


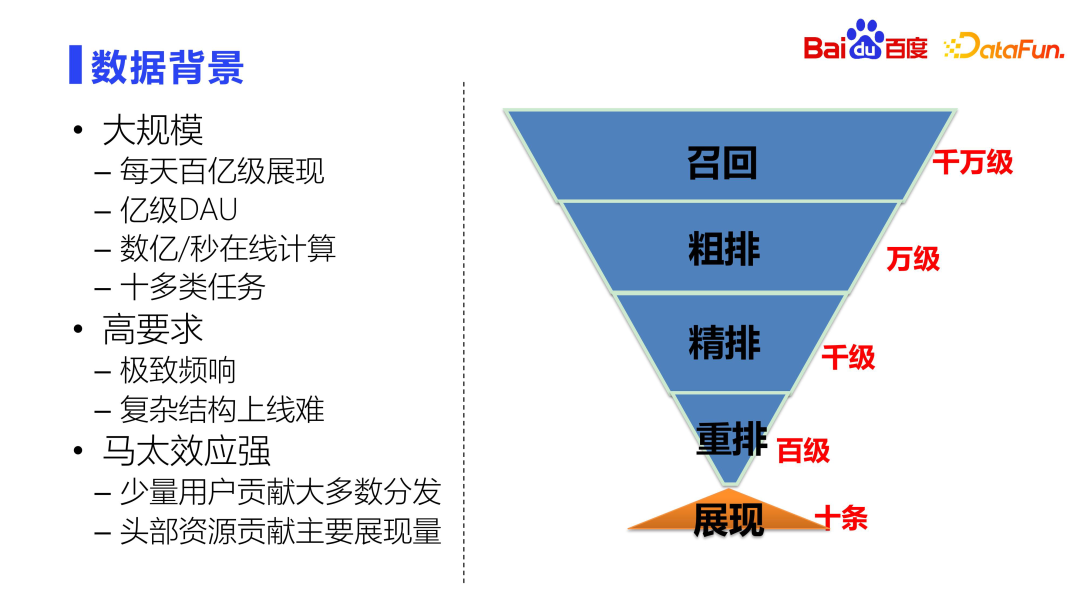
First of all, let’s introduce the business background, data background, and basic algorithm strategy of Baidu’s comprehensive information flow recommendation.

Baidu’s comprehensive information flow includes the search box in the Baidu APP The form of list page and immersion page covers a variety of product types. As you can see from the picture above, the recommended content formats include immersive recommendations similar to Douyin, as well as single-column and double-column recommendations, similar to the layout of Xiaohongshu Notes. There are also many ways for users to interact with content. They can comment, like, and collect content on the landing page. They can also enter the author page to view relevant information and interact. Users can also provide negative feedback, etc. The design of the entire comprehensive information flow is very rich and diverse, and can meet the different needs and interaction methods of users.
From a modeling perspective, we mainly face three challenges:
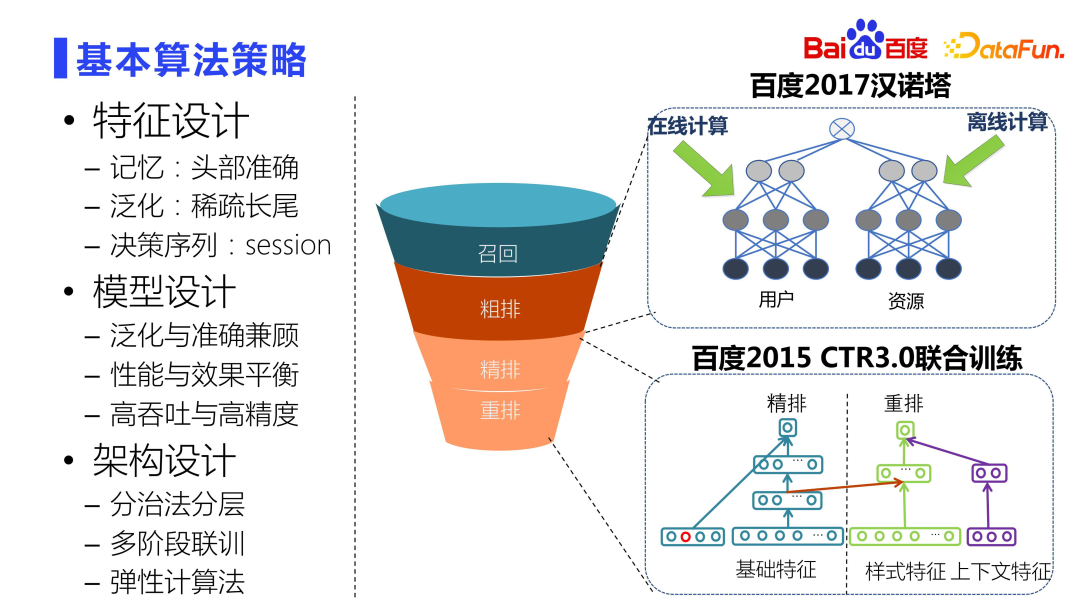
throughout the industry In search scenarios, feature design usually adopts a discretization method to ensure both memory and generalization effects. Features are converted into one-hot codes through hashing for discretization. For head users, fine characterization is required to achieve accurate memory. For the sparse long-tail users who account for a larger proportion, good generalization processing is required. In addition, session plays a very important role in the user's click and consumption decision sequence.
