


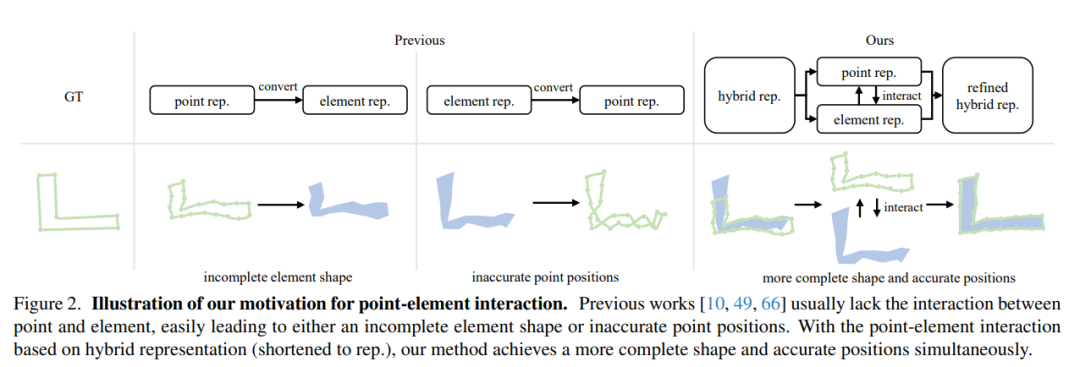
Vectorized high-definition (HD) map construction requires predicting the categories and point coordinates of map elements (such as road boundaries, lane dividers, crosswalks, etc.). State-of-the-art methods are mainly based on point-level representation learning for regressing precise point coordinates. However, this pipeline has limitations in obtaining element-level information and handling element-level failures, such as wrong element shapes or entanglements between elements. In order to solve the above problems, this paper proposes a simple and effective HybrId framework, named HIMap, to fully learn and interact with point-level and element-level information.
Specifically, a hybrid representation called HIQuery is introduced to represent all map elements, and a point element interactor is proposed to interactively extract hybrid information of elements, such as point location and element shape and encode it into HIQuery. In addition, point-element consistency constraints are also proposed to enhance the consistency between point-level and element-level information. Finally, the output point elements of the integrated HIQuery can be directly converted into the class, point coordinates and mask of the map element. Extensive experiments are conducted on nuScenes and Argoverse2 datasets, showing consistently superior results to previous methods. It is worth noting that the method achieves 77.8mAP on the nuScenes dataset, which is significantly better than the previous SOTA by at least 8.3mAP!
Paper name: HIMap: HybrId Representation Learning for End-to-end Vectorized HD Map Construction
Paper link: https://arxiv.org/pdf/2403.08639.pdf
HIMap first introduces a hybrid representation called HIQuery to represent all map elements in the map. It is a set of learnable parameters that can be iteratively updated and refined by interacting with BEV features. Then, a multi-layer hybrid decoder is designed to encode the hybrid information of map elements (such as point position, element shape) into HIQuery and perform point element interaction, see Figure 2. Each layer of the hybrid decoder includes point element interactors, self-attention and FFN. Inside the point-element interactor, a mutual interaction mechanism is implemented to realize the exchange of point-level and element-level information and avoid the learning bias of single-level information. Finally, integrated HIQuery's output point elements can be directly converted to the element's point coordinates, class, and mask. In addition, point-element consistency constraints are also proposed to enhance the consistency between point-level and element-level information.
The overall process of HIMap is shown in Figure 3(a). HIMap is compatible with a variety of airborne sensor data, such as RGB images from multi-view cameras, point clouds from lidar, or multi-modal data. Here we take multi-view RGB images as an example to explain how HIMap works.
