


Imagine that when you are standing in the room and preparing to walk towards the door, are you gradually planning the path through autoregression? In effect, your path is generated as a whole in one go.
The latest research points out that the planning module using the diffusion model can generate long sequence trajectory plans at the same time, which is more in line with human decision-making methods. In addition, the diffusion model can also provide more optimized solutions for existing decision-making intelligence algorithms in terms of policy representation and data synthesis.
A review paper written by a team from Shanghai Jiao Tong University"Diffusion Models for Reinforcement Learning: A Survey"combines the application of diffusion models in fields related to reinforcement learning. The review points out that existing reinforcement learning algorithms face challenges such as error accumulation in long sequence planning, limited policy expression capabilities, and insufficient interactive data, while the diffusion model has demonstrated advantages in solving reinforcement learning problems and bringing new ideas to address the long-standing challenges mentioned above. Paper link: https://arxiv.org/abs/2311.01223

This review classifies the role of diffusion models in reinforcement learning and summarizes successful cases of diffusion models in different reinforcement learning scenarios. . Finally, the review looks forward to the future development direction of using diffusion models to solve reinforcement learning problems.
The figure shows the role of the diffusion model in the classic agent-environment-experience replay pool cycle. Compared with traditional solutions, the diffusion model introduces new elements into the system and provides more comprehensive information interaction and learning opportunities. In this way, the agent can better adapt to changes in the environment and optimize its decisions
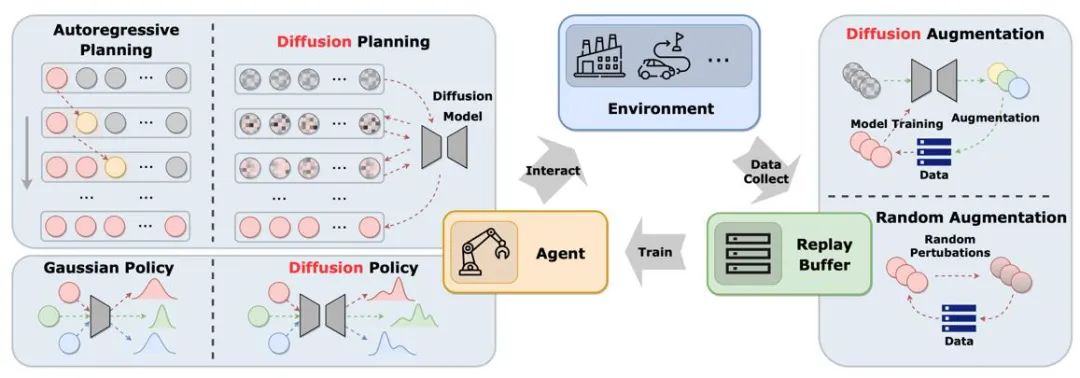
The article classifies and compares the application methods and characteristics of diffusion models based on the different roles they play in reinforcement learning.
Figure 2: The different roles that diffusion models play in reinforcement learning.
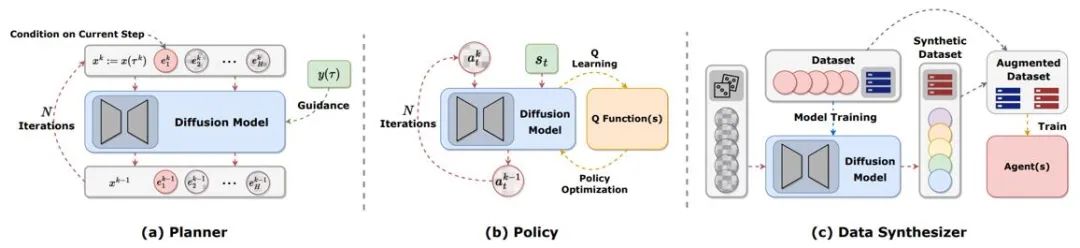
Trajectory planning
Planning in reinforcement learning refers to making decisions in imagination by using dynamic models and then choosing Appropriate actions to maximize cumulative rewards. The process of planning often explores sequences of actions and states to improve the long-term effectiveness of decisions. In model-based reinforcement learning (MBRL) frameworks, planning sequences are often simulated in an autoregressive manner, resulting in accumulated errors. Diffusion models can generate multi-step planning sequences simultaneously. The targets generated by existing articles using diffusion models are very diverse, including (s,a,r), (s,a), only s, only a, etc. To generate high-reward trajectories during online evaluation, many works use guided sampling techniques with or without classifiers.
