The PyTorch team personally teaches you how to accelerate large model inference.
In the past year, generative AI has developed rapidly. Among them, text generation has been a particularly popular field. Many Open source projects such as llama.cpp, vLLM, MLC-LLM, etc. are constantly being optimized in order to achieve better results. As one of the most popular frameworks in the machine learning community, PyTorch has naturally seized this new opportunity and continuously optimized it. In order to let everyone better understand these innovations, the PyTorch team has specially set up a series of blogs to focus on how to use pure native PyTorch to accelerate generative AI models. 
Code address: https://github.com/pytorch-labs/gpt-fastIn the In a blog, the PyTorch team demonstrated how to rewrite the Segment Anything (SAM) model using only pure native PyTorch, which is 8 times faster than the original implementation. In this blog, they bring us something new, namely how to speed up LLM inference.
Let’s take a look at the results first. The team rewrote LLM, and the inference speed was 10 times faster than the baseline, without losing accuracy and using less than 1000 lines of pure native PyTorch code! 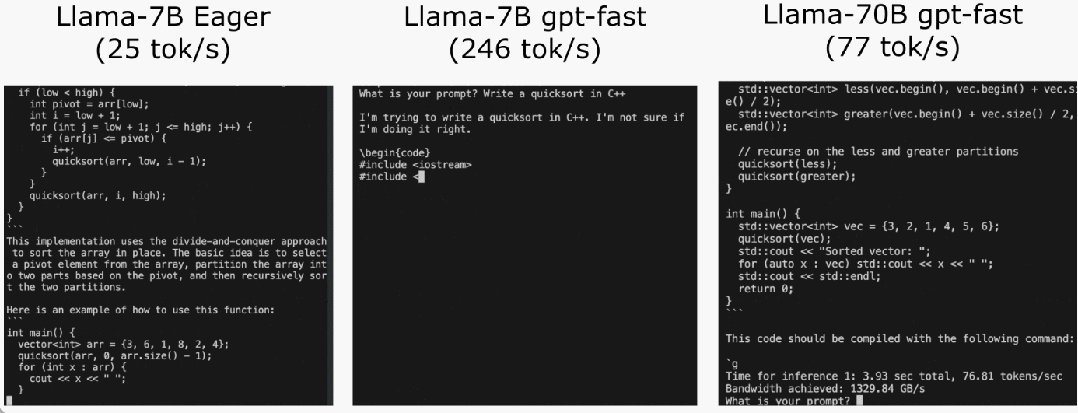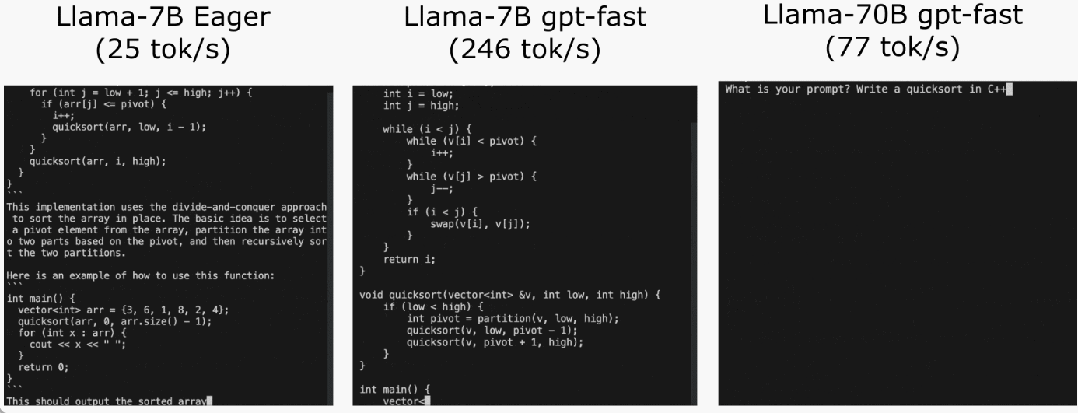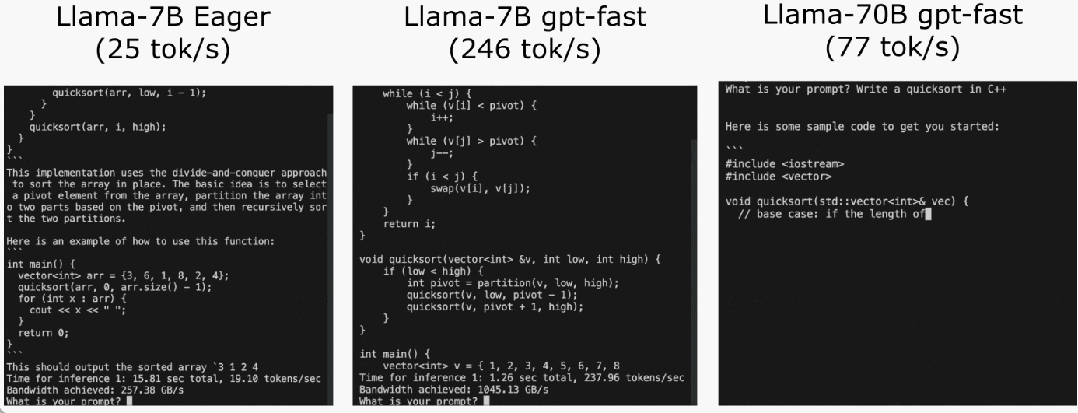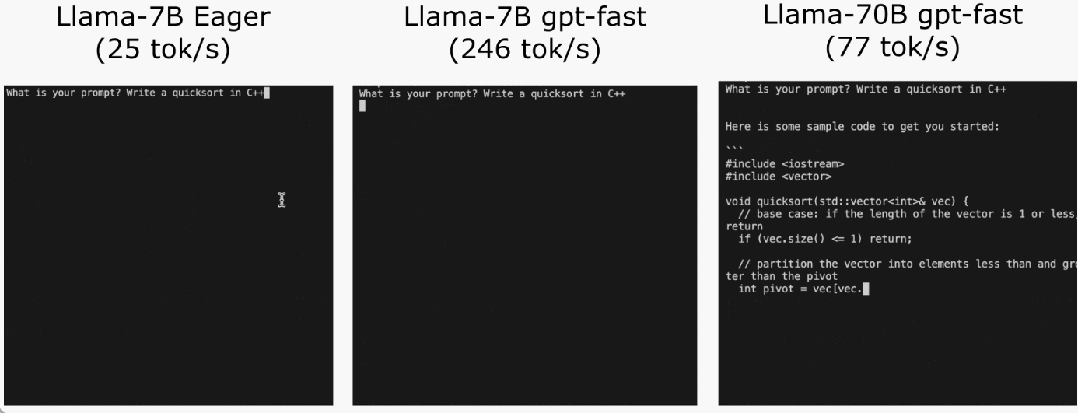
All benchmarks were run on the A100-80GB, which is limited to 330W.
