


Exhibits excellent accuracy in deep neural networks (DNNs). However, they show vulnerability to additional noise, i.e., adversarial attacks. Previous research hypothesized that this vulnerability may stem from the over-reliance of high-accuracy DNNs on insignificant and unrestricted features such as texture and background. However, new research reveals that this vulnerability has nothing to do with the specific characteristics of highly accurate DNNs overly trusting irrelevant factors such as their weights and context.
At the recent AAAI 2024 academic conference, researchers from the University of Sydney revealed that "edge information extracted from images can provide highly relevant and robust information related to shape and background." Characteristics".

Paper link: https://ojs.aaai.org/index.php/AAAI/article/view/28110
These features help the pre-trained deep network improve its adversarial robustness without affecting its accuracy on clear images.
Researchers propose a lightweight and adaptable EdgeNet that can be seamlessly integrated into existing pre-trained deep networks, including Vision Transformers (ViTs), which is the latest A family of advanced models for visual classification.
EdgeNet is an edge extraction technique that processes edges extracted from clean natural images or noisy adversarial images, which can be injected into the pre-trained and frozen backbone depth The middle layer of the network. This deep network has excellent backbone robustness features and can extract features with rich semantic information. By inserting EdgeNet into such a network, one can take advantage of its high-quality backbone deep network
It should be noted that this approach brings minimal additional cost: using traditional The cost of edge detection algorithms (such as the Canny edge detector mentioned in the article) to obtain these edges is miniscule compared to the inference cost of deep networks; and the cost of training EdgeNet is similar to the cost of fine-tuning the backbone network using technologies such as Adapter. Up and down.
In order to inject the edge information in the image into the pre-trained backbone network, the author introduces a side branch network named EdgeNet. This lightweight, plug-and-play collateral network can be seamlessly integrated into existing pre-trained deep networks, including state-of-the-art models like ViTs.
By running on the edge information extracted from the input image, EdgeNet can generate a set of robust features. This process produces a robust feature that can be selectively injected into the pre-trained backbone deep network for freezing in the middle layers of the deep network.
By injecting these robust features, the network's ability to defend against adversarial perturbations can be improved. At the same time, since the backbone network is frozen and the injection of new features is selective, the accuracy of the pre-trained network in identifying unperturbed clear images can be maintained.
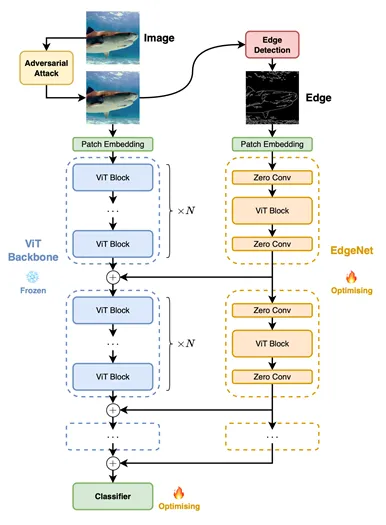
As shown in the figure, the author inserts new building blocks at a certain interval N based on the original building blocks 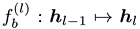 The EdgeNet building blocks
The EdgeNet building blocks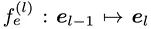 . The new intermediate layer output can be represented by the following formula:
. The new intermediate layer output can be represented by the following formula:
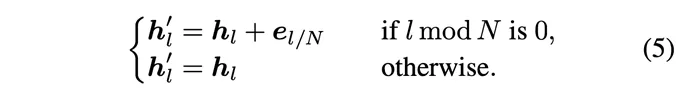
In order to achieve selective feature extraction and selectivity Feature injection, these EdgeNet building blocks adopt a "sandwich" structure: zero convolution is added before and after each block to control the input and output. Between these two zero convolutions is a ViT block with random initialization and the same architecture as the backbone network
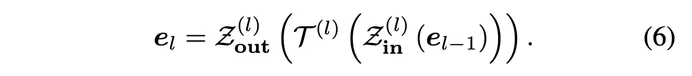
With zero input, 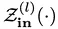 acts as a filter to extract information relevant to the optimization goal; with zero output, acts as a filter to determine the information to be integrated into the backbone. Additionally, with zero initialization, it is ensured that the flow of information within the backbone remains unaffected. As a result, subsequent fine-tuning of EdgeNet becomes more streamlined.
