


The main issue this discussion paper focuses on is the application of 3D target detection technology in the process of autonomous driving. Although the development of environmental vision camera technology provides high-resolution semantic information for 3D object detection, this method is limited by issues such as the inability to accurately capture depth information and poor performance in bad weather or low-light conditions. In response to this problem, the discussion proposed a new multi-mode 3D target detection method-RCBEVDet that combines surround-view cameras and economical millimeter-wave radar sensors. This method provides richer semantic information and a solution to problems such as poor performance in bad weather or low-light conditions by comprehensively using information from multiple sensors. In response to this problem, the discussion proposed a new multi-mode 3D target detection method-RCBEVDet that combines surround-view cameras and economical millimeter-wave radar sensors. By comprehensively using information from multi-mode sensors, RCBEVDet is able to provide high-resolution semantic information and exhibit good performance in severe weather or low-light conditions. The core of this method to improve automatic
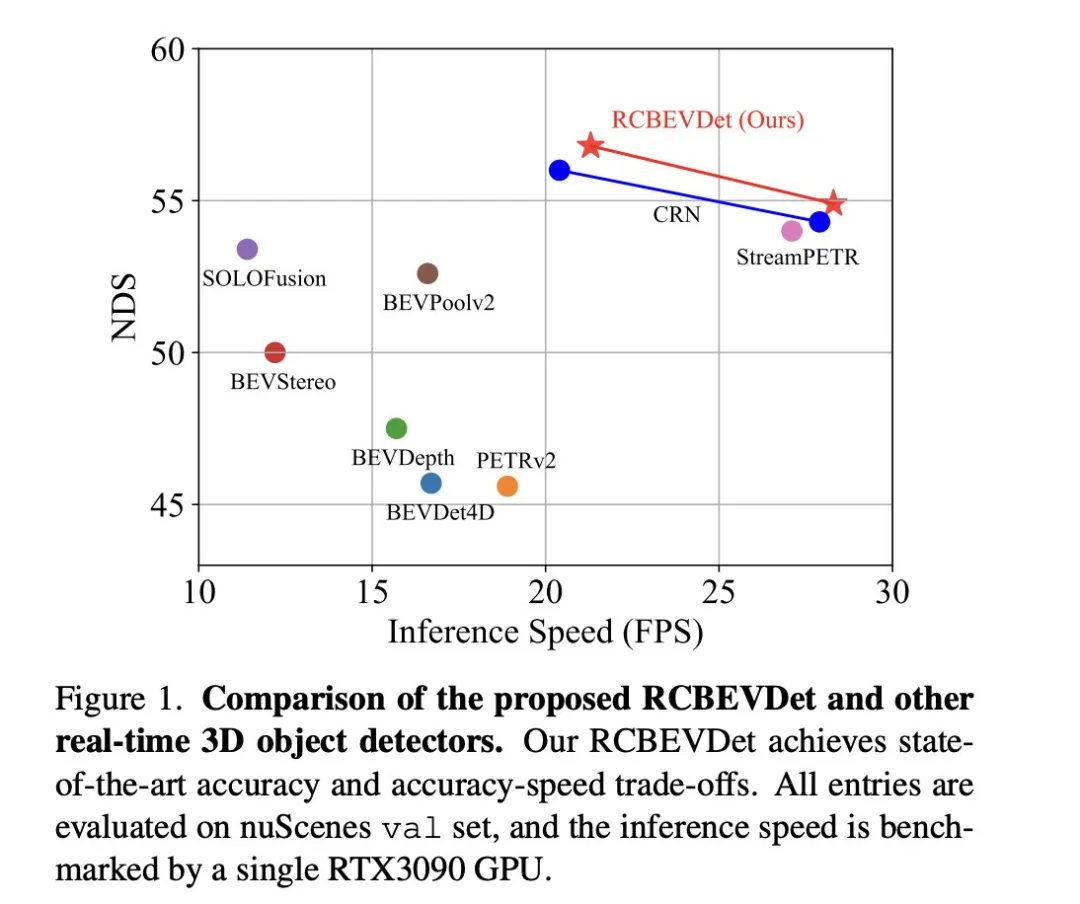
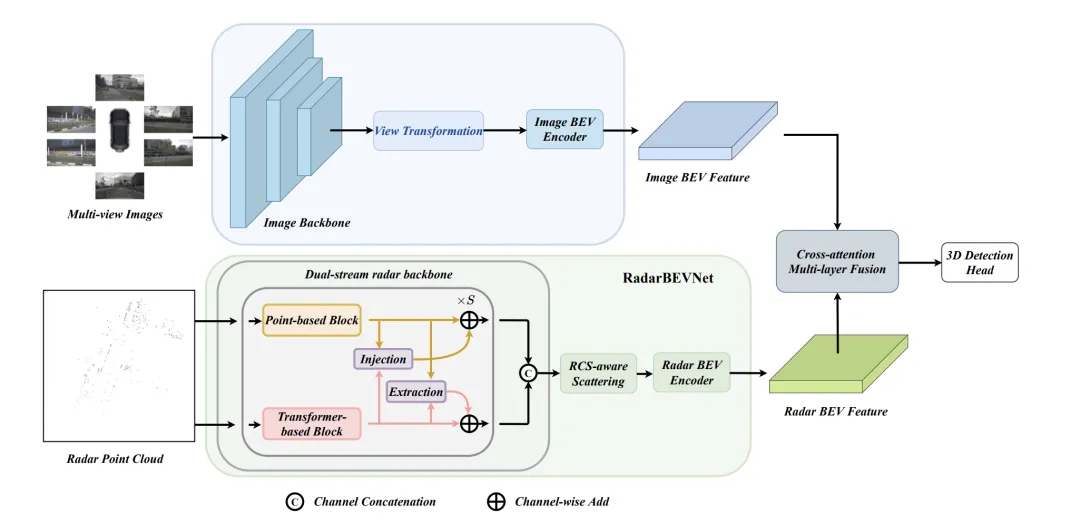
RCBEVDet lies in two key designs: RadarBEVNet and Cross-Attention Multi-layer Fusion Module (CAMF). RadarBEVNet is designed to efficiently extract radar features and it includes a dual-stream radar backbone network RCS (Radar Cross Section) aware BEV (Bird's Eye View) encoder. Such a design uses point cloud-based and transformer-based encoders to process radar points, update radar point