


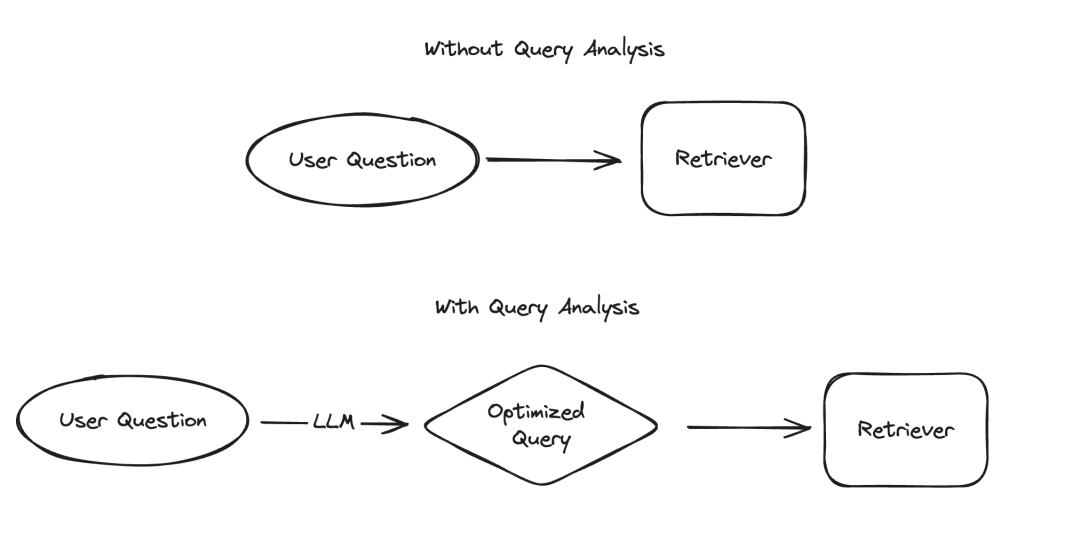
In the application of large language models (LLM), there are several scenarios that require data to be presented in a structured manner, of which information extraction and query analysis are two typical examples. We recently emphasized the importance of information extraction with updated documentation and a dedicated code repository. For query analysis, we have also updated relevant documentation. In these scenarios, data fields may include strings, Boolean values, integers, etc. Among these types, dealing with high cardinality categorical values (i.e. enumeration types) is the most challenging.
 Picture
Picture
The so-called "high cardinality grouping value" refers to those values that must be selected from limited options, and these values cannot be specified arbitrarily , but must come from a predefined collection. In such a set, sometimes there will be a very large number of valid values, which we call "high cardinality values". The reason dealing with such values is difficult is that LLM itself does not know what these feasible values are. Therefore, we need to provide LLM with information about these feasible values. Even ignoring the case where there are only a few feasible values, we can still solve this problem by explicitly listing these possible values in the hint. However, the problem becomes complicated because there are so many possible values.
As the number of possible values increases, the difficulty of LLM selecting values also increases. On the one hand, if there are too many possible values, they may not fit in the LLM's context window. On the other hand, even if all possible values can fit into the context, including them all results in slower processing, increased cost, and reduced LLM reasoning capabilities when dealing with large amounts of context. `As the number of possible values increases, the difficulty of LLM selecting values increases. On the one hand, if there are too many possible values, they may not fit in the LLM's context window. On the other hand, even if all possible values can fit into the context, including them all results in slower processing, increased cost, and reduced LLM reasoning capabilities when dealing with large amounts of context. ` (Note: The original text appears to be URL encoded. I have corrected the encoding and provided the rewritten text.)
Recently, we have conducted an in-depth study of query analysis and specifically added A page on how to handle high cardinality numbers. In this blog, we’ll dive into several experimental approaches and provide their performance benchmark results.
An overview of the results can be viewed at LangSmith https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d?ref=blog.langchain.dev. Next, we will introduce in detail:
 Picture
Picture
Detailed dataset can Check it out here https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d?ref=blog.langchain.dev.
To simulate this problem, we assume a scenario: we want to find a book about aliens by a certain author. In this scenario, the writer field is a high-cardinality categorical variable - there are many possible values, but they should be specific valid writer names. To test this, we created a dataset containing author names and common aliases. For example, "Harry Chase" might be an alias for "Harrison Chase." We want intelligent systems to be able to handle this kind of aliasing. In this dataset, we generated a dataset containing a list of writers' names and aliases. Note that 10,000 random names is not too much - for enterprise-level systems, you may need to deal with cardinality in the millions.
Using this data set, we asked the question: "What are Harry Chase's books about aliens?" Our query analysis system should be able to parse this question into a structured format, containing two Fields: Subject and Author. In this example, the expected output would be {"topic": "aliens", "author": "Harrison Chase"}. We expect the system to recognize that there is no author named Harry Chase, but Harrison Chase may be what the user meant.
With this setup, we can test against the alias dataset we created to check if they map correctly to real names. At the same time, we also record the latency and cost of the query. This kind of query analysis system is usually used for search, so we are very concerned about these two indicators. For this reason, we also limit all methods to only one LLM call. We may benchmark methods using multiple LLM calls in a future article.
Next, we will introduce several different methods and their performance.
 Picture
Picture
The complete results can be viewed in LangSmith, and the code to reproduce these results can be found here.
