


Have you ever encountered various memory problems in Linux systems? Such as memory leaks, memory fragmentation, etc. These problems can be solved through a deep understanding of the Linux memory model.
The Linux kernel supports three memory models, namely flat memory model, Discontiguous memory model and sparse memory model. The so-called memory model actually refers to the distribution of physical memory from the perspective of the CPU and the method used to manage these physical memories in the Linux kernel. In addition, it should be noted that this article mainly focuses on shared memory systems, which means that all CPUs share a physical address space.
The content of this article is organized as follows: In order to clearly analyze the memory model, we describe some basic terms, which is in Chapter 2. The third chapter explains the working principles of the three memory models. The last chapter is code analysis. The code comes from the 4.4.6 kernel. For architecture-related codes, we use ARM64 for analysis.
1. What is page frame?
One of the most important functions of the operating system is to manage various resources in the computer system. As the most important resource: memory, we must manage it. In the Linux operating system, physical memory is managed according to page size. The specific page size is related to the hardware and Linux system configuration. 4k is the most classic setting. Therefore, for physical memory, we divide it into pages arranged by page size. The memory area of page size in each physical memory is called page frame. We establish a struct page data structure for each physical page frame to track the usage of each physical page: Is it used for the text segment of the kernel? Or is it a page table for a process? Is it used for various file caches or is it in a free state...
Each page frame has a one-to-one corresponding page data structure. The system defines page_to_pfn and pfn_to_page macros to convert between page frame number and page data structure. The specific conversion method is related to the memory module. We will describe the three memory models in the Linux kernel in detail in Chapter 3.
2. What is PFN?
For a computer system, its entire physical address space should be an address space starting from 0 and ending with the maximum physical space that the actual system can support. In the ARM system, assuming the physical address is 32 bits, then the physical address space is 4G. In the ARM64 system, if the number of supported physical address bits is 48, then the physical address space is 256T. Of course, in fact, not all such a large physical address space is used for memory, some also belong to I/O space (of course, some CPU arches have their own independent io address space). Therefore, the physical address space occupied by the memory should be a limited interval, and it is impossible to cover the entire physical address space. However, now that memory is getting larger and larger, for 32-bit systems, the 4G physical address space can no longer meet the memory requirements, so there is the concept of high memory, which will be described in detail later.
PFN is the abbreviation of page frame number. The so-called page frame refers to physical memory. The physical memory is divided into page size areas and each page is numbered. This number is PFN. Assuming that physical memory starts at address 0, then the page frame with PFN equal to 0 is the page that starts at address 0 (physical address). Assuming that physical memory starts at address x, then the first page frame number is (x>>PAGE_SHIFT).
3. What is NUMA?
There are two options when designing the memory architecture for a multiprocessors system: one is UMA (Uniform memory access). All processors in the system share a unified and consistent physical memory space, no matter which processor initiates it. The access time to the memory address is the same. NUMA (Non-uniform memory access) is different from UMA. Access to a certain memory address is related to the relative position between the memory and the processor. For example, for a processor on a node, accessing local memory takes longer than accessing remote memory.
