


In the past year, a succession of large-scale models have made breakthroughs that are reshaping the field of robotics research.
With the most advanced large models becoming the "brains" of robots, robots are evolving faster than imagined.
In July, Google DeepMind announcedthe launch of RT-2: the world's first vision-language-action (VLA) model to control robots.
Just give the command like a dialogue, and it will be able to identify Swift among a bunch of pictures and give her a jar of "happy water."

#It can even think actively, completing a multi-stage reasoning leap from "selecting an animal for extinction" to grabbing a plastic dinosaur on the table.

After RT-2, Google DeepMind proposed Q-Transformer, and the robotics world also has its own Transformer. Q-Transformer enables robots to break through their reliance on high-quality demonstration data and become better at accumulating experience by relying on independent "thinking".
Just two months after its release, RT-2 is having another ImageNet moment for robots. Google DeepMind and other institutions launched the Open A new idea for training universal robots.
Imagine simply asking your robot assistants to complete these tasks, such as "clean the house" or "make a delicious and healthy meal." For humans, these tasks may be simple, but for robots, they require a deep understanding of the world, which is not easy. Based on years of research in the field of robot Transformers, Google recently announced a series of robot research progress: AutoRT, SARA-RT and RT-Trajectory, which can help robots make decisions faster and more efficiently. Better understand the environment they are in and better guide themselves to complete tasks. Google believes that with the launch of research results such as AutoRT, SARA-RT and RT-Trajectory, it can bring improvements to the data collection, speed and generalization capabilities of real-world robots. Next, let us review these important studies.AutoRT: Leverage large models to better train robots
AutoRT combines large base models such as large language models (LLM) or visual language models (VLM) and robot control models (RT-1 or RT-2), creating a system that can deploy robots in new environments to collect training data. AutoRT can simultaneously guide multiple robots equipped with video cameras and end effectors to perform diverse tasks in a variety of environments. Specifically, each robot will use a visual language model (VLM) to "look around" and understand its environment and objects within its line of sight, based on AutoRT. Next, the large language model will propose a series of creative tasks for it, such as "put snacks on the table," and play the role of decision-maker, choosing the tasks for the robot to perform. Researchers conducted an extensive seven-month evaluation of AutoRT in real-world settings. Experiments have proven that the AutoRT system can safely coordinate up to 20 robots at the same time, and a maximum of 52 robots in total. By guiding the robots to perform a variety of tasks within a variety of office buildings, the researchers collected a diverse dataset spanning 77,000 robot trials with 6,650 unique tasks.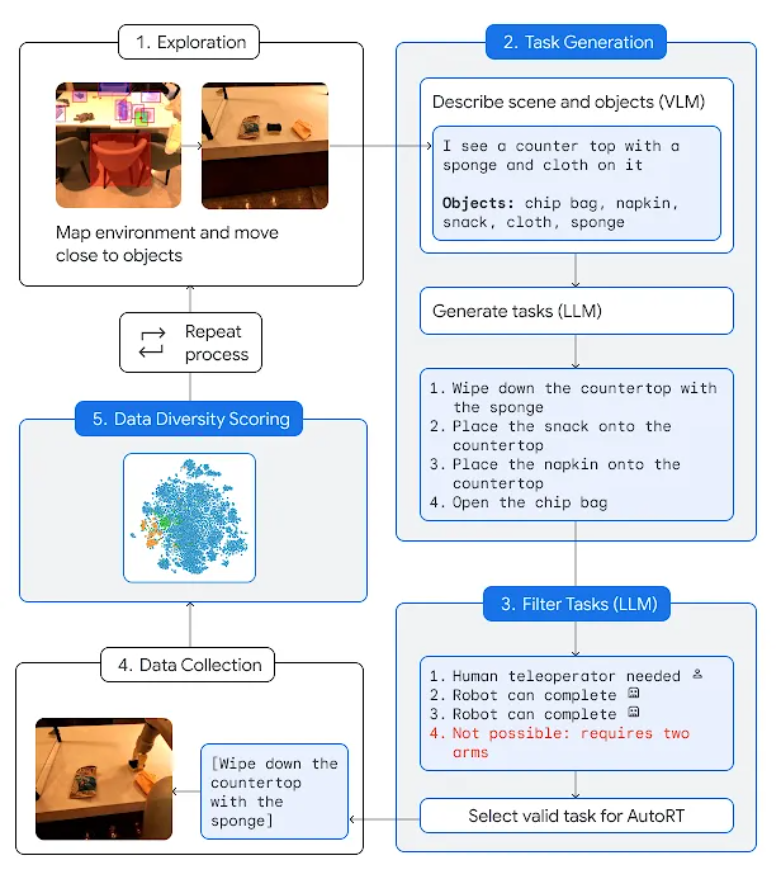
While AutoRT is just a data collection system now, think of it as the early stages of autonomous robots in the real world. It features safety guardrails, one of which is a set of safety-focused cue words that provide ground rules to follow when the robot makes LLM-based decisions.
