


Meta FAIR The research project Tian Yuandong participated in received widespread praise last month. In their paper "MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases", they began to explore how to optimize small models with less than 1 billion parameters, aiming to achieve the goal of running large language models on mobile devices.
On March 6, Tian Yuandong’s team released the latest research results, this time focusing on improving the efficiency of LLM memory. In addition to Tian Yuandong himself, the research team also includes researchers from the California Institute of Technology, the University of Texas at Austin, and CMU. This research aims to further optimize the performance of LLM memory and provide support and guidance for future technology development.
They jointly proposed a training strategy called GaLore (Gradient Low-Rank Projection), which allows full parameter learning. Compared with common low-rank automatic methods such as LoRA, Adaptation method, GaLore is more memory efficient.
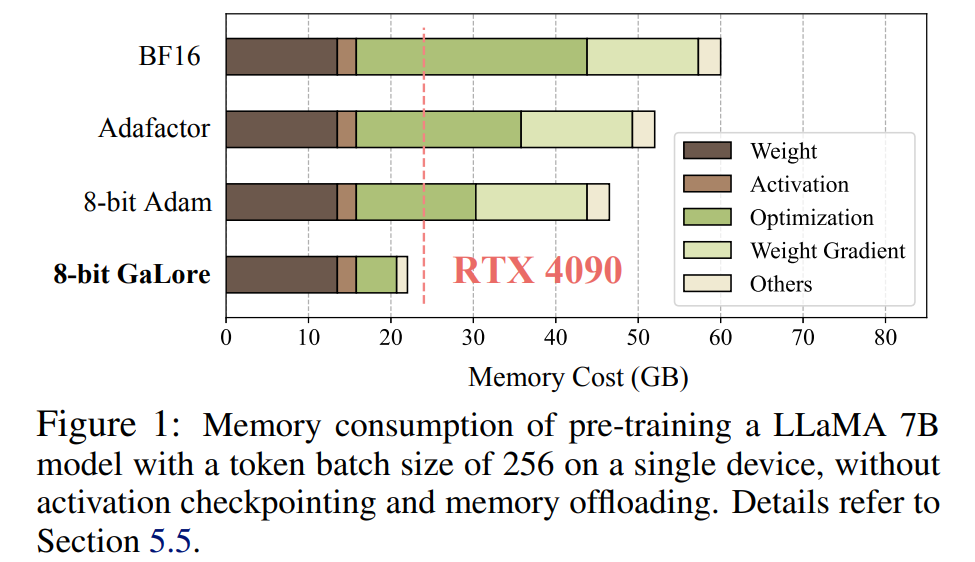
This study shows for the first time that 7B models can be successfully pre-trained on a consumer GPU with 24GB of memory, such as the NVIDIA RTX 4090, without using model parallelism, Checkpoint or offload strategy.

Paper address: https://arxiv.org/abs/2403.03507
Paper title: GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
Next let’s take a look at the main content of the article.
Currently, large language models (LLM) have shown outstanding potential in many fields, but we must also face a realistic problem, that is, pre-training and fine-tuning LLM not only require a large amount of Computing resources also require a large amount of memory support.
LLM's memory requirements include not only parameters in the billions, but also gradients and Optimizer States (such as gradient momentum and variance in Adam), which can be larger than the storage itself. For example, LLaMA 7B, pretrained from scratch using a single batch size, requires at least 58 GB of memory (14 GB for trainable parameters, 42 GB for Adam Optimizer States and weight gradients, and 2 GB for activations). This makes training LLM infeasible on consumer-grade GPUs such as the NVIDIA RTX 4090 with 24GB of memory.
To solve the above problems, researchers continue to develop various optimization techniques to reduce memory usage during pre-training and fine-tuning.
This method reduces memory usage by 65.5% under Optimizer States while maintaining pre-training on the C4 dataset with up to 19.7B tokens on LLaMA 1B and 7B architectures efficiency and performance, as well as fine-tuning the efficiency and performance of RoBERTa on GLUE tasks. Compared to the BF16 baseline, 8-bit GaLore further reduces optimizer memory by 82.5% and total training memory by 63.3%.
After seeing this research, netizens said: “It’s time to forget the cloud and HPC. With GaLore, all AI4Science will be completed on a $2,000 consumer-grade GPU. ."
