


"It is by no means a simple cutout."
ControlNet authorThe latest study has received a wave of high attention——
Give me a prompt, you can use Stable Diffusion to directly generate single or multiple transparent layers (PNG) !
For example:
A woman with messy hair is in the bedroom.
Woman with messy hair, in the bedroom.

As you can see, AI not only generated a complete image that conforms to the prompt, but even the background Can also be separated from characters.
And if you zoom in on the character PNG image and take a closer look, you will see that the hair strands are clearly defined.

Look at another example:
Burning firewood, on a table, in the countryside.
Burning firewood, on a table, in the countryside.

Similarly, zoom in on the PNG of the "burning match", even the black smoke around the flame can all be separated:

This is the new method proposed by the author of ControlNet - LayerDiffusion, which allows large-scale pre-training of latent diffusion models (Latent Diffusion Model) generates transparent images.

It is worth emphasizing again that LayerDiffusion is by no means as simple as cutout, the focus is on generating.
As netizens said:
This is one of the core processes in animation and video production now. If this step can be passed, it can be said that SD consistency is no longer a problem.
# Some netizens thought that a job like this was not difficult, just a matter of "adding an alpha channel by the way", but what surprised him was:
It took so long for the results to come out.
#So how is LayerDiffusion implemented?
The core of LayerDiffusion is a method called latent transparency(latent transparency).
Simply put, it allows adding transparency to the model without destroying the latent distribution of the pre-trained latent diffusion model (such as Stable Diffusion) .
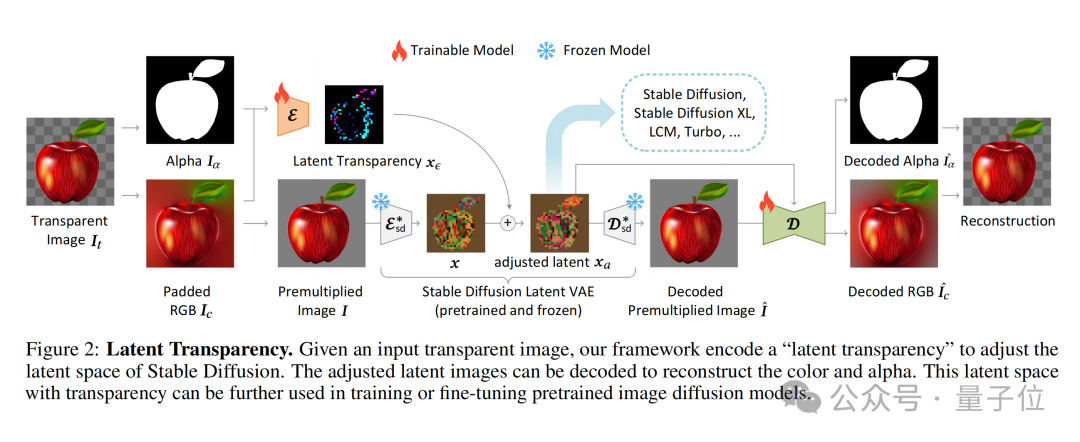
In terms of specific implementation, it can be understood as adding a carefully designed small perturbation (offset) to the latent image. This perturbation is encoded as an additional channel, which together with the RGB channel constitutes a complete potential image.