Model design needs to balance the data distribution of the head and long tail to ensure accuracy and generalization ability. Feature design already takes this into account, so model design also needs to take both generalization and accuracy into consideration. Baidu recommendation funnel has very strict performance requirements, so it requires joint design in architecture and strategy to find a balance between performance and effect. Additionally, there is a need to balance high throughput and accuracy of the model.
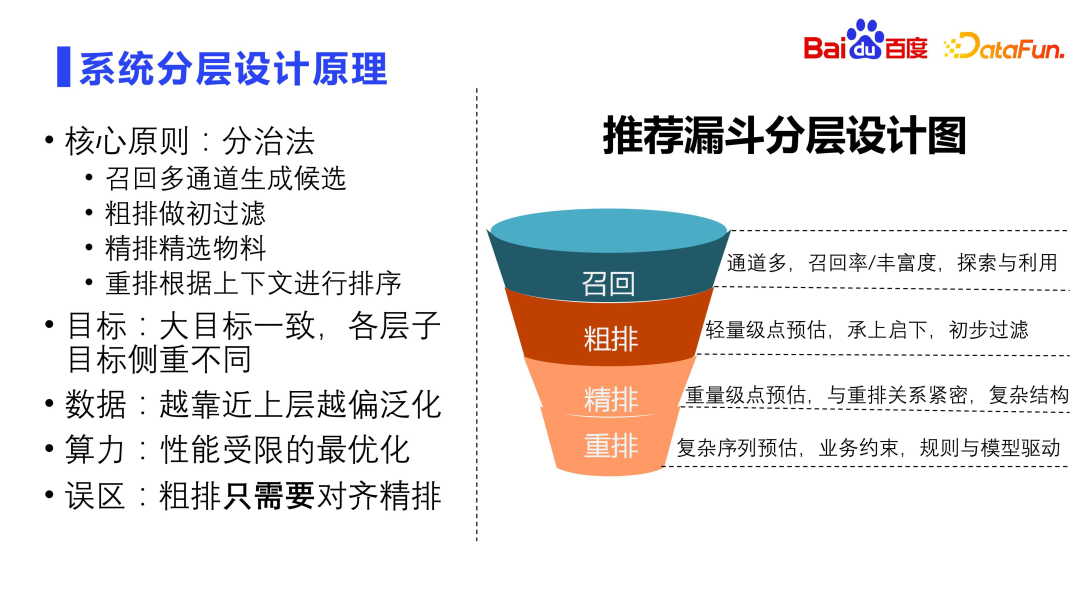
The design of the architecture needs to be comprehensively considered from two dimensions: performance and effect. One model cannot handle tens of millions of resource libraries, so it must be designed in layers. The core idea is the divide and conquer method. There is a correlation between each layer, so multi-stage joint training is required to improve the efficiency between multi-stage funnels. In addition, elastic computing methods need to be adopted to enable complex models to be launched while resources remain almost unchanged.
The Tower of Hanoi project on the right side of the picture above very cleverly implements the separation modeling of users and resources at the rough layout level. There is also CTR3.0 joint training, which realizes multi-layer and multi-stage joint training. For example, fine ranking is the most complex and exquisite model in the entire system. The accuracy is quite high. Rearrangement is based on the fine ranking. The relationship between wise modeling, fine ranking and rearrangement is very close. The joint training method we proposed based on these two models has achieved very good online results.
Next, we will further introduce it from the three perspectives of features, algorithms and architecture.
Characteristics describe the interactive decision-making process between the user and the system.
The following figure shows the user-resource-scenario-state spatio-temporal relationship interaction matrix diagram.