Policy representation
The diffusion planner is more similar to MBRL in traditional reinforcement learning. In contrast, the diffusion planner will Models as policies are more similar to model-free reinforcement learning. Diffusion-QL first combines the diffusion strategy with the Q-learning framework. Because diffusion models are far more capable of fitting multimodal distributions than traditional models, diffusion strategies perform well in multimodal data sets sampled by multiple behavioral strategies. The diffusion strategy is the same as the ordinary strategy, usually using the state as a condition to generate actions while considering maximizing the Q (s,a) function. Methods such as Diffusion-QL add a weighted value function term when training the diffusion model, while CEP constructs a weighted regression target from an energy perspective, using the value function as a factor to adjust the action distribution learned by the diffusion model.
Data synthesis
Diffusion model can be used as a data synthesizer to alleviate data scarcity in offline or online reinforcement learning The problem. Traditional reinforcement learning data enhancement methods can usually only slightly perturb the original data, while the powerful distribution fitting capabilities of the diffusion model allow it to directly learn the distribution of the entire data set and then sample new high-quality data.
Other types
In addition to the above categories, there are also some scattered works using diffusion models in other ways. For example, DVF estimates a value function using a diffusion model. LDCQ first encodes the trajectory into the latent space and then applies the diffusion model on the latent space. PolyGRAD uses a diffusion model to dynamically transfer the learning environment, allowing policy and model interaction to improve policy learning efficiency.
Offline reinforcement learning
The introduction of the diffusion model helps the offline reinforcement learning strategy fit multi-modal data distribution and expands the representation ability of the strategy. Diffuser first proposed a high-reward trajectory generation algorithm based on classifier guidance and inspired a lot of subsequent work. At the same time, the diffusion model can also be applied in multi-task and multi-agent reinforcement learning scenarios.
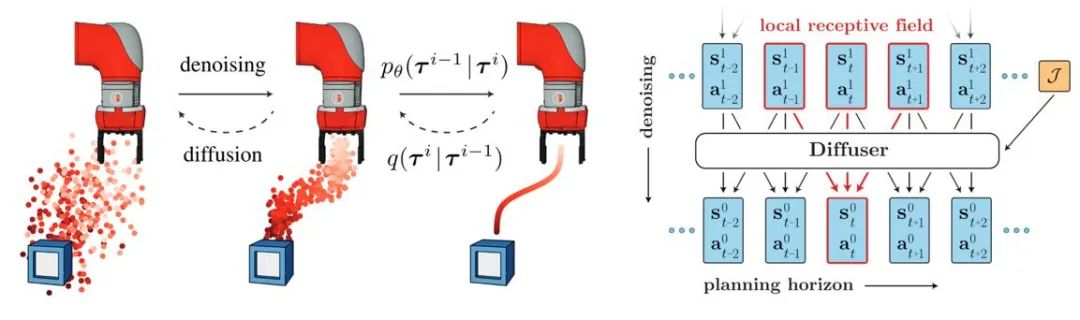
Figure 3: Diffuser trajectory generation process and model diagram
Online reinforcement learning
Researchers have proven that the diffusion model also has the ability to optimize value functions and strategies in online reinforcement learning. For example, DIPO re-labels action data and uses diffusion model training to avoid the instability of value-guided training; CPQL has verified that the single-step sampling diffusion model as a strategy can balance exploration and utilization during interaction.