features interactively, and use radar-specific RCS characteristics as prior information of target size to optimize the point feature distribution in BEV space. The CAMF module solves the azimuth error problem of radar points through a multi-modal cross-attention mechanism, achieving dynamic alignment of BEV feature maps of radar and cameras and adaptive fusion of multi-modal features through channel and spatial fusion. In the implementation, the point feature distribution in the BEV space is optimized by interactively updating the radar point features and using the radar-specific RCS characteristics as prior information of the target size. The CAMF module solves the azimuth error problem of radar points through a multi-modal cross-attention mechanism, achieving dynamic alignment of BEV feature maps of radar and cameras and adaptive fusion of multi-modal features through channel and spatial fusion.
The new method proposed in the paper solves the existing problems through the following points:
The main contributions of the paper are as follows:
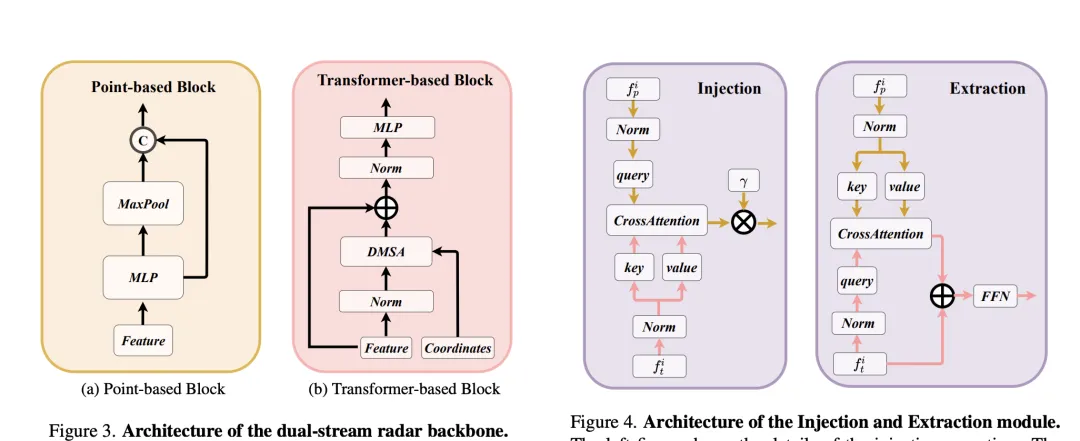
In order to solve the sparsity problem of BEV features produced by traditional radar BEV encoders, an RCS-aware BEV encoder is proposed. It uses RCS as prior information of target size and spreads radar point features to multiple pixels in the BEV space instead of a single pixel to increase the density of BEV features. This process is implemented through the following formula:
where, is the Gaussian BEV weight map based on RCS, which is optimized by maximizing the weight map of all radar points. Finally, the features obtained by RCS spreading are connected and processed by MLP to obtain the final RCS-aware BEV features.
