


Concept drift has always been a thorny problem in machine learning research. It refers to changes in data distribution over time, causing the effectiveness of the model to be affected. This situation forces researchers to constantly adjust models to adapt to new data distributions. The key to solving the problem of concept drift is to develop algorithms that can detect and adapt to changes in data in a timely manner.
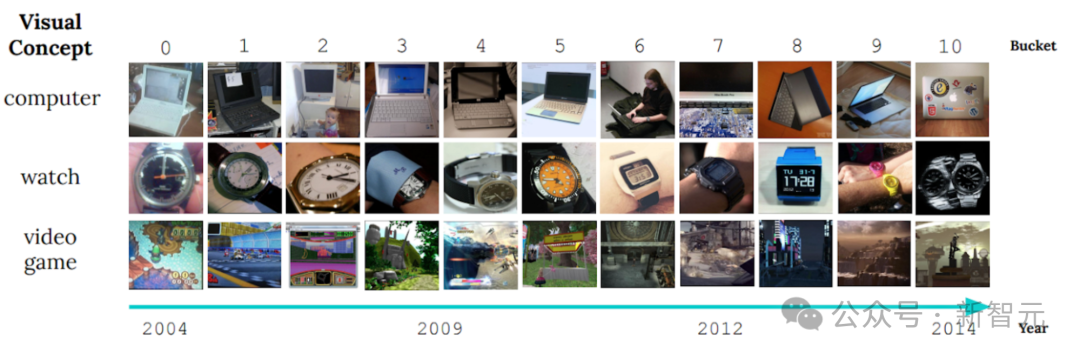
One obvious case is the image display of the CLEAR non-steady state learning benchmark, which reveals the past ten years. Significant changes in the visual characteristics of objects over the course of the year.
This phenomenon is called "slow concept drift" and poses a severe challenge to object classification models. As the appearance or attributes of objects change over time, how to ensure that the model can adapt to this change and continue to classify accurately becomes the focus of research.
Recently, facing this challenge, Google AI’s research team proposed an optimization called MUSCATEL (Multi-Scale Temporal Learning) Driving methods, successfully improved model performance on large and ever-changing data sets. This research result has been published at AAAI2024.

Paper address: https://arxiv.org/abs/2212.05908
Currently, for The mainstream methods of probability drift are online learning and continuous learning (online and continue learning).
The main concept of these methods is to continuously update the model to adapt to the latest data to ensure the effectiveness of the model. However, this approach faces two main challenges.
These methods often focus only on the latest data, ignoring the valuable information contained in past data. In addition, they assume that the contribution of all data instances decays uniformly over time, which is not consistent with the actual situation.
The MUSCATEL method can effectively solve these problems. It assigns importance scores to training instances and optimizes the performance of the model in future instances.
To this end, the researchers introduced an auxiliary model that combines instances and their ages to generate scores. The auxiliary model and the main model learn collaboratively to solve two core problems.
This method performs well in practical applications. In a large real-world dataset experiment covering 39 million photos and lasting for 9 years, it outperformed other steady-state learning baselines. method, the accuracy increased by 15%.
At the same time, it also shows better results than the SOTA method in two non-stationary learning data sets and continuous learning environments.
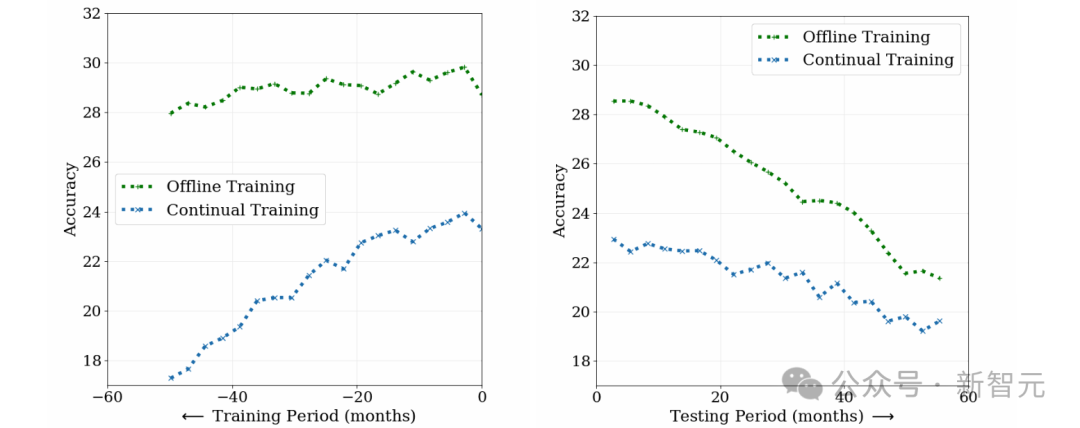
To study the challenges of concept drift to supervised learning, researchers conducted a photo classification task Two methods, offline training and continue training, were compared, using about 39 million social media photos from 10 years.
As shown in the figure below, although the initial performance of the offline training model is high, the accuracy decreases over time, and the understanding of early data is reduced due to catastrophic forgetting.
On the contrary, although the initial performance of the continuous training model is lower, it is less dependent on old data and degrades faster during testing.
This shows that the data evolves over time and the applicability of the two models decreases. Concept drift poses a challenge to supervised learning, which requires continuous updating of the model to adapt to changes in data.
MUSCATEL
##MUSCATEL is an innovative approach to the concept of slowness The problem of drift. It aims to reduce the performance degradation of the model in the future by cleverly combining the advantages of offline learning and continuous learning.
In the face of huge training data, MUSCATEL shows its unique charm. It not only relies on traditional offline learning, but also carefully regulates and optimizes the impact of past data on this basis, laying a solid foundation for the future performance of the model.
In order to further improve the performance of the main model on new data, MUSCATEL introduces an auxiliary model.
Based on the optimization goals in the figure below, the training auxiliary model assigns weights to each data point based on its content and age. This design enables the model to better adapt to changes in future data and maintain continuous learning capabilities.

