


After the emergence of large models such as GPT, the Transformer autoregressive modeling method of language model, which is the pre-training task of predicting next token, has achieved great success. So, can this autoregressive modeling method achieve better results in visual models? The article introduced today is Apple’s recent article on training a visual model based on Transformer autoregressive pre-training. Let me introduce this work to you.
 Picture
Picture
Paper title: Scalable Pre-training of Large Autoregressive Image Models
Download address: https://arxiv.org /pdf/2401.08541v1.pdf
Open source code: https://github.com/apple/ml-aim
The model structure is based on Transformer. And adopt next token prediction in the language model as the optimization goal. The main modifications are in three aspects. First of all, unlike ViT, this article uses GPT's one-way attention, that is, the element at each position only calculates attention with the previous element. Secondly, we introduce more contextual information to improve the model's language understanding capabilities. Finally, we optimized the model's parameter settings to further improve performance. With these improvements, our model achieves significant performance improvements on language tasks.
 Picture
Picture
In the Transformer model, a new mechanism is introduced, that is, multiple prefix tokens are added in front of the input sequence. These tokens use a two-way attention mechanism. The main purpose of this change is to enhance consistency between pre-training and downstream applications. In downstream tasks, bidirectional attention methods similar to ViT are widely used. By introducing prefix bidirectional attention in the pre-training process, the model can better adapt to the needs of various downstream tasks. Such improvements can improve the performance and generalization capabilities of the model.
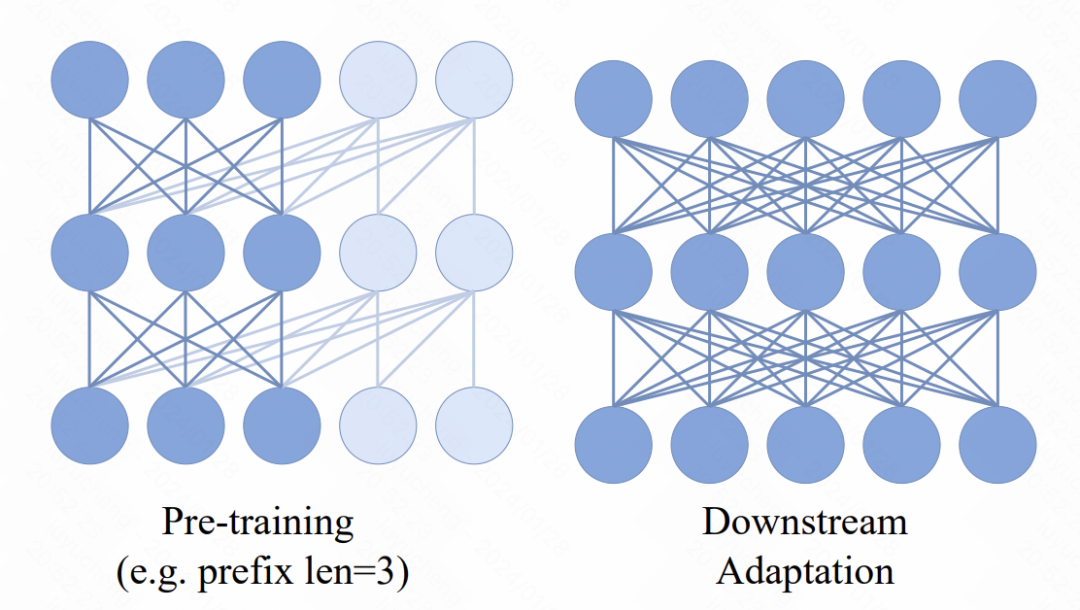 Picture
Picture
In terms of optimizing the final output MLP layer of the model, the original pre-training method usually discards the MLP layer and uses it in downstream tasks A brand new MLP. This is to prevent the pre-trained MLP from being too biased towards the pre-training task, resulting in a decrease in the effectiveness of downstream tasks. However, in this paper, the authors propose a new approach. They use an independent MLP for each patch, and also use the fusion of representation and attention of each patch to replace the traditional pooling operation. In this way, the usability of the pre-trained MLP head in downstream tasks is improved. Through this method, the authors can better retain the information of the overall image and avoid the problem of over-reliance on pre-training tasks. This is very helpful to improve the generalization ability and adaptability of the model.