Imitation learning
Imitation learning reconstructs expert behavior by learning from expert demonstration data. The application of diffusion models helps improve policy representation capabilities and learn diverse task skills. In the field of robot control, research has found that diffusion models can predict closed-loop action sequences while maintaining temporal stability. Diffusion Policy uses a diffusion model of image input to generate robot action sequences. Experiments show that the diffusion model can generate effective closed-loop action sequences while ensuring timing consistency.
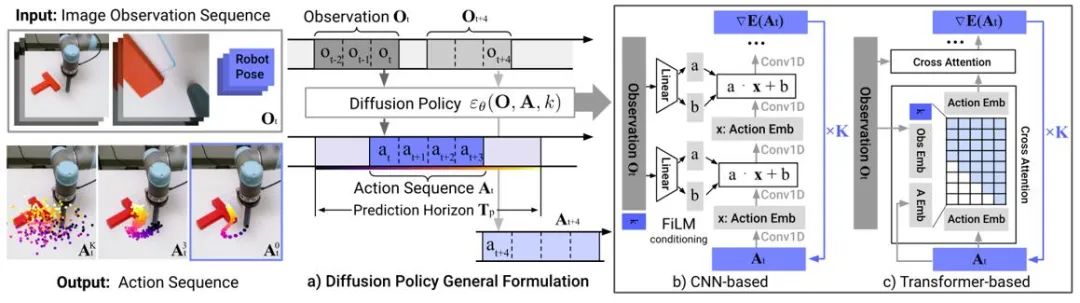
Figure 4: Diffusion Policy model diagram
Trajectory generation
The trajectory generation of the diffusion model in reinforcement learning mainly focuses on two types of tasks: human action generation and robot control. Action data or video data generated by diffusion models are used to build simulation simulators or train downstream decision-making models. UniPi trains a video generation diffusion model as a general strategy, and achieves cross-body robot control by accessing different inverse dynamics models to obtain underlying control commands.
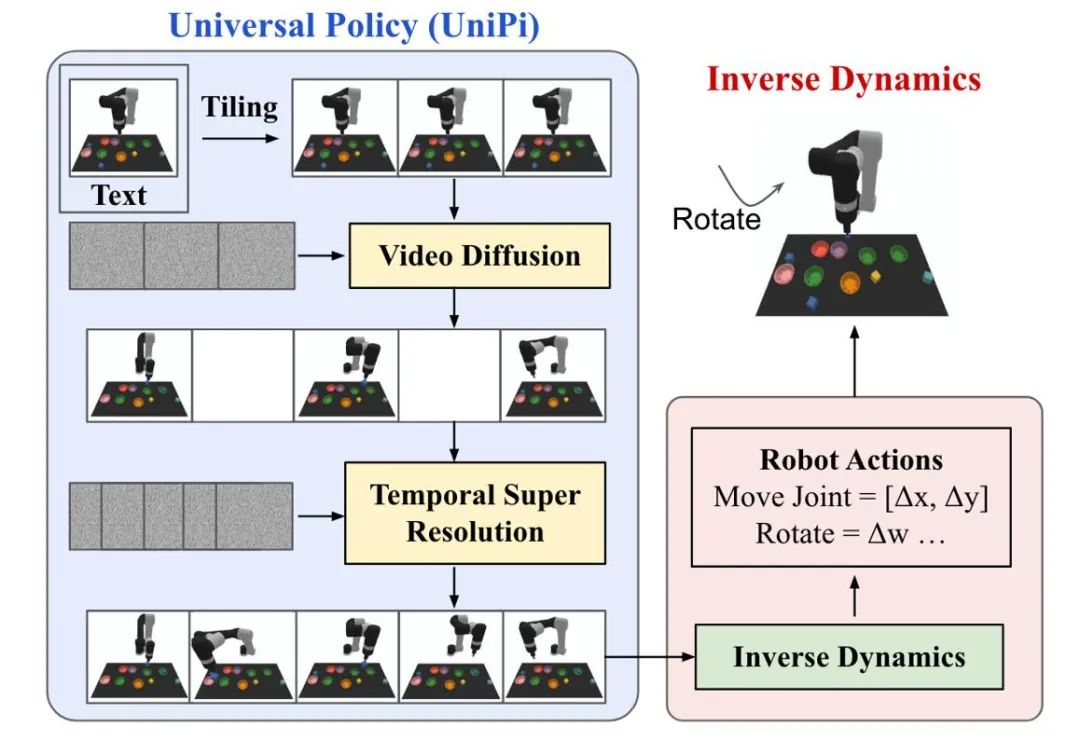
Figure 5: Schematic diagram of UniPi’s decision-making process.