In order to co-evolve the auxiliary model and the main model, MUSCATEL also adopts a meta-learning strategy.
The key to this strategy is to effectively separate the contribution of sample instances and age, and to set the weights by combining multiple fixed decay time scales, as shown in the figure below.
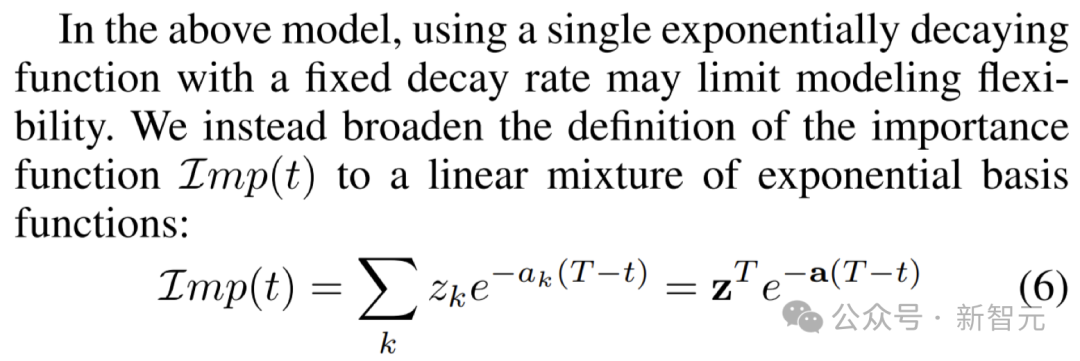
In addition, MUSCATEL also learns to "distribute" each instance to the most suitable time scale to achieve more Precise learning.
As shown in the figure below, in the CLEAR object recognition challenge, the learned auxiliary model successfully adjusted the weight of the object: The weight of objects with the new appearance is increased, and the weight of objects with the old appearance is decreased.

Through gradient-based feature importance evaluation, it can be found that the auxiliary model focuses on the subject in the image, rather than the background or the instance age-independent characteristics, thereby proving its effectiveness.