acts as a filter to extract information relevant to the optimization goal; with zero output, acts as a filter to determine the information to be integrated into the backbone. Additionally, with zero initialization, it is ensured that the flow of information within the backbone remains unaffected. As a result, subsequent fine-tuning of EdgeNet becomes more streamlined.
During the process of training EdgeNet, the pre-trained ViT backbone network is frozen except for the classification head and is not updated. The optimization goal focuses only on the EdgeNet network introduced for edge features, and the classification heads within the backbone network. Here, the author adopts a very simplified joint optimization objective to ensure the efficiency of training:
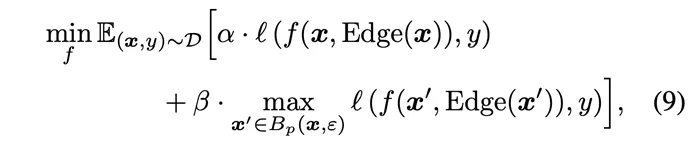
In Formula 9, α is the accuracy loss The weight of the function, β is the weight of the robustness loss function. By adjusting the size of α and β, the balance of the EdgeNet training objectives can be fine-tuned to achieve the purpose of improving its robustness without significantly losing accuracy.
The authors tested the robustness of two major categories on the ImageNet dataset.
The first category is robustness against adversarial attacks, including white box attacks and black box attacks;
The second category is resistance against Robustness to some common perturbations, including Natural Adversarial Examples in ImageNet-A, Out-of-Distribution Data in ImageNet-R and common data distortions in ImageNet-C ( Common Corruptions).
The author also visualized the edge information extracted under different perturbations.

##Network scale and performance test
In the experimental part, the author first The classification performance and computational overhead of EdgeNet of different sizes were tested (Table 1). After comprehensively considering classification performance and computational overhead, they determined that the configuration of #Intervals = 3 was the optimal setting.
In this configuration, EdgeNet achieves significant accuracy and robustness improvements compared to baseline models. It achieves a balanced compromise between classification performance, computational requirements and robustness.
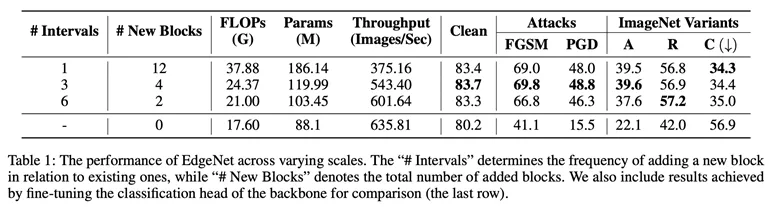
This configuration achieves substantial gains in clarity accuracy and robustness while maintaining reasonable computational efficiency.
