


CLIP long text capability is unlocked, and the performance of image retrieval tasks is significantly improved!
Some key details can also be captured. Shanghai Jiao Tong University and Shanghai AI Laboratory proposed a new frameworkLong-CLIP.
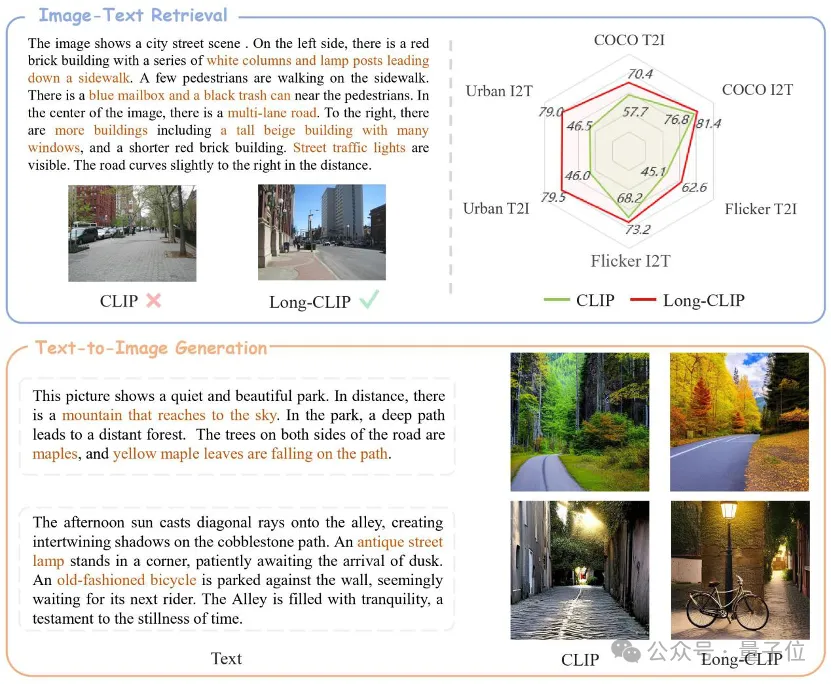
Long-CLIP is based on maintaining the original feature space of CLIP, in the downstream such as image generation Plug and play in the task to achieve fine-grained image generation of long text.
Long text-image retrieval increased by 20%, short text-image retrieval increased by 6%.
CLIP aligns visual and text modalities and has powerful zero-shot generalization capabilities. Therefore, CLIP is widely used in various multi-modal tasks, such as image classification, text image retrieval, image generation, etc.
But a major drawback of CLIP is thelack of long text capabilities.
First of all, due to the use of absolute position encoding, the text input length of CLIP is limited to 677 tokens. Not only that, experiments have proven that the real effective length of CLIP is even less than 20 tokens, which is far from enough to represent fine-grained information. However, to overcome this limitation, researchers have proposed a solution. By introducing specific tags in the text input, the model can focus on the important parts. The position and number of these tokens in the input are determined in advance and will not exceed 20 tokens. In this way, CLIP is able to
Long text missing on the text side also limits the capabilities of the visual side when processing text input. Since it only contains short text, CLIP's visual encoder will only extract the most important components of an image, while ignoring various details. This is very detrimental to fine-grained tasks such ascross-modal retrieval.
At the same time, the lack of long text also makes CLIP adopt a simple modeling method similar to bag-of-feature (BOF), which does not have complex capabilities such as causal reasoning.
In response to this problem, researchers proposed the Long-CLIP model.