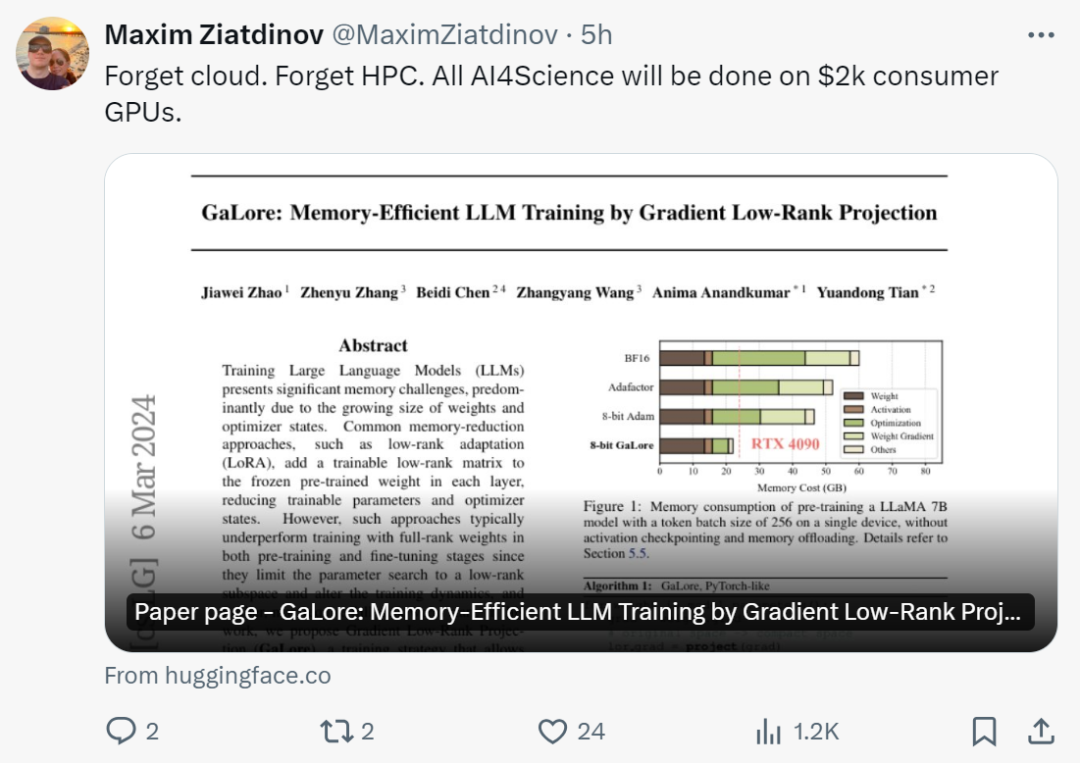
Tian Yuandong said: "With GaLore, it is now possible to pre-train the 7B model in NVidia RTX 4090s with 24G memory.
Instead of assuming a low-rank weight structure like LoRA, we show that the weight gradients are naturally low-rank and can therefore be projected into a (varying) low-dimensional space. Therefore, we simultaneously save memory for gradients, Adam momentum and variance.
Thus, unlike LoRA, GaLore does not change the training dynamics and can be used to pre-train 7B models from scratch without any memory-consuming pre-training. heat. GaLore can also be used for fine-tuning, producing results comparable to LoRA."