Regarding the optimization goal, the article tried two methods. The first one is to directly fit the patch pixels and use MSE for prediction. The second is to tokenize the image patch in advance, convert it into a classification task, and use cross-entropy loss. However, in the subsequent ablation experiments in the article, it was found that although the second method can also allow the model to be trained normally, the effect is not as good as that based on pixel granularity MSE.
The experimental part of the article analyzes in detail the effect of this autoregressive image model and the impact of each part on the effect.
First of all, as training progresses, the downstream image classification task becomes better and better, indicating that this pre-training method can indeed learn good image representation information.
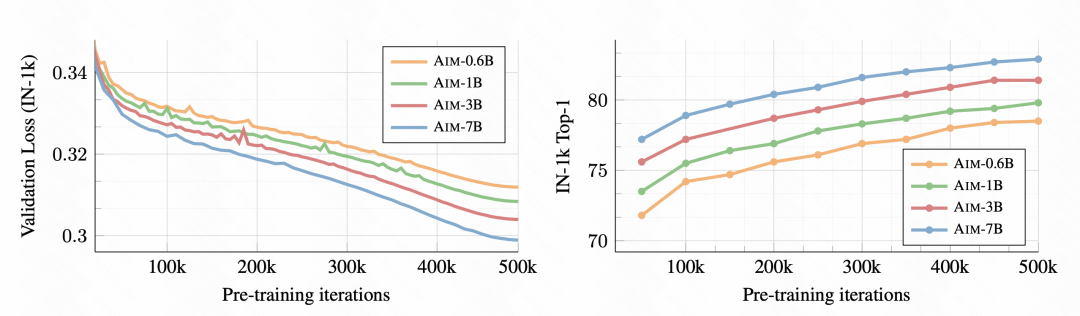 Picture
Picture
On the training data, training with a small data set will lead to overfitting, and using DFN-2B although the initial verification set loss is larger , but there is no obvious over-fitting problem.
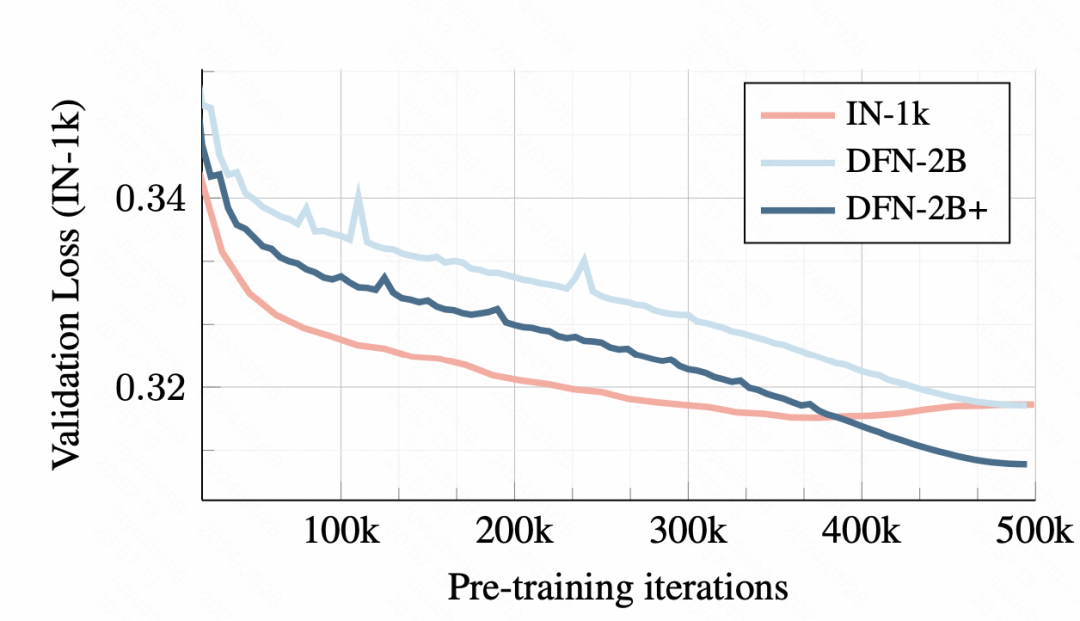 Picture
Picture
Regarding the design of each module of the model, the article also conducts a detailed ablation experiment analysis.
