


"Learning from history can help us understand the ups and downs." The history of human progress is a self-evolution process that constantly draws on past experience and pushes the boundaries of capabilities. We learn from past failures and correct mistakes; we learn from successful experiences to improve efficiency and effectiveness. This self-evolution runs through all aspects of life: summarizing experience to solve work problems, using patterns to predict the weather, we continue to learn and evolve from the past.
Successfully extracting knowledge from past experience and applying it to future challenges is an important milestone on the road to human evolution. So in the era of artificial intelligence, can AI agents do the same thing?
In recent years, language models such as GPT and LLaMA have demonstrated amazing capabilities in solving complex tasks. However, while they can use tools to solve specific tasks, they inherently lack insights and learnings from past successes and failures. This is like a robot that can only perform a specific task. Although it performs well in the current task, it cannot call on its past experience to help when faced with new challenges. Therefore, we need to further develop these models so that they can accumulate knowledge and experience and apply them in new situations. By introducing memory and learning mechanisms, we can make these models more comprehensive in intelligence, able to respond flexibly in different tasks and situations, and gain inspiration from past experiences. This will make language models more powerful and reliable and help advance the development of artificial intelligence.
In response to this problem, a joint team from Tsinghua University, the University of Hong Kong, Renmin University and Wall-Facing Intelligence recently proposed a brand-new self-evolution strategy for agents: Exploration- Consolidation - Exploit (Investigate-Consolidate-Exploit, ICE) . It aims to improve the adaptability and flexibility of AI agents through self-evolution across tasks. It can not only improve the efficiency and effectiveness of the agent in handling new tasks, but also significantly reduce the demand for the capabilities of the agent base model.
The emergence of this strategy has indeed opened a new chapter in the self-evolution of intelligent agents, and also marks another step forward for us to achieve fully autonomous agents.

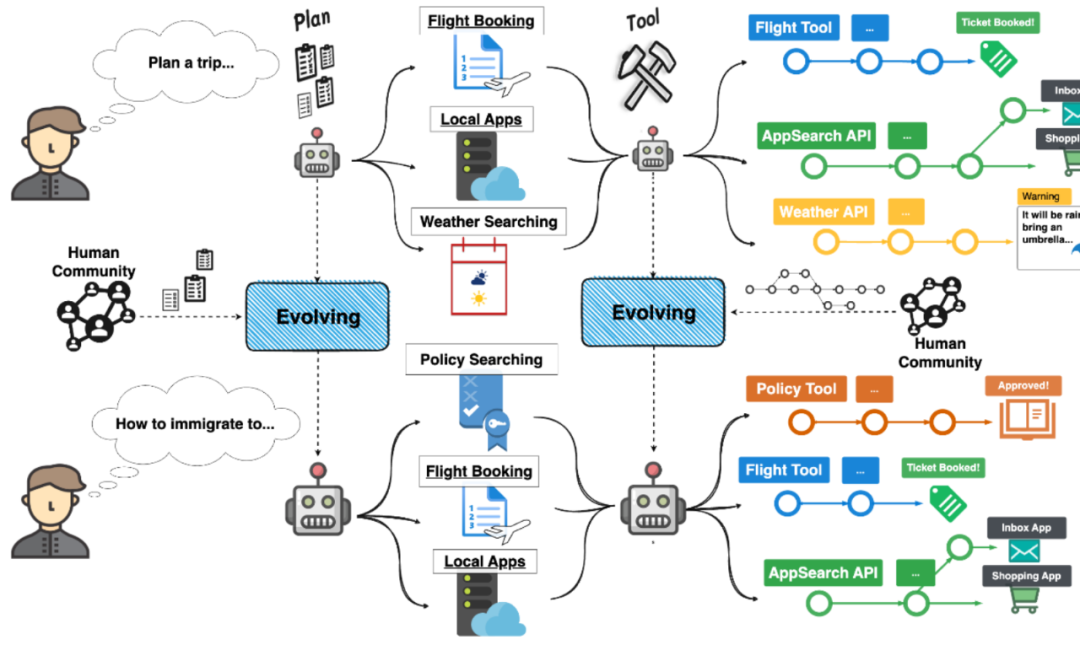 Overview of experience transfer between agent tasks to achieve self-evolution
Overview of experience transfer between agent tasks to achieve self-evolution
The current complex intelligent agents can be mainly divided into two aspects: task planning and task execution. In terms of task planning, the agent decomposes user needs and develops detailed target strategies through logical reasoning. In terms of task execution, the agent uses various tools to interact with the environment to complete the corresponding sub-goals.