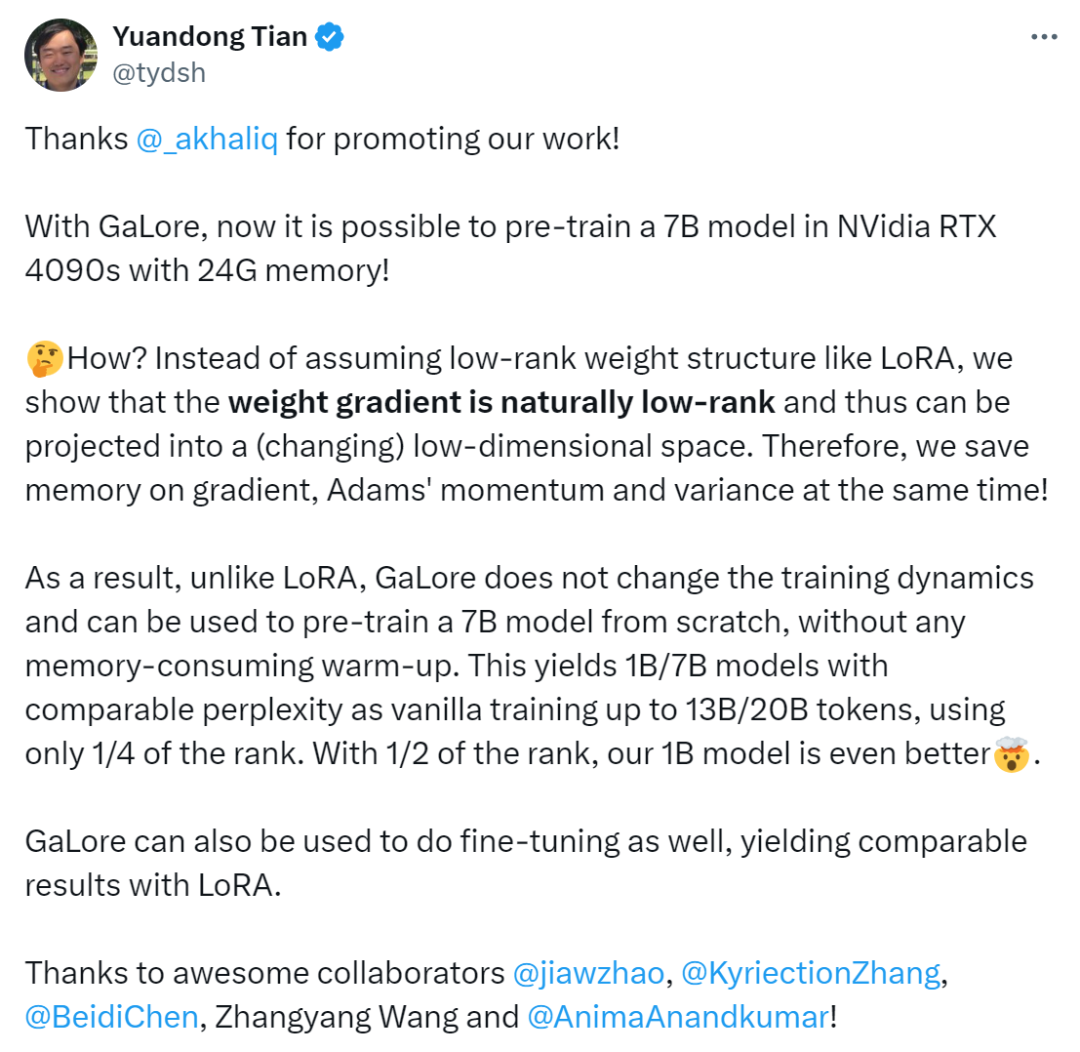
As mentioned earlier, GaLore is a training that allows full parameter learning strategy, but is more memory efficient than common low-rank adaptive methods such as LoRA. The key idea of GaLore is to utilize the slowly changing low-rank structure of the gradient 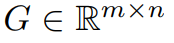 of the weight matrix W, rather than trying to directly approximate the weight matrix into a low-rank form.
of the weight matrix W, rather than trying to directly approximate the weight matrix into a low-rank form.
This article first theoretically proves that the gradient matrix G will become low rank during the training process. On the basis of theory, this article uses GaLore to calculate two projection matrices 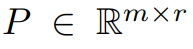 and
and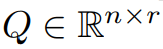 project the gradient matrix G into the low-rank form P^⊤GQ. In this case, the memory cost of Optimizer States that rely on component gradient statistics can be significantly reduced. As shown in Table 1, GaLore is more memory efficient than LoRA. In fact, this can reduce memory by up to 30% during pre-training compared to LoRA.
project the gradient matrix G into the low-rank form P^⊤GQ. In this case, the memory cost of Optimizer States that rely on component gradient statistics can be significantly reduced. As shown in Table 1, GaLore is more memory efficient than LoRA. In fact, this can reduce memory by up to 30% during pre-training compared to LoRA.

This article proves that GaLore performs well in pre-training and fine-tuning. When pre-training LLaMA 7B on the C4 dataset, 8-bit GaLore combines an 8-bit optimizer and layer-by-layer weight update technology to achieve performance comparable to full rank, with less than 10% memory cost for the optimizer state.
It is worth noting that for pre-training, GaLore maintains low memory throughout the training process without requiring full-rank training like ReLoRA. Thanks to the memory efficiency of GaLore, for the first time LLaMA 7B can be trained from scratch on a single GPU with 24GB of memory (e.g., on an NVIDIA RTX 4090) without any expensive memory offloading techniques (Figure 1).