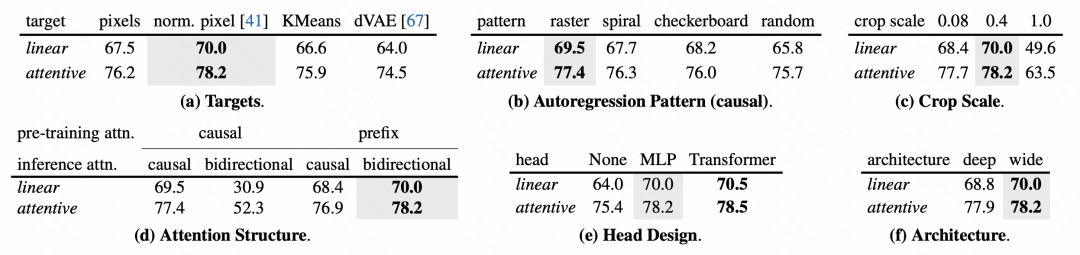 Picture
Picture
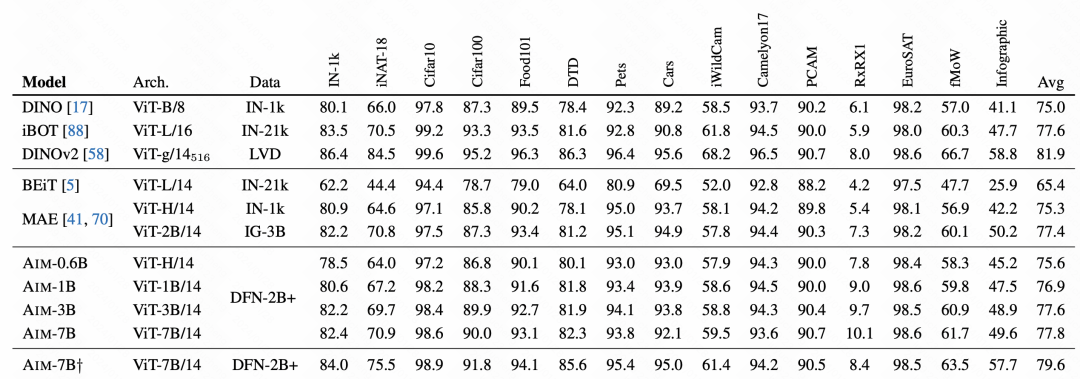
In the final effect comparison, AIM achieved very good results, which also verified that this autoregressive pre-training method is effective It is also available on images and may become a main way to pre-train large models for subsequent images.
 picture
picture
The above is the detailed content of Apple uses autoregressive language models to pre-train image models. For more information, please follow other related articles on the PHP Chinese website!
 Solution to Connection reset
Solution to Connection reset
 Which version of linux system is easy to use?
Which version of linux system is easy to use?
 Why the computer keeps restarting automatically
Why the computer keeps restarting automatically
 Can Douyin short videos be restored after being deleted?
Can Douyin short videos be restored after being deleted?
 what is world wide web
what is world wide web
 How to solve the computer prompt of insufficient memory
How to solve the computer prompt of insufficient memory
 What does the metaverse concept mean?
What does the metaverse concept mean?
 Usage of instr function in oracle
Usage of instr function in oracle








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