Overall, RadarBEVNet efficiently extracts the features of radar data by combining a dual-stream radar backbone network and an RCS-aware BEV encoder, and optimizes the feature distribution of the BEV space by using RCS as a priori for target size. , which provides a strong foundation for subsequent multi-modal fusion.
Cross-Attention Multi-layer Fusion Module (CAMF) is a An advanced network structure for dynamic alignment and fusion of multi-modal features, especially designed for dynamic alignment and fusion of bird's-eye view (BEV) features generated by radar and cameras. This module mainly solves the problem of feature misalignment caused by the azimuth error of radar point clouds. Through the deformable cross-attention mechanism (Deformable Cross-Attention), it effectively captures the small deviations of radar points and reduces the standard cross-attention. computational complexity.
CAMF utilizes a deformed cross-attention mechanism to align the BEV features of cameras and radars. Given a sum of BEV features for a camera and a radar, learnable position embeddings are first added to sum and then converted to query and reference points as keys and values. The calculation of multi-head deformation cross attention can be expressed as:
where represents the index of the attention head, represents the index of the sampling key, and is the total number of sampling keys. Represents the sampling offset and is the attention weight calculated by and .
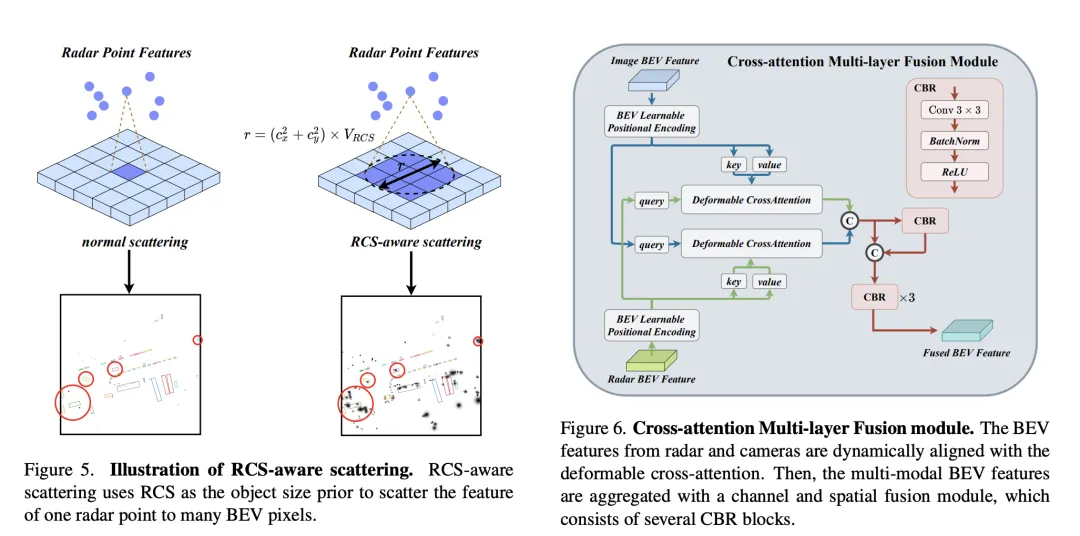
After aligning the BEV features of camera and radar through cross-attention, CAMF uses channel and spatial fusion layers to aggregate multi-modal BEV features. Specifically, two BEV features are first concatenated, and then fed into the CBR (convolution-batch normalization-activation function) block and the fused features are obtained through residual connection. The CBR block sequentially consists of a convolutional layer, a batch normalization layer and a ReLU activation function. After that, three CBR blocks are applied consecutively to further fuse multi-modal features.
Through the above process, CAMF effectively achieves precise alignment and efficient fusion of radar and camera BEV features, providing rich and accurate feature information for 3D target detection, thus improving detection performance.