These optimizations include: Torch.compile: PyTorch model compiler, PyTorch 2.0 adds a new function called torch.compile (), which can accelerate existing models with one line of code; GPU quantization: by reducing Computational accuracy to accelerate the model;Speculative Decoding: a large model inference acceleration method that uses a small "draft" model to predict the output of a large "target" model;Tensor Parallel: Accelerate model inference by running models on multiple devices.
Next, let’s see how each step is implemented. 6 Steps to speed up large model inference
The study shows that without optimization , the inference performance of the large model is 25.5 tok/s, and the effect is not very good: 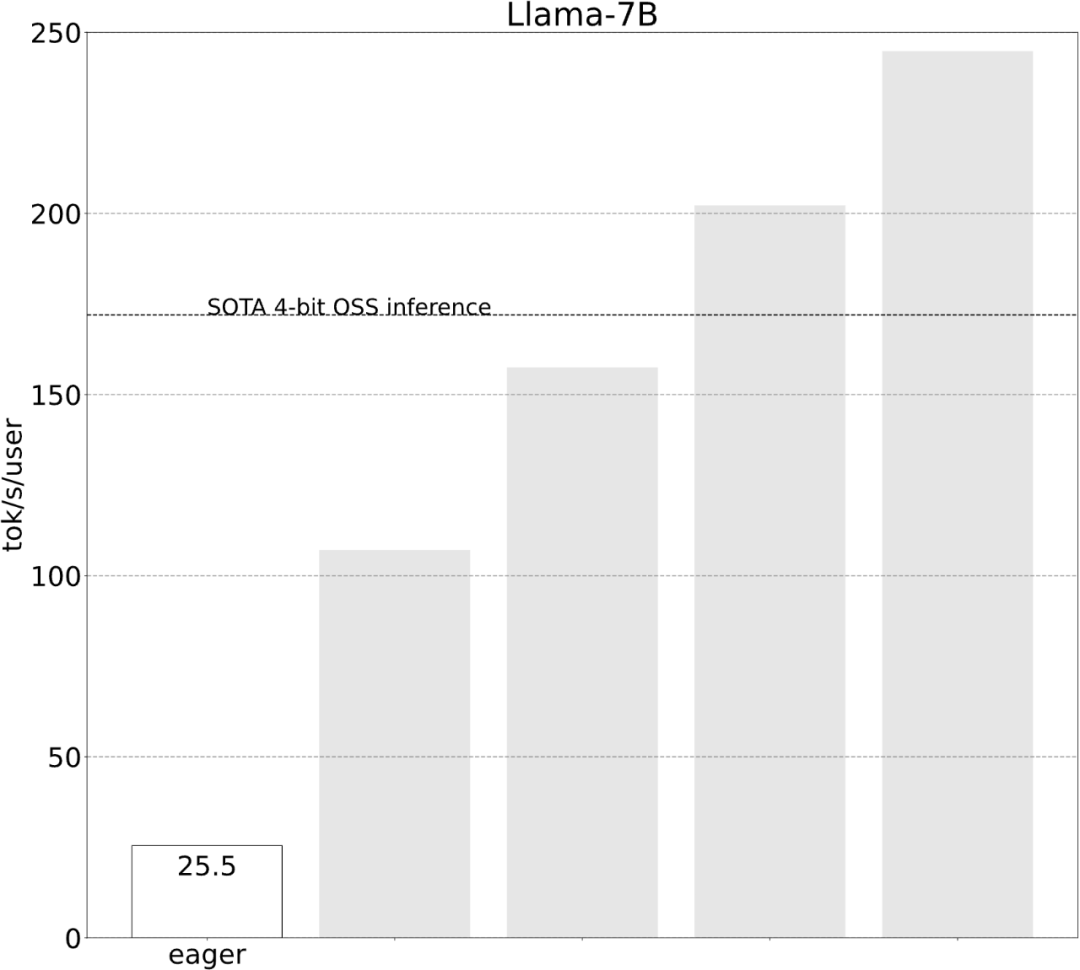 After some exploration, I finally found the reason: excessive CPU overhead. Then there is the following 6-step optimization process.
After some exploration, I finally found the reason: excessive CPU overhead. Then there is the following 6-step optimization process.