Specifically proposed two major strategies: Knowledge-Preserving Stretching of Positional Embedding (Knowledge-Preserving Stretching of Positional Embedding) and fine-tuning strategy of adding core component alignment (Primary Component Matching).
A simple method to extend the input length and enhance long text capabilities is to first interpolate the positional encoding at a fixed ratio λ1, and then fine-tune it with long text.
Researchers found that the training degree of different position encodings of CLIP is different. Since the training text is likely to be mainly short text, the lower position coding is more fully trained and can accurately represent the absolute position, while the higher position coding can only represent its approximate relative position. Therefore, the cost of interpolating codes at different positions is different.
Based on the above observations, the researcher retained the first 20 position codes, and for the remaining 57 position codes, interpolated with a larger ratio λ2, the calculation formula It can be expressed as: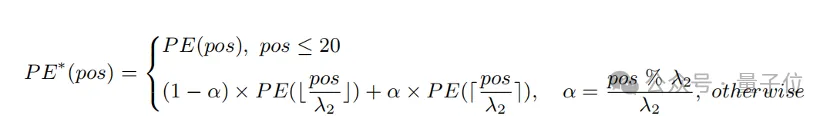
Experiments show that compared with direct interpolation, this strategy can significantly improve the performance on various tasks while supporting a longer total length.
Merely introducing long-text fine-tuning will lead the model into another misunderstanding, that is, including all details equally. To address this problem, researchers introduced the strategy of core attribute alignment in fine-tuning.
Specifically, researchers use the principal component analysis (PCA) algorithm to extract core attributes from fine-grained image features, filter the remaining attributes and reconstruct coarse-grained image features, and combine them with generalized of short text. This strategy requires that the model not only contains more details (fine-grained alignment), but also identifies and models the most core attributes (core component extraction and coarse-grained alignment).
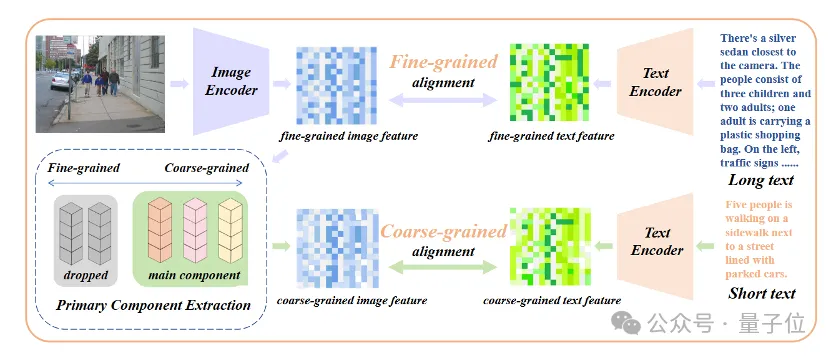
△Add the fine-tuning process of core attribute alignment
In pictures and texts In fields such as retrieval and image generation, Long-CLIP can replace CLIP plug-and-play.
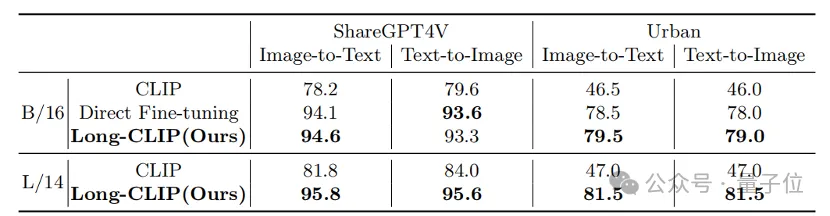
For example, in image and text retrieval, Long-CLIP can capture more fine-grained information in image and text modes, thereby enhancing the ability to distinguish similar images and text, and greatly improving the performance of image and text retrieval.
Whether it is in traditional short text retrieval (COCO, Flickr30k) or long text retrieval tasks, Long-CLIP has significantly improved the recall rate.
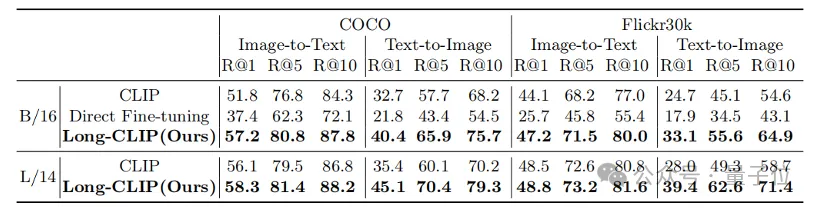
△Short text-image retrieval experimental results


Paper link:https://arxiv.org/abs/2403.15378
Code link:https://github.com/beichenzbc/Long-CLIP
The above is the detailed content of Shanghai Jiao Tong University's new framework unlocks CLIP long text capabilities, grasps the details of multi-modal generation, and significantly improves image retrieval capabilities. For more information, please follow other related articles on the PHP Chinese website!




























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