These rules are inspired in part by Isaac Asimov's Three Laws of Robotics, the most important of which is that robots "must not harm humans." Safety rules also require robots not to attempt tasks involving humans, animals, sharp objects or electrical appliances.
Only working on prompt words cannot fully guarantee the safety of robots in practical applications. Therefore, the AutoRT system also includes a layer of practical safety measures that is a classic design of robotics. For example, collaborative robots are programmed to automatically stop if the forces on their joints exceed a given threshold, and all autonomously controlled robots are able to be restricted to the line of sight of a human supervisor via a physical deactivation switch.
SARA-RT: Make the robot Transformer (RT) faster and more streamlined
Another achievement, SARA-RT, can transform the robot Transformer (RT) The model is converted to a more efficient version.
The RT neural network architecture developed by the Google team has been used in the latest robot control systems, including the RT-2 model. The best SARA-RT-2 model is 10.6% more accurate and 14% faster than the RT-2 model when given a brief image history. Google says it's the first scalable attention mechanism that increases computing power without compromising quality.
While Transformers are powerful, they can be limited by computational requirements, slowing decision-making. Transformer mainly relies on the attention module of quadratic complexity. This means that if the input to the RT model is doubled (e.g., providing the robot with more or higher-resolution sensors), the computational resources required to process that input increase fourfold, resulting in slower decision-making.
SARA-RT adopts a novel model fine-tuning method (called "up-training") to improve the efficiency of the model. Uptraining converts quadratic complexity into purely linear complexity, significantly reducing computational requirements. This conversion not only improves the speed of the original model, but also maintains its quality.
Google hopes that many researchers and practitioners will apply this practical system to robotics and other fields. Because SARA provides a general approach to speeding up Transformers without the need for computationally expensive pre-training, this approach has the potential to scale Transformer technology at scale. SARA-RT does not require any additional coding as various open source linear variants are available.
When SARA-RT is applied to the SOTA RT-2 model with billions of parameters, it enables faster decision-making and better performance in a variety of robotic tasks:

SARA-RT-2 model for manipulation tasks. The robot's movements are conditioned on images and textual instructions.
With its solid theoretical foundation, SARA-RT can be applied to various Transformer models. For example, applying SARA-RT to the Point Cloud Transformer, which processes spatial data from a robot's depth camera, can more than double the speed.
RT-Trajectory: Helping Robots Generalize
Humans can intuitively understand and learn how to clean tables, but robots need many possible ways to translate instructions into actual physical action.
Traditionally, training of robotic arms relies on mapping abstract natural language (wipe the table) to concrete actions (close gripper, move left, move right), which makes the model difficult to generalize to a new task. In contrast, the RT-Trajectory Model enables the RT model to understand "how" a task is accomplished by interpreting specific robot actions (such as those in a video or sketch).
RT-Trajectory model can automatically add visual contours to describe the robot's movements in the training video. RT-Trajectory overlays each video in the training dataset with a 2D trajectory sketch of the gripper as the robot arm performs a task. These trajectories, in the form of RGB images, provide low-level, practical visual cues for the model to learn robot control strategies.
When tested on 41 tasks not seen in the training data, the performance of the robot arm controlled by RT-Trajectory was more than double that of the existing SOTA RT model: the task success rate reached 63% , while the success rate of RT-2 is only 29%.