Step one: Reduce CPU overhead through Torch.compile and static KV cache to achieve 107.0 TOK/S
torch.compile allows users to capture larger areas into a single compilation area, especially when mode="reduce-overhead" (refer to the code below), this feature is very useful for reducing CPU overhead. Effective. In addition, this article also specifies fullgraph=True to verify that there is no "graph interruption" in the model (that is, the part that torch.compile cannot compile).  #However, even with the blessing of torch.compile, there are still some obstacles.
#However, even with the blessing of torch.compile, there are still some obstacles.
The first hurdle is the kv cache. That is, when the user generates more tokens, the "logical length" of the kv cache will grow. This problem arises for two reasons: first, it is very expensive to reallocate (and copy) the kv cache every time the cache grows; second, this dynamic allocation makes it more difficult to reduce the overhead.
In order to solve this problem, this article uses a static KV cache, statically allocates the size of the KV cache, and then masks out unused values in the attention mechanism. The second obstacle is the prefill stage. Text generation with Transformer can be viewed as a two-stage process: 1. Prefill stage to process the entire prompt 2. Decode the token.Although the kv cache is set to static ization, but the prefill phase still requires more dynamics due to variable prompt lengths. Therefore, separate compilation strategies need to be used to compile these two stages.

While these details are a bit tricky, they are not difficult to implement and the performance improvements are huge. After this operation, the performance increased by more than 4 times, from 25 tok/s to 107 tok/s. 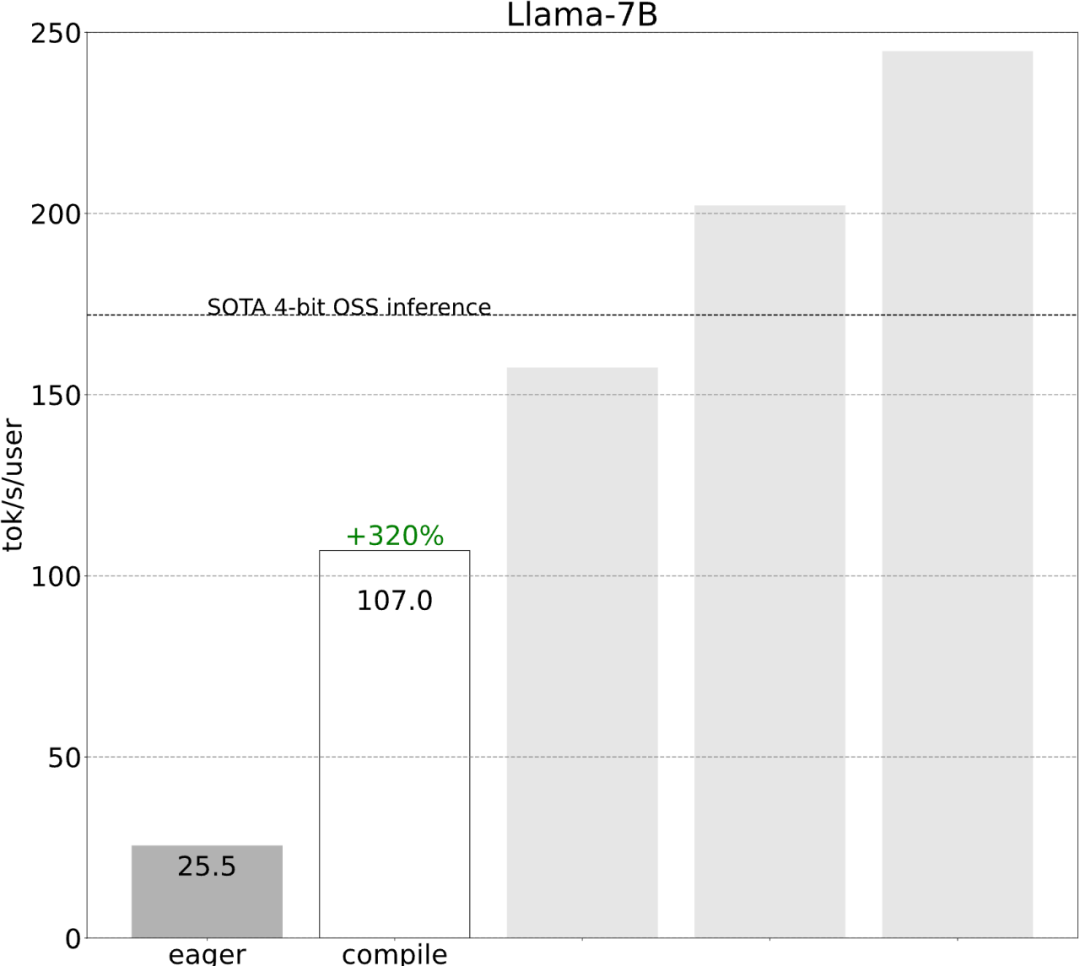
The second step: alleviate the memory bandwidth bottleneck through int8 weight quantization to achieve 157.4 tok /sThrough the above, we have seen the huge acceleration brought by applying torch.compile, static kv cache, etc., but the PyTorch team is not satisfied with this, and they have found other angles for optimization. They believe that the biggest bottleneck in accelerating generative AI training is the cost of loading weights from GPU global memory into registers. In other words, each forward pass needs to "touch" every parameter on the GPU. So, how fast can we theoretically "access" every parameter in the model? 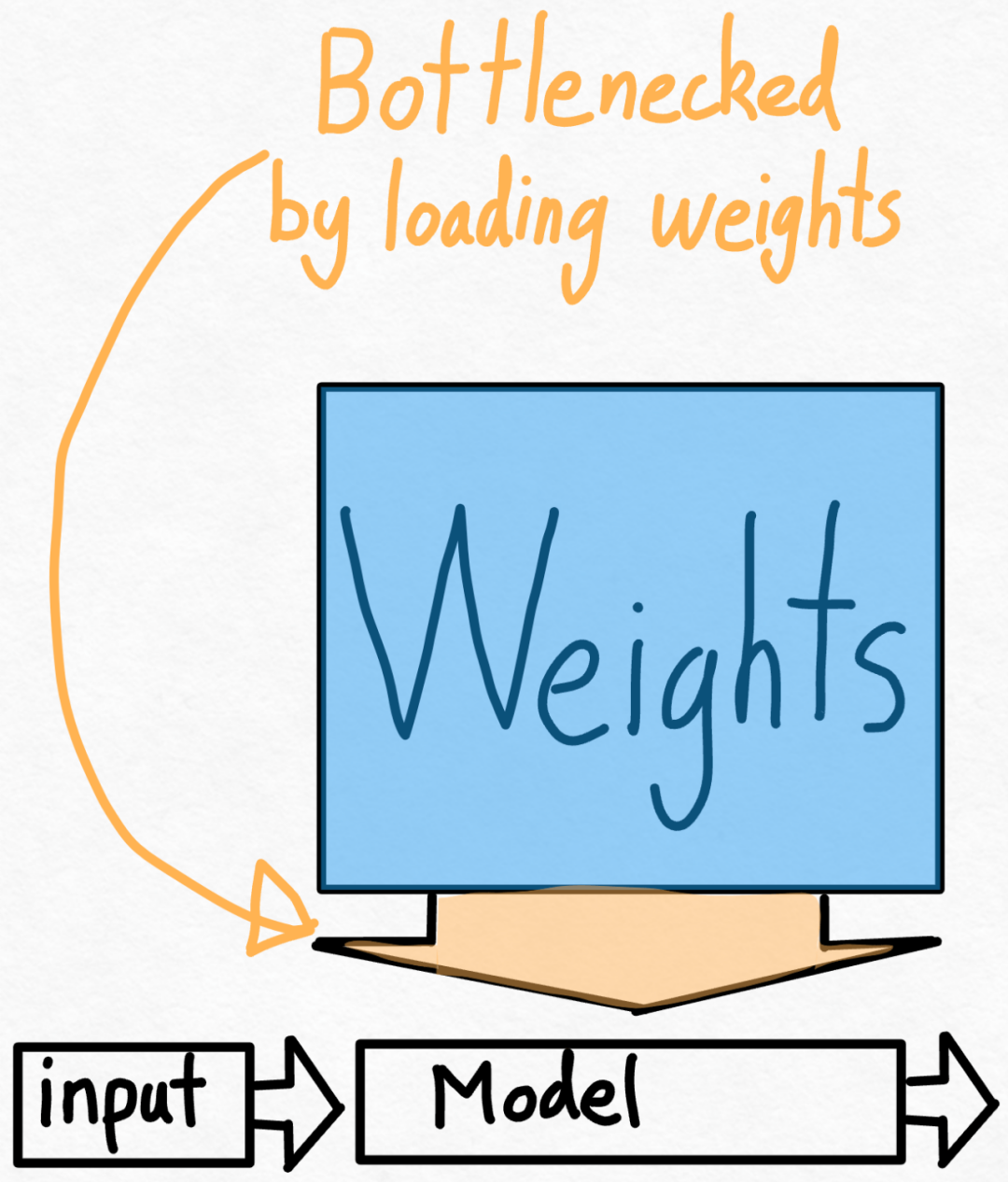
To measure this, this article uses Model Bandwidth Utilization (MBU), which is very simple to calculate as follows: 
For example, for a 7B parameter model, each parameter is stored in fp16 (2 bytes per parameter), 107 tokens/s can be achieved. The A100-80GB has a theoretical memory bandwidth of 2 TB/s. As shown in the figure below, by putting the above formula into specific values, you can get an MBU of 72%! This result is quite good, because many studies have difficulty breaking through 85%. 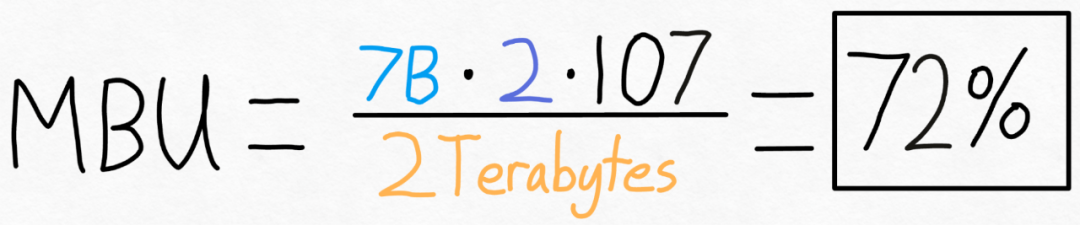
But the PyTorch team also wants to increase this value. They found that they could not change the number of parameters in the model, nor could they change the memory bandwidth of the GPU. But they discovered that they could change the number of bytes stored for each parameter! 
