


Today, I would like to share with you the common unsupervised learning clustering methods in machine learning
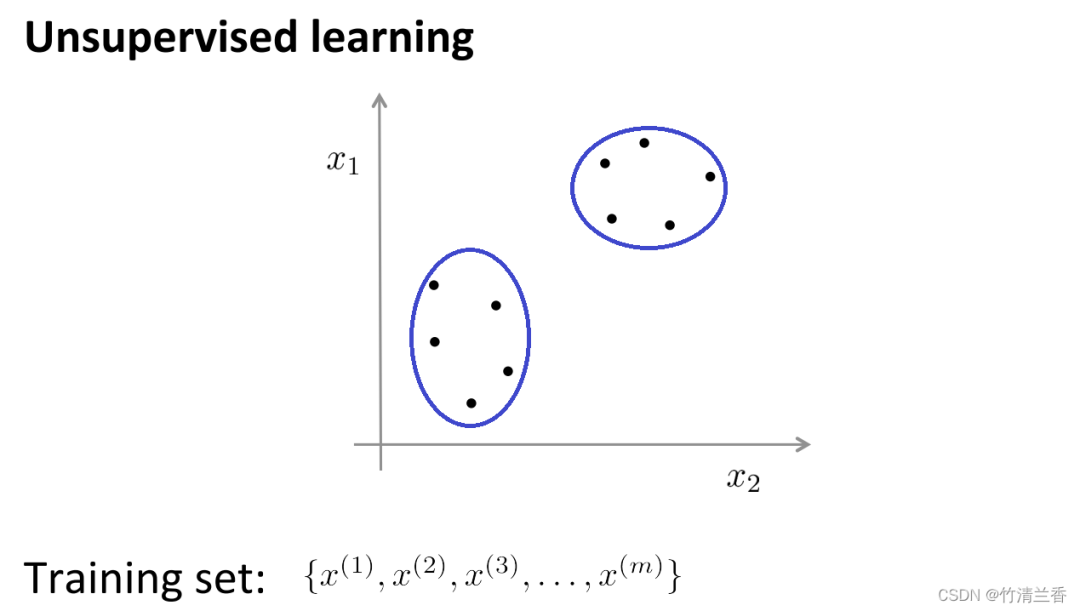
In unsupervised learning, our data does not carry any labels, so there is no need to What needs to be done in supervised learning is to input this series of unlabeled data into the algorithm, and then let the algorithm find some structures hidden in the data. Through the data in the figure below, one of the structures that can be found is the point in the data set. It can be divided into two separate sets of points (clusters), and the algorithm that can circle these clusters (cluster) is called a clustering algorithm.
The goal of cluster analysis is to divide observations into groups ("clusters") such that pairwise differences between observations assigned to the same cluster tend to be smaller than those that are different The difference between observations in a cluster. Clustering algorithms are divided into three different types: combinatorial algorithms, hybrid modeling, and pattern search.
The K-means algorithm is currently one of the most popular clustering methods.
K-means was proposed by Stuart Lloyd of Bell Labs in 1957. It was initially used for pulse code modulation. It was not until 1982 that the algorithm was announced to the public. In 1965, Edward W. Forgy published the same algorithm, so K-Means is sometimes called Lloyd-Forgy.
Clustering problems usually require processing a set of unlabeled data sets, and require an algorithm to automatically divide these data into closely related subsets or clusters. Currently, the most popular and widely used clustering algorithm is the K-means algorithm
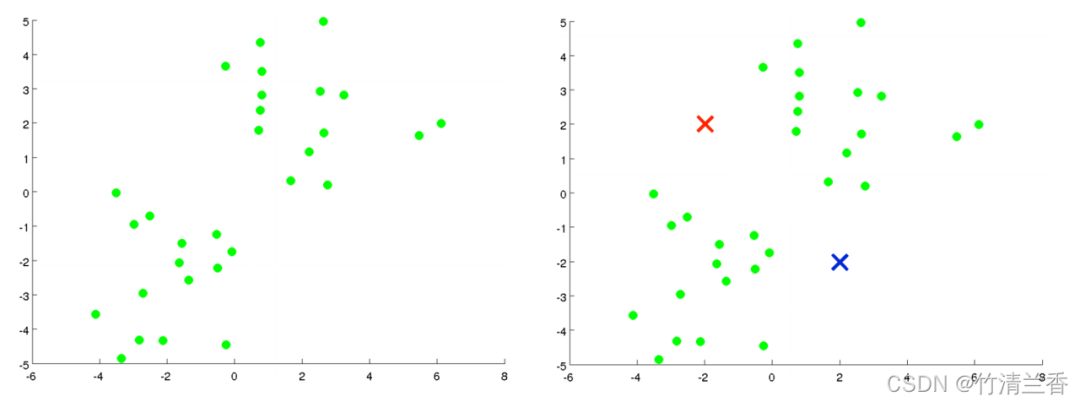
Suppose there is an unlabeled data set (left in the figure above) and we want to divide it into two clusters. Now execute the K-means algorithm. The specific operations are as follows:
The first step in the inner loop is to perform cluster assignment, that is, traverse each sample, and then assign each point according to its distance from the cluster center. Assigning to different cluster centers (which ones are closer to each other), in this case, is to traverse the data set and color each point red or blue.
The second step of the inner loop is to move the cluster center so that the red and blue cluster centers move to the average positions of the points they belong to
Assign all points to new clusters based on their distance from the new cluster center, and continue to cycle this process until the position of the cluster center no longer changes with iteration, and the color of the points also changes. No more changes. At this time it can be said that K-means has completed aggregation. This algorithm does a pretty good job of finding two clusters in the data

