


In the field of video understanding, although multi-modal models have made breakthroughs in short video analysis and demonstrated strong understanding capabilities, when they face movie-level long videos, In the video, it seems powerless. Therefore, the analysis and understanding of long videos, especially the understanding of hours-long movie content, has become a huge challenge today.
The difficulty of the model in understanding long videos mainly stems from the lack of long video data resources, which have defects in quality and diversity. Additionally, collecting and labeling this data requires a lot of work.
Faced with such a problem, the research team from Tencent and Fudan University proposed MovieLLM, an innovative AI generation framework. MovieLLM adopts an innovative method that not only generates high-quality and diverse video data, but also automatically generates a large number of related question and answer data sets, greatly enriching the dimension and depth of the data. At the same time, the entire automated process is also extremely Dadi reduces human investment.

this Important advances not only improve the model's understanding of complex video narratives, but also enhance the model's analytical capabilities when processing hours-long movie content. At the same time, it overcomes the limitations of scarcity and bias of existing data sets and provides a new and effective way to understand ultra-long video content.
MovieLLM cleverly takes advantage of the powerful generation capabilities of GPT-4 and diffusion models, and adopts a "story expanding" continuous frame description generation strategy. The "textual inversion" method is used to guide the diffusion model to generate scene images that are consistent with the text description, thereby creating continuous frames of a complete movie.

MovieLLM combines GPT-4 and diffusion models to improve large models Understanding long videos. This clever combination produces high-quality, diverse long video data and QA questions and answers, helping to enhance the model's generative capabilities.
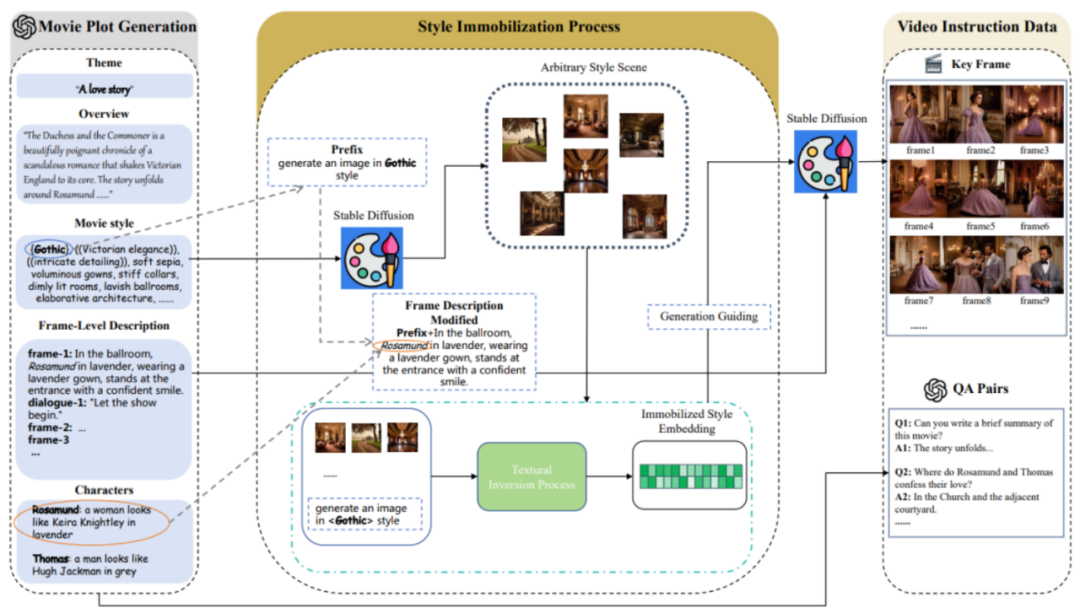
MovieLLM mainly includes three stages:
1. Movie plot generation.
Rather than relying on the web or existing datasets to generate plots, MovieLLM fully leverages the power of GPT-4 to produce synthetic data. By providing specific elements such as theme, overview, and style, GPT-4 is guided to produce cinematic keyframe descriptions tailored to the subsequent generation process.
#2. Style fixing process.
MovieLLM cleverly uses "textual inversion" technology to fix the style description generated in the script to the latent space of the diffusion model. This method guides the model to generate scenes with a fixed style and maintain diversity while maintaining a unified aesthetic.
#3. Video command data generation.
Based on the first two steps, fixed style embedding and key frame description have been obtained. Based on these, MovieLLM uses style embedding to guide the diffusion model to generate key frames that conform to key frame descriptions and gradually generates various instructional question and answer pairs according to the movie plot.