In order to achieve encoding and decoding of transparency, the author trained two independent neural network models: one is the latent transparency encoder(latent transparency encoder), and the other One is latent transparency decoder(latent transparency decoder).
The encoder receives the RGB channel and alpha channel of the original image as input and converts the transparency information into an offset in the latent space.
The decoder receives the adjusted latent image and the reconstructed RGB image, and extracts the transparency information from the latent space to reconstruct the original transparent image.
To ensure that the added potential transparency does not destroy the underlying distribution of the pre-trained model, the authors propose a measure of "harmlessness" .
This metric evaluates the impact of latent transparency by comparing the decoding results of the adjusted latent image by the original pre-trained model's decoder to the original image.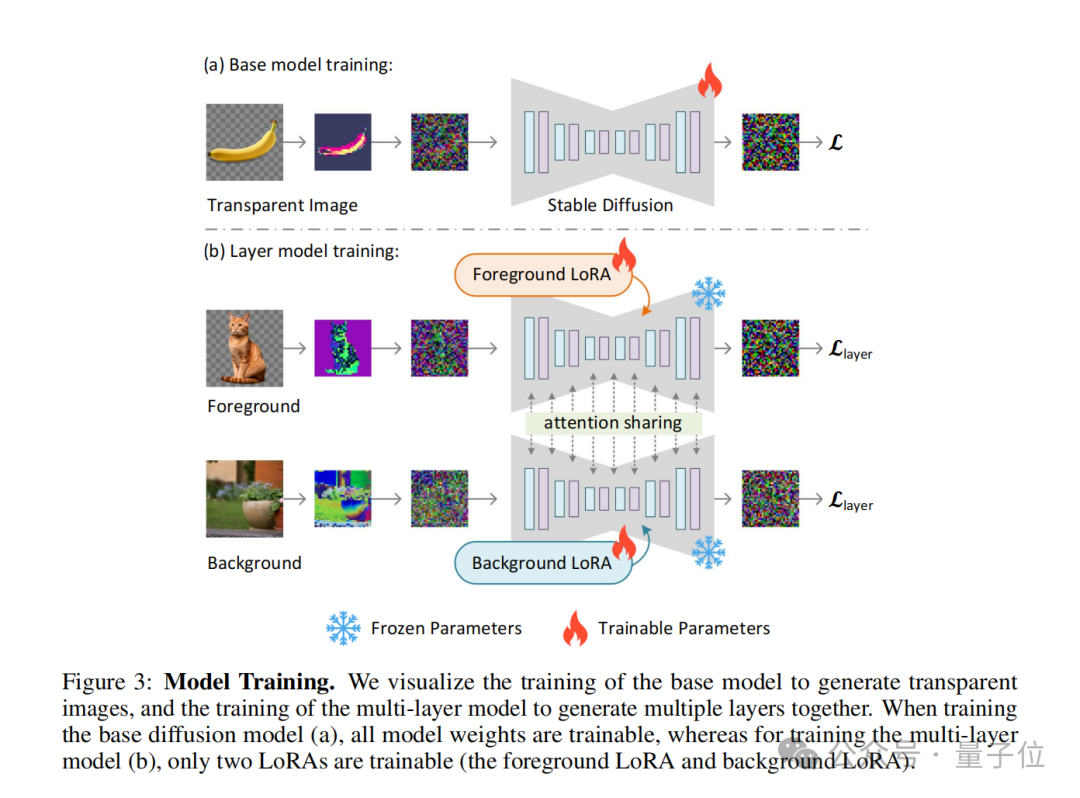
(joint loss function), which combines the reconstruction loss( reconstruction loss), identity loss (identity loss) and discriminator loss. Their functions are:
Reconstruction loss: used to ensure that the decoded image is as similar as possible to the original image; The concept of latent transparency can also be extended to generate multiple transparent layers, as well as combined with other conditional control systems to achieve more complex image generation tasks such as foreground/background Conditional generation, joint layer generation, structural control of layer content, etc.
The concept of latent transparency can also be extended to generate multiple transparent layers, as well as combined with other conditional control systems to achieve more complex image generation tasks such as foreground/background Conditional generation, joint layer generation, structural control of layer content, etc.