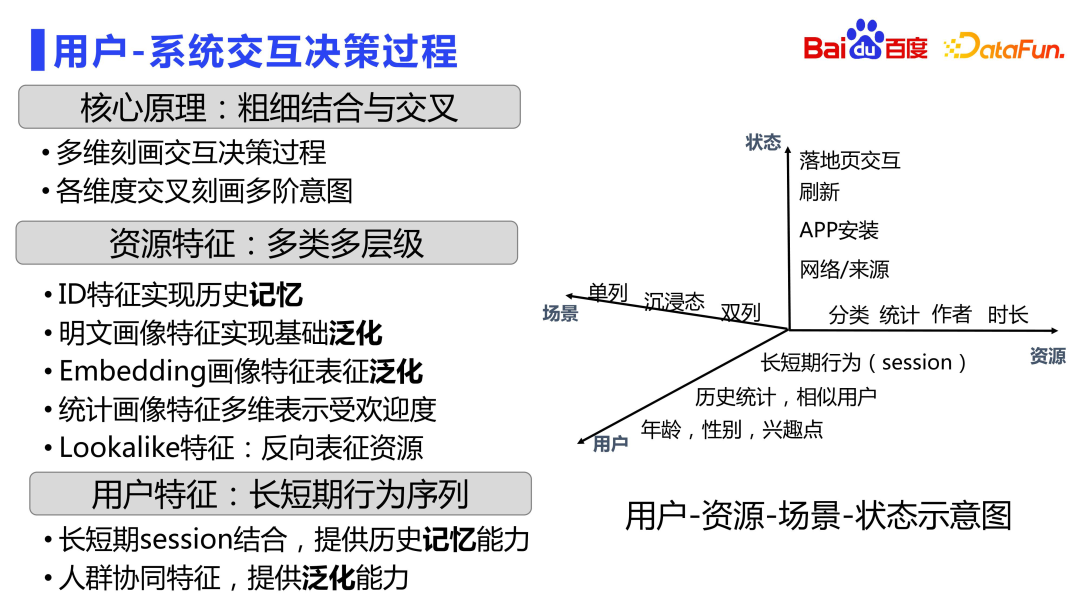
First divide all signals into the four dimensions of users, resources, scenarios and states, because essentially we need to model users and resources The relationship between. In each dimension, various portrait data can be produced.
From the user perspective, the most basic portrait of age, gender, and points of interest. On this basis, there will also be some fine-grained features, such as similar users and users’ historical preference behaviors for different resource types. Session characteristics are mainly long and short-term behavior sequences. There are many sequence models in the industry, so I won’t go into details here. But no matter what type of sequence model you make, discrete session features at the feature level are indispensable. In Baidu's search advertising, this kind of fine-grained sequence feature has been introduced more than 10 years ago, which carefully depicts users' clicking behavior, consumption behavior, etc. on different resource types in different time windows. Multiple sets of sequence features.
In the resource dimension, there will also be ID-type features to record the status of the resource itself, which is dominated by memory. There are also plaintext portrait features to achieve basic generalization capabilities. In addition to coarse-grained features, there will also be more detailed resource features, such as embedding portrait features, which are produced based on multi-modal and other pre-trained models, and more detailed modeling of the relationship between resources in discrete embedding space. There are also statistical portrait features that describe the posteriori performance of resources under various circumstances. As well as lookalike features, users can reversely characterize resources to improve accuracy.
In terms of scene dimensions, there are different scene characteristics such as single column, immersive, and double columns.
Users consume feed information differently in different states. For example, what the refresh status is, what kind of network it comes from, and what the interaction form is on the landing page, will affect the user's future decision-making, so the characteristics will also be described from the status dimension.
Comprehensively depict the decision-making process of user-system interaction through the four dimensions of user, resource, status, and scenario. In many cases, combinations between multiple dimensions are also done.
The following introduces the principle of discrete feature design.
