


In the field of target detection, YOLOv9 continues to make progress during the implementation process. By adopting new architecture and methods, it effectively improves the parameter utilization of traditional convolution, which makes its performance far superior to previous generation products.
More than a year after YOLOv8 was officially released in January 2023, YOLOv9 is finally here!
Since Joseph Redmon, Ali Farhadi and others proposed the first-generation YOLO model in 2015, researchers in the field of target detection have updated and iterated it many times. YOLO is a prediction system based on global information of images, and its model performance is continuously enhanced. By continuously improving algorithms and technologies, researchers have achieved remarkable results, making YOLO more and more powerful in target detection tasks. These continuous improvements and optimizations have brought new opportunities and challenges to the development of target detection technology, while also promoting progress and innovation in this field. The success of YOLO has also inspired researchers to continue their efforts.
This time, YOLOv9 was jointly developed by Academia Sinica, Taipei University of Technology, Taiwan, and other institutions. The related paper "Learning What You Want to Learn Using Programmable Gradient Information" 》has been released.

Paper address: https://arxiv.org/pdf/2402.13616.pdf
GitHub address: https://github.com/WongKinYiu/ yolov9
Today’s deep learning methods focus on how to design the most appropriate objective function so that the model’s prediction results can be closest to the real situation. At the same time, an appropriate architecture must be designed that can help obtain sufficient information for prediction. However, existing methods ignore the fact that a large amount of information will be lost when the input data undergoes layer-by-layer feature extraction and spatial transformation.
Therefore, YOLOv9 deeply studies the important issues of data loss when data is transmitted through deep networks, namely information bottlenecks and reversible functions.
Researchers proposed the concept of programmable gradient information (PGI) to cope with the various changes required by deep networks to achieve multiple goals. PGI can provide complete input information for the target task to calculate the objective function, thereby obtaining reliable gradient information to update network weights.
In addition, researchers designed a new lightweight network architecture based on gradient path planning, namely Generalized Efficient Layer Aggregation Network (GELAN). This architecture confirms that PGI can achieve excellent results on lightweight models.
The researchers verified the proposed GELAN and PGI on the target detection task based on the MS COCO data set. Results show that GELAN achieves better parameter utilization using only traditional convolution operators compared to SOTA methods developed based on deep convolutions.
For PGI, it is very adaptable and can be used on various models from light to large. We can use this to obtain complete information, thereby enabling a model trained from scratch to achieve better results than a SOTA model pre-trained using a large dataset. Figure 1 below shows some comparison results.

For the newly released YOLOv9, Alexey Bochkovskiy, who has participated in the development of YOLOv7, YOLOv4, Scaled-YOLOv4 and DPT, spoke highly of it, saying that YOLOv9 is better than any convolution-based or transformer's object detector.

## Source: https://twitter.com/alexeyab84/status/1760685626247250342
and Netizens said that YOLOv9 looks like the new SOTA real-time target detector, and his own custom training tutorial is also on the way.

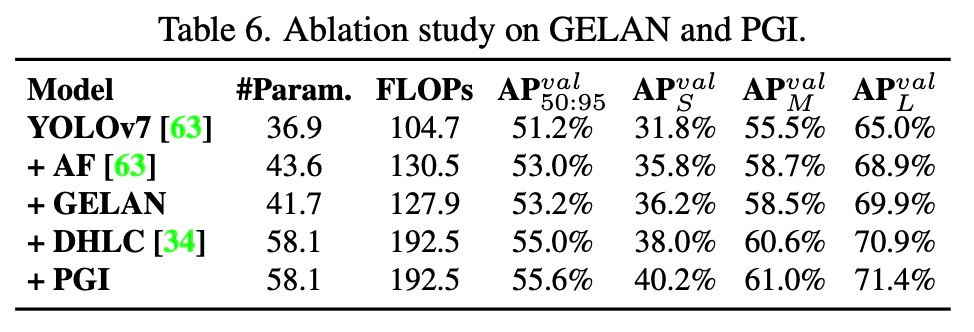
#More "hard-working" netizens have added pip support to the YOLOv9 model. ## Source: https://twitter.com/kadirnar_ai/status/1760716187896283635 Problem Statement Neural Network to factors such as gradient disappearance or gradient saturation. These phenomena are indeed Exists in traditional deep neural networks. However, modern deep neural networks have fundamentally solved the above problems by designing various normalization and activation functions. But even so, there are still problems with slow convergence speed or poor convergence effect in deep neural networks. So what is the essence of this problem? Through in-depth analysis of the information bottleneck, the researchers deduced the root cause of the problem: soon after the gradient is initially passed out from the very deep network, much of the information needed to achieve the goal is lost. To verify this inference, the researchers performed feedforward processing on deep networks of different architectures with initial weights. Figure 2 illustrates this visually. Clearly, PlainNet loses a lot of important information required for object detection at deep layers. As for the proportion of important information that ResNet, CSPNet and GELAN can retain, it is indeed positively related to the accuracy that can be obtained after training. The researchers further designed a method based on reversible networks to solve the causes of the above problems. Method Introduction Programmable Gradient Information (PGI) This study proposes a new auxiliary supervision framework : Programmable Gradient Information (PGI), as shown in Figure 3(d). In addition, the study also proposes a new network architecture GELAN (as shown in the figure below). Specifically, The researchers combined the two neural network architectures of CSPNet and ELAN to design a generalized efficient layer aggregation network (GELAN) that takes into account lightweight, reasoning speed and accuracy. The researchers generalized the capabilities of ELAN, which initially only used stacks of convolutional layers, to a new architecture that can use any computational block. To evaluate the performance of YOLOv9, the study first compared YOLOv9 with other real-time object detectors trained from scratch A comprehensive comparison was conducted and the results are shown in Table 1 below. In order to explore the role of each component in YOLOv9, this study conducted a series of ablation experiments. In terms of PGI, researchers conducted ablation studies on auxiliary reversible branches and multi-level auxiliary information on the backbone network and neck respectively. Table 4 lists the results of all experiments. As can be seen from Table 4, PFH is only effective for deep models, while the PGI proposed in this paper can improve accuracy under different combinations. The researchers further implemented PGI and depth monitoring on models of different sizes and compared the results. The results are shown in Table 5. Figure 6 shows the results of incrementally adding components from baseline YOLOv7 to YOLOv9-E. Visualization The researchers explored the information bottleneck problem and visualized it. Figure 6 shows the Visualization results of feature maps obtained under the architecture using random initial weights as feedforward. Figure 7 illustrates whether PGI can provide more reliable gradients during training, so that the parameters used for updating effectively capture the relationship between the input data and the target. For more technical details, please read the original article. 
 Experimental results
Experimental results
 Ablation Experiment
Ablation Experiment





The above is the detailed content of New SOTA for target detection: YOLOv9 comes out, and the new architecture brings traditional convolution back to life. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



