


What needs to be rewritten is: Understand the characteristics of supervised learning, unsupervised learning and semi-supervised learning, and how they are applied in machine learning projects

When discussing artificial intelligence technology, supervised learning is often the method that gets the most attention because it is usually the last step in creating an artificial intelligence model and can be used for image recognition, better predictions, Aspects such as product recommendations and lead scoring
In contrast, unsupervised learning tends to work behind the scenes early in the AI development life cycle: it is often used to provide a basis for supervised learning. The magic unfolds to lay the foundation, just like the grunt work that allows a manager to shine. As explained later, both machine learning models can be effectively applied to business problems.
On a technical level, the difference between supervised and unsupervised learning is whether the raw data used to create the algorithm is pre-labeled (supervised learning) or not (unsupervised learning) ).
Let’s get started
In supervised learning, data scientists provide the algorithm with labeled training data and define the variables they want the algorithm to evaluate for relevance
The input data and output variables of the algorithm are specified through the training data. For example, if you want to use supervised learning to train an algorithm to determine whether an image contains a cat, you can create a label for each image used in the training data to indicate whether the image contains a cat
As we explain in our definition of supervised learning: “[A] computer algorithm is trained on input data labeled for a specific output. The model is trained until it Ability to detect underlying patterns and relationships between input data and output labels, enabling it to produce accurate labeling results when presenting never-before-seen data. Common types of supervised algorithms include classification, decision trees, regression, and predictive modeling , which you can learn about in Arcitura Education's machine learning tutorials.
Supervised machine learning techniques are used in a variety of business applications, including the following:
In unsupervised learning, there is an algorithm suitable for this method (such as K-means clustering), which is on unlabeled data is trained. The algorithm scans the data set looking for any meaningful associations within it. In other words, unsupervised learning identifies patterns and similarities in the data rather than correlating them with some external measure
This approach is useful when you don’t know what you are looking for, but less useful when you do. If you show an unsupervised algorithm the number Thousands or millions of images, it might classify a subset of images that humans identify as felines. In contrast, supervised algorithms trained on labeled data of cats vs. canines can achieve a high degree of confidence can accurately identify images of cats. But this approach comes with a trade-off: If a supervised learning project requires millions of labeled images to develop a model, machine-generated predictions require a lot of human effort.
There is a middle ground: semi-supervised learning.
Semi-supervised learning is the combination of unsupervised learning and supervised learning An effective method of learning combination. It uses an unsupervised learning algorithm to automatically generate labels through a certain workflow, and then inputs these labels into the supervised learning algorithm. In this method, humans manually label some images, while unsupervised learning The algorithm guesses the labels of other images, and finally inputs all labels and images into the supervised learning algorithm to create an AI model
One benefit of semi-supervised learning is that it can reduce the cost of machine learning The cost of working with large-scale data sets. According to Aaron Kalb, co-founder and chief innovation officer of enterprise data catalog platform Alation, if humans can label 0.01% of millions of samples, computers can take advantage of them. tags to significantly improve its prediction accuracy
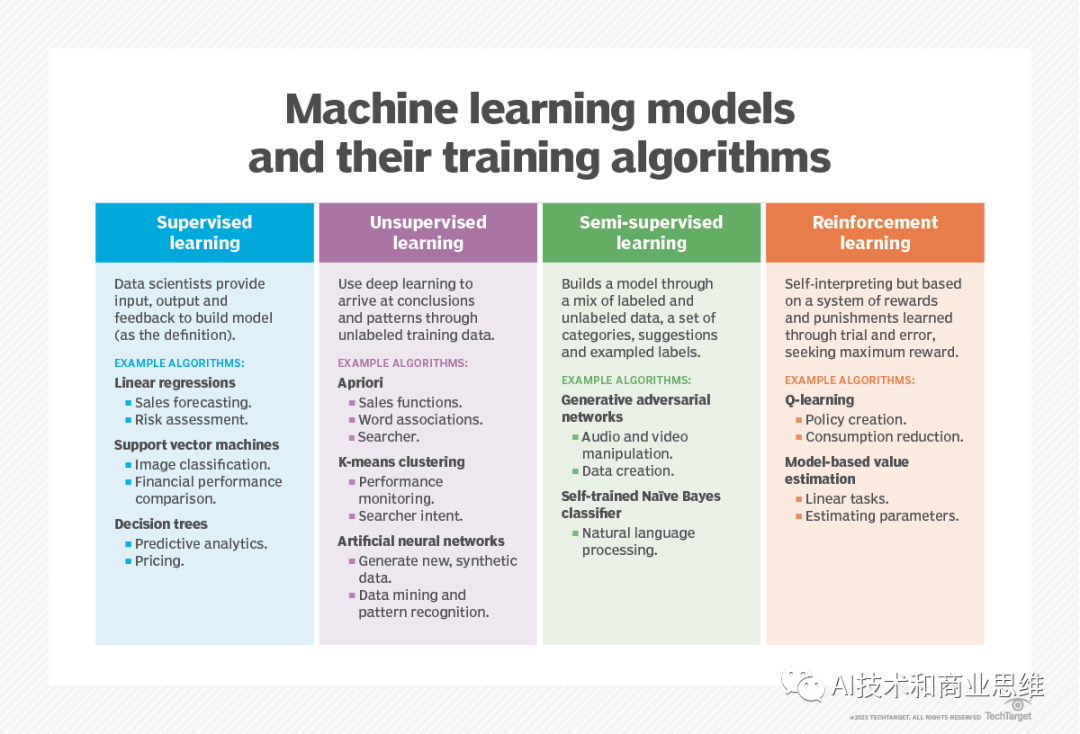
Another machine learning method is reinforcement learning. Reinforcement learning is typically used to teach a machine to complete a sequence of steps, and differs from supervised and unsupervised learning. Data scientists program algorithms to perform tasks, giving positive or negative cues or reinforcements when determining how to complete tasks. The programmer sets the rules for the reward, but lets the algorithm decide what steps it needs to take to maximize the reward to complete the task.
Shivani Rao, machine learning manager at LinkedIn, said best practices for taking a supervised or unsupervised machine learning approach often depend on the environment, the assumptions you can make about the data and the application.
The choice of using supervised versus unsupervised machine learning algorithms will also change over time, Rao said. In the early stages of the model building process, data is often unlabeled, while labeled data can emerge in later stages of modeling.