As a gradient projection method, GaLore is independent of the choice of optimizer and can be easily plugged into an existing optimizer with just two lines of code. As shown in Algorithm 1.

The following figure shows the algorithm for applying GaLore to Adam:

The researchers evaluated the pre-training of GaLore and the fine-tuning of LLM. All experiments were performed on NVIDIA A100 GPU.
To evaluate its performance, the researchers applied GaLore to train a large language model based on LLaMA on the C4 dataset. The C4 dataset is a huge, sanitized version of the Common Crawl web crawling corpus, used primarily to pretrain language models and word representations. In order to best simulate the actual pre-training scenario, the researchers trained on a sufficiently large amount of data without duplicating the data, with model sizes ranging up to 7 billion parameters.
This paper follows the experimental setup of Lialin et al., using an LLaMA3-based architecture with RMSNorm and SwiGLU activation. For each model size, except for the learning rate, they used the same set of hyperparameters and ran all experiments in BF16 format to reduce memory usage while adjusting the learning rate for each method with the same computational budget. and report optimal performance.
In addition, the researchers used the GLUE task as a benchmark for memory-efficient fine-tuning of GaLore and LoRA. GLUE is a benchmark for evaluating the performance of NLP models in a variety of tasks, including sentiment analysis, question answering, and text association.
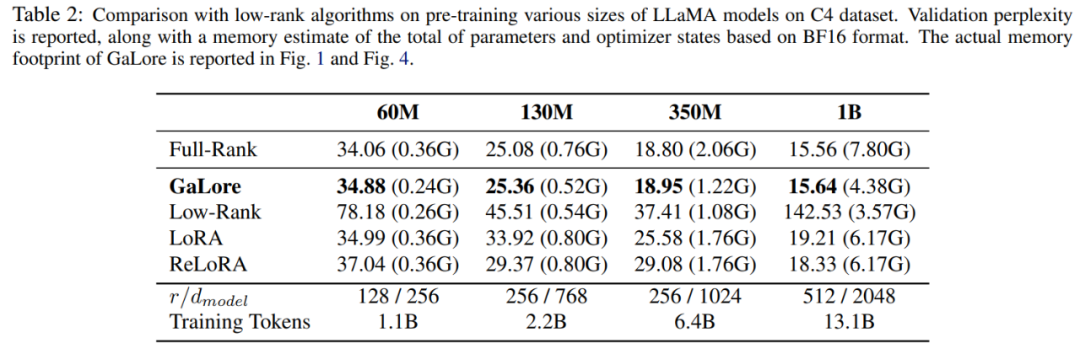
This paper first uses the Adam optimizer to compare GaLore with existing low-rank methods, and the results are shown in Table 2.
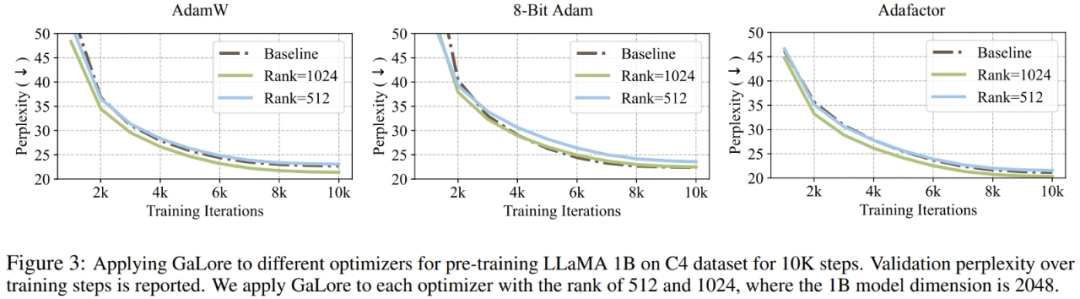
Researchers have proven that GaLore can be applied to various learning algorithms, especially memory-efficient optimizers, to further reduce memory usage. The researchers applied GaLore to the AdamW, 8-bit Adam, and Adafactor optimizers. They employ the first-order statistical Adafactor to avoid performance degradation.
Experiments evaluated them on the LLaMA 1B architecture with 10K training steps, tuned the learning rate for each setting, and reported the best performance. As shown in Figure 3, the graph below demonstrates that GaLore works with popular optimizers such as AdamW, 8-bit Adam, and Adafactor. Furthermore, introducing very few hyperparameters does not affect the performance of GaLore.