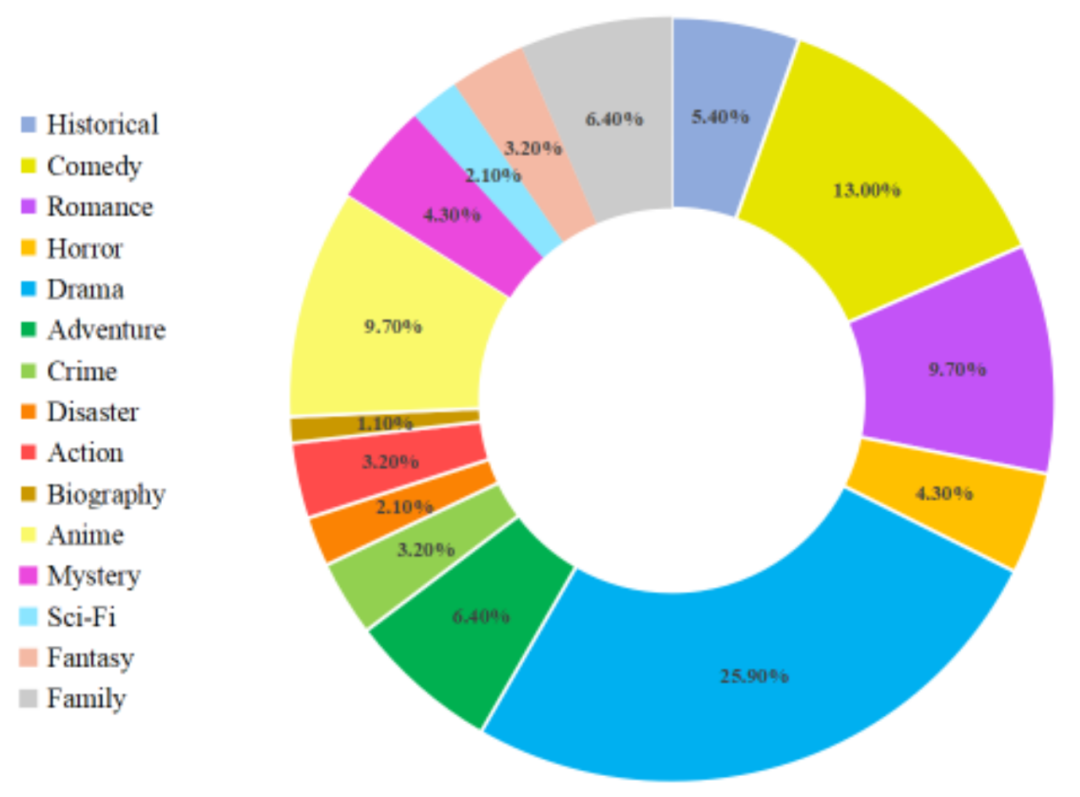
#After the above steps, MovieLLM creates high-quality, diverse styles, coherent movie frames and corresponding question and answer pair data. The detailed distribution of movie data types is as follows:
By fine-tuning LLaMA-VID, a large model focused on long video understanding, using data constructed based on MovieLLM, this paper significantly enhances The model's understanding of video content of various lengths. For long video understanding, there is currently no work proposing a test benchmark, so this article also proposes a benchmark for testing long video understanding capabilities.
Although MovieLLM did not specifically construct short video data for training, through training, performance improvements on various short video benchmarks were still observed. The results are as follows:
Compared with the baseline model, there is a significant improvement in the two test data sets of MSVD-QA and MSRVTT-QA.

On the performance benchmark based on video generation, performance improvements were achieved in all five evaluation areas.
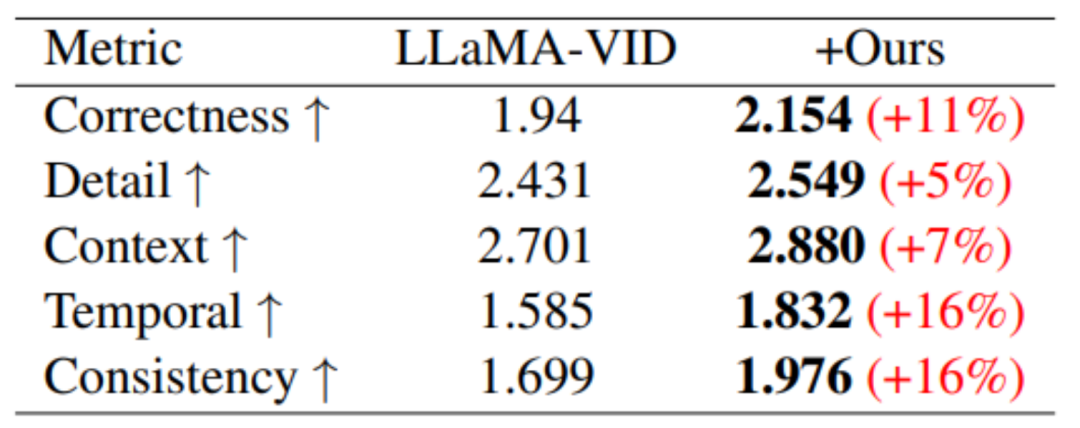
#In terms of long video understanding, through the training of MovieLLM, the model's understanding of summary, plot and timing has been significantly improved.

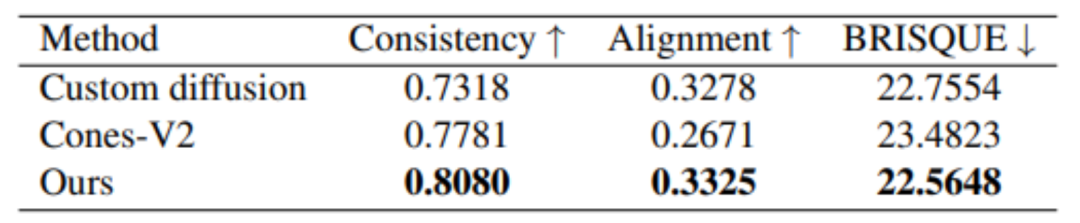
In addition, MovieLLM also has better results in terms of generation quality compared to other similar methods of generating images with fixed styles.
In short, the data generation workflow proposed by MovieLLM significantly reduces the challenge of producing movie-level video data for the model and improves the generation of content. control and diversity. At the same time, MovieLLM significantly enhances the multi-modal model's ability to understand movie-level long videos, providing a valuable reference for other fields to adopt similar data generation methods.
Readers who are interested in this research can read the original text of the paper to learn more about the research content.
The above is the detailed content of Using AI short videos to 'feed back' long video understanding, Tencent's MovieLLM framework aims at movie-level continuous frame generation. For more information, please follow other related articles on the PHP Chinese website!















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