Comparison of accuracy and robustness
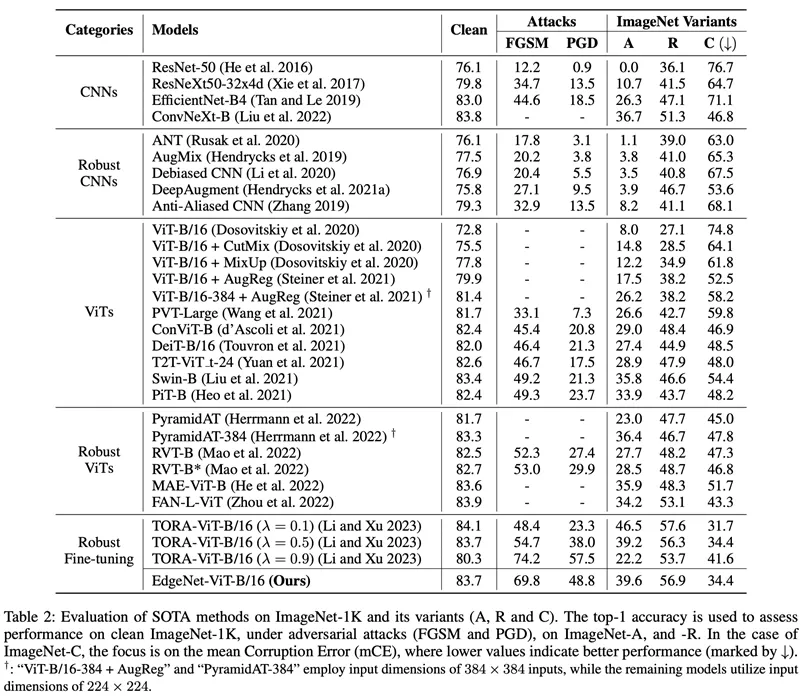
The authors compare their proposed EdgeNet with Five different categories of SOTA methods were compared (Table 2). These methods include CNNs trained on natural images, robust CNNs, ViTs trained on natural images, robust ViTs, and robust fine-tuned ViTs.
Metrics considered include accuracy under adversarial attacks (FGSM and PGD), accuracy on ImageNet-A, and accuracy on ImageNet-R.
Additionally, the mean error (mCE) of ImageNet-C is also reported, with lower values indicating better performance. Experimental results demonstrate that EdgeNet exhibits superior performance in the face of FGSM and PGD attacks, while performing on par with previous SOTA methods on the clean ImageNet-1K dataset and its variants.
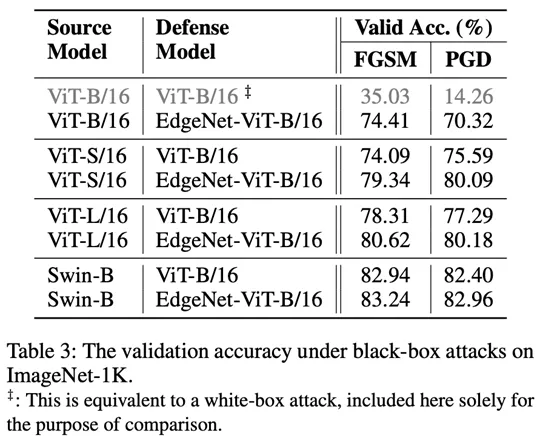
In addition, the author also conducted black box attack experiments (Table 3). Experimental results show that EdgeNet can also resist black box attacks very effectively.
#この研究では、著者は、ディープ ニューラル ネットワーク (特に ViT) の堅牢性を向上できる EdgeNet と呼ばれる新しい方法を提案しました。
これは、既存のネットワークにシームレスに統合できる軽量モジュールであり、敵対的な堅牢性を効果的に向上させることができます。実験によると、EdgeNet は効率的であり、追加の計算オーバーヘッドが最小限に抑えられるだけです。
さらに、EdgeNet はさまざまな堅牢なベンチマークに幅広く適用できます。これは、この分野で注目に値する発展となっています。
さらに、実験結果では、EdgeNet が敵対的な攻撃に効果的に抵抗し、クリーンな画像の精度を維持できることが確認されており、視覚的分類タスクにおける堅牢なツールとしてのエッジ情報の役割が強調されています。関連機能の可能性。
EdgeNet の堅牢性は敵対的攻撃に限定されるものではなく、自然な敵対的例 (ImageNet-A)、配布外のデータ (ImageNet-R)、および一般的な破壊 (ImageNet-C) シナリオ。
この広範なアプリケーションは、EdgeNet の多用途性を強調し、視覚的分類タスクにおけるさまざまな課題に対する包括的なソリューションとしての可能性を示しています。
The above is the detailed content of Low-cost algorithm greatly improves the robustness of visual classification! University of Sydney Chinese team releases new EdgeNet method. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