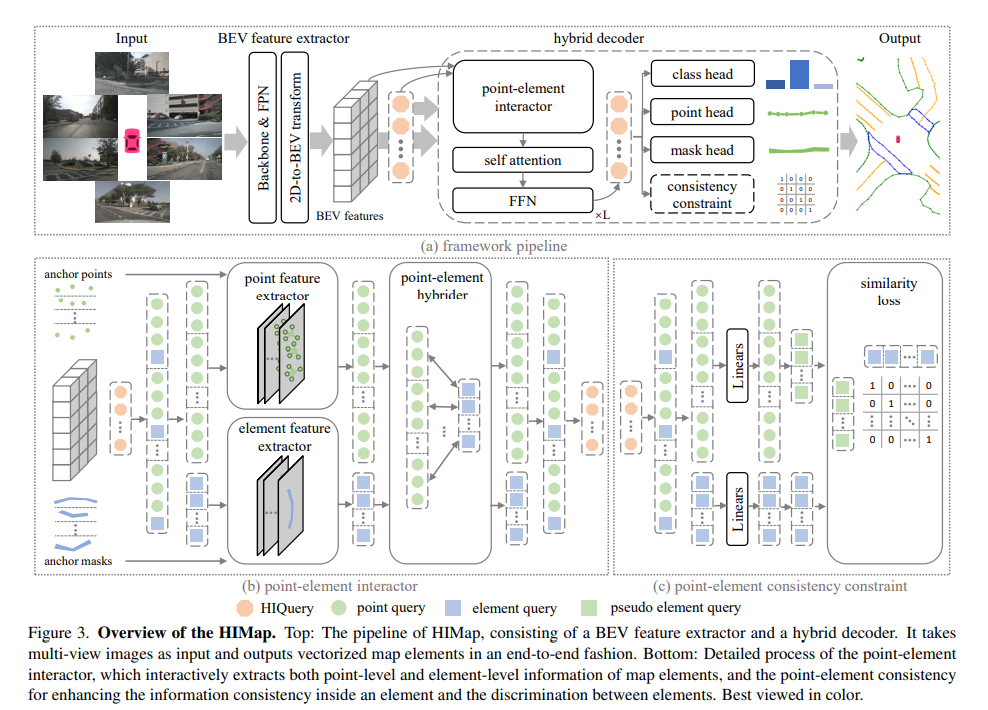
BEV Feature Extractor is a tool for extracting BEV features from multi-view RGB images. Its core includes extracting the backbone part of multi-scale 2D features from each perspective, obtaining the FPN part of single-scale features by fusing and refining multi-scale features, and utilizing the 2D to BEV feature conversion module to map 2D features into BEV features. . This process helps convert image information into BEV features more suitable for processing and analysis, improving the usability and accuracy of features. Through this method, we can better understand and utilize the information in multi-view images, providing stronger support for subsequent data processing and decision-making.
HIQuery: In order to fully learn the point-level and element-level information of map elements, HIQuery is introduced to represent all elements in the map!
Hybrid decoder: The hybrid decoder produces integrated HIQuery by iteratively interacting HIQuery Qh with BEV features X.
The goal of the point element interactor is to interactively extract point-level and element-level information of map elements and encode it into HIQuery. The motivation for the interaction of the two levels of information comes from their complementarity. Point-level information contains local location knowledge, while element-level information provides global shape and semantic knowledge. This interaction thus enables mutual refinement of local and global information of map elements.