The large-scale photo classification task was studied on the YFCC100M dataset Photo classification task (PCAT) uses the data of the first five years as the training set and the data of the last five years as the test set.
Compared with unweighted baselines and other robust learning techniques, the MUSCATEL method shows obvious advantages.
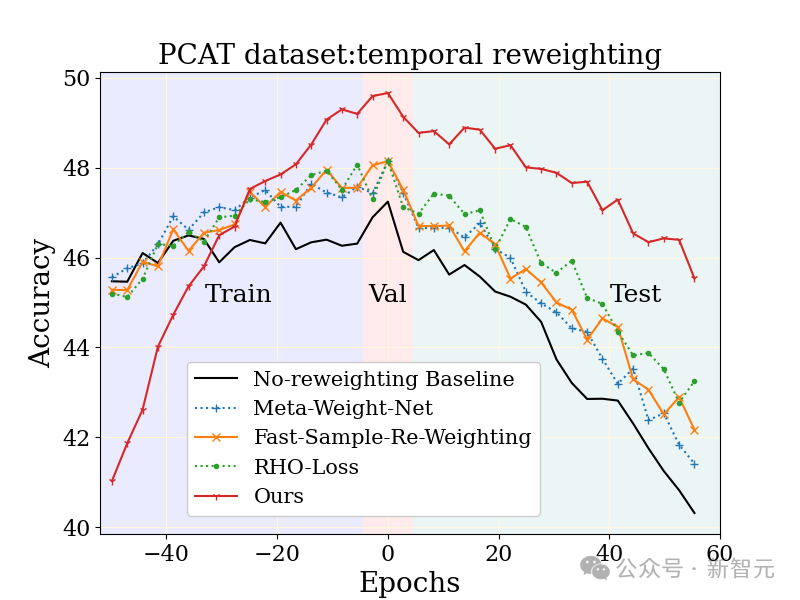
#It is worth noting that the MUSCATEL method consciously adjusts the accuracy of data from the distant past in exchange for a significant improvement in performance during testing. This strategy not only optimizes the model's ability to adapt to future data, but also shows lower degradation during testing.
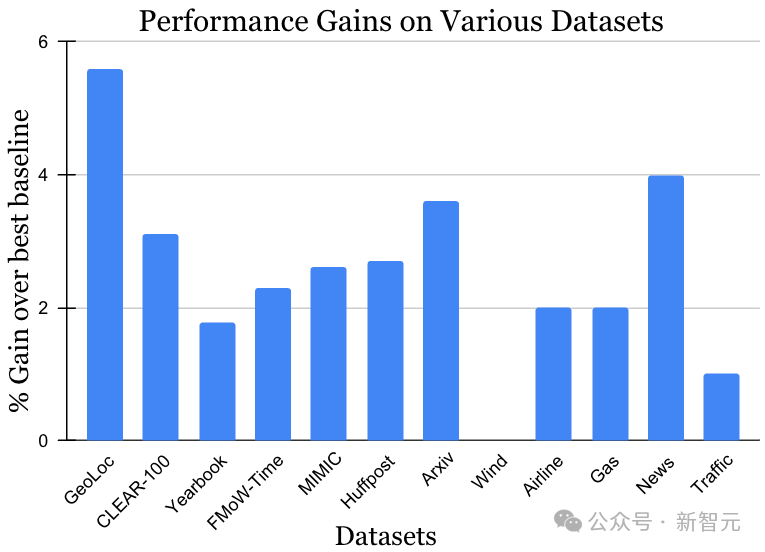
The dataset for the non-stationary learning challenge covers a variety of data sources and modalities, including photos , satellite images, social media text, medical records, sensor readings and tabular data, the data size also ranges from 10k to 39 million instances. It is worth noting that the previous best method may be different for each data set. However, as shown in the figure below, in the context of diversity in both data and methods, the MUSCATEL method has shown significant gain effects. This result fully demonstrates the broad applicability of MUSCATEL.
When faced with mountains of When dealing with large-scale data, traditional offline learning methods may feel inadequate.
With this problem in mind, the research team cleverly adapted a method inspired by continuous learning to easily adapt to the processing of large-scale data.
This method is very simple, which is to add a time weight to each batch of data and then update the model sequentially.
Although there are still some minor limitations in doing this, such as model updates can only be based on the latest data, the effect is surprisingly good!
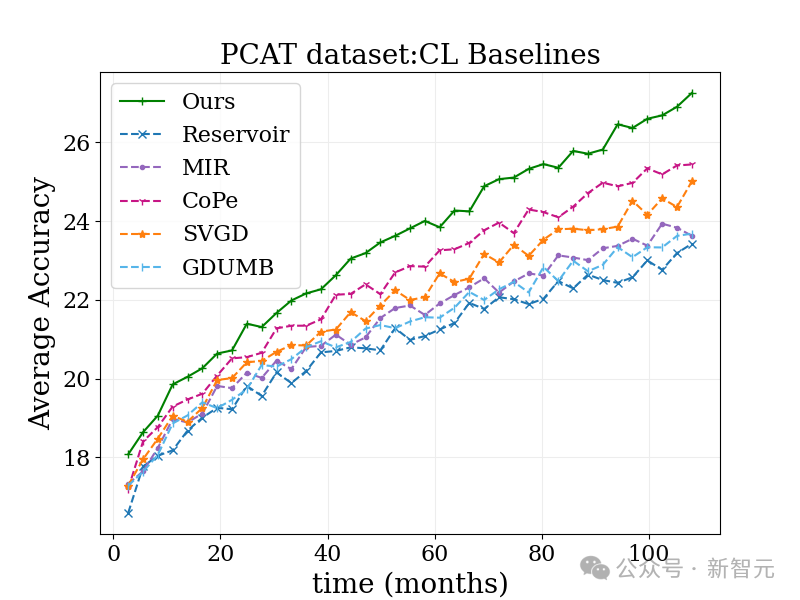
In the photo classification benchmark test below, this method performed better than the traditional continuous learning algorithm and various other algorithms.
Moreover, since its idea matches well with many existing methods, it is expected that when combined with other methods, the effect will be even more amazing!
# Overall, the research team successfully combined offline and continuous learning to solve the data drift problem that has long plagued the industry.
This innovative strategy not only significantly alleviates the "disaster forgetting" phenomenon of the model, but also opens up a new path for the future development of large-scale data continuous learning, and provides a new direction for the entire field of machine learning. Injected new vitality.
The above is the detailed content of Fight the problem of 'conceptual elegance'! Google releases new time perception framework: image recognition accuracy increased by 15%. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