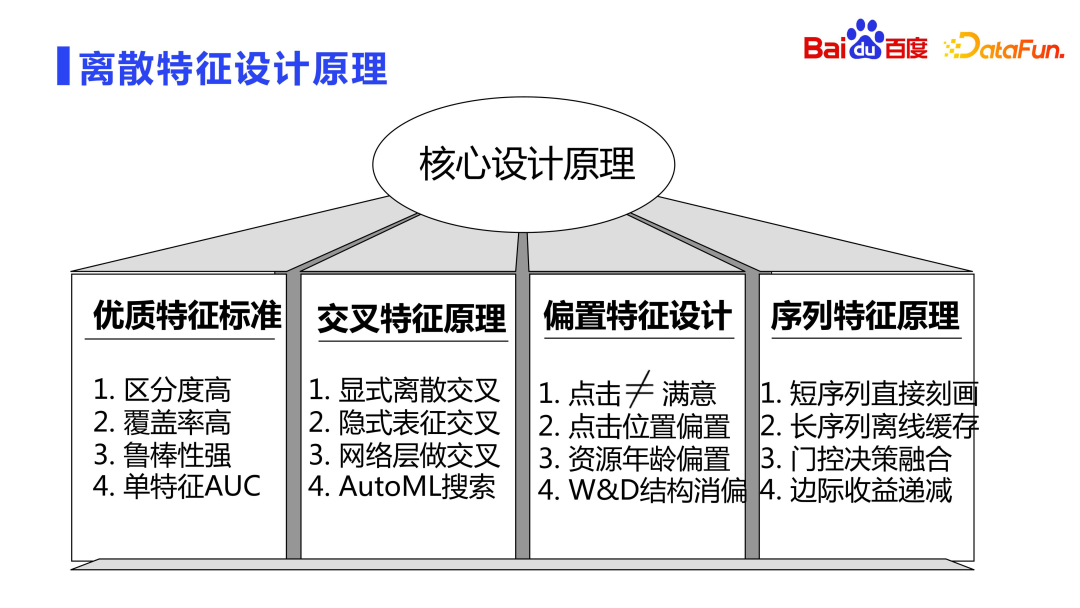
High-quality features usually have three characteristics: high discrimination, high coverage, and strong robustness.
#In addition to the above three criteria, you can also make AUC judgments on single features. For example, only use a certain feature to train the model and see the relationship between the feature and the target. You can also remove a certain feature and see the change in AUC after missing the feature.
Based on the above design principles, we will focus on three types of important features: crossover, bias and sequence features.
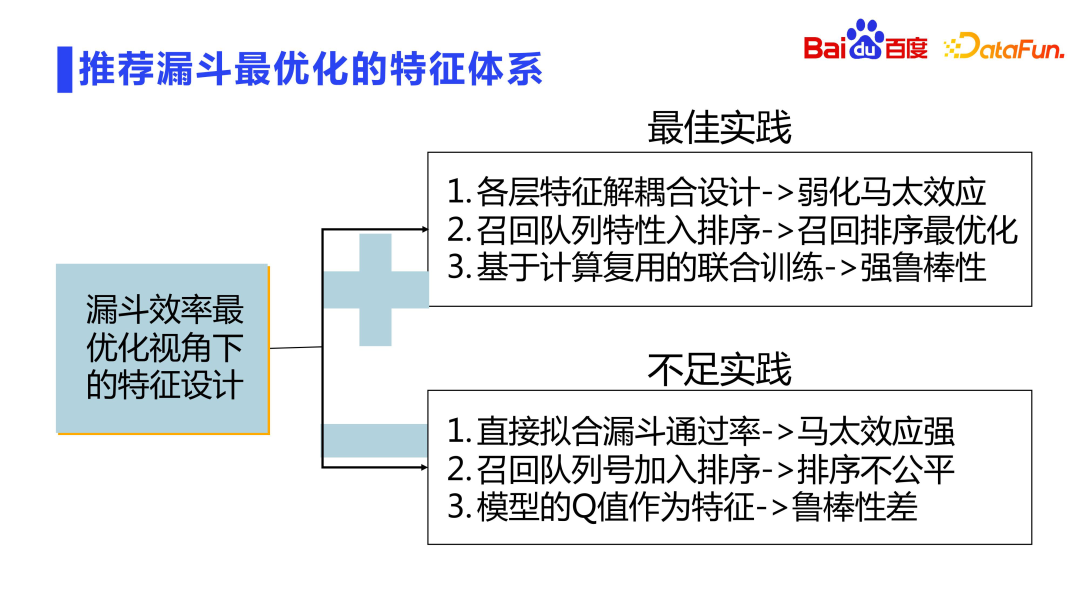
Entire recommendation The funnel is designed in layers, with filtering and truncation at each layer. How to achieve maximum efficiency in a layered design with filter truncation? As mentioned earlier, we will do joint training of models. In addition, related designs can also be done in the dimension of feature design. There are also some problems here:
The following introduces the core algorithm the design of.
First let’s look at the recommended sorting model. It is generally believed that fine ranking is the most accurate model in the recommendation system. There is a view in the industry that rough layout is attached to fine layout and can be learned from fine layout. However, in actual practice, it has been found that rough layout cannot be directly learned from fine layout, which may cause many problems.