So they intend to use int8 quantization. 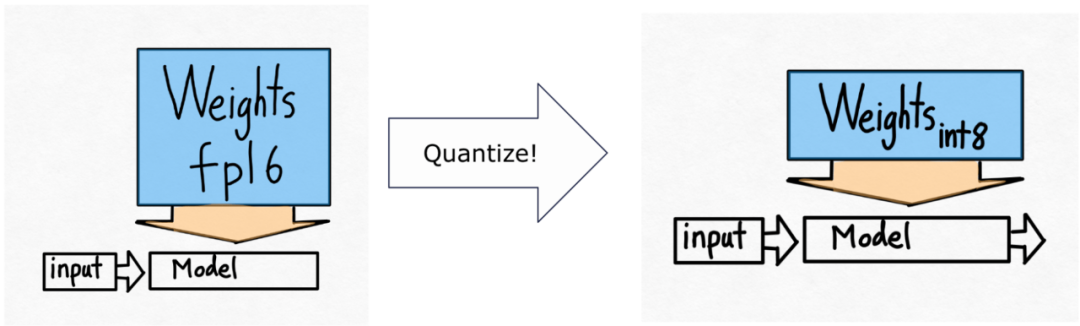
Please note that this is only the quantized weights, the calculation itself is still done in bf16. Furthermore, with torch.compile, it is easy to generate efficient code for int8 quantization. 
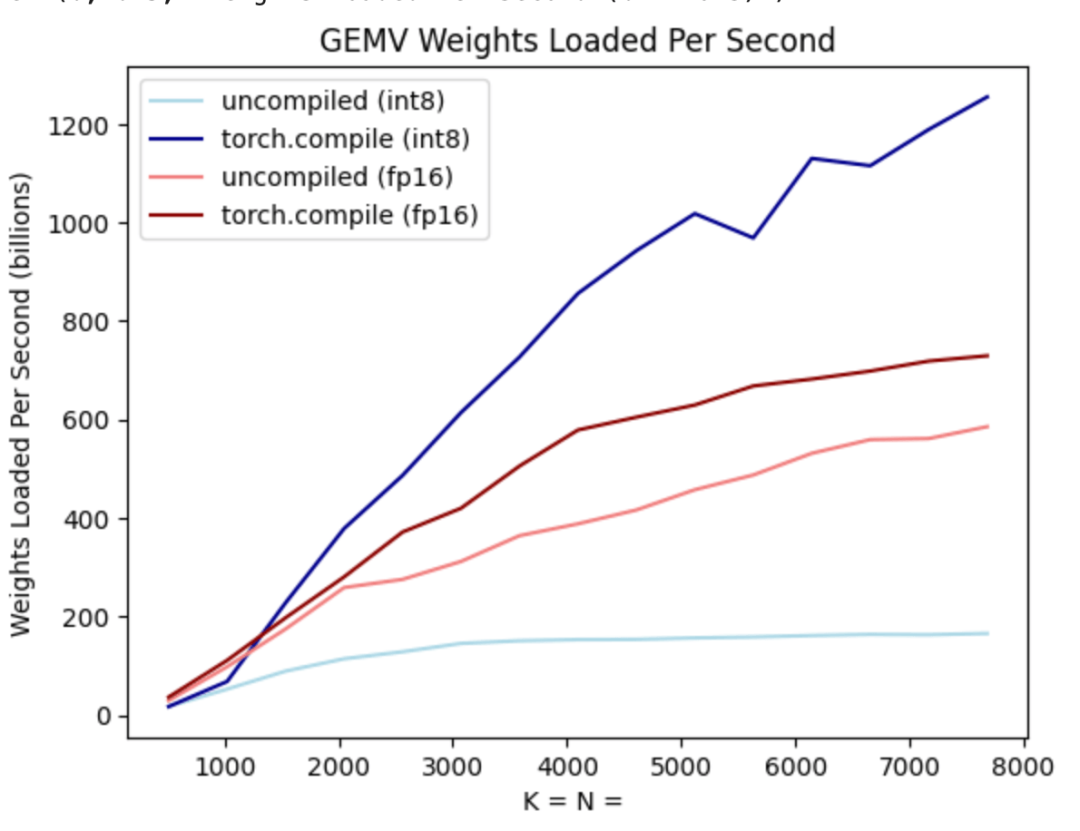
As shown in the picture above, it can be seen from the dark blue line (torch.compile int8) that using torch.compile There is a significant performance improvement when weight-only quantization is int8. Applying int8 quantization to the Llama-7B model improves performance by about 50%, reaching 157.4 tokens/s. 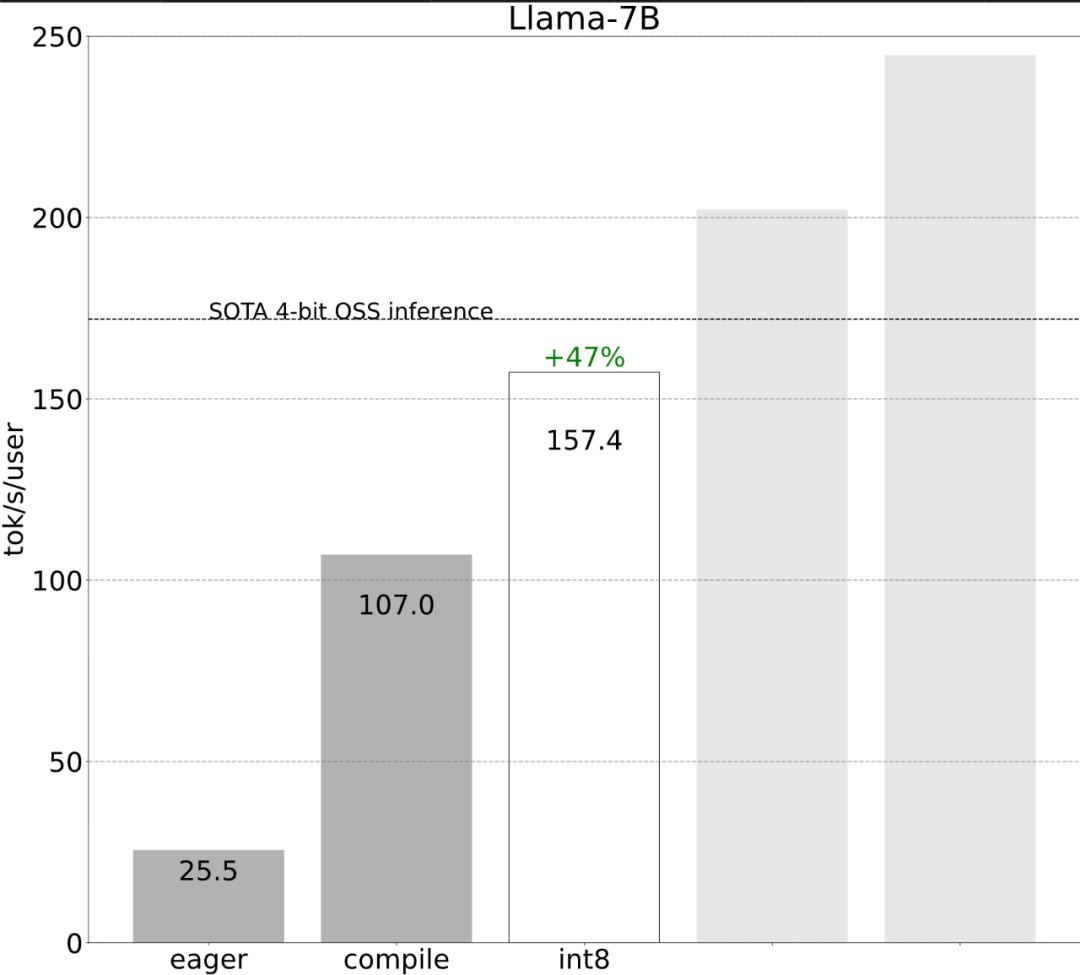
Step 3: Use Speculative Decoding
Even after using After int8 quantization and other technologies, the team still faced another problem, that is, in order to generate 100 tokens, the weights must be loaded 100 times. 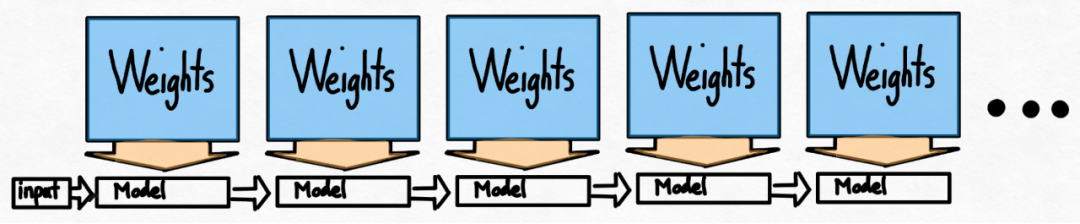
