


We will discuss ways to build a retrieval-augmented generation (RAG) system using the open source Large Language Multi-Modal. Our focus is to achieve this without relying on LangChain or LLlama index to avoid adding more framework dependencies.

In the field of artificial intelligence, retrieval-augmented generation, The emergence of RAG technology has brought revolutionary improvements to large language models (Large Language Models). The essence of RAG is to enhance the responsiveness of artificial intelligence by allowing models to dynamically retrieve real-time information from external sources. The introduction of this technology enables AI to respond to user needs more specifically. By retrieving and fusing information from external sources, RAG is able to generate more accurate and comprehensive answers, providing users with more valuable content. This improvement in capabilities has brought broader prospects to the application fields of artificial intelligence, including intelligent customer service, intelligent search and knowledge question and answer systems. The emergence of RAG marks the further development of language models, bringing artificial intelligence
This architecture seamlessly combines the dynamic retrieval process with generation capabilities, enabling artificial intelligence to adapt to various fields constantly changing information. Unlike fine-tuning and retraining, RAG provides a cost-effective solution that allows AI to obtain the latest and relevant information without changing the entire model. This combination of capabilities gives RAG an advantage in responding to rapidly changing information environments.
1. Improve accuracy and reliability:
By Large Language Models (LLMs) direct to reliable sources of knowledge, solving the problem of its unpredictability and reducing the risk of providing false or outdated information, making responses more accurate and reliable.
2. Increase transparency and trust:
Generative AI models like LLM often lack transparency, which makes it difficult for people to trust them. output. RAG addresses concerns about bias, reliability and compliance by providing greater control.
3. Reduce hallucinations:
LLM is prone to hallucinatory reactions - providing coherent but inaccurate or fabricated information. RAG reduces the risk of misleading advice to key sectors by relying on authoritative sources to ensure responsiveness.
4. Cost-effective adaptability:
RAG provides a cost-effective way to improve AI output without the need for Extensive retraining/fine-tuning. Information can be kept up-to-date and relevant by dynamically retrieving specific details as needed, ensuring the adaptability of AI to changing information.
Multimodal involves having multiple inputs and combining them into a single output, taking CLIP as an example : The training data of CLIP is text-image pairs. Through comparative learning, the model can learn the matching relationship of text-image pairs.
This model generates the same (very similar) embedding vectors for different inputs that represent the same thing.
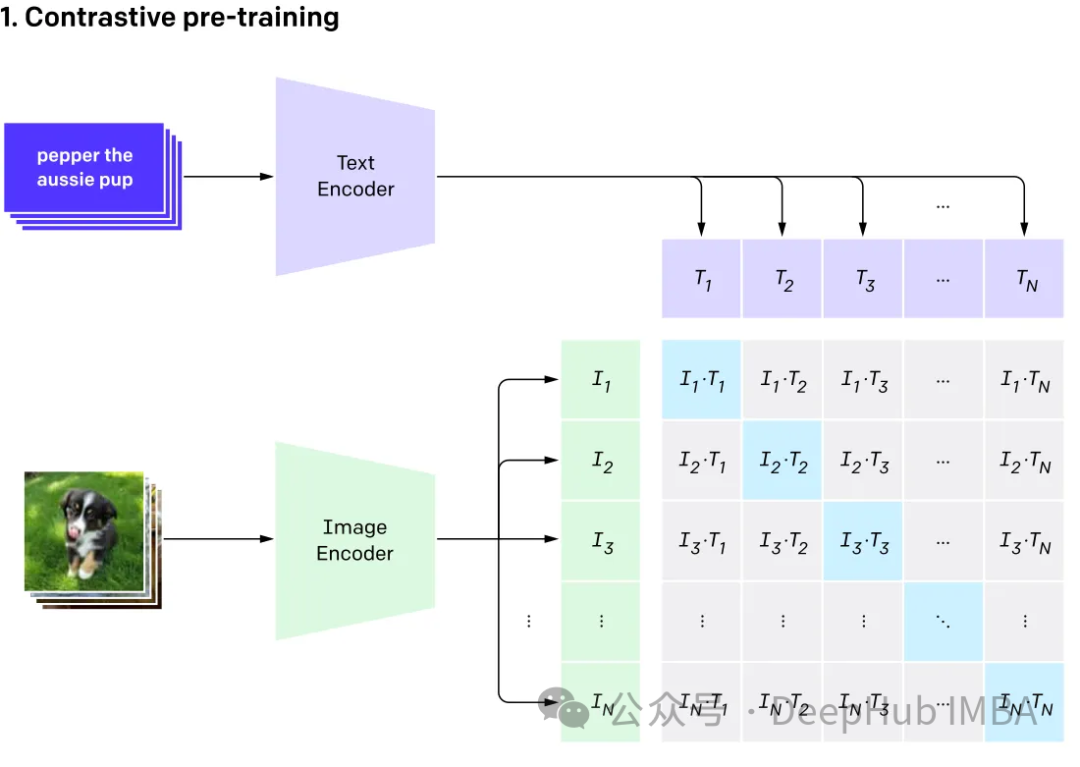
GPT4v and Gemini vision explore multi-modal large language that integrates various data types (including images, text, language, audio, etc.) Modal Language Model (MLLM). While large language models (LLMs) like GPT-3, BERT, and RoBERTa perform well on text-based tasks, they face challenges in understanding and processing other data types. To address this limitation, multimodal models combine different modalities to enable a more comprehensive understanding of different data.
Multimodal large language model It goes beyond traditional text-based methods. Taking GPT-4 as an example, these models can seamlessly process various data types, including images and text, to understand the information more comprehensively.
Here we will use Clip to embed images and text, storing these embeds in the ChromDB vector database. The large model will then be leveraged to engage in user chat sessions based on the retrieved information.
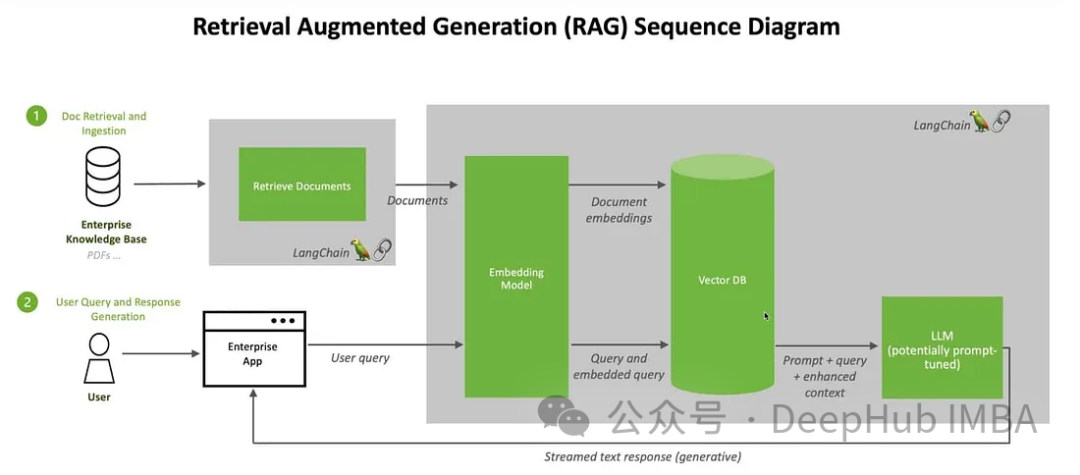
We will use images from Kaggle and information from Wikipedia to create a flower expert chatbot
First we install the software package:
! pip install -q timm einops wikipedia chromadb open_clip_torch !pip install -q transformers==4.36.0 !pip install -q bitsandbytes==0.41.3 accelerate==0.25.0
The steps to preprocess the data are very simple. Just put the images and text in a folder
可以随意使用任何矢量数据库,这里我们使用ChromaDB。
import chromadb from chromadb.utils.embedding_functions import OpenCLIPEmbeddingFunction from chromadb.utils.data_loaders import ImageLoader from chromadb.config import Settings client = chromadb.PersistentClient(path="DB") embedding_function = OpenCLIPEmbeddingFunction() image_loader = ImageLoader() # must be if you reads from URIs
ChromaDB需要自定义嵌入函数
from chromadb import Documents, EmbeddingFunction, Embeddings class MyEmbeddingFunction(EmbeddingFunction):def __call__(self, input: Documents) -> Embeddings:# embed the documents somehow or imagesreturn embeddings
这里将创建2个集合,一个用于文本,另一个用于图像
collection_images = client.create_collection(name='multimodal_collection_images', embedding_functinotallow=embedding_function, data_loader=image_loader) collection_text = client.create_collection(name='multimodal_collection_text', embedding_functinotallow=embedding_function, ) # Get the Images IMAGE_FOLDER = '/kaggle/working/all_data' image_uris = sorted([os.path.join(IMAGE_FOLDER, image_name) for image_name in os.listdir(IMAGE_FOLDER) if not image_name.endswith('.txt')]) ids = [str(i) for i in range(len(image_uris))] collection_images.add(ids=ids, uris=image_uris) #now we have the images collection对于Clip,我们可以像这样使用文本检索图像
from matplotlib import pyplot as plt retrieved = collection_images.query(query_texts=["tulip"], include=['data'], n_results=3) for img in retrieved['data'][0]:plt.imshow(img)plt.axis("off")plt.show()
也可以使用图像检索相关的图像