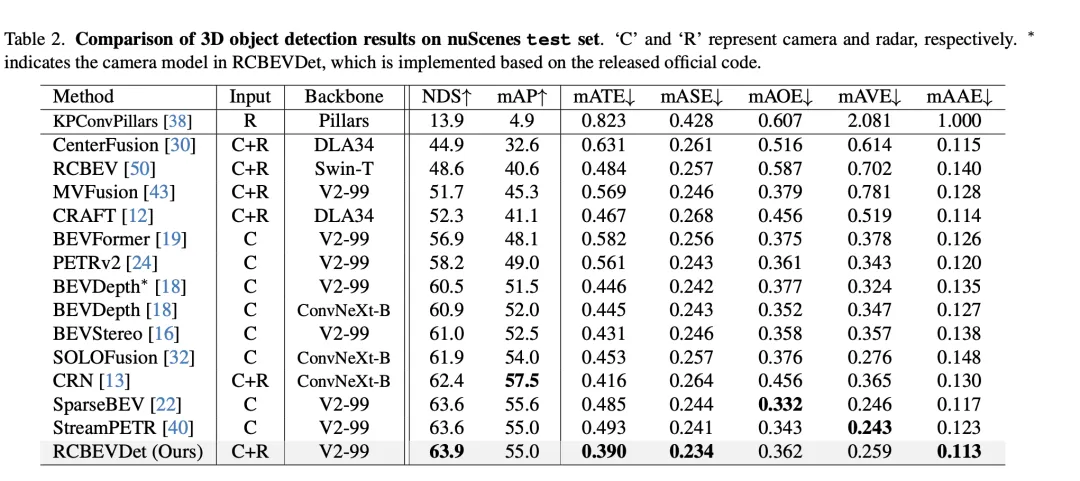
In the comparison of 3D target detection results on the VoD validation set, RadarBEVNet fuses camera and radar data, It shows excellent performance in terms of average precision (mAP) performance within the entire annotation area and within the area of interest. Specifically, for the entire annotated area, RadarBEVNet achieved AP values of 40.63%, 38.86%, and 70.48% respectively in the detection of cars, pedestrians, and cyclists, increasing the comprehensive mAP to 49.99%. In the area of interest, that is, in the driving channel close to the vehicle, RadarBEVNet's performance is even more outstanding, reaching 72.48%, 49.89% and 87.01% AP values in the detection of cars, pedestrians and cyclists respectively, and the comprehensive mAP reached 69.80%.
These results reveal several key points. First, RadarBEVNet can fully utilize the complementary advantages of the two sensors by effectively fusing camera and radar inputs, improving the overall detection performance. Compared with methods that only use radar, such as PointPillar and RadarPillarNet, RadarBEVNet has a significant improvement in comprehensive mAP, which shows that multi-modal fusion is particularly important to improve detection accuracy. Secondly, RadarBEVNet performs particularly well in areas of interest, which is particularly critical for autonomous driving applications because targets in areas of interest usually have the greatest impact on real-time driving decisions. Finally, although the AP value of RadarBEVNet is slightly lower than some single-modal or other multi-modal methods in the detection of cars and pedestrians, RadarBEVNet shows its overall performance advantages in cyclist detection and comprehensive mAP performance. RadarBEVNet achieves excellent performance on the VoD verification set by fusing multi-modal data from cameras and radars, especially demonstrating strong detection capabilities in areas of interest that are critical to autonomous driving, proving its effectiveness as a The potential of 3D object detection methods.