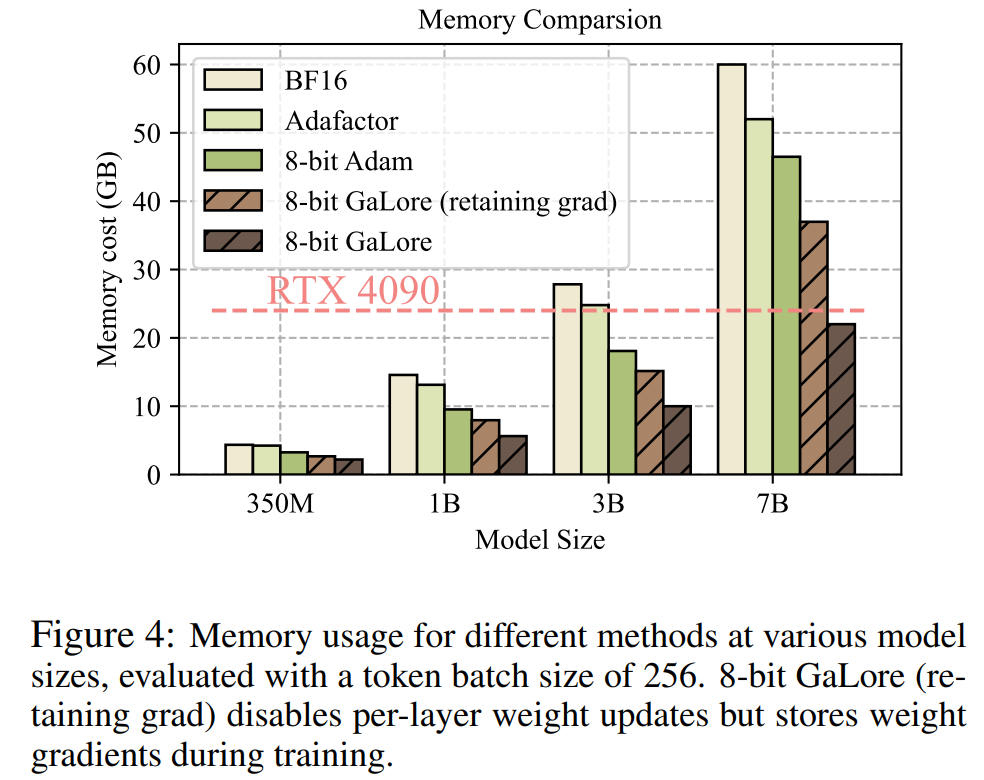
As shown in Table 4, GaLore can achieve higher performance than LoRA with less memory usage in most tasks. This demonstrates that GaLore can be used as a full-stack memory-efficient training strategy for LLM pre-training and fine-tuning.
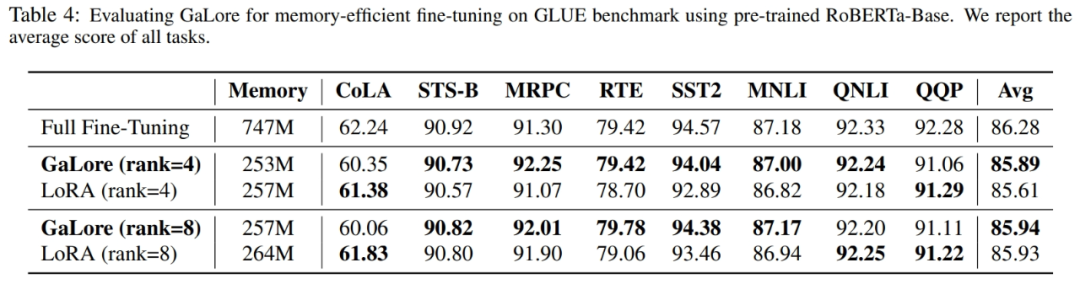
As shown in Figure 4, 8 bit GaLore requires much less memory compared to the BF16 benchmark and 8 bit Adam. Pre-training LLaMA 7B only requires 22.0G of memory, and the token batch size per GPU is small (up to 500 tokens).
For more technical details, please read the original paper.
The above is the detailed content of New work by Tian Yuandong and others: Breaking through the memory bottleneck and allowing a 4090 pre-trained 7B large model. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



