


In April last year, researchers from the University of Wisconsin-Madison, Microsoft Research, and Columbia University jointly released LLaVA (Large Language and Vision Assistant). Although LLaVA is only trained with a small multi-modal instruction data set, it shows very similar inference results to GPT-4 on some samples. Then in October, they launched LLaVA-1.5, which refreshed the SOTA in 11 benchmarks with simple modifications to the original LLaVA. The results of this upgrade are very exciting, bringing new breakthroughs to the field of multi-modal AI assistants.
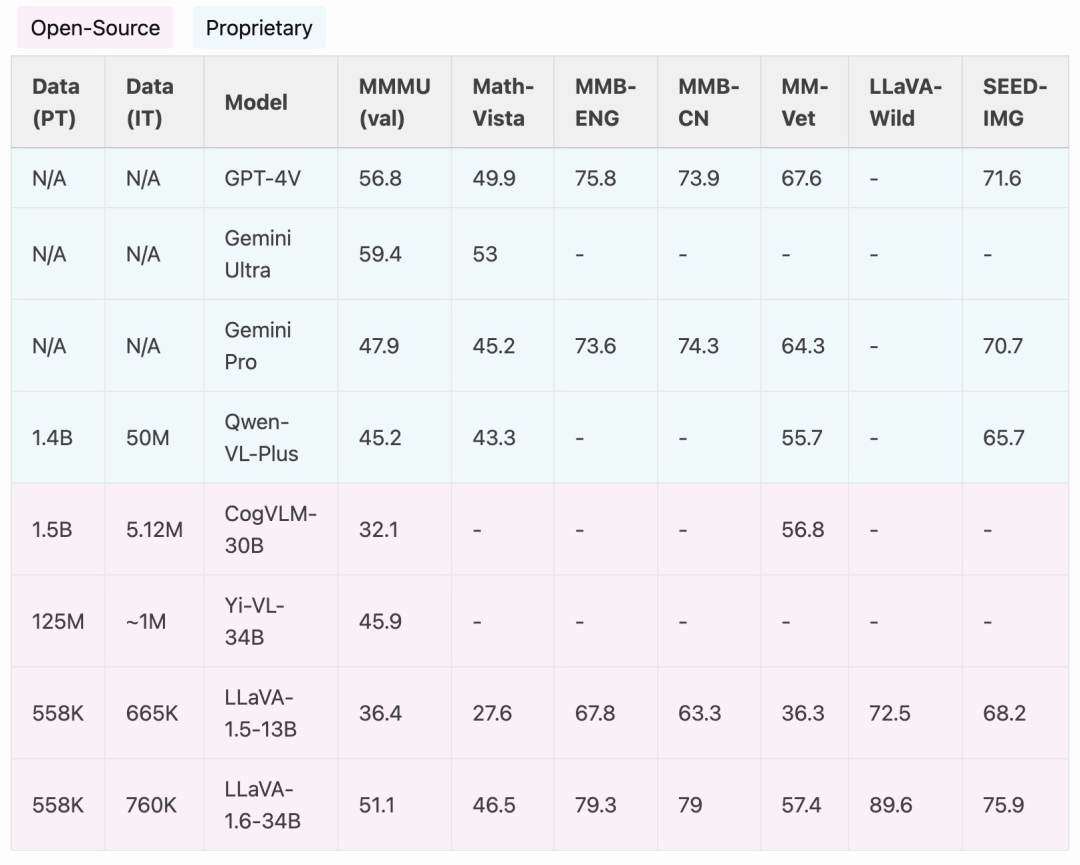
The research team announced the launch of LLaVA-1.6 version, which has made major performance improvements in reasoning, OCR and world knowledge. This version of LLaVA-1.6 even outperforms the Gemini Pro in multiple benchmarks.