Even if the weights are quantized, loading the weights over and over again is unavoidable. How to solve this problem? It turns out that leveraging speculative decoding can break this strict serial dependency and gain speedup. 
This study uses the draft model to generate 8 tokens, and then uses the validator model to process them in parallel, discarding unmatched tokens. This process breaks serial dependencies. The entire implementation takes about 50 lines of native PyTorch code. 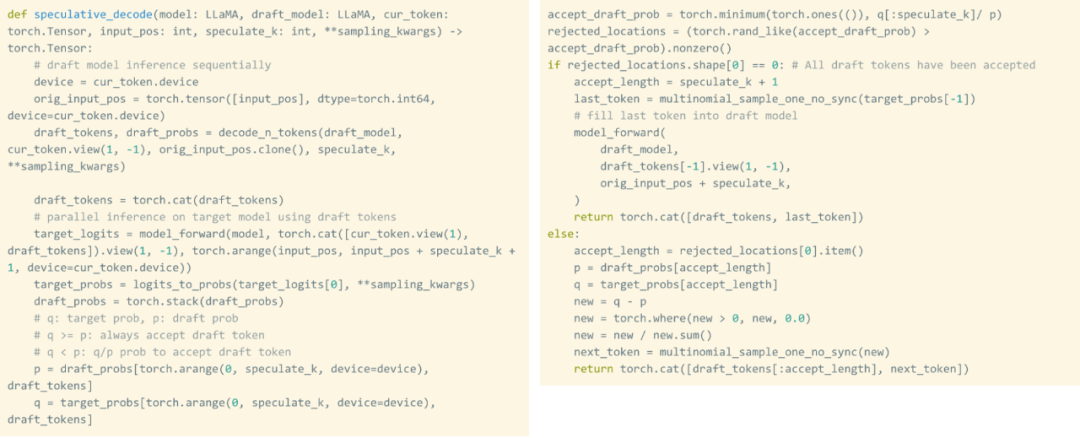
Step 4: Use int4 quantization and GPTQ methods to further reduce the weight and achieve 202.1 tok/sThis article found that when the weight is 4-bits, the accuracy of the model begins to decrease. 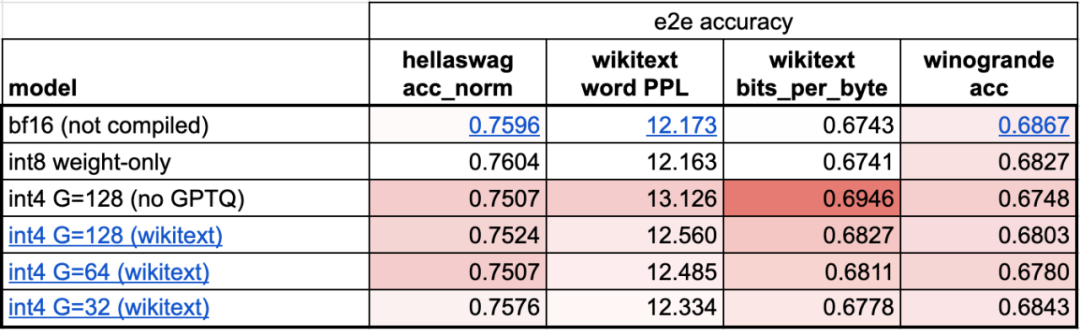