Data enhancement
The diffusion model can also directly fit the original data distribution, while maintaining authenticity Provide a variety of dynamically expanded data. For example, SynthER and MTDiff-s generate complete environment transfer information of the training task through the diffusion model and apply it to policy improvement, and the results show that the diversity and accuracy of the generated data are better than historical methods.
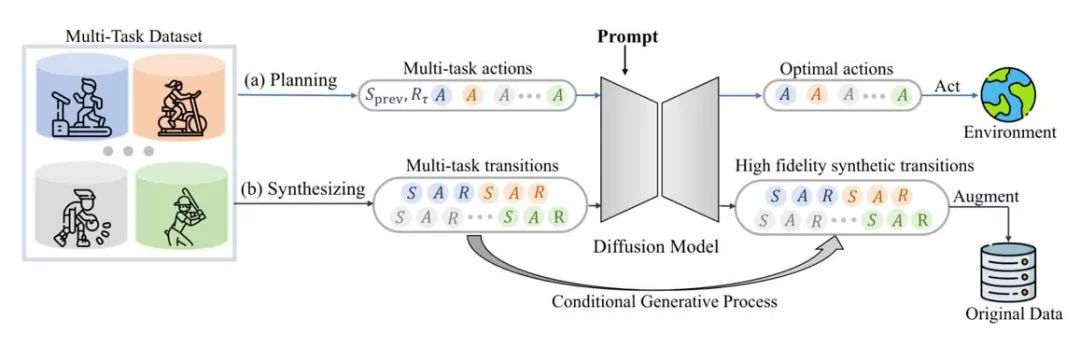
Figure 6: Schematic diagram of MTDiff for multi-task planning and data enhancement
Generative simulation environment
As shown in Figure 1, existing research mainly uses the diffusion model to overcome the problem of agents and Due to the limitations of the experience replay pool, there are relatively few studies on using diffusion models to enhance simulation environments. Gen2Sim uses the Vincentian graph diffusion model to generate diverse manipulable objects in the simulation environment to improve the generalization ability of precision robot operations. Diffusion models also have the potential to generate state transition functions, reward functions, or adversary behavior in multi-agent interactions in a simulation environment.
Add security constraints
By using safety constraints as sampling conditions for the model, agents based on the diffusion model can make decisions that satisfy specific constraints. Guided sampling of the diffusion model allows new security constraints to be continuously added by learning additional classifiers, while the parameters of the original model remain unchanged, thus saving additional training overhead.
Retrieval enhancement generation
Retrieval enhancement generation technology can enhance model capabilities by accessing external data sets, in large languages The model has been widely used. The performance of diffusion-based decision models in these states may also be improved by retrieving trajectories related to the agent's current state and feeding them into the model. If the retrieval data set is constantly updated, it is possible for the agent to exhibit new behaviors without being retrained.
Combining multiple skills
Diffusion models can be combined with classifier guidance or without classifier guidance A variety of simple skills to complete complex tasks. Early results in offline reinforcement learning also indicate that diffusion models can share knowledge between different skills, making it possible to achieve zero-shot transfer or continuous learning by combining different skills.