1. What is FLAT memory model?
If from the perspective of any processor in the system, when it accesses physical memory, the physical address space is a continuous address space without holes, then the memory model of this computer system is Flat memory. Under this memory model, the management of physical memory is relatively simple. Each physical page frame will have a page data structure to abstract it. Therefore, there is an array of struct page (mem_map) in the system, and each array entry points to an actual physical page. Frame (page frame). In the case of flat memory, the relationship between PFN (page frame number) and mem_map array index is linear (there is a fixed offset, if the physical address corresponding to the memory is equal to 0, then PFN is the array index). Therefore, it is very easy to go from PFN to the corresponding page data structure, and vice versa. For details, please refer to the definitions of page_to_pfn and pfn_to_page. In addition, for the flat memory model, there is only one node (struct pglist_data) (in order to use the same mechanism as the Discontiguous Memory Model). The following picture describes the situation of flat memory:
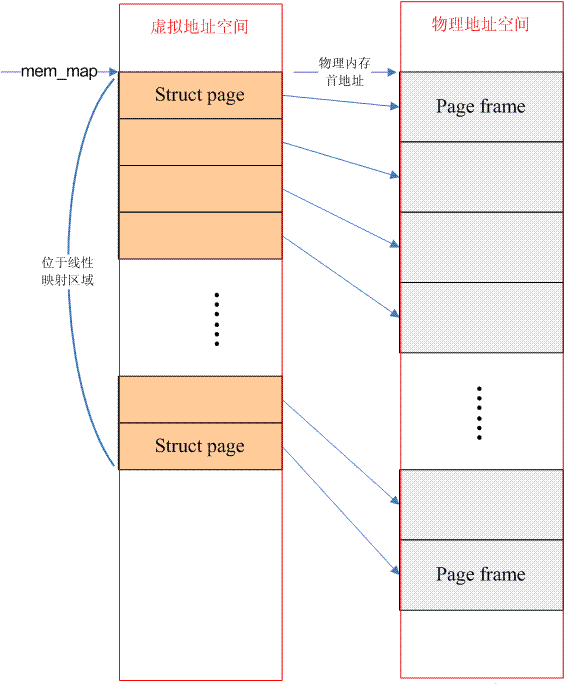
It should be emphasized that the memory occupied by struct page is in the directly mapped interval, so the operating system does not need to create a page table for it.
2. What is Discontiguous Memory Model?
If the CPU's address space has some holes and is discontinuous when accessing physical memory, then the memory model of this computer system is Discontiguous memory. Generally speaking, the memory model of a NUMA-based computer system is Discontiguous Memory. However, the two concepts are actually different. NUMA emphasizes the positional relationship between memory and processor, which has nothing to do with the memory model. However, because memory and processor on the same node have a closer coupling relationship (faster access), multiple nodes are needed to manage it. . Discontiguous memory is essentially an extension of the flat memory memory model. Most of the address space of the entire physical memory is a large piece of memory, with some holes in the middle. Each piece of memory address space belongs to a node (if it is limited to one Internally, node's memory model is flat memory). The following picture describes the situation of Discontiguous memory:
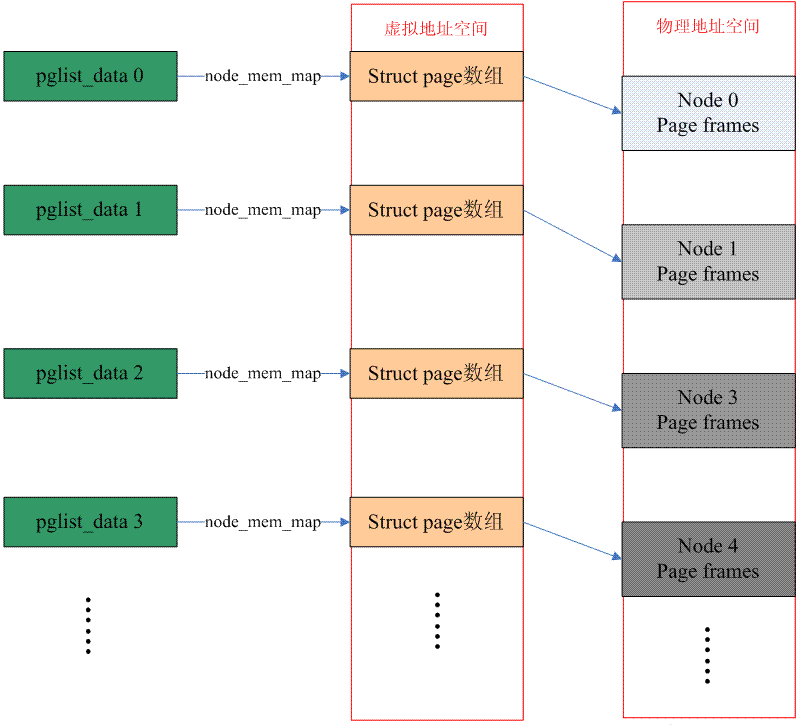
Therefore, under this memory model, there are multiple node data (struct pglist_data), and the macro definition NODE_DATA can get the struct pglist_data of the specified node. However, the physical memory managed by each node is stored in the node_mem_map member of the struct pglist_data data structure (the concept is similar to mem_map in flat memory). At this time, converting from PFN to a specific struct page will be a little more complicated. We first need to get the node ID from PFN, and then find the corresponding pglist_data data structure based on this ID, and then find the corresponding page array. The subsequent method is similar flat memory.
