


In the eighth section of the awk series, we introduced some powerful awk command functions, which are variables, numeric expressions, and assignment operators.
In this section we will learn more about awk functions, namely awk's special modes:BEGINandEND.
As we progress and explore more ways to build complex awk operations, we will prove how powerful these special features of awk are.
Before we start, let us review the introduction of the awk series. Remember when we started this series, I pointed out that the general syntax of the awk instruction is like this:
# awk 'script' filenames
In the above syntax, the awk script has this form:
/pattern/ { actions }
You will usually find that the pattern in the script (/pattern) is a regular expression. In addition, you can also use the special patterns hereBENGINandEND. Therefore, we can also write an awk command in the following form:
awk ' BEGIN { actions } /pattern/ { actions } /pattern/ { actions } ………. END { actions } ' filenames
If you use special modes in the awk script:BEGINandEND, the following are their corresponding meanings:
The execution flow of awk command scripts containing these special modes is as follows:
When you use special modes, to get the best results from awk operations, you should remember the above execution order.
For ease of understanding, let us use the example in Section 8 for demonstration. That example is about the list of domain names owned by Tecmint and saved in a file called domains.txt.
news.tecmint.com tecmint.com linuxsay.com windows.tecmint.com tecmint.com news.tecmint.com tecmint.com linuxsay.com tecmint.com news.tecmint.com tecmint.com linuxsay.com windows.tecmint.com tecmint.com
$ cat ~/domains.txt
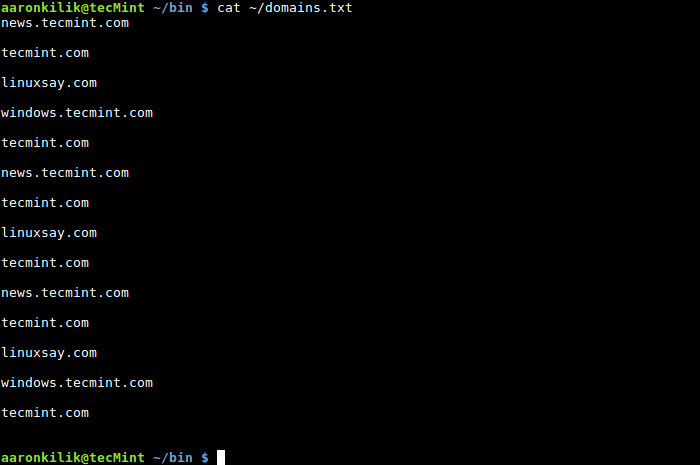
In this example, we hope to count the number of times the domain nametecmint.comappears in the domains.txt file. So, we wrote a simple shell script to help us complete the task, which uses the ideas of variables, mathematical expressions and assignment operators. The content of the script is as follows:
#!/bin/bash for file in $@; do if [ -f $file ] ; then ### 输出文件名 echo "File is: $file" ### 输出一个递增的数字记录包含 tecmint.com 的行数 awk '/^tecmint.com/ { counter+=1 ; printf "%s/n", counter ; }' $file else ### 若输入不是文件,则输出错误信息 echo "$file 不是一个文件,请指定一个文件。" >&2 && exit 1 fi done ### 成功执行后使用退出代码 0 终止脚本 exit 0
Now let us apply these two special patterns in the awk command of the above script like below:BEGINandEND:
We should put the script:
awk '/^tecmint.com/ { counter+=1 ; printf "%s/n", counter ; }' $file
changed to:
awk ' BEGIN { print "文件中出现 tecmint.com 的次数是:" ; } /^tecmint.com/ { counter+=1 ; } END { printf "%s/n", counter ; } ' $file
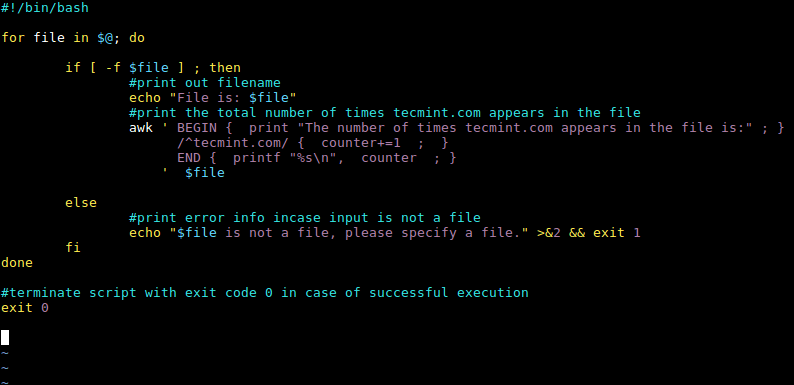
在修改了 awk 命令之后,现在完整的 shell 脚本就像下面这样:
#!/bin/bash for file in $@; do if [ -f $file ] ; then ### 输出文件名 echo "File is: $file" ### 输出文件中 tecmint.com 出现的总次数 awk ' BEGIN { print "文件中出现 tecmint.com 的次数是:" ; } /^tecmint.com/ { counter+=1 ; } END { printf "%s/n", counter ; } ' $file else ### 若输入不是文件,则输出错误信息 echo "$file 不是一个文件,请指定一个文件。" >&2 && exit 1 fi done ### 成功执行后使用退出代码 0 终止脚本 exit 0
当我们运行上面的脚本时,它会首先输出 domains.txt 文件的位置,然后执行 awk 命令脚本,该命令脚本中的特殊模式BEGIN将会在从文件读取任何行之前帮助我们输出这样的消息“文件中出现 tecmint.com 的次数是:”。
接下来,我们的模式/^tecmint.com/会在每个输入行中进行比较,对应的动作{ counter+=1 ; }会在每个匹配成功的行上执行,它会统计出tecmint.com在文件中出现的次数。
最终,END模式将会输出域名tecmint.com在文件中出现的总次数。
$ ./script.sh ~/domains.txt

最后总结一下,我们在本节中演示了更多的 awk 功能,并学习了特殊模式BEGIN和END的概念。
正如我之前所言,这些 awk 功能将会帮助我们构建出更复杂的文本过滤操作。第十节将会给出更多的 awk 功能,我们将会学习 awk 内置变量的思想,所以,请继续保持关注。
The above is the detailed content of How to use awk's special modes BEGIN and END for processing. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