In order to better promote the reuse of past experience, the author first decouples the evolutionary strategy into two aspects in this paper. Specifically, the author takes the tree task planning structure and ReACT chain tool execution in the XAgent agent architecture as examples to introduce the implementation method of the ICE strategy in detail.
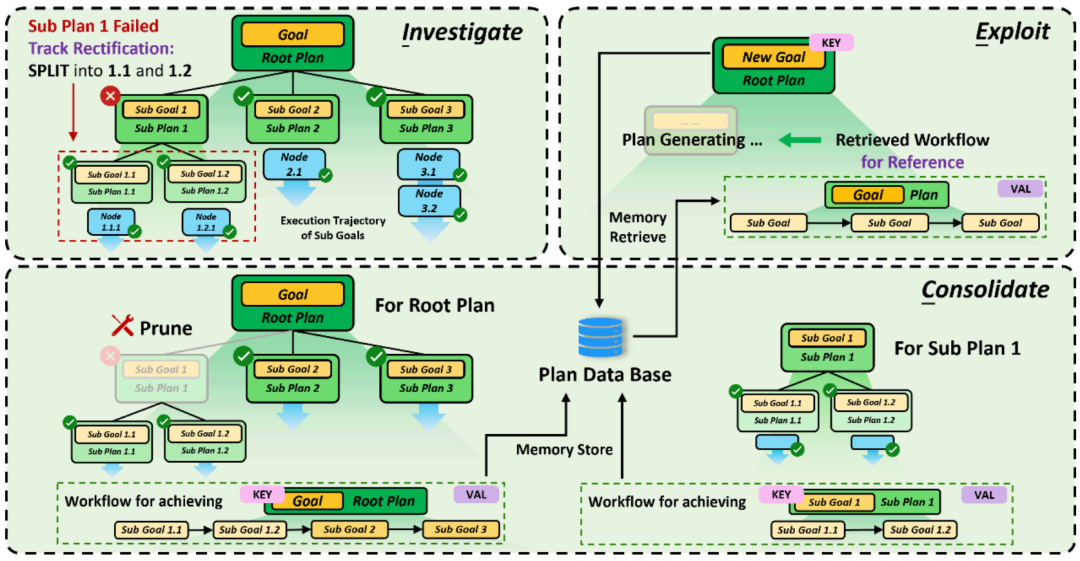 ICE self-evolution strategy for agent mission planning
ICE self-evolution strategy for agent mission planning
For mission planning, self-evolution is divided into the following three according to ICE stage:
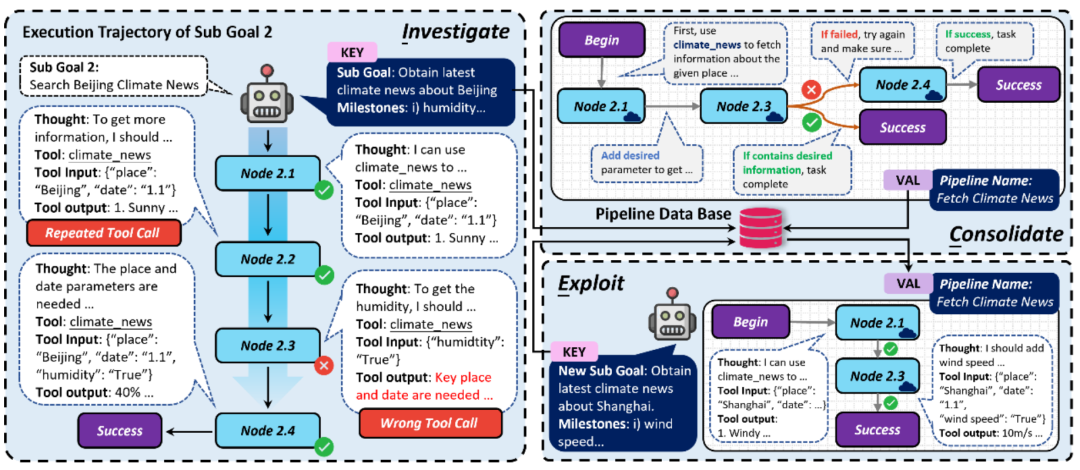 ICE self-evolution strategy for agent task execution
ICE self-evolution strategy for agent task execution
The self-evolution strategy for task execution is still divided into ICE three stages, among which:
The author tested the proposed ICE self-evolution strategy in the XAgent framework. And summarized the following four findings:
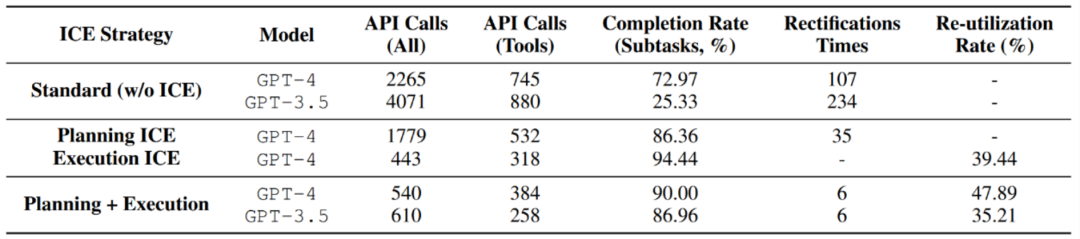 After exploring and solidifying for experience storage, the performance of the test set task under different agent ICE strategies
After exploring and solidifying for experience storage, the performance of the test set task under different agent ICE strategies