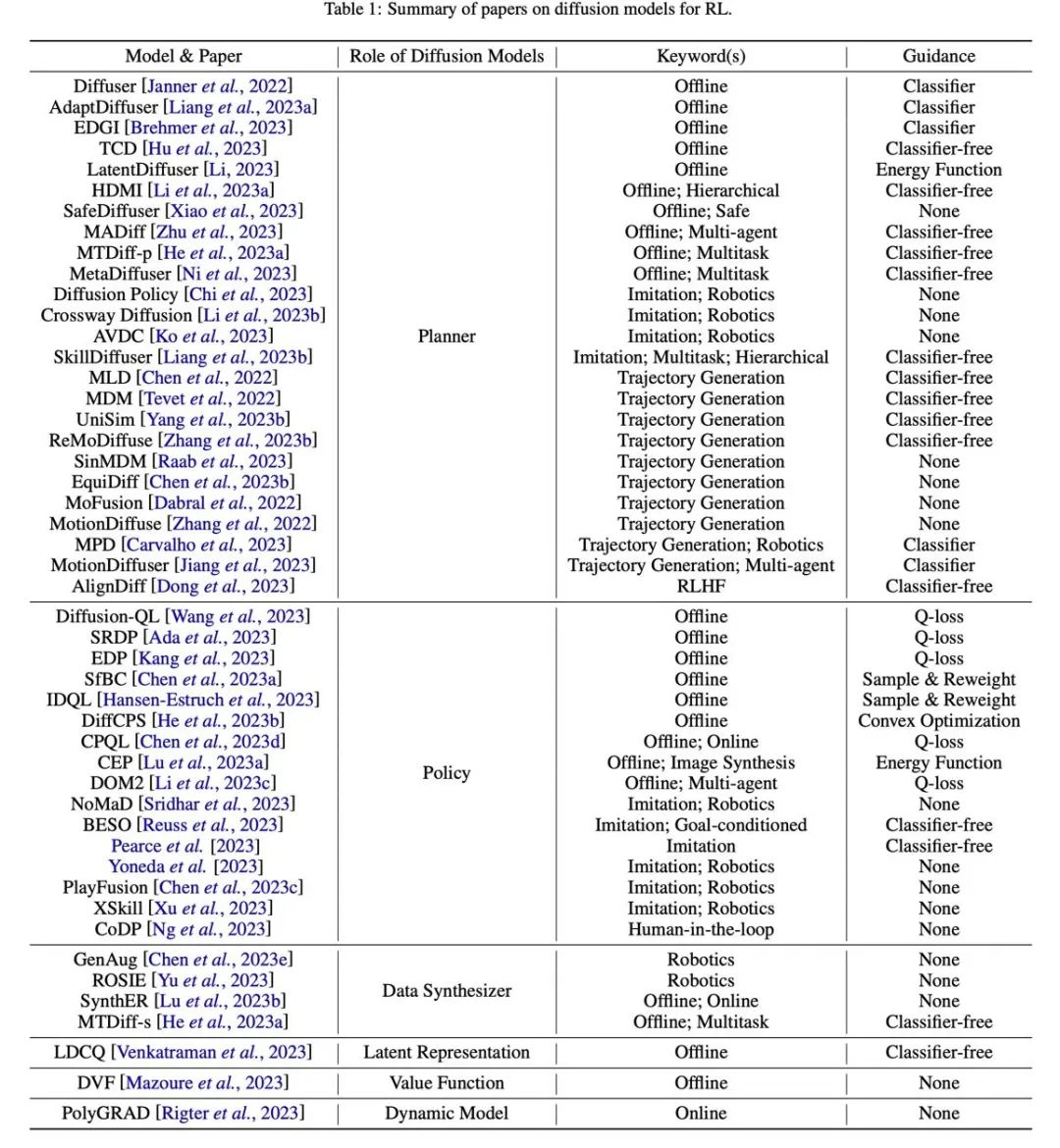
Figure 7: Summary and classification table of related papers.
The above is the detailed content of How does the diffusion model build a new generation of decision-making agents? Beyond autoregression, simultaneously generate long sequence planning trajectories. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