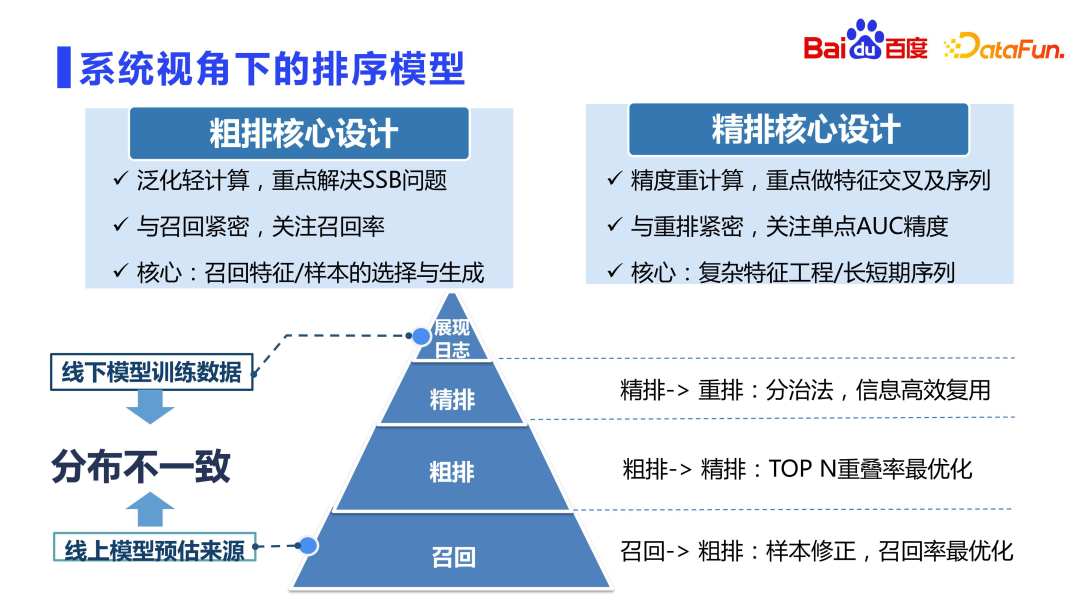
As you can see from the picture above, the positioning of rough sorting and fine sorting is different. Generally speaking, the rough sorting training samples are the same as the fine sorting samples, which are also display samples. Each time there are tens of thousands of candidates recalled for rough ranking, more than 99% of the resources are not displayed, and the model only uses a dozen or so resources that are finally displayed for training, which breaks the independence Under the assumption of identical distribution, the distribution of offline models varies greatly. This situation is most serious in recall, because the recall candidate sets are millions, tens of millions or even hundreds of millions, and most of the final returned results are not displayed. Rough sorting is also relatively serious. Because the candidate set is usually in the tens of thousands. The fine sorting is relatively better. After passing through the two-layer funnel of recall and rough sorting, the basic quality of resources is guaranteed. It mainly does the work of selecting the best from the best. Therefore, the problem of offline distribution inconsistency in fine ranking is not so serious, and there is no need to consider too much the problem of sample selection bias (SSB). At the same time, because the candidate set is small, heavy calculations can be done. Fine ranking focuses on feature intersection, sequence modeling, etc. .
However, the level of rough sorting cannot be directly learned from fine sorting, nor can it be directly recalculated similar to fine sorting, because the calculation amount is dozens of times that of fine sorting. Times, if you directly use the design idea of fine layout, the online machine will be completely unbearable, so rough layout requires a high degree of skill to balance performance and effect. It is a lightweight module. The focus of rough sorting iteration is different from fine sorting, and it mainly solves problems such as sample selection bias and recall queue optimization. Since rough sorting is closely related to recall, more attention is paid to the average quality of thousands of resources returned to fine sorting rather than the precise sorting relationship. Fine ranking is more closely related to rearrangement and focuses more on the AUC accuracy of a single point.
Therefore, in the design of rough ranking, it is more about the selection and generation of samples, and the design of generalization features and networks. The refined design can do complex multi-order intersection features, ultra-long sequence modeling, etc.
The previous introduction is at the macro level, let’s take a look at the micro level.
