


To be honest, the speed of technology update is indeed very fast, which has also led to some old methods in academia being gradually replaced by new methods. Recently, a research team from Zhejiang University proposed a new method called Gaussians, which has attracted widespread attention. This method has unique advantages in solving problems and has been successfully used in work. Although Nerf has gradually lost some influence in academia
In order to help players who have not yet passed the level, let’s take a look at the specific methods of solving puzzles in the game.
To help players who have not passed the level yet, we can learn about the specific puzzle solving methods together. To do this, I found a paper on puzzle solving, the link is here: https://arxiv.org/pdf/2401.01339.pdf. You can learn more about puzzle-solving techniques by reading this paper. Hope this helps players!
This paper aims to solve the problem of modeling dynamic urban street scenes from monocular videos. Recent methods have extended NeRF to incorporate tracked vehicle poses into animate vehicles, enabling photorealistic view synthesis of dynamic urban street scenes. However, their significant limitations are slow training and rendering speeds, coupled with the urgent need for high accuracy in tracking vehicle poses. This paper introduces Street Gaussians, a new explicit scene representation that addresses all these limitations. Specifically, dynamic city streets are represented as a set of point clouds equipped with semantic logits and 3D Gaussians, each associated with a foreground vehicle or background.
To model the dynamics of foreground object vehicles, each object point cloud can be optimized using optimizable tracking poses as well as dynamic spherical harmonic models of dynamic appearance. This explicit representation allows for simple synthesis of target vehicles and backgrounds, and scene editing operations and rendering at 133 FPS (1066×1600 resolution) within half an hour of training. The researchers evaluated this approach on several challenging benchmarks, including the KITTI and Waymo Open datasets.
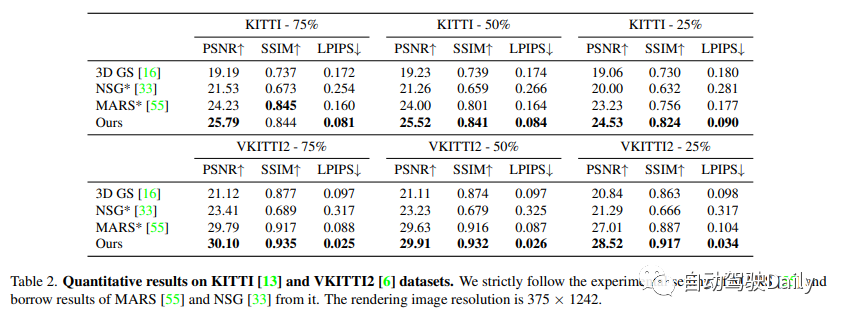
Experimental results show that our proposed method consistently outperforms existing techniques on all datasets. Although we rely solely on pose information from off-the-shelf trackers, our representation provides performance comparable to that achieved using real pose information.
In order to help players who have not passed the level yet, I have provided you with a link: https://zju3dv.github.io/streetgaussians/, where you can find specific puzzle solving methods. You can click on the link for reference, I hope it can help you.
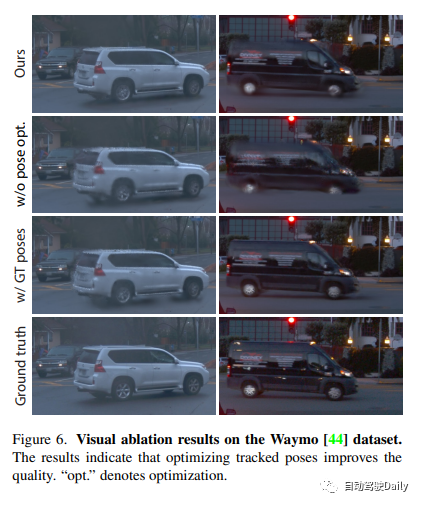
Given a series of images captured from a moving vehicle in an urban street scene, the goal of this paper is to develop a method that can A model that generates photorealistic images from any input time step and any viewpoint. To achieve this goal, a new scene representation, named Street Gaussians, is proposed, specifically designed to represent dynamic street scenes. As shown in Figure 2, the dynamic urban street scene is represented as a set of point clouds, each point cloud corresponding to a static background or a moving vehicle. Explicit point-based representation allows for simple composition of individual models, enabling real-time rendering as well as foreground object decomposition for editing applications. The proposed scene representation can be efficiently trained using only RGB images along with tracked vehicle poses from off-the-shelf trackers, enhanced by our tracked vehicle pose optimization strategy.
Street Gaussians Overview As shown below, dynamic urban street scenes are represented as a set of point-based background and foreground targets with optimized tracked vehicle poses. Each point is assigned a 3D Gaussian including position, opacity and covariance consisting of rotation and scale to represent the geometry. To represent the appearance, each background point is assigned a spherical harmonic model, while the foreground point is associated with a dynamic spherical harmonic model. Explicit point-based representation allows simple combination of separate models, which enables real-time rendering of high-quality images and semantic maps (optional if 2D semantic information is provided during training), as well as decomposition of foreground objects for editing Application

We conducted experiments on the Waymo open dataset and the KITTI benchmark. On the Waymo open data set, 6 recording sequences were selected, which contained a large number of moving objects, significant ego motion, and complex lighting conditions. The length of all sequences is approximately 100 frames, and every 10 images in the sequence are selected as test frames and the remaining images are used for training. When it was found that our baseline method had a high memory cost when training with high-resolution images, the input images were downscaled to 1066×1600. On KITTI and Vitural KITTI 2, the settings of MARS were followed and evaluated using different train/test split settings. Use the bounding boxes generated by the detector and tracker on the Waymo dataset, and use the target trajectory officially provided by KITTI.

Compare our method with three recent methods.
(1) NSG represents the background as a multi-plane image and uses latent codes learned for each object and shared decoders to model moving objects.
(2) MARS builds the scene graph based on Nerfstudio.
(3) 3D Gaussian uses a set of anisotropic Gaussians to model the scene.
Both NSG and MARS are trained and evaluated using GT boxes, different versions of their implementations are tried here and the best results for each sequence are reported. We also replace SfM point clouds in 3D Gaussian maps with the same input as our method for fair comparison. See supplementary information for details.



The above is the detailed content of Real-time rendering: dynamic urban scene modeling based on Street Gaussians. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