3. What is Sparse Memory Model?
Memory model is also an evolutionary process. At the beginning, flat memory was used to abstract a continuous memory address space (mem_maps[]). After NUMA appeared, the entire discontinuous memory space was divided into several nodes, each There is a continuous memory address space on the node. In other words, the original single mem_maps[] has become several mem_maps[]. Everything seems perfect, but the emergence of memory hotplug makes the original perfect design imperfect, because even mem_maps[] in a node may be discontinuous. In fact, after the emergence of sparse memory, the Discontiguous memory memory model is no longer so important. It stands to reason that sparse memory can eventually replace Discontiguous memory. This replacement process is in progress. The 4.4 kernel still has three memory models to choose from.
Why is it said that sparse memory can eventually replace Discontiguous memory? In fact, under the sparse memory memory model, the continuous address space is divided into sections according to SECTION (such as 1G), and each section is hotplugged. Therefore, under the sparse memory, the memory address space can be divided into more detailed sections. , supports more discrete Discontiguous memory. In addition, before sparse memory appeared, NUMA and Discontiguous memory were always in a confusing relationship: NUMA did not stipulate the continuity of its memory, and the Discontiguous memory system was not necessarily a NUMA system, but these two configurations They are all multi-node. With sparse memory, we can finally separate the concept of memory continuity from NUMA: a NUMA system can be flat memory or sparse memory, and a sparse memory system can be NUMA or UMA. .
The following picture illustrates how sparse memory manages page frames (SPARSEMEM_EXTREME is configured):
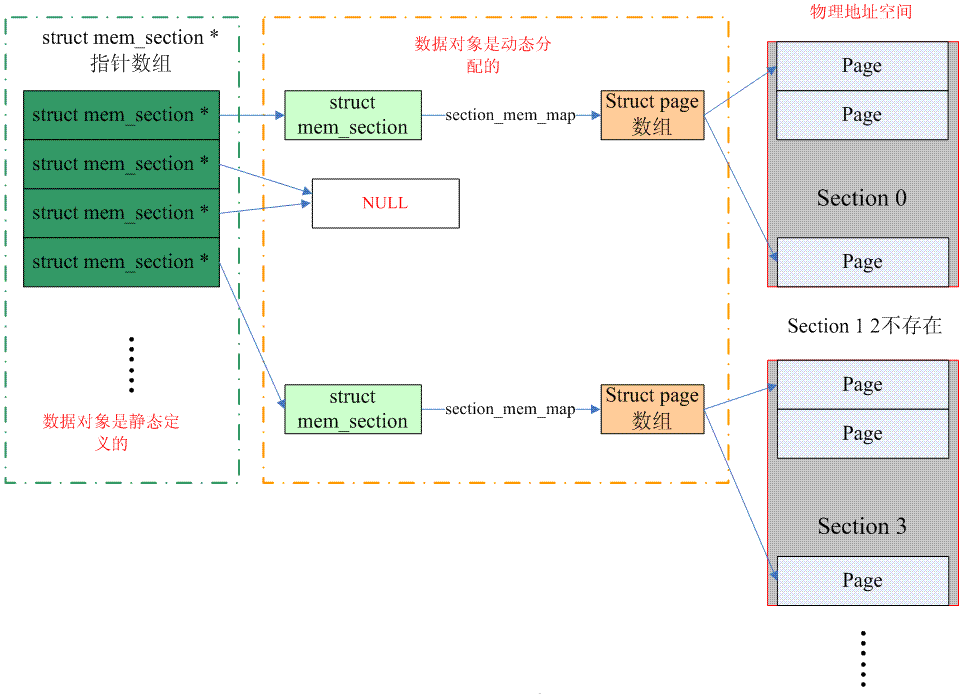
(Note: A mem_section pointer in the above picture should point to a page, and there are several struct mem_section data units in a page)
The entire continuous physical address space is cut off section by section. Inside each section, its memory is continuous (that is, it conforms to the characteristics of flat memory). Therefore, the page array of mem_map is attached to the section structure (struct mem_section) instead of node structure (struct pglist_data). Of course, no matter which memory model is used, the correspondence between PFN and page needs to be processed. However, sparse memory has an additional concept of section, making the conversion into PFNSectionpage.