For example, for the problem of predicting whether LinkedIn members will watch course videos, the first model uses unsupervised techniques. After these suggestions are provided, a metric that records whether someone clicks on the suggestion will provide new data to generate the tag
LinkedIn also uses this technique to tag skills that students may want to acquire. online courses. Human taggers, such as authors, publishers, or students, can provide a precise and accurate list of skills taught in a course, but they are unlikely to provide an exhaustive list of such skills. Therefore, these data labels can be considered incomplete. These types of problems can use semi-supervised techniques to help build a more exhaustive set of labels.
Bharath Thota, an expert in data science and advanced analytics and a partner at consulting firm Kearney, said his team chose to use supervised learning or When doing unsupervised learning, practical factors are often taken into consideration.
Thota said: "We choose supervised learning as the application when there is available labeled data, with the goal of predicting or classifying future observations. When there is no labeled data available, We use unsupervised learning and the goal is to develop strategies by identifying patterns or snippets from the data.” Kalb said Alation data scientists use unsupervised learning internally for a variety of applications program. For example, they developed a collaborative human-machine process for translating obscure data object names into human language—for example, “na_gr_rvnu_ps” into “North American total professional services revenue.” In this case, machine guesses, humans confirm, machine learning
"You can think of it as semi-supervised learning in an iterative loop, creating a virtuous cycle of improved accuracy ," Kalb said.
5 Unsupervised Learning Techniques
Unsupervised learning techniques often employ multiple ways of slicing and dicing the original data set to supplement supervision Learning works in these ways including:
Data clustering.
Data points with similar characteristics are grouped together to help understand and explore the data more effectively. For example, a company might use data clustering methods to segment customers into groups based on their demographics, interests, purchasing behaviors, and other factors.Dimensionality reduction.
Each variable in the dataset is treated as a separate dimension. However, many models work better by analyzing specific relationships between variables. A simple example of dimensionality reduction is using profit as a single dimension, which Represents income minus expenses—two separate dimensions. However, new, more complex variable types can be generated using algorithms such as principal component analysis, autoencoders, algorithms that convert text into vectors, or T-distributed stochastic neighborhood embedding.Dimensionality reduction can help reduce the problem of overfitting, in which a model works well for small data sets but does not generalize well to new data. The technique also enables companies to model models in 2D or 3D Forms visualize high-dimensional data that humans can easily understand.
# Anomaly or outlier detection.
Transfer learning. These algorithms utilize models trained on related but different tasks. For example, transfer learning techniques make it easy to fine-tune a classifier trained on Wikipedia articles to label any type of new text with the correct topics. LinkedIn’s Rao says this is one of the most effective and quickest ways to solve the problem of unlabeled data. Graph-based algorithm. These techniques try to build a graph that captures the relationship between data points, Rao said. For example, if each data point represents a LinkedIn member with a skill, you can represent the members using a graph, where edges represent skill overlap between members. Graph algorithms can also help transfer labels from known data points to unknown but closely related data points. Unsupervised learning can also be used to build graphs between different types of entities (sources and targets). The stronger the edge, the higher the affinity of the source node to the target node. For example, LinkedIn uses them to match members with skills-based courses.
The above is the detailed content of Supervised vs. unsupervised learning: Experts define the gap. For more information, please follow other related articles on the PHP Chinese website!
 Application of artificial intelligence in life
Application of artificial intelligence in life
 What is the basic concept of artificial intelligence
What is the basic concept of artificial intelligence
 vbnet tutorial
vbnet tutorial
 Common color hexadecimal codes
Common color hexadecimal codes
 Why can't the Himalayan connect to the Internet?
Why can't the Himalayan connect to the Internet?
 Why is there no sound in Tencent meetings?
Why is there no sound in Tencent meetings?
 InvocationTargetException exception handling
InvocationTargetException exception handling
 How to use RealVNC
How to use RealVNC








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



