedMLP caused the 30% loss.
To emphasize, GatedMLP does not cause a change in the "final" storage rate of the model - because Figure 1 tells us that they will not be different if the training is sufficient. However, GatedMLP will lead to unstable training, so the same knowledge requires longer training time; in other words, for knowledge that rarely appears in the training set, the storage efficiency of the model will decrease.
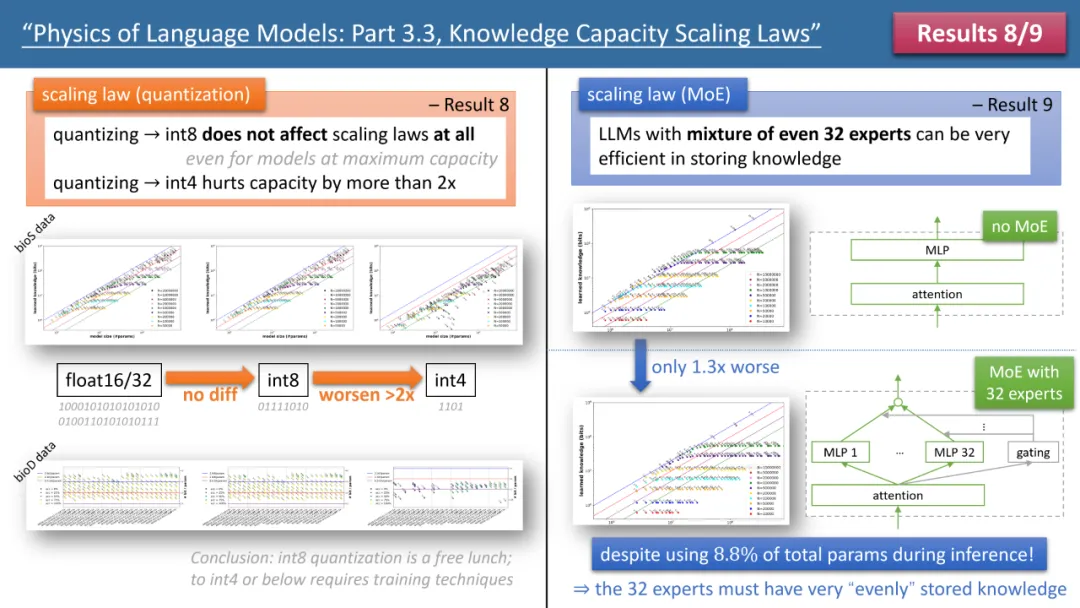
The author’s laws 8 and Law 9 separately studies the impact of quantization and MoE on the model scaling law, and the conclusion is shown in Figure 3 above. One result is that compressing the trained model from float32/16 to int8 has no impact on the storage of knowledge, even for models that have reached the 2bit/param storage limit.
This means that LLM can reach 1/4 of the "information theory limit" - because the int8 parameter is only 8 bits, but on average each parameter can store 2 bits of knowledge. The author points out that this is a universal law and has nothing to do with the form of knowledge expression.
The most striking results come from the authors’ laws 10-12 (see Figure 4). If our (pre-)training data, 1/8 comes from high-quality knowledge bases (such as Baidu Encyclopedia), and 7/8 comes from low-quality data (such as common crawl or forum conversations, or even completely random garbage data).
So,
Will low-quality data affect LLM’s absorption of high-quality knowledge? The results are surprising. Even if the training time for high-quality data remains consistent, the "existence itself" of low-quality data may reduce the model's storage of high-quality knowledge by 20 times! Even if the training time on high-quality data is extended by 3 times, the knowledge reserve will still be reduced by 3 times. This is like throwing gold into the sand, and high-quality data is being wasted.
Is there any way to fix it? The author proposed a simple but extremely effective strategy, which simply adds your own website domain name token to all (pre)training data. For example, add all Wikipedia data to wikipedia.org. The model does not require any prior knowledge to identify which websites have "gold" knowledge, but canautomatically discoverwebsites with high-quality knowledge during the pre-training process, andautomaticallyThis high-quality data frees up storage space.
The author proposed a simple experiment to verify: if high-quality data is added with a special token (any special token will do, the model does not need to know which token it is in advance), then The knowledge storage capacity of the model can be increased by 10 times immediately. Isn’t it amazing? Therefore, adding domain name token to pre-training data is an extremely important data preparation operation.
Figure 4: Scaling laws, model defects and how to repair them when pre-training data has "inconsistent knowledge quality"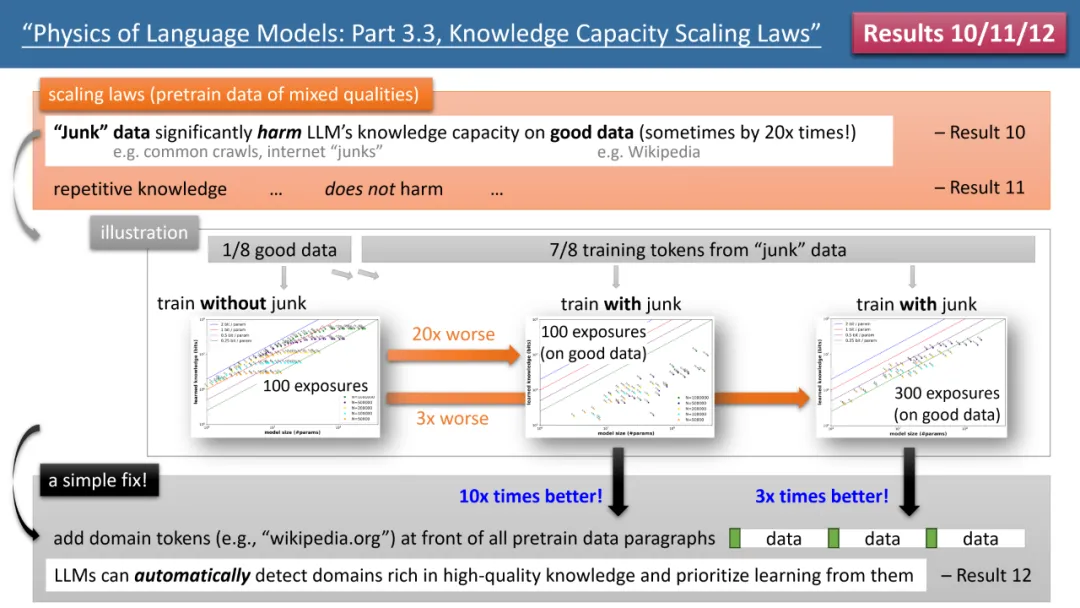
Conclusion
The above is the detailed content of Is the Llama architecture inferior to GPT2? Magical token improves memory 10 times?. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