Considering the original difference between point-level representation and element-level representation, which focus on local information and overall information respectively, the learning of two-level representations may also interfere with each other. This will increase the difficulty of information interaction and reduce the effectiveness of information interaction. Therefore, point element consistency constraints are introduced to enhance the consistency between each point level and element level information, and the discriminability of elements can also be enhanced!
The paper conducted experiments on NuScenes Dataset and Argoverse2 Dataset!
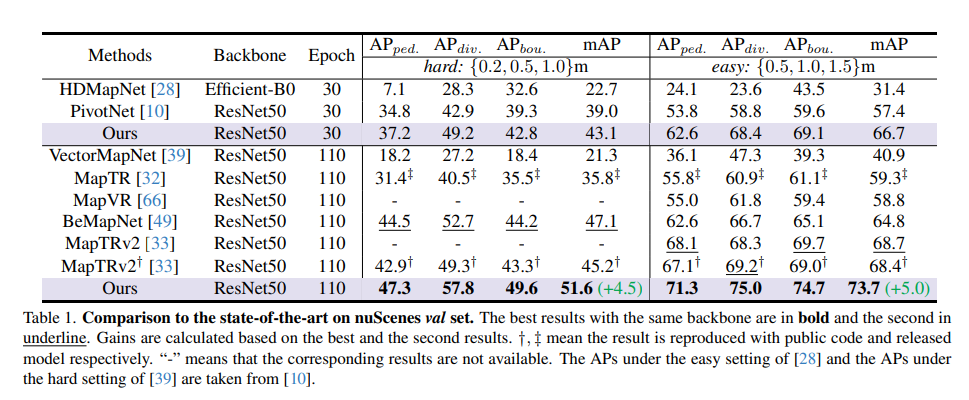
Comparison of SOTA model on nuScenes val-set:
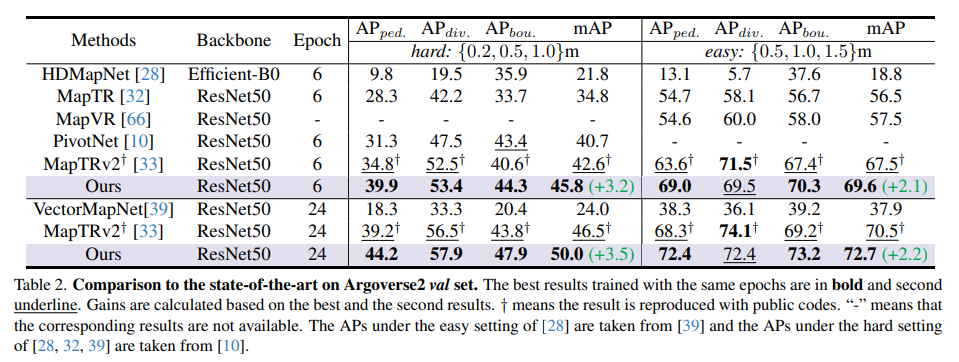
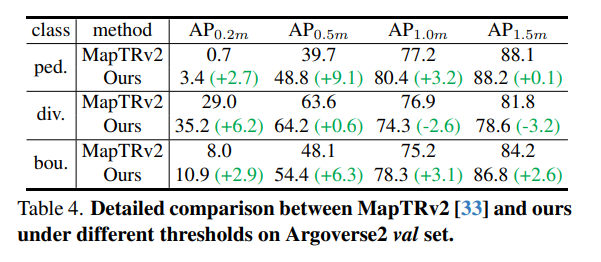
Comparison of SOTA model on Argoverse2 val set:
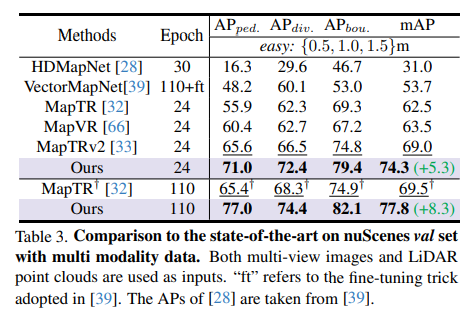
Comparison with SOTA model under nuScenes validation set multi-modal data:
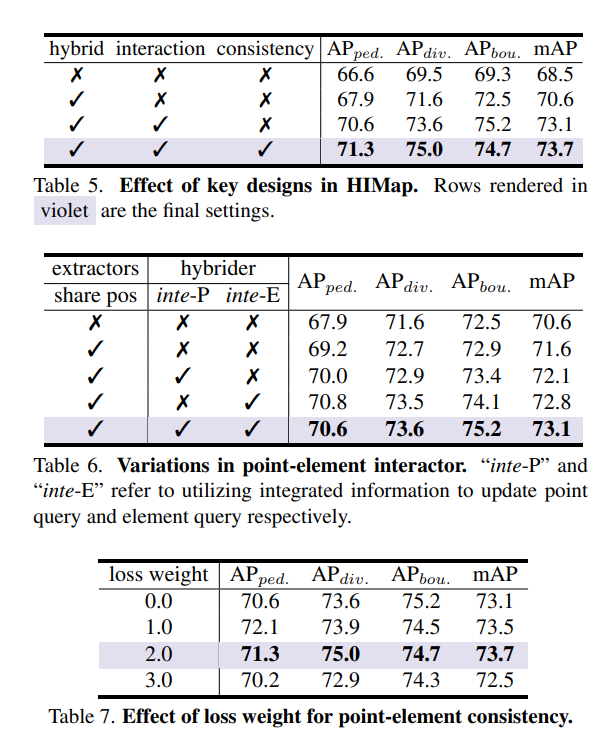
More ablation experiments:
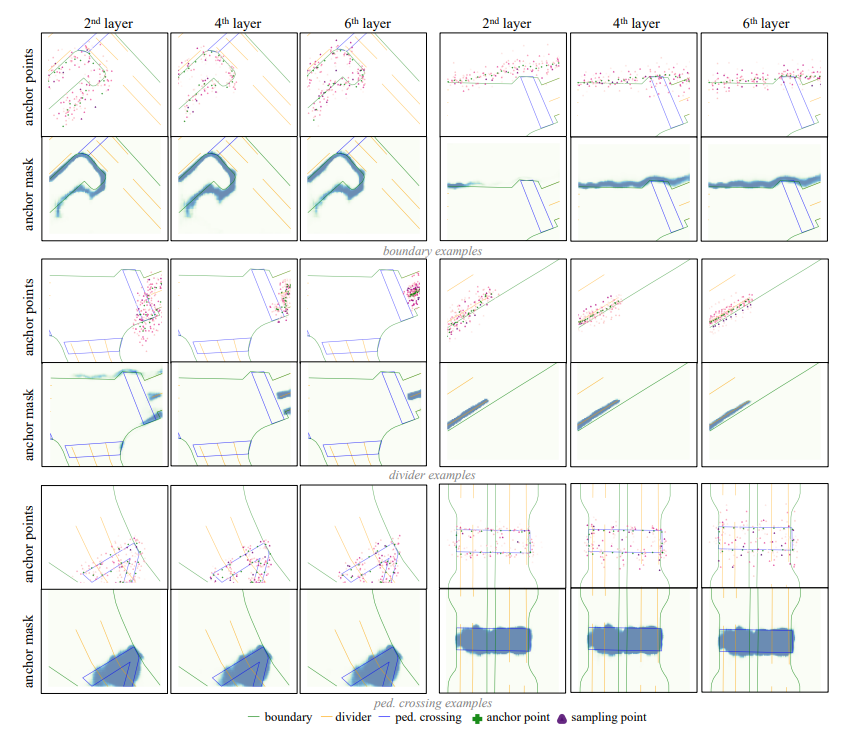

The above is the detailed content of Better than all methods! HIMap: End-to-end vectorized HD map construction. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