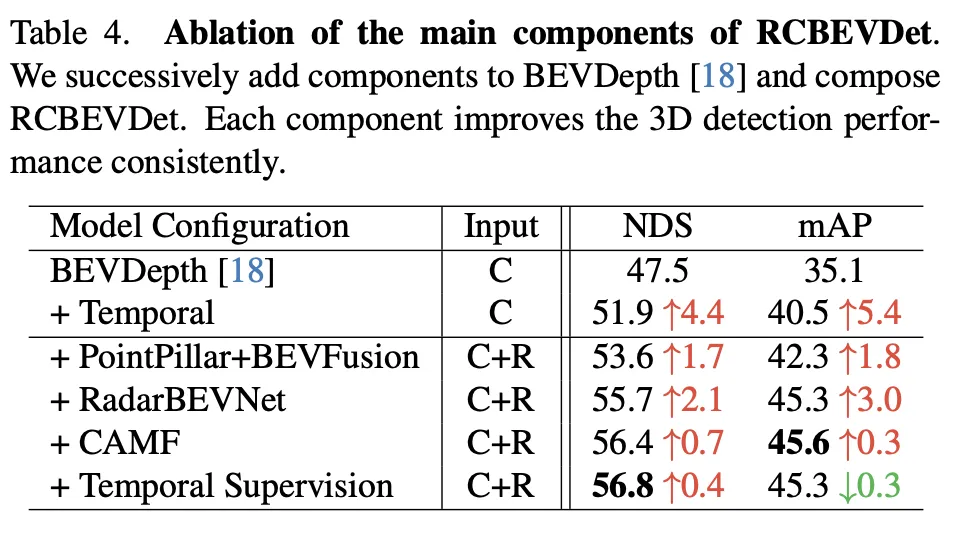
This ablation experiment demonstrates RadarBEVNet’s continued improvement in 3D object detection performance as it gradually adds major components. Starting from the baseline model BEVDepth, the added components at each step significantly improve NDS (core metric, reflecting detection accuracy and completeness) and mAP (average precision, reflecting the model's ability to detect objects).
Overall, this series of ablation experiments clearly demonstrates the contribution of each major component in RadarBEVNet to improving 3D object detection performance, from the introduction of temporal information to complex multi-modality Fusion strategy, each step brings performance improvement to the model. In particular, the sophisticated processing and fusion strategies for radar and camera data prove the importance of multi-modal data processing in complex autonomous driving environments.
The RadarBEVNet method proposed in the paper effectively improves the accuracy and robustness of 3D target detection by fusing multi-modal data from cameras and radars. It performs particularly well in complex autonomous driving scenarios. By introducing RadarBEVNet and Cross-Attention Multi-layer Fusion Module (CAMF), RadarBEVNet not only optimizes the feature extraction process of radar data, but also achieves precise feature alignment and fusion between radar and camera data, thereby overcoming the problem of using a single sensor data limitations, such as radar bearing errors and camera performance degradation in low light or adverse weather conditions.
In terms of advantages, the main contribution of RadarBEVNet is its ability to effectively process and utilize complementary information between multi-modal data, improving detection accuracy and system robustness. The introduction of RadarBEVNet makes the processing of radar data more efficient, and the CAMF module ensures the effective fusion of different sensor data, making up for their respective shortcomings. In addition, RadarBEVNet demonstrated excellent performance on multiple data sets in experiments, especially in areas of interest that are crucial in autonomous driving, showing its potential in practical application scenarios.
In terms of shortcomings, although RadarBEVNet has achieved remarkable results in the field of multi-modal 3D target detection, the complexity of its implementation has also increased accordingly, and may require more computing resources and processing time, which to a certain extent Limits its deployment in real-time application scenarios. In addition, although RadarBEVNet performs well in cyclist detection and overall performance, there is still room for improvement in performance on specific categories (such as cars and pedestrians), which may require further algorithm optimization or more efficient feature fusion strategies to solve.
In short, RadarBEVNet has demonstrated significant performance advantages in the field of 3D target detection through its innovative multi-modal fusion strategy. Although there are some limitations, such as higher computational complexity and room for performance improvement on specific detection categories, its potential in improving the accuracy and robustness of autonomous driving systems cannot be ignored. Future work can focus on optimizing the computational efficiency of the algorithm and further improving its performance on various target detections to promote the widespread deployment of RadarBEVNet in actual autonomous driving applications.
The paper introduces RadarBEVNet and Cross-Attention Multi-layer Fusion Module (CAMF) by fusing camera and radar data, showing significant results in the field of 3D target detection. Improved performance, especially in key scenarios of autonomous driving. It effectively utilizes the complementary information between multi-modal data to improve detection accuracy and system robustness. Despite the challenges of high computational complexity and room for performance improvement in some categories, \ours has shown great potential and value in promoting the development of autonomous driving technology, especially in improving the perception capabilities of autonomous driving systems. Future work can focus on optimizing algorithm efficiency and further improving detection performance to better adapt to the needs of real-time autonomous driving applications.
The above is the detailed content of RV fusion performance is amazing! RCBEVDet: Radar also has spring, the latest SOTA!. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