Simple and easy to understand, fast calculation speed, and suitable for large-scale data sets.
Hierarchical clustering is the operation of clustering sample sets according to a certain level. The level here actually refers to the definition of a certain distance
The ultimate purpose of clustering is to reduce the number of classifications, so the behavior is similar to gradually approaching from the leaf node to the root node The dendrogram process, this behavior is also called "bottom-up"
More popularly, hierarchical clustering treats the initialized multiple clusters as tree nodes , each iteration step is to merge two similar clusters into a new large cluster, and so on, until finally only one cluster (root node) remains.
Hierarchical clustering strategies are divided into two basic paradigms: aggregation (bottom-up) and divisive (top-down).
The opposite of hierarchical clustering is divisive clustering, also known as DIANA (Divise Analysis), and its behavior process is "top-down"
The results of the K-means algorithm depend on the number of clusters chosen to search and the allocation of the starting configuration. In contrast, hierarchical clustering methods do not require such specification. Instead, they require the user to specify a measure of dissimilarity between (disjoint) groups of observations based on the pairwise dissimilarity between the two sets of observations. As the name suggests, hierarchical clustering methods produce a hierarchical representation in which clusters at each level are created by merging clusters at the next lower level. At the lowest level, each cluster contains one observation. At the highest level, there is only one cluster containing all the data
The rewritten content is: Agglomerative Clustering is a bottom-up clustering algorithm. Treat each data point as an initial cluster and gradually merge them to form larger clusters until the stopping condition is met. In this algorithm, each data point is initially treated as a separate cluster, and then clusters are gradually merged until all data points are merged into one large cluster
Modified content: Affinity Propagation Algorithm (AP) is usually translated as Affinity Propagation Algorithm or Proximity Propagation Algorithm
Affinity Propagation is a clustering algorithm based on graph theory designed to identify "exemplars" (representative points) and "clusters" (clusters) in data. Unlike traditional clustering algorithms such as K-Means, Affinity Propagation does not need to specify the number of clusters in advance, nor does it need to randomly initialize cluster centers. Instead, it obtains the final clustering result by calculating the similarity between data points.
Shifting clustering is a density-based non-parametric clustering algorithm. Its basic idea is to find the maximum density of data points. locations (called "local maxima" or "peaks") to identify clusters in the data. The core of this algorithm is to estimate the local density of each data point, and use the density estimation results to calculate the direction and distance of the movement of the data point
Bisecting K-Means is a hierarchical clustering algorithm based on the K-Means algorithm. Its basic idea is to combine all data The points are divided into a cluster, and then the cluster is divided into two sub-clusters, and the K-Means algorithm is applied to each sub-cluster respectively. This process is repeated until the predetermined number of clusters is reached.
The algorithm first treats all data points as an initial cluster, then applies the K-Means algorithm to the cluster, divides the cluster into two sub-clusters, and calculates the squared error of each sub-cluster and (SSE). Then, the subcluster with the largest sum of squared errors is selected and divided into two subclusters again, and this process is repeated until the predetermined number of clusters is reached.
Density-based spatial clustering algorithm DBSCAN (Density-Based Spatial Clustering of Applications with Noise) is a typical clustering algorithm with noise. Class method
The method of density has the characteristic that it does not depend on distance, but depends on density. Therefore, it can overcome the shortcoming that distance-based algorithms can only find "spherical" clusters
The core idea of the DBSCAN algorithm is: for a given data point, if its density If it reaches a certain threshold, it belongs to a cluster; otherwise, it is regarded as a noise point.
OPTICS (Ordering Points To Identify the Clustering Structure) is a density-based clustering algorithm that can automatically determine the number of clusters. At the same time, it can also discover clusters of any shape and can handle noisy data
The core idea of the OPTICS algorithm is to calculate the distance between a given data point and other points to determine its distance. reachability over density and construct a density-based distance graph. Then, by scanning this distance map, the number of clusters is automatically determined and each cluster is divided
BIRCH (Balanced Iterative Reduction and Hierarchical Clustering) is a clustering algorithm based on hierarchical clustering that can efficiently handle large scale data set, and can achieve good results for clusters of any shape
The core idea of the BIRCH algorithm is to gradually reduce the size of the data by hierarchically clustering the data set. , and finally the cluster structure is obtained. The BIRCH algorithm uses a structure similar to B-tree, called CF tree, which can quickly insert and delete sub-clusters and can be automatically balanced to ensure the quality and efficiency of the cluster
The above is the detailed content of Nine clustering algorithms to explore unsupervised machine learning. For more information, please follow other related articles on the PHP Chinese website!
 Introduction to the usage of vbs whole code
Introduction to the usage of vbs whole code
 How to switch between full-width and half-width
How to switch between full-width and half-width
 How to display two divs side by side
How to display two divs side by side
 Three commonly used encoding methods
Three commonly used encoding methods
 A complete list of idea shortcut keys
A complete list of idea shortcut keys
 c/s architecture and b/s architecture
c/s architecture and b/s architecture
 What is the difference between mysql and mssql
What is the difference between mysql and mssql
 What are the main functions of redis?
What are the main functions of redis?








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