Let’s first look at how to convert from PFN to page structure: a mem_section pointer array is statically defined in the kernel. A section often includes multiple pages, so it is necessary to convert PFN into a section number by right shifting, using section Number is used as index in the mem_section pointer array to find the section data structure corresponding to the PFN. After finding the section, you can find the corresponding page data structure along its section_mem_map. By the way, at the beginning, sparse memory used a one-dimensional memory_section array (not a pointer array). This implementation is very wasteful of memory for particularly sparse (CONFIG_SPARSEMEM_EXTREME) systems. In addition, it is more convenient to save the pointer for hotplug support. If the pointer is equal to NULL, it means that the section does not exist. The above picture describes the situation of a one-dimensional mem_section pointer array (SPARSEMEM_EXTREME is configured). For non-SPARSEMEM_EXTREME configuration, the concept is similar. You can read the code for the specific operation.
It is a little troublesome to go from page to PFN. In fact, PFN is divided into two parts: one part is the section index, and the other part is the offset of the page in the section. We need to first get the section index from the page, and then get the corresponding memory_section. Knowing the memory_section means that the page is in the section_mem_map, and we also know the offset of the page in the section. Finally, we can synthesize PFN. For the conversion of page to section index, sparse memory has two solutions. Let's look at the classic solution first, which is saved in page->flags (SECTION_IN_PAGE_FLAGS is configured). The biggest problem with this method is that the number of bits in page->flags is not necessarily enough, because this flag carries too much information. Various page flags, node ids, and zone ids now add a section id. Algorithms that cannot achieve consistency in different architectures. Is there a universal algorithm? This is CONFIG_SPARSEMEM_VMEMMAP. For the specific algorithm, please refer to the figure below:
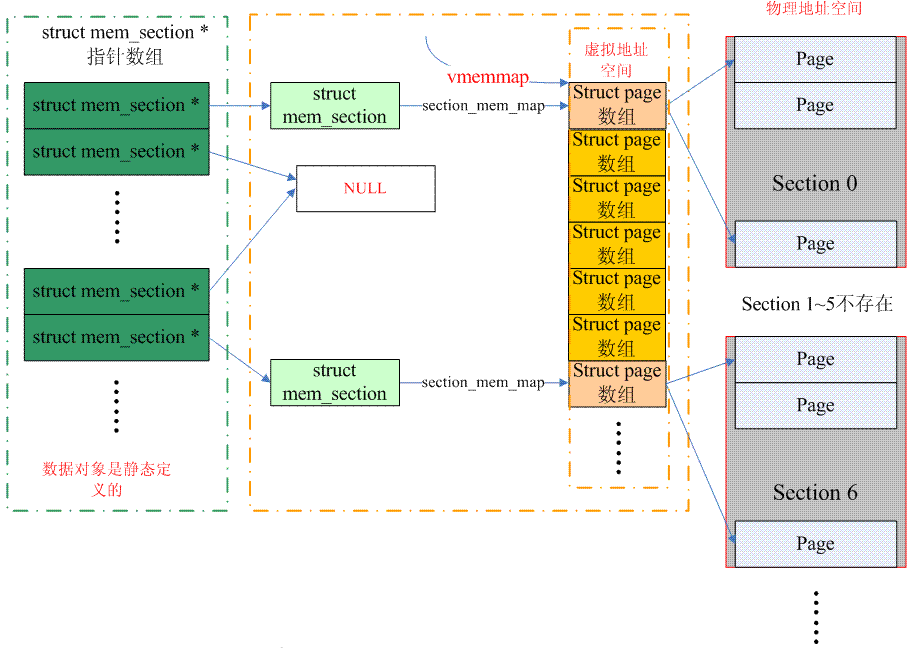
(There is a problem with the above picture. vmemmap only points to the first struct page array when PHYS_OFFSET is equal to 0. Generally speaking, there should be an offset, but I am too lazy to change it, haha)
For the classic sparse memory model, the memory occupied by a section's struct page array comes from the directly mapped area. The page table is established during initialization, and the page frame is allocated, which means the virtual address is allocated. However, for SPARSEMEM_VMEMMAP, the virtual address is allocated from the beginning. It is a continuous virtual address space starting from vmemmap. Each page has a corresponding struct page. Of course, there is only a virtual address and no physical address. Therefore, when a section is discovered, the virtual address of the corresponding struct page can be found immediately. Of course, it is also necessary to allocate a physical page frame and then establish a page table. Therefore, for this kind of sparse memory, the overhead will be slightly larger. Some (one more process of establishing mapping).