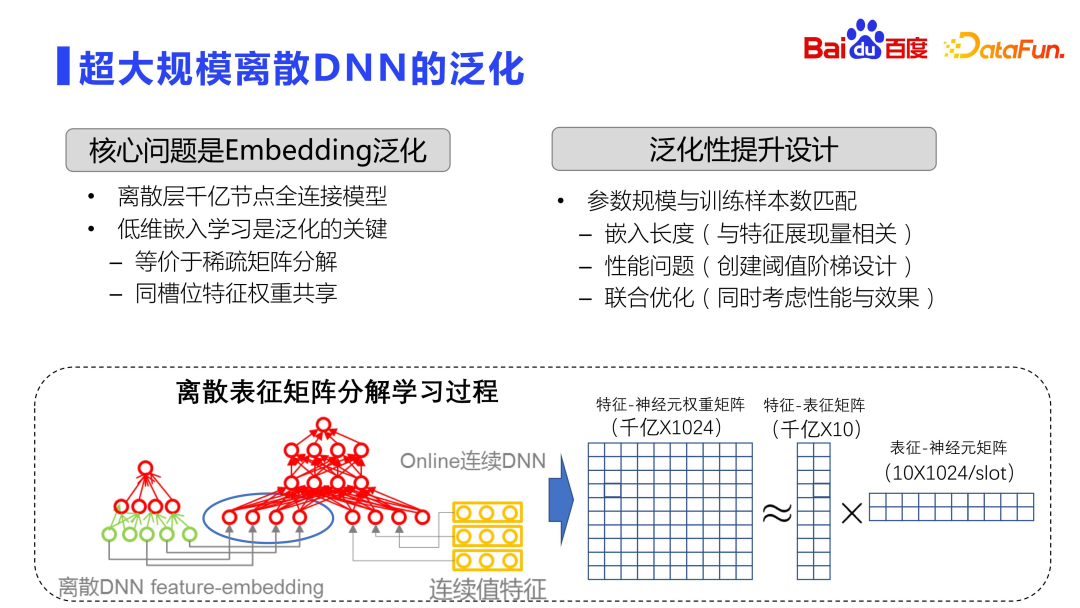
# Specific to the model training process, the current mainstream in the industry is to use ultra-large-scale discrete DNN, and the generalization problem will be more serious. Because ultra-large-scale discrete DNN, through the embedding layer, mainly performs the memory function. See the figure above. The entire embedding space is a very large matrix, usually with hundreds of billions or trillions of rows and 1,000 columns. Therefore, model training is fully distributed, with dozens or even hundreds of GPUs doing distributed training.
Theoretically, for such a large matrix, brute force calculations will not be performed directly, but operations similar to matrix decomposition will be used. Of course, this matrix decomposition is different from the standard SVD matrix decomposition. The matrix decomposition here first learns the low-dimensional representation, and reduces the amount of calculation and storage through the sharing of parameters between slots, that is, it is decomposed into two matrices. the process of learning. The first is the feature and representation matrix, which will learn the relationship between the feature and the low-dimensional embedding. This embedding is very low, and an embedding of about ten dimensions is usually selected. The other one is the embedding and neuron matrix, and the weights between each slot are shared. In this way, the storage volume is reduced and the effect is improved.
Low-dimensional embedding learning is the key to optimizing the generalization ability of offline DNN. It is equivalent to doing sparse matrix decomposition. Therefore, the key to improving the generalization ability of the entire model lies in how to make it Parameter size can be better matched with the number of samples.
Optimize from multiple aspects:
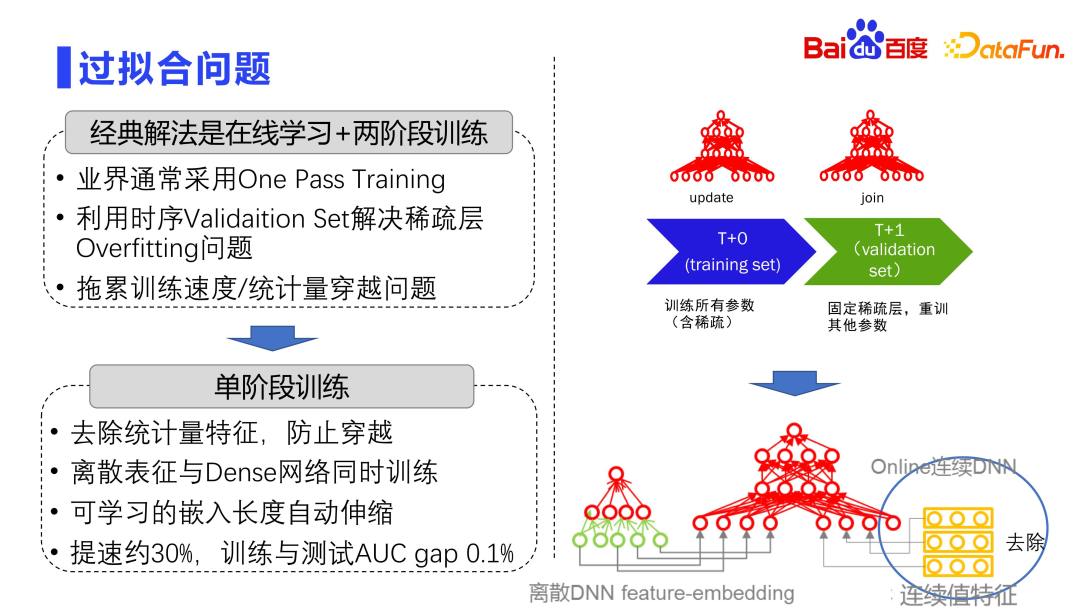
The industry usually adopts a two-stage training method to resist overfitting. The entire model consists of two layers, one is a large discrete matrix layer, and the other is a small dense parameter layer. The discrete matrix layer is very easy to overfit, so industry practice usually uses One Pass Training, that is, online learning, where all the data is passed through, and batch training is not done like in academia.