At the same time, the author also conducted additional ablation experiments: As the storage experience gradually increases, does the performance of the agent get better and better? The answer is yes. From zero experience, half experience, to full experience, the number of calls to the base model gradually decreases, while the completion of subtasks gradually increases, and the reuse rate also increases. This shows that more past experience can better promote agent execution and achieve scale effects.
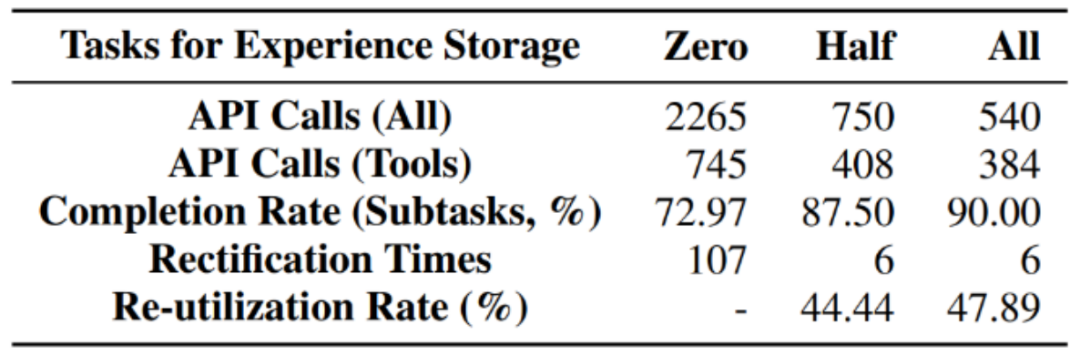 Statistics of ablation experiment results of test set task performance under different experience storage amounts
Statistics of ablation experiment results of test set task performance under different experience storage amounts
Imagine a world where everyone can deploy intelligent agents. The number of successful experiences will continue to accumulate as the individual agents perform tasks, and users can also use these experiences in the cloud or in the community. share. These experiences will prompt the intelligent agent to continuously acquire capabilities, evolve itself, and gradually achieve complete autonomy. We are one step closer to such an era.
The above is the detailed content of Taking a step closer to complete autonomy, Tsinghua University and HKU's new cross-task self-evolution strategy allows agents to learn to 'learn from experience”. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