4. Code analysis
Our code analysis is mainly carried out through include/asm-generic/memory_model.h.
1. flat memory. code show as below:
“
\#define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET)) \#define __page_to_pfn(page) ((unsigned long)((page) - mem_map) + ARCH_PFN_OFFSET)Copy after login”
It can be seen from the code that PFN and struct page array (mem_map) index are linearly related, and there is a fixed offset called ARCH_PFN_OFFSET. This offset is related to the estimated architecture. For ARM64, it is defined in the arch/arm/include/asm/memory.h file. Of course, this definition is related to the physical address space occupied by the memory (that is, related to the definition of PHYS_OFFSET).
2. Discontiguous Memory Model. code show as below:
“
\#define __pfn_to_page(pfn) \ ({ unsigned long __pfn = (pfn); \ unsigned long __nid = arch_pfn_to_nid(__pfn); \ NODE_DATA(__nid)->node_mem_map + arch_local_page_offset(__pfn, __nid);\ }) \#define __page_to_pfn(pg) \ ({ const struct page *__pg = (pg); \ struct pglist_data *__pgdat = NODE_DATA(page_to_nid(__pg)); \ (unsigned long)(__pg - __pgdat->node_mem_map) + \ __pgdat->node_start_pfn; \ })Copy after login”
Discontiguous Memory Model需要获取node id,只要找到node id,一切都好办了,比对flat memory model进行就OK了。因此对于__pfn_to_page的定义,可以首先通过arch_pfn_to_nid将PFN转换成node id,通过NODE_DATA宏定义可以找到该node对应的pglist_data数据结构,该数据结构的node_start_pfn记录了该node的第一个page frame number,因此,也就可以得到其对应struct page在node_mem_map的偏移。__page_to_pfn类似,大家可以自己分析。
3、Sparse Memory Model。经典算法的代码我们就不看了,一起看看配置了SPARSEMEM_VMEMMAP的代码,如下:
“
\#define __pfn_to_page(pfn) (vmemmap + (pfn)) \#define __page_to_pfn(page) (unsigned long)((page) - vmemmap)Copy after login”
简单而清晰,PFN就是vmemmap这个struct page数组的index啊。对于ARM64而言,vmemmap定义如下:
“
\#define vmemmap ((struct page *)VMEMMAP_START - \ SECTION_ALIGN_DOWN(memstart_addr >> PAGE_SHIFT))Copy after login”
毫无疑问,我们需要在虚拟地址空间中分配一段地址来安放struct page数组(该数组包含了所有物理内存跨度空间page),也就是VMEMMAP_START的定义。
总之,Linux内存模型是一个非常重要的概念,可以帮助你更好地理解Linux系统中的内存管理。如果你想了解更多关于这个概念的信息,可以查看本文提供的参考资料。
The above is the detailed content of Linux Memory Model: A Deeper Understanding of Memory Management. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