Compared with LLaVA-1.5, LLaVA-1.6 has the following improvements:

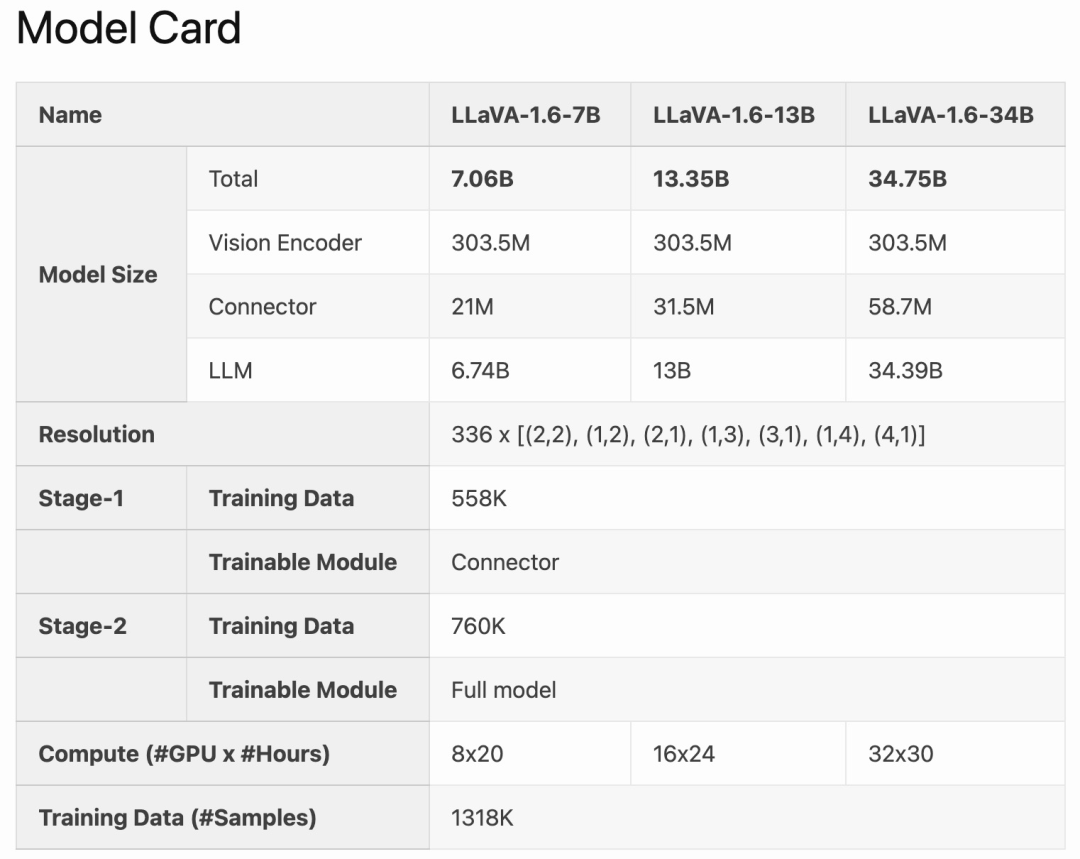
LLaVA-1.6 is fine-tuned and optimized based on LLaVA-1.5. It retains the simple design and efficient data processing capabilities of LLaVA-1.5, and continues to use less than 1M visual instruction tuning samples. By using 32 A100 graphics cards, the largest 34B model was trained in approximately 1 day. In addition, LLaVA-1.6 utilizes 1.3 million data samples, and its calculation/training data cost is only 100-1000 times that of other methods. These improvements make LLaVA-1.6 a more efficient and cost-effective version.
Method Improvement
Dynamic High Resolution
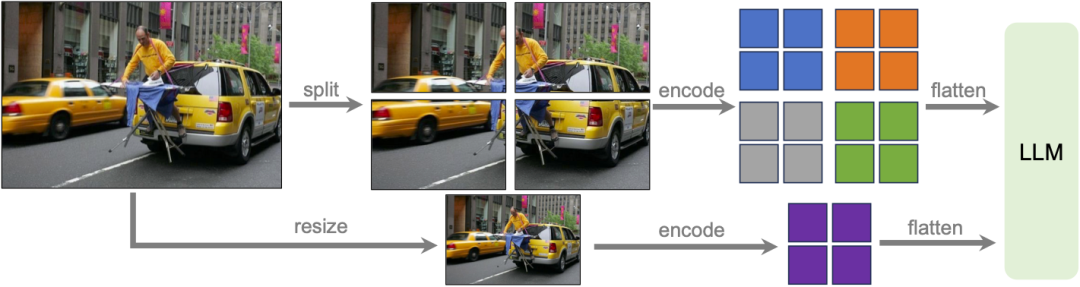
Research Team The LLaVA-1.6 model was designed at high resolution to maintain its data efficiency. When provided with high-resolution images and detail-preserving representations, the model's ability to perceive complex details in images improves significantly. It reduces model hallucination when faced with low-resolution images, i.e. guessing the imagined visual content.