In order to solve this problem, this article uses two techniques to solve it: the first is to have a more fine-grained scaling factor; the other is to use a more advanced quantization strategy . Combining these operations together, we get this: 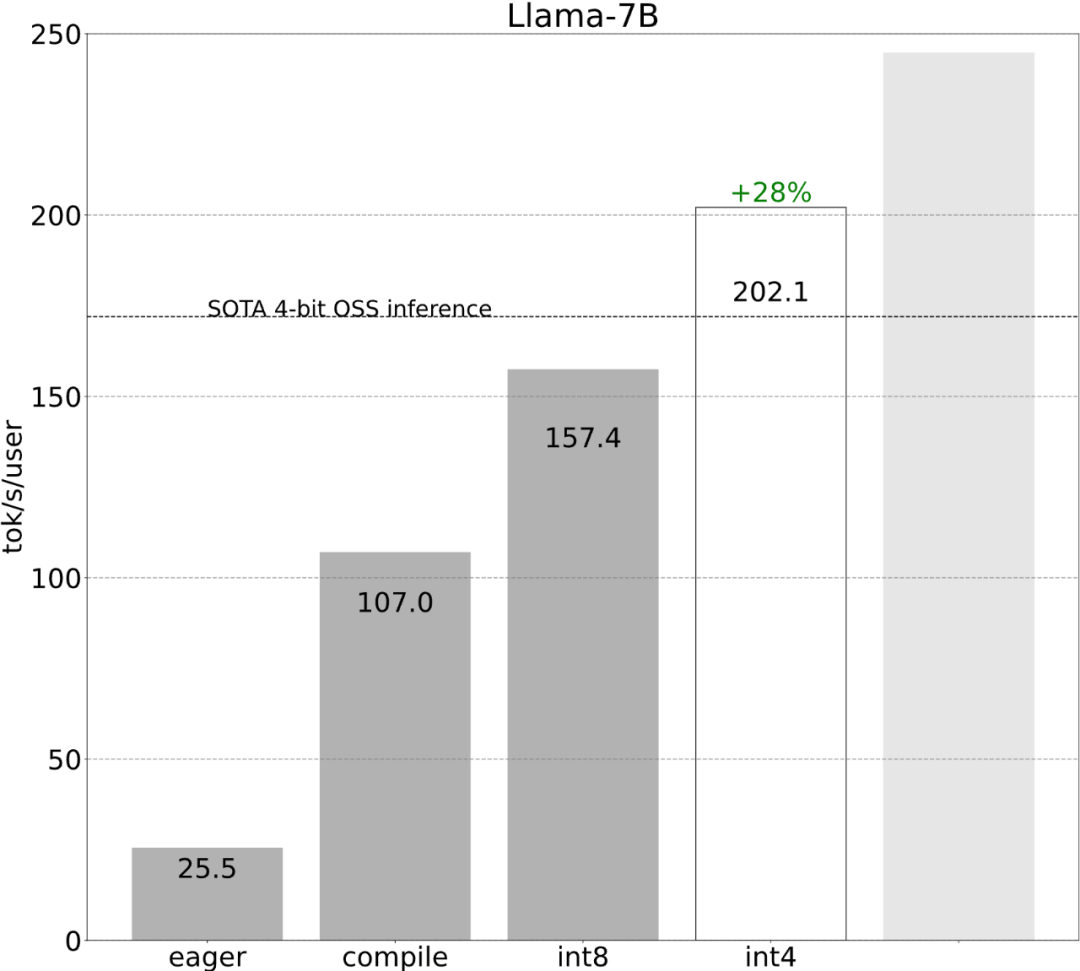
Step 5: Combining everything together, we get 244.7 tok/s Finally, combining all techniques together for better performance, we get 244.7 tok/s. 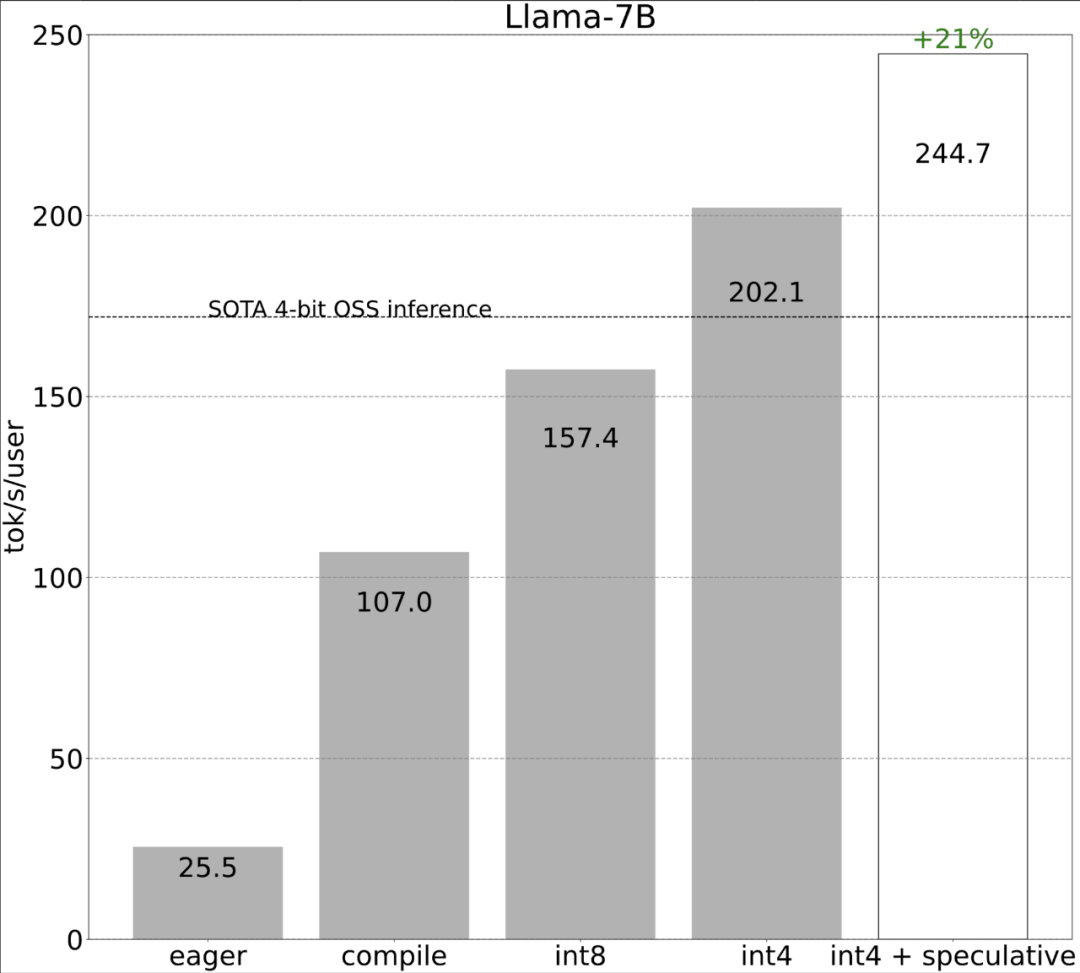
Step Six: Tensor ParallelismSo far, this article has been is to minimize latency on a single GPU. In fact, it is also possible to use multiple GPUs, so that the latency will be further improved. Fortunately, the PyTorch team provides low-level tools for tensor parallelism that only require 150 lines of code and do not require any model changes. 