In addition, the industry usually uses timing validation set to solve the overfitting problem of sparse layers. Divide the entire training data set into many Deltas, T0, T1, T2, and T3, according to the time dimension. Each training is fixed with the discrete parameter layer trained a few hours ago, and then the next Delta data is used to finetune the dense network. That is, by fixing the sparse layer and retraining other parameters, the overfitting problem of the model can be alleviated.
This approach will also bring another problem, because the training is divided, and the discrete parameters at time T0 need to be fixed each time, and then the join is retrained at time t 1 stage, this will slow down the entire training speed and bring scalability challenges. Therefore, in recent years, single-stage training has been adopted, that is, the discrete representation layer and the dense network layer are updated simultaneously in a Delta. There is also a problem with single-stage training, because in addition to embedding features, the entire model also has many continuous-valued features. These continuous-valued features will count the display clicks of each discrete feature. Therefore, it may bring the risk of data crossing. Therefore, in actual practice, the first step will be to remove the characteristics of the statistics, and the second step will be to train the dense network together with the discrete representation, using a single-stage training method. In addition, the entire embedded length is automatically scalable. Through this series of methods, model training can be accelerated by about 30%. Practice shows that the degree of overfitting of this method is very slight, and the difference between the AUC of training and testing is 1/1000 or lower.
Next, we will introduce the architecture design thoughts and experiences.
effect. Because fine ranking is not the ground truth, user behavior is. You need to learn user behavior well, not learn fine ranking. This is a very important tip.
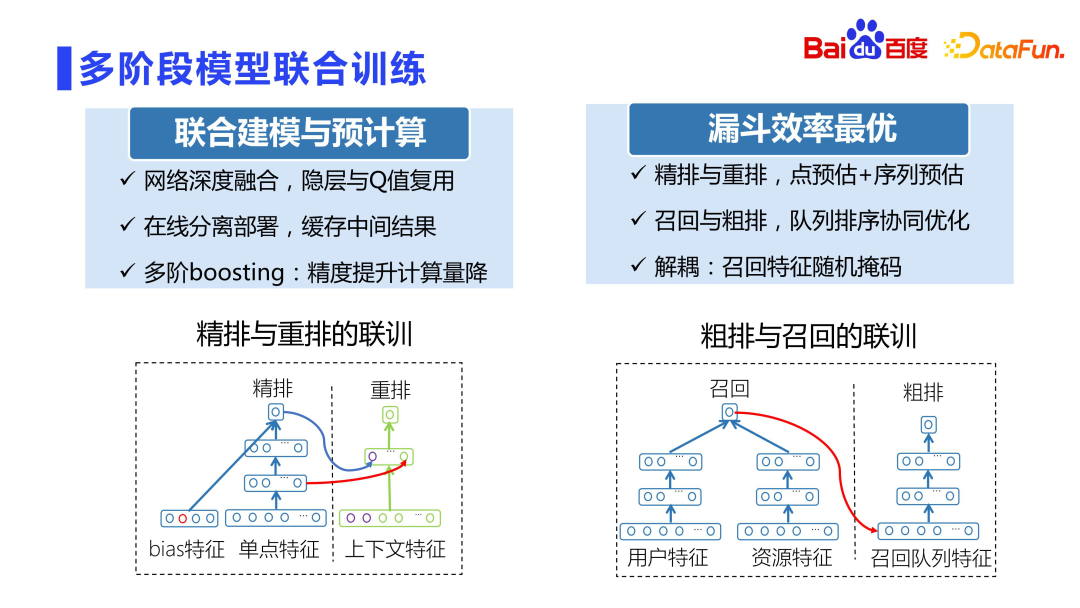
#The relationship between fine ranking and rearrangement is It is very close. In the early years, rearrangements were directly trained using the scores of fine lineups. On the one hand, the coupling was very serious. On the other hand, the scores of fine lineups were directly used for training, which easily caused online fluctuations.
Baidu Fengchao CTR 3.0 joint training project of fine ranking and rearrangement very cleverly uses models to train at the same time to avoid the problem of scoring coupling. This project uses the hidden layer and internal scoring of the fine-ranking sub-network as characteristics of the rearrangement sub-network. Then, the fine-ranking and rearrangement sub-networks are separated and deployed in their respective modules. On the one hand, the intermediate results can be reused well without the fluctuation problem caused by scoring coupling. At the same time, the accuracy of rearrangement will be improved by a percentile. This was also one of the sub-projects that received Baidu’s highest award that year.