Data Mixing
High quality user command data. The study’s definition of high-quality visual instruction following data depends on two main criteria: first, the diversity of task instructions, ensuring that the broad range of user intentions that may be encountered in real-life scenarios is adequately represented, especially It is during the model deployment phase. Second, prioritization of responses is critical, aiming to solicit favorable user feedback.
Therefore, the study considered two data sources:Existing GPT-V data (LAION-GPT-V and ShareGPT -4V);
In order to further promote better visual dialogue in more scenarios, the research team collected a small 15K visual instruction tuning data set covering different applications, carefully filtering samples that may have privacy issues or may be harmful, And use GPT-4V to generate the response. Multimodal document/chart data. (1) Remove TextCap from the training data because the research team realized that TextCap uses the same training image set as TextVQA. This allowed the research team to better understand the model's zero-shot OCR capabilities when evaluating TextVQA. In order to maintain and further improve the OCR capabilities of the model, this study replaced TextCap with DocVQA and SynDog-EN. (2) With Qwen-VL-7B-Chat, this study further adds ChartQA, DVQA, and AI2D for better understanding of plots and charts. The research team also stated that in addition to Vicuna-1.5 (7B and 13B), it is also considering using more LLM solutions, including Mistral-7B and Nous-Hermes-2-Yi-34B, to Enable LLaVA to support a wider range of users and more scenarios. 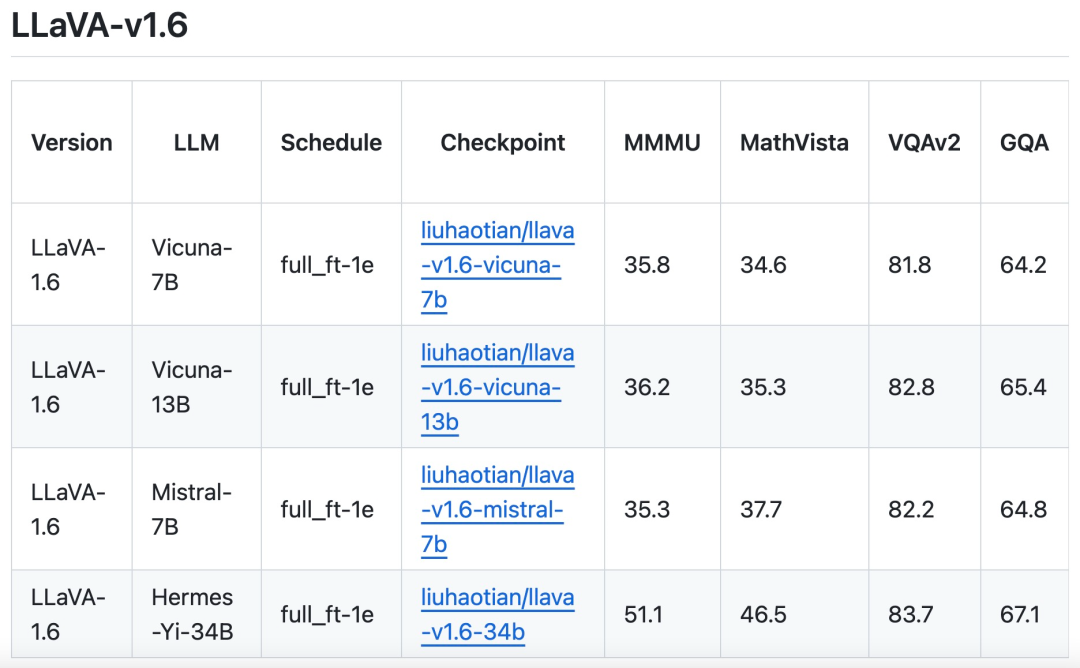
The above is the detailed content of LLaVA-1.6, which catches up with Gemini Pro and improves reasoning and OCR capabilities, is too powerful. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