文本集合如下所示
# now the text DB from chromadb.utils import embedding_functions default_ef = embedding_functions.DefaultEmbeddingFunction() text_pth = sorted([os.path.join(IMAGE_FOLDER, image_name) for image_name in os.listdir(IMAGE_FOLDER) if image_name.endswith('.txt')]) list_of_text = [] for text in text_pth:with open(text, 'r') as f:text = f.read()list_of_text.append(text) ids_txt_list = ['id'+str(i) for i in range(len(list_of_text))] ids_txt_list collection_text.add(documents = list_of_text,ids =ids_txt_list )然后使用上面的文本集合获取嵌入
results = collection_text.query(query_texts=["What is the bellflower?"],n_results=1 ) results
结果如下:
{'ids': [['id0']],'distances': [[0.6072186183744086]],'metadatas': [[None]],'embeddings': None,'documents': [['Campanula () is the type genus of the Campanulaceae family of flowering plants. Campanula are commonly known as bellflowers and take both their common and scientific names from the bell-shaped flowers—campanula is Latin for "little bell".\nThe genus includes over 500 species and several subspecies, distributed across the temperate and subtropical regions of the Northern Hemisphere, with centers of diversity in the Mediterranean region, Balkans, Caucasus and mountains of western Asia. The range also extends into mountains in tropical regions of Asia and Africa.\nThe species include annual, biennial and perennial plants, and vary in habit from dwarf arctic and alpine species under 5 cm high, to large temperate grassland and woodland species growing to 2 metres (6 ft 7 in) tall.']],'uris': None,'data': None}或使用图片获取文本
query_image = '/kaggle/input/flowers/flowers/rose/00f6e89a2f949f8165d5222955a5a37d.jpg' raw_image = Image.open(query_image) doc = collection_text.query(query_embeddings=embedding_function(query_image), n_results=1, )['documents'][0][0]