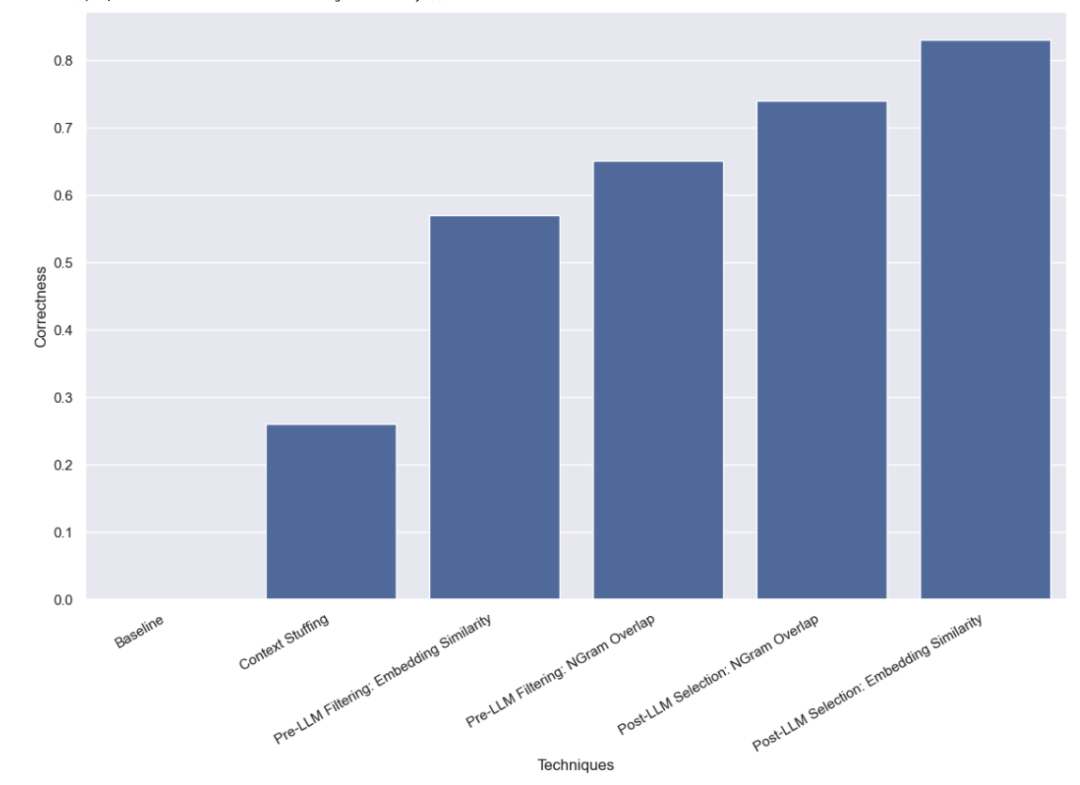
First, we conducted a baseline test on LLM, that is, directly asking LLM to perform query analysis without providing any valid name information. As expected, not a single question was answered correctly. This is because we intentionally constructed a dataset that requires querying authors by alias.
In this method, we put all 10,000 legal author names into the prompt and ask LLM to perform query analysis Remember these are legal author names. Some models (such as GPT-3.5) simply cannot perform this task due to the limitations of the context window. For other models with longer context windows, they also had difficulty accurately selecting the correct name. GPT-4 only picked the correct name in 26% of cases. Its most common error is extracting names but not correcting them. Not only is this method slow, it's also expensive, taking an average of 5 seconds to complete and costing a total of $8.44.
The method we tested next was to filter the list of possible values before passing it to the LLM. The advantage of this is that it only passes a subset of possible names to LLM, so LLM has far fewer names to consider, hopefully allowing it to complete query analysis faster, cheaper, and more accurately. But this also adds a new potential failure mode – what if the initial filtering goes wrong?
The filtering method we initially used was the embedding method and selected the 10 names most similar to the query. Note that we are comparing the entire query to the name, which is not an ideal comparison!
We found that using this approach, GPT-3.5 was able to correctly handle 57% of the cases. This method is much faster and cheaper than previous methods, taking only 0.76 seconds on average to complete, with a total cost of just $0.002.
The second filtering method we use is TF-IDF vectorization of 3-gram character sequences of all valid names , and uses the cosine similarity between the vectorized valid names and the vectorized user input to select the 10 most relevant valid names to add to the model prompts. Also note that we are comparing the entire query to the name, which is not an ideal comparison!
We found that using this approach, GPT-3.5 was able to correctly handle 65% of the cases. This method is also much faster and cheaper than previous methods, taking only 0.57 seconds on average to complete, and the total cost is only $0.002.
The last method we tested was to try to correct any errors after LLM completed the preliminary query analysis. We first performed query analysis on user input without providing any information about valid author names in the prompt. This is the same baseline test we did initially. We then did a subsequent step of taking the names in the author field and finding the most similar valid name.
First, we performed a similarity check using the embedding method.
We found that using this approach, GPT-3.5 was able to correctly handle 83% of the cases. This method is much faster and cheaper than previous methods, taking only 0.66 seconds on average to complete, and the total cost is only $0.001.
Finally, we try to use the 3-gram vectorizer for similarity checking.
We found that using this approach, GPT-3.5 was able to correctly handle 74% of the cases. This method is also much faster and cheaper than previous methods, taking only 0.48 seconds on average to complete, and the total cost is only $0.001.
We conducted various benchmark tests on query analysis methods for handling high-cardinality categorical values. We limited ourselves to making only one LLM call in order to simulate real-world latency constraints. We found that selection methods based on embedding similarity performed best after using LLM.
There are other methods worthy of further testing. In particular, there are many different ways to find the most similar categorical value before or after the LLM call. Additionally, the category base in this dataset is not as high as many enterprise systems face. This dataset has approximately 10,000 values, while many real-world systems may need to handle cardinality in the millions. Therefore, benchmarking on higher cardinality data would be very valuable.
The above is the detailed content of LLM ultra-long context query-practical performance evaluation. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