##It is worth mentioning that the author also shows how to introduce ControlNet to enrich the functions of LayerDiffusion: 
The difference with traditional cutout
Native generation vs. post-processing
LayerDiffusion is a native transparent image generation method that considers and encodes transparency information directly during the generation process. This means that the model creates an alpha channel when generating the image, thus producing an image with transparency.
Traditional matting methods usually involve first generating or obtaining an image, and then using image editing techniques(such as chroma key, edge detection, user-specified masks, etc.) to separate the foreground and background. This approach often requires additional steps to handle transparency and can produce unnatural transitions on complex backgrounds or edges.
Latent space operations vs. pixel space operations
LayerDiffusion operates in latent space (latent space) , which is an intermediate representation that allows the model to learn and generate more complex image features. By encoding transparency in the latent space, the model can naturally handle transparency during generation without the need for complex calculations at the pixel level.
Traditional cutout technology is usually performed in pixel space, which may involve direct editing of the original image, such as color replacement, edge smoothing, etc. These methods may have difficulty handling translucent effects (such as fire, smoke) or complex edges.
Dataset and training
LayerDiffusion uses a large-scale data set for training. This data set contains transparent image pairs, allowing the model to learn to generate high-definition images. Complex distribution required for quality transparent images.
Traditional matting methods may rely on smaller data sets or specific training sets, which may limit their ability to handle diverse scenarios.
Flexibility and control
LayerDiffusion provides greater flexibility and control because it allows users to prompt via text (text prompts) to guide the generation of images and can generate multiple layers that can be blended and combined to create complex scenes.
Traditional cutout methods may be more limited in control, especially when dealing with complex image content and transparency.
Quality Comparison
User research shows that transparent images generated by LayerDiffusion are preferred by users in most cases (97%) , indicating The transparent content it generates is visually equivalent to, or perhaps even superior to, commercial transparent assets.
Traditional cutout methods may not achieve the same quality in some cases, especially when dealing with challenging transparency and edges.
In short, LayerDiffusion provides a more advanced and flexible method to generate and process transparent images.
It encodes transparency directly during the generation process and is able to produce high-quality results that are difficult to achieve in traditional matting methods.
As we just mentioned, one of the authors of this study is the inventor of the famous ControlNet-Zhang Lumin.
He graduated from Suzhou University with an undergraduate degree. He published a paper related to AI painting when he was a freshman. During his undergraduate period, he published 10 top-level works.
Zhang Lumin is currently studying for a PhD at Stanford University, but he can be said to be very low-key and has not even registered for Google Scholar.
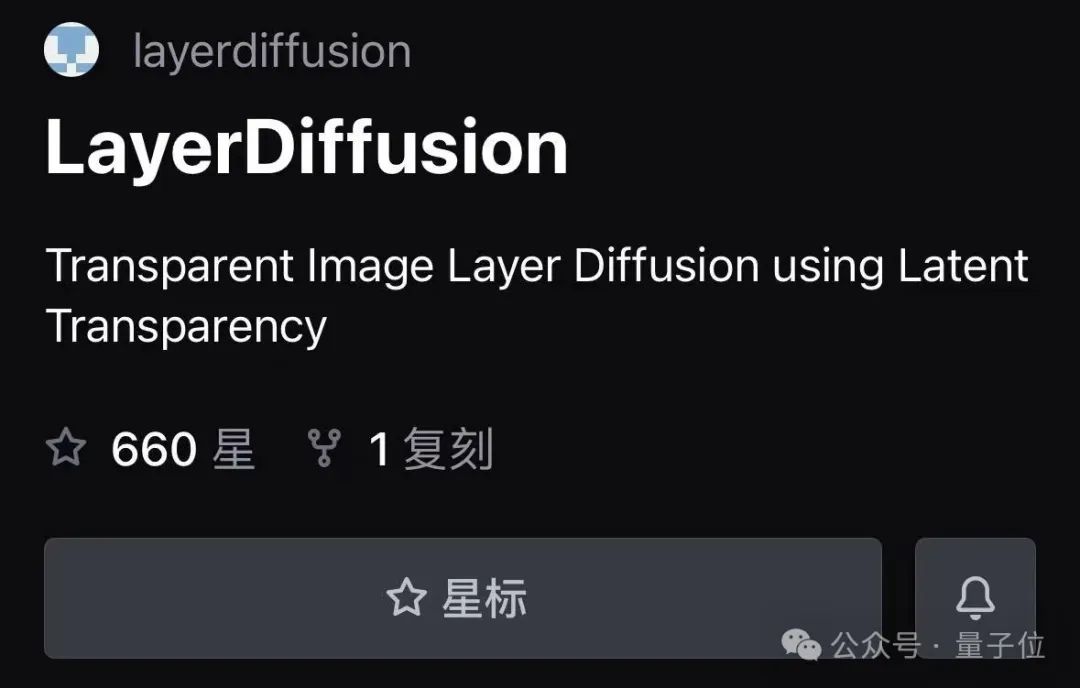
As of now, LayerDiffusion is not open source in GitHub, but even so it cannot stop everyone's attention and has already gained 660 stars.
After all, Zhang Lumin has also been ridiculed by netizens as a "time management master". Friends who are interested in LayerDiffusion can mark it in advance.
The above is the detailed content of New work by the author of ControlNet: AI painting can be divided into layers! The project earned 660 stars without being open source. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