上图的结果如下:
A rose is either a woody perennial flowering plant of the genus Rosa (), in the family Rosaceae (), or the flower it bears. There are over three hundred species and tens of thousands of cultivars. They form a group of plants that can be erect shrubs, climbing, or trailing, with stems that are often armed with sharp prickles. Their flowers vary in size and shape and are usually large and showy, in colours ranging from white through yellows and reds. Most species are native to Asia, with smaller numbers native to Europe, North America, and northwestern Africa. Species, cultivars and hybrids are all widely grown for their beauty and often are fragrant. Roses have acquired cultural significance in many societies. Rose plants range in size from compact, miniature roses, to climbers that can reach seven meters in height. Different species hybridize easily, and this has been used in the development of the wide range of garden roses.
这样我们就完成了文本和图像的匹配工作,其实这里都是CLIP的工作,下面我们开始加入LLM。
from huggingface_hub import hf_hub_download hf_hub_download(repo_, filename="configuration_llava.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="configuration_phi.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="modeling_llava.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="modeling_phi.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="processing_llava.py", local_dir="./", force_download=True)
我们是用visheratin/LLaVA-3b
from modeling_llava import LlavaForConditionalGeneration import torch model = LlavaForConditionalGeneration.from_pretrained("visheratin/LLaVA-3b") model = model.to("cuda")加载tokenizer
from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("visheratin/LLaVA-3b")然后定义处理器,方便我们以后调用
from processing_llava import LlavaProcessor, OpenCLIPImageProcessor image_processor = OpenCLIPImageProcessor(model.config.preprocess_config) processor = LlavaProcessor(image_processor, tokenizer)
下面就可以直接使用了
question = 'Answer with organized answers: What type of rose is in the picture? Mention some of its characteristics and how to take care of it ?' query_image = '/kaggle/input/flowers/flowers/rose/00f6e89a2f949f8165d5222955a5a37d.jpg' raw_image = Image.open(query_image) doc = collection_text.query(query_embeddings=embedding_function(query_image), n_results=1, )['documents'][0][0] plt.imshow(raw_image) plt.show() imgs = collection_images.query(query_uris=query_image, include=['data'], n_results=3) for img in imgs['data'][0][1:]:plt.imshow(img)plt.axis("off")plt.show()得到的结果如下:

结果还包含了我们需要的大部分信息

这样我们整合就完成了,最后就是创建聊天模板,
prompt = """system A chat between a curious human and an artificial intelligence assistant. The assistant is an exprt in flowers , and gives helpful, detailed, and polite answers to the human's questions. The assistant does not hallucinate and pays very close attention to the details. user <image> {question} Use the following article as an answer source. Do not write outside its scope unless you find your answer better {article} if you thin your answer is better add it after document. assistant """.format(questinotallow='question', article=doc)</image>如何创建聊天过程我们这里就不详细介绍了,完整代码在这里:
//m.sbmmt.com/link/71eee742e4c6e094e6af364597af3f05
The above is the detailed content of Methods for building multimodal RAG systems: using CLIP and LLM. For more information, please follow other related articles on the PHP Chinese website!
 Application of artificial intelligence in life
Application of artificial intelligence in life
 What is the basic concept of artificial intelligence
What is the basic concept of artificial intelligence
 The difference between JD.com's self-operated flagship store and its official flagship store
The difference between JD.com's self-operated flagship store and its official flagship store
 How to format hard drive in linux
How to format hard drive in linux
 How to open eml file
How to open eml file
 Why does localstorage expire so quickly?
Why does localstorage expire so quickly?
 if what does it mean
if what does it mean
 Ripple currency market trend
Ripple currency market trend





















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