The system is so versatile that RT-Trajectory can also create trajectories by watching human demonstrations of the required tasks, and even accepts hand-drawn sketches. Moreover, it can adapt to different robot platforms at any time.
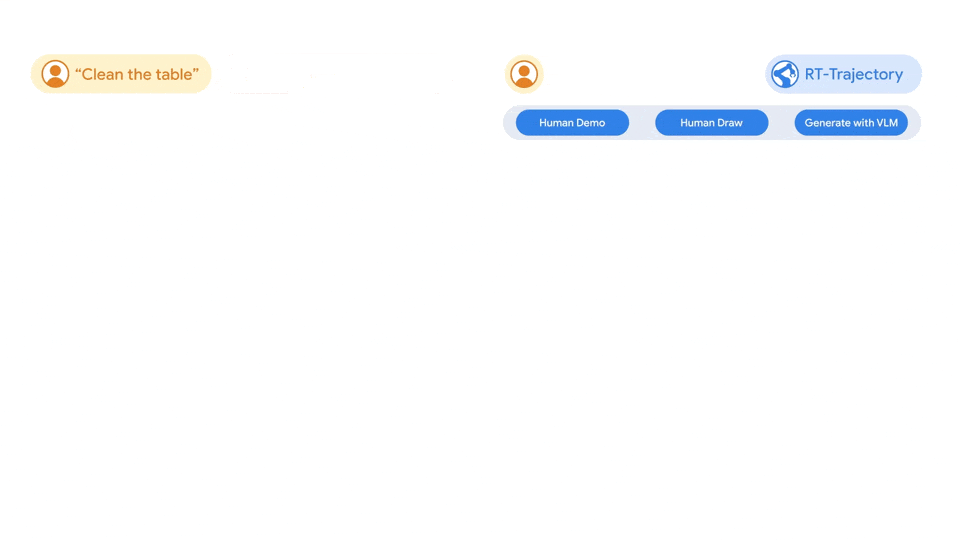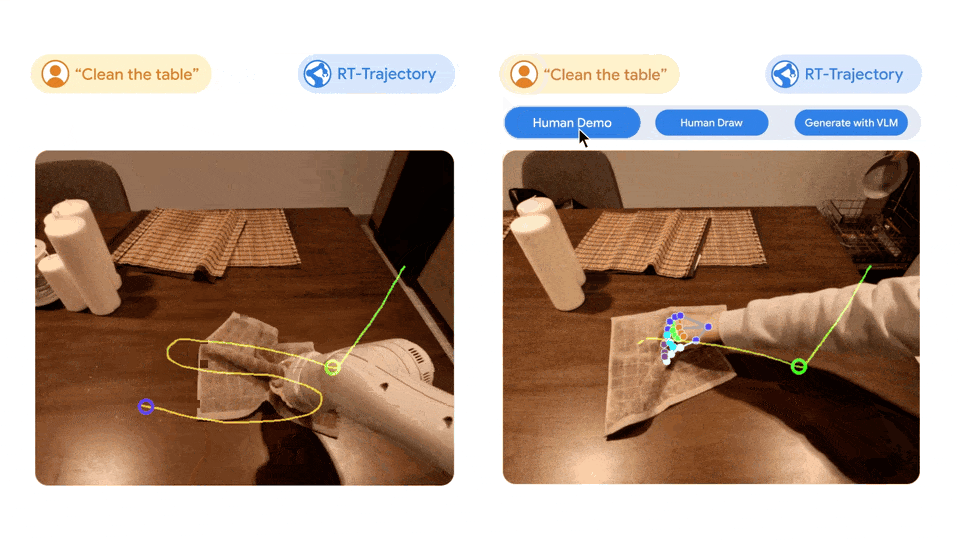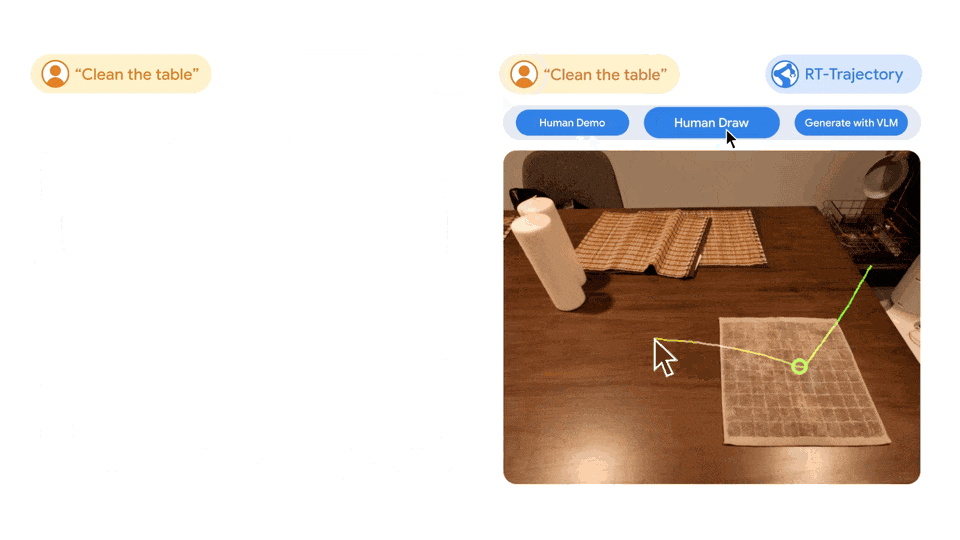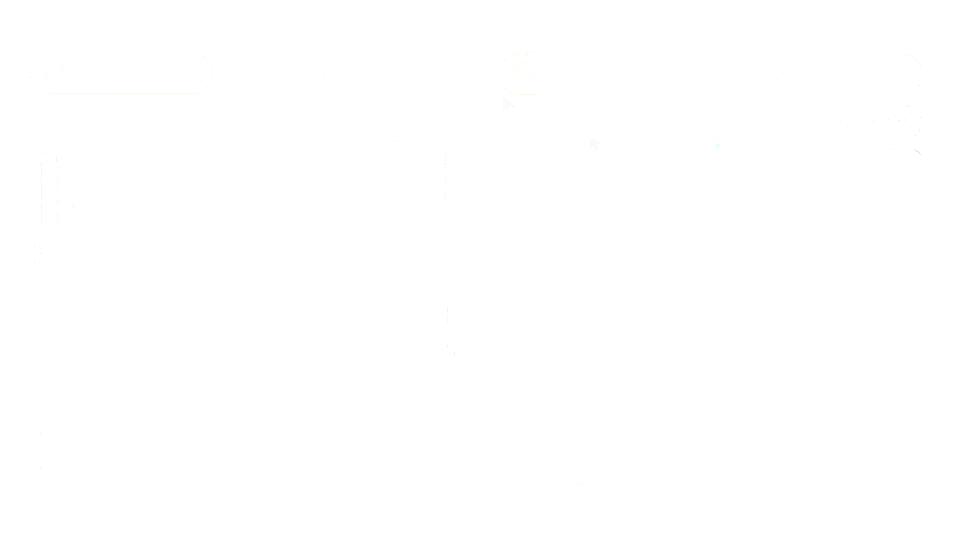 Left picture: The robot controlled by the RT model trained only using the natural language data set was frustrated when performing the new task of wiping the table, while the robot controlled by the RT trajectory model was After training on the same dataset augmented with 2D trajectories, the wiping trajectory was successfully planned and executed. Right: A trained RT trajectory model, given a new task (wiping the table), can create 2D trajectories in a variety of ways, with human assistance or on its own using a visual language model.
Left picture: The robot controlled by the RT model trained only using the natural language data set was frustrated when performing the new task of wiping the table, while the robot controlled by the RT trajectory model was After training on the same dataset augmented with 2D trajectories, the wiping trajectory was successfully planned and executed. Right: A trained RT trajectory model, given a new task (wiping the table), can create 2D trajectories in a variety of ways, with human assistance or on its own using a visual language model.
RT trajectories exploit the rich robot motion information that is present in all robot datasets but is currently underutilized. RT-Trajectory not only represents another step on the path to creating robots that move efficiently and accurately for new tasks, but also enables the discovery of knowledge from existing data sets.
The above is the detailed content of Google Deepmind envisions a future that reinvents robots, bringing embodied intelligence to large models. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



