


In this NeurIPS23 paper, researchers from the University of Leuven, the National University of Singapore, and the Institute of Automation of the Chinese Academy of Sciences proposed a visual "brain reading technology" that can learn from human brain activity. High resolution resolution of the image seen by the human eye.
In the field of cognitive neuroscience, people realize that human perception is not only affected by objective stimuli, but also deeply affected by past experiences. These factors work together to create complex activity in the brain. Therefore, decoding visual information from brain activity becomes an important task. Among them, functional magnetic resonance imaging (fMRI), as an efficient non-invasive technology, plays a key role in recovering and analyzing visual information, especially image categories
However, due to the noise of fMRI signals Due to the complexity of the characteristics and visual representation of the brain, this task faces considerable challenges. To address this problem, this paper proposes a two-stage fMRI representation learning framework, which aims to identify and remove noise in brain activity, and focuses on parsing neural activation patterns that are crucial for visual reconstruction, successfully reconstructing high-level images from brain activity. resolution and semantically accurate images.

Paper link: https://arxiv.org/abs/2305.17214
Project link: https://github.com/soinx0629/vis_dec_neurips/
The method proposed in the paper is based on dual contrast learning, cross-modal information intersection and diffusion models. It has achieved nearly 40% improvement in evaluation indicators on relevant fMRI data sets compared to the previous best models. In generating images Compared with existing methods, the quality, readability and semantic relevance have been improved perceptibly by the naked eye. This work helps to understand the visual perception mechanism of the human brain and is beneficial to promoting research on visual brain-computer interface technology. The relevant codes have been open source.
Although functional magnetic resonance imaging (fMRI) is widely used to analyze neural responses, accurately reconstructing visual images from its data remains challenging, mainly because fMRI data contain noise from multiple sources, which may obscure Neural activation mode, increasing the difficulty of decoding. In addition, the neural response process triggered by visual stimulation is complex and multi-stage, making the fMRI signal present a nonlinear complex superposition that is difficult to reverse and decode.
Traditional neural decoding methods, such as ridge regression, although used to associate fMRI signals with corresponding stimuli, often fail to effectively capture the nonlinear relationship between stimuli and neural responses. Recently, deep learning techniques, such as generative adversarial networks (GANs) and latent diffusion models (LDMs), have been adopted to model this complex relationship more accurately. However, isolating vision-related brain activity from noise and accurately decoding it remains one of the main challenges in the field.
To address these challenges, this work proposes a two-stage fMRI representation learning framework, which can effectively identify and remove noise in brain activities and focus on parsing neural activation patterns that are critical for visual reconstruction. . This method generates high-resolution and semantically accurate images with a Top-1 accuracy of 39.34% for 50 categories, exceeding the existing state-of-the-art technology.
A method overview is a brief description of a series of steps or processes. It is used to explain how to achieve a specific goal or complete a specific task. The purpose of a method overview is to provide the reader or user with an overall understanding of the entire process so that they can better understand and follow the steps within it. In a method overview, you usually include the sequence of steps, materials or tools needed, and problems or challenges that may be encountered. By describing the method overview clearly and concisely, the reader or user can more easily understand and successfully complete the required task
fMRI Representation Learning (FRL)

First stage: Pre-training dual contrast mask autoencoder (DC-MAE)
In order to distinguish shared brain activity patterns and individual noise among different groups of people, this paper introduces DC-MAE technology to pre-train fMRI representations using unlabeled data. DC-MAE consists of an encoder  and a decoder
and a decoder  , where
, where  takes the masked fMRI signal as input and
takes the masked fMRI signal as input and  is trained to predict the unmasked fMRI signal. The so-called “double contrast” means that the model optimizes the contrast loss in fMRI representation learning and participates in two different contrast processes.
is trained to predict the unmasked fMRI signal. The so-called “double contrast” means that the model optimizes the contrast loss in fMRI representation learning and participates in two different contrast processes.
In the first stage of contrastive learning, the samples  in each batch containing n fMRI samples v are randomly masked twice, generating two different masked versions
in each batch containing n fMRI samples v are randomly masked twice, generating two different masked versions  and
and 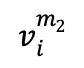 , as a positive sample pair for comparison. Subsequently, 1D convolutional layers convert these two versions into embedded representations, which are fed into the fMRI encoder respectively. The decoder
, as a positive sample pair for comparison. Subsequently, 1D convolutional layers convert these two versions into embedded representations, which are fed into the fMRI encoder respectively. The decoder  receives these encoded latent representations and produces predictions
receives these encoded latent representations and produces predictions  and
and  . Optimize the model through the first contrast loss calculated by the InfoNCE loss function, that is, the cross-contrast loss:
. Optimize the model through the first contrast loss calculated by the InfoNCE loss function, that is, the cross-contrast loss:

In the second stage of contrastive learning, each unmasked original image  and its corresponding masked image
and its corresponding masked image 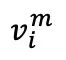 form a pair of natural positive samples. The
form a pair of natural positive samples. The 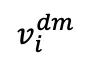 here represents the image predicted by the decoder . The second contrast loss, which is the self-contrast loss, is calculated according to the following formula:
here represents the image predicted by the decoder . The second contrast loss, which is the self-contrast loss, is calculated according to the following formula:

Optimizing the self-contrast loss can achieve occlusion reconstruction. Whether it is
can achieve occlusion reconstruction. Whether it is  or
or  , the negative sample
, the negative sample  comes from the same batch of instances.
comes from the same batch of instances.  and are jointly optimized as follows:
and are jointly optimized as follows:  , where the hyperparameters
, where the hyperparameters  and
and  are used to adjust the weight of each loss item.
are used to adjust the weight of each loss item.
Phase 2: Adjustment using cross-modal guidance
Given the low signal-to-noise ratio and highly convolutional nature of fMRI recordings , it is crucial for fMRI feature learners to focus on brain activation patterns that are most relevant to visual processing and most informative for reconstruction
After the first stage of pre-training, the fMRI autoencoder is adjusted with image assistance to achieve fMRI reconstruction, and the second stage also follows this process. Specifically, a sample  and its corresponding fMRI recorded neural response
and its corresponding fMRI recorded neural response  are selected from a batch of n samples.
are selected from a batch of n samples.  and
and  are transformed into
are transformed into  and
and  respectively after blocking and random masking processing, and then are input to the image encoder
respectively after blocking and random masking processing, and then are input to the image encoder  and fMRI encoder respectively to generate
and fMRI encoder respectively to generate  and
and  . To reconstruct fMRI
. To reconstruct fMRI , use the cross attention module to merge
, use the cross attention module to merge  and
and  :
:

W and b represent the weight and bias of the corresponding linear layer respectively.  is the scaling factor,
is the scaling factor,  is the dimension of the key vector. CA is the abbreviation of cross-attention. After
is the dimension of the key vector. CA is the abbreviation of cross-attention. After  is added to
is added to  , it is input into the fMRI decoder to reconstruct
, it is input into the fMRI decoder to reconstruct  , and
, and  is obtained:
is obtained:

The image autoencoder is also performed Similar calculations, the output  of the image encoder
of the image encoder  is merged with the output of
is merged with the output of  through the cross attention module , and then used to decode the image
through the cross attention module , and then used to decode the image  , resulting in
, resulting in  :
: 
fMRI and image autoencoders are trained together by optimizing the following loss function:

When generating images, a latent diffusion model (LDM) can be used

After completing the first and second stages of FRL training, use the fMRI feature learner's encoder to drive a latent diffusion model (LDM) to generate images from brain activity. As shown in the figure, the diffusion model includes a forward diffusion process and a reverse denoising process. The forward process gradually degrades the image into normal Gaussian noise by gradually introducing Gaussian noise with varying variance.
This study generates images by extracting visual knowledge from a pre-trained label-to-image latent diffusion model (LDM) and using fMRI data as a condition. A cross-attention mechanism is employed here to incorporate fMRI information into LDM, following recommendations from stable diffusion studies. In order to strengthen the role of conditional information, the methods of cross attention and time step conditioning are used here. In the training phase, the VQGAN encoder and the fMRI encoder trained by the first and second stages of FRL are used to process the image u and fMRI v, and the fMRI encoder is fine-tuned while keeping the LDM unchanged. The loss The function is:
and the fMRI encoder trained by the first and second stages of FRL are used to process the image u and fMRI v, and the fMRI encoder is fine-tuned while keeping the LDM unchanged. The loss The function is: 
where,  is the noise plan of the diffusion model. In the inference phase, the process starts with standard Gaussian noise at time step T, and the LDM sequentially follows the inverse process to gradually remove the noise of the hidden representation, conditioned on the given fMRI information. When time step zero is reached, the hidden representation is converted into an image using the VQGAN decoder.
is the noise plan of the diffusion model. In the inference phase, the process starts with standard Gaussian noise at time step T, and the LDM sequentially follows the inverse process to gradually remove the noise of the hidden representation, conditioned on the given fMRI information. When time step zero is reached, the hidden representation is converted into an image using the VQGAN decoder. 
Experiment
Reconstruction results
 ##By working with DC-LDM, IC- Comparison of previous studies such as GAN and SS-AE, and evaluation on the GOD and BOLD5000 data sets show that the model proposed in this study significantly exceeds these models in accuracy, which is improved compared to DC-LDM and IC-GAN respectively. 39.34% and 66.7%
##By working with DC-LDM, IC- Comparison of previous studies such as GAN and SS-AE, and evaluation on the GOD and BOLD5000 data sets show that the model proposed in this study significantly exceeds these models in accuracy, which is improved compared to DC-LDM and IC-GAN respectively. 39.34% and 66.7%
 Evaluation on the other four subjects of the GOD dataset shows that even when DC-LDM is allowed to adjust on the test set In this case, the model proposed in this study is also significantly better than DC-LDM in the Top-1 classification accuracy of 50 ways, proving the reliability and superiority of the proposed model in reconstructing brain activity of different subjects.
Evaluation on the other four subjects of the GOD dataset shows that even when DC-LDM is allowed to adjust on the test set In this case, the model proposed in this study is also significantly better than DC-LDM in the Top-1 classification accuracy of 50 ways, proving the reliability and superiority of the proposed model in reconstructing brain activity of different subjects.
The research results show that using the proposed fMRI representation learning framework and pre-trained LDM can better reconstruct the brain's visual activity, far exceeding the current baseline level. This work helps further explore the potential of neural decoding models
The above is the detailed content of NeurIPS23 | 'Brain Reading' decodes brain activity and reconstructs the visual world. For more information, please follow other related articles on the PHP Chinese website!
 mysql paging
mysql paging
 What is the shortcut key for switching users?
What is the shortcut key for switching users?
 How to solve the problem that Win10 folder cannot be deleted
How to solve the problem that Win10 folder cannot be deleted
 How to open ramdisk
How to open ramdisk
 What to do if your IP address is attacked
What to do if your IP address is attacked
 How to cut long pictures on Huawei mobile phones
How to cut long pictures on Huawei mobile phones
 mybatis first level cache and second level cache
mybatis first level cache and second level cache
 Usage of get function in c language
Usage of get function in c language








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