All of the previously mentioned optimizations can continue to be combined with tensor parallelism, and combined these can achieve 55 tokens/s for the Llama-70B model Provides int8 quantization. 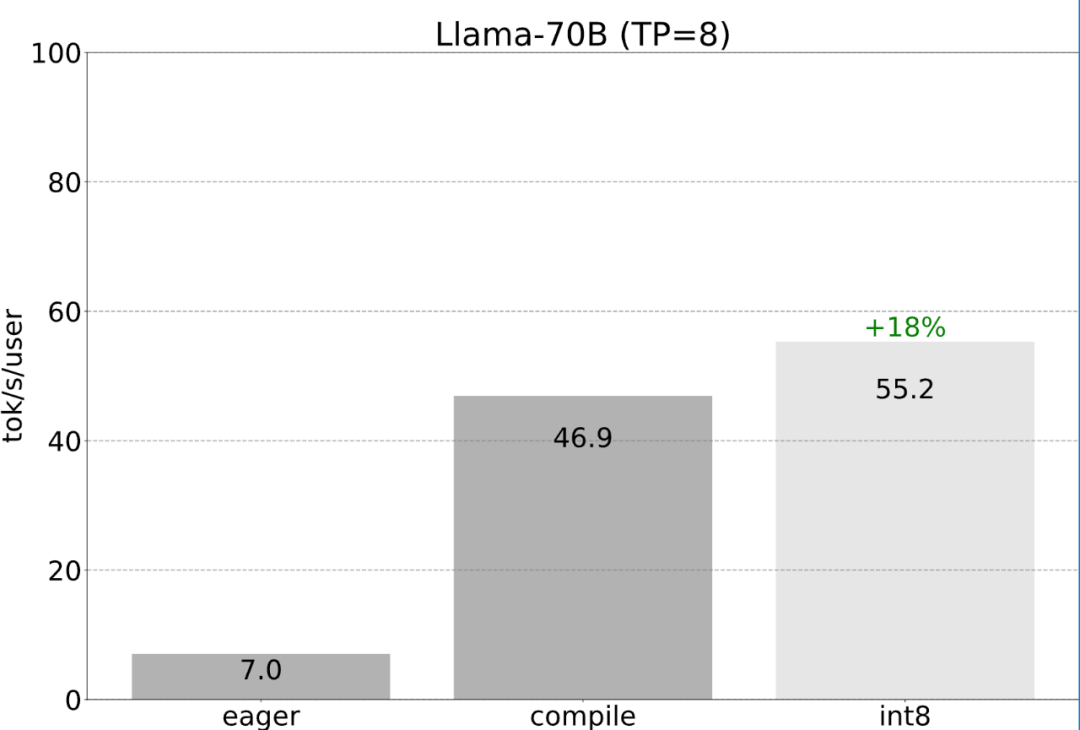
Finally, briefly summarize the main content of the article. On Llama-7B, this article uses the "compile int4 quant speculative decoding" combination to achieve 240 tok/s. On Llama-70B, this paper also introduces tensor parallelism to achieve about 80 tok/s, which are close to or exceed SOTA performance. Original link: https://pytorch.org/blog/accelerating-generative-ai-2/The above is the detailed content of With less than 1,000 lines of code, the PyTorch team made Llama 7B 10 times faster. For more information, please follow other related articles on the PHP Chinese website!






















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