In addition, please note that this project is not ESSM. ESSM is CTCVR modeling and multi-objective modeling. CTR3.0 joint training mainly solves the problems of scoring coupling and rearrangement model accuracy. .
In addition, recall and rough sorting must be decoupled, because new queues are added, which may not be fair to the new queues. Therefore, a random masking method is proposed, that is, randomly masking out some features so that the coupling degree is not so strong.
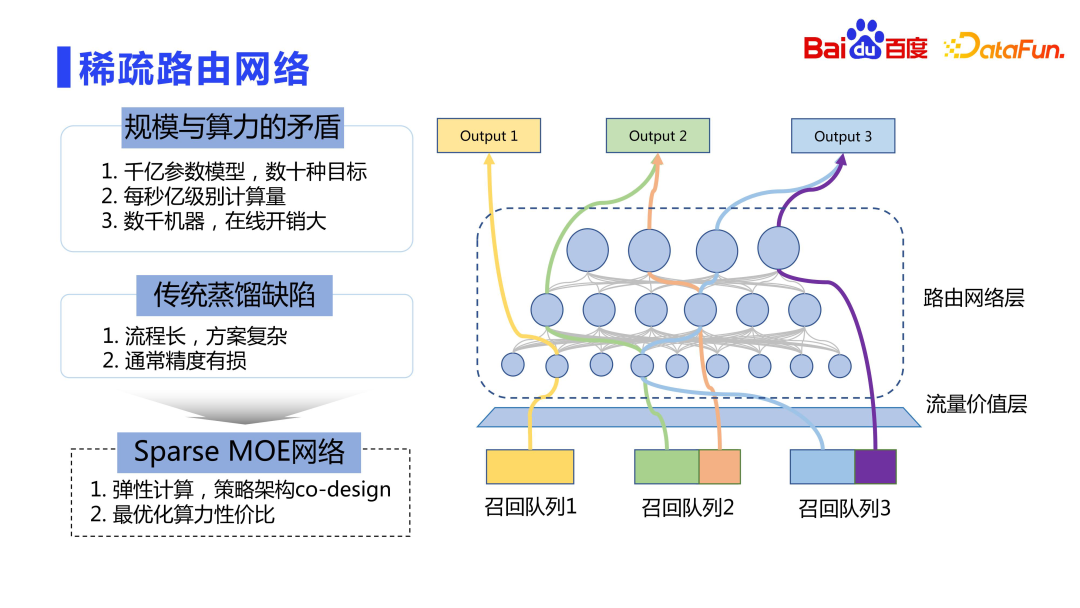
Finally, let’s take a look at the online deployment process. The scale of model parameters is in the order of hundreds of billions to trillions, and there are many targets. Direct online deployment is very expensive, and we cannot only consider the effect without considering the performance. A better way is elastic calculation, similar to the idea of Sparse MOE.
Rough sorting has access to a lot of queues, with dozens or even hundreds of queues. The online value (LTV) of these queues is different. The traffic value layer calculates the value of different recall queues to online click duration. The core idea is that the greater the overall contribution of the recall queue, the more complex calculations can be enjoyed. This allows limited computing power to serve higher value traffic. Therefore, we did not use the traditional distillation method, but adopted an idea similar to Sparse MOE for elastic computing, that is, the design of strategy and architecture co-design, so that different recall queues can use the most suitable resource network for calculation.
As we all know, now Entering the era of LLM large models. Baidu's exploration of the next generation recommendation system based on LLM large language model will be carried out from three aspects.

The first aspect is to upgrade the model from basic prediction to being able to make decisions. For example, important issues such as efficient exploration of classic cold start resources, immersive sequence recommendation feedback, and the decision-making chain from search to recommendation can all be made with the help of large models.
The second aspect is from discrimination to generation. Now the entire model is discriminative. In the future, we will explore generative recommendation methods, such as automatically generating recommendation reasons, and based on long-tail data prompt for automatic data enhancement and generative retrieval model.
The third aspect is from black box to white box. In the traditional recommendation system, people often say that neural network is an alchemy and a black box. Is it possible to move towards white box? Exploration is also one of the important tasks in the future. For example, based on cause and effect, we can explore the reasons behind user behavior state transitions, make better unbiased estimates of recommendation fairness, and perform better scene adaptation in Multi Task Machine Learning scenarios.
The above is the detailed content of Exploration and application of Baidu sorting technology. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



