


From the beginning of the year to now, generative AI has developed rapidly. But many times, we have to face a difficult problem: how to speed up the training, reasoning, etc. of generative AI, especially when using PyTorch.
In this article, researchers from the PyTorch team provide us with a solution. The article focuses on how to use pure native PyTorch to accelerate generative AI models. It also introduces new PyTorch features and practical examples of how to combine them.
What is the result? The PyTorch team said they rewrote Meta's "Split Everything" (SAM) model, resulting in code that is 8 times faster than the original implementation without losing accuracy, all optimized using native PyTorch.

Blog address: https://pytorch.org/blog/accelerating-generative-ai/
After reading this article, you will gain the following understanding:
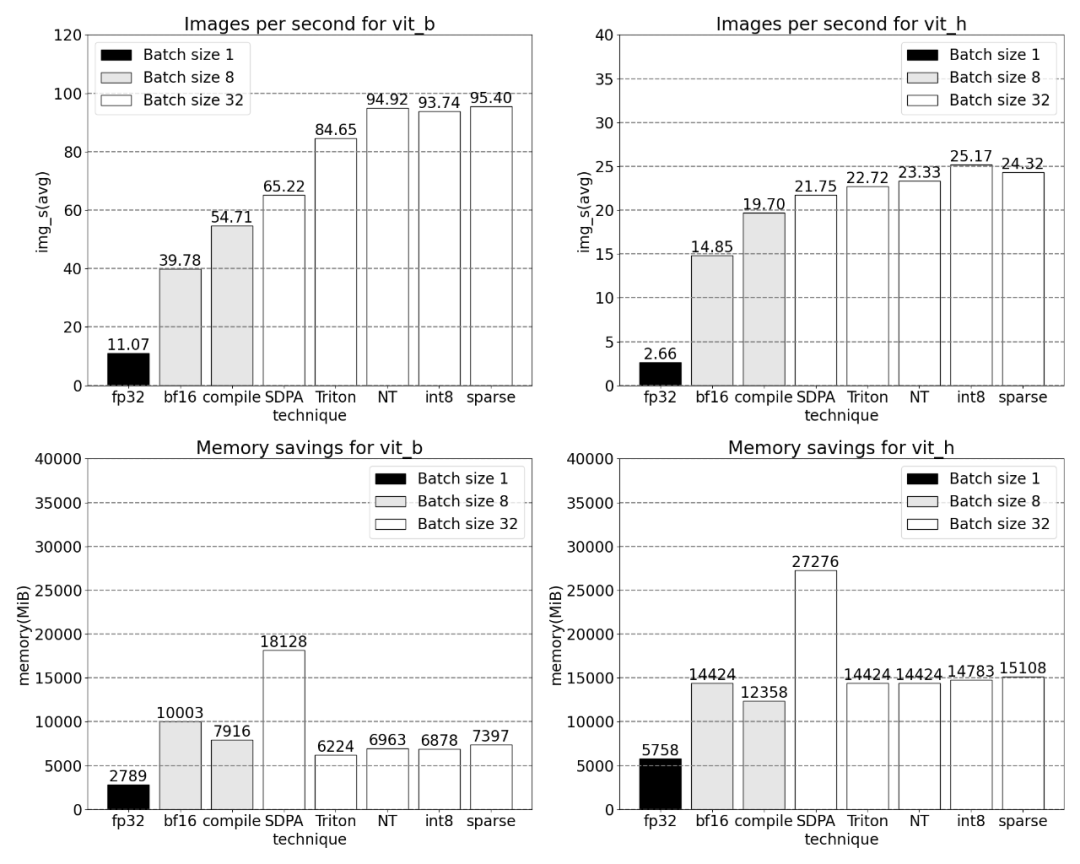
Increased throughput and reduced memory overhead brought about by PyTorch’s native features.
For more information about this research, please refer to the SAM proposed by Meta. Detailed articles can be found in "CV no longer exists? Meta releases "Split Everything" AI model, CV may usher in GPT-3 moment"

Next, we will introduce the SAM optimization process, including performance analysis, bottleneck identification, and how to integrate these new features into PyTorch to solve the problems faced by SAM. In addition, we will also introduce some new features of PyTorch, including torch.compile, SDPA, Triton kernels, Nested Tensor and semi-structured sparsity (semi-structured sparsity)
content step by step Going deeper, this article will introduce the fast version of SAM at the end. For interested readers, you can download it from GitHub. In addition, these data were visualized using Perfetto UI to demonstrate the application value of various features of PyTorch
GitHub address: https://github.com/pytorch-labs/segment The source code for this project can be found at -anything-fast
The study points out that the The SAM baseline data type is float32 dtype, the batch size is 1, and the results of using PyTorch Profiler to view the core tracing are as follows:
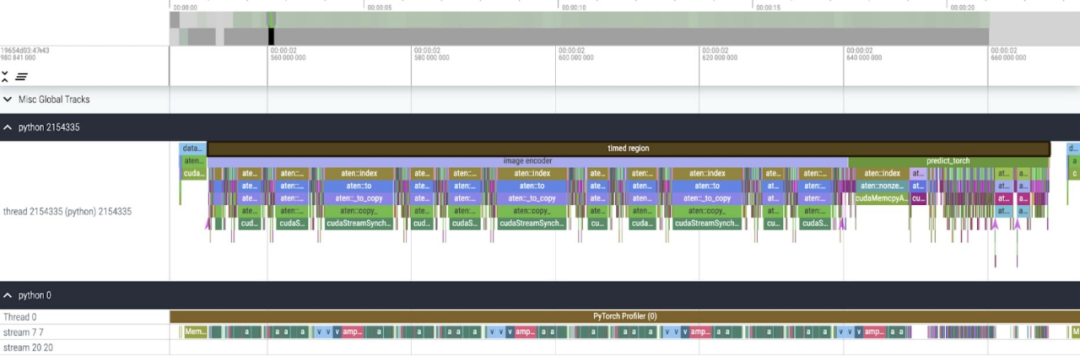
This article found that SAM has two places that can be optimized:
The first is the long call to aten::index, which is performed by the tensor index operation (such as []) Caused by the underlying calls generated. However, the actual time the GPU spends on aten::index is relatively low. The reason is that during the process of starting two cores, aten::index blocks cudaStreamSynchronize between the two. This means that the CPU waits for the GPU to finish processing until the second core is launched. Therefore, in order to optimize SAM, this paper believes that one should strive to eliminate blocking GPU synchronization that causes idle time.
The second problem is that SAM spends a lot of GPU time in matrix multiplication (dark green part as shown in the picture), which is very common in Transformers model. If we can reduce the GPU time of the SAM model on matrix multiplication, then we can significantly improve the speed of SAM
Next, we will take the throughput of SAM (img/s ) and memory overhead (GiB) to establish a baseline. Then there is the optimization process
The sentence that needs to be rewritten is: Bfloat16 half precision (plus GPU synchronization and Batch processing)
#In order to solve the above problem, that is, to reduce the time required for matrix multiplication, this article turns to bfloat16. bfloat16 is a commonly used half-precision type. By reducing the precision of each parameter and activation, it can save a lot of computing time and memory

##Replace fill type with bfloat16
In addition, this article found that there are two places that can be optimized to remove GPU synchronization


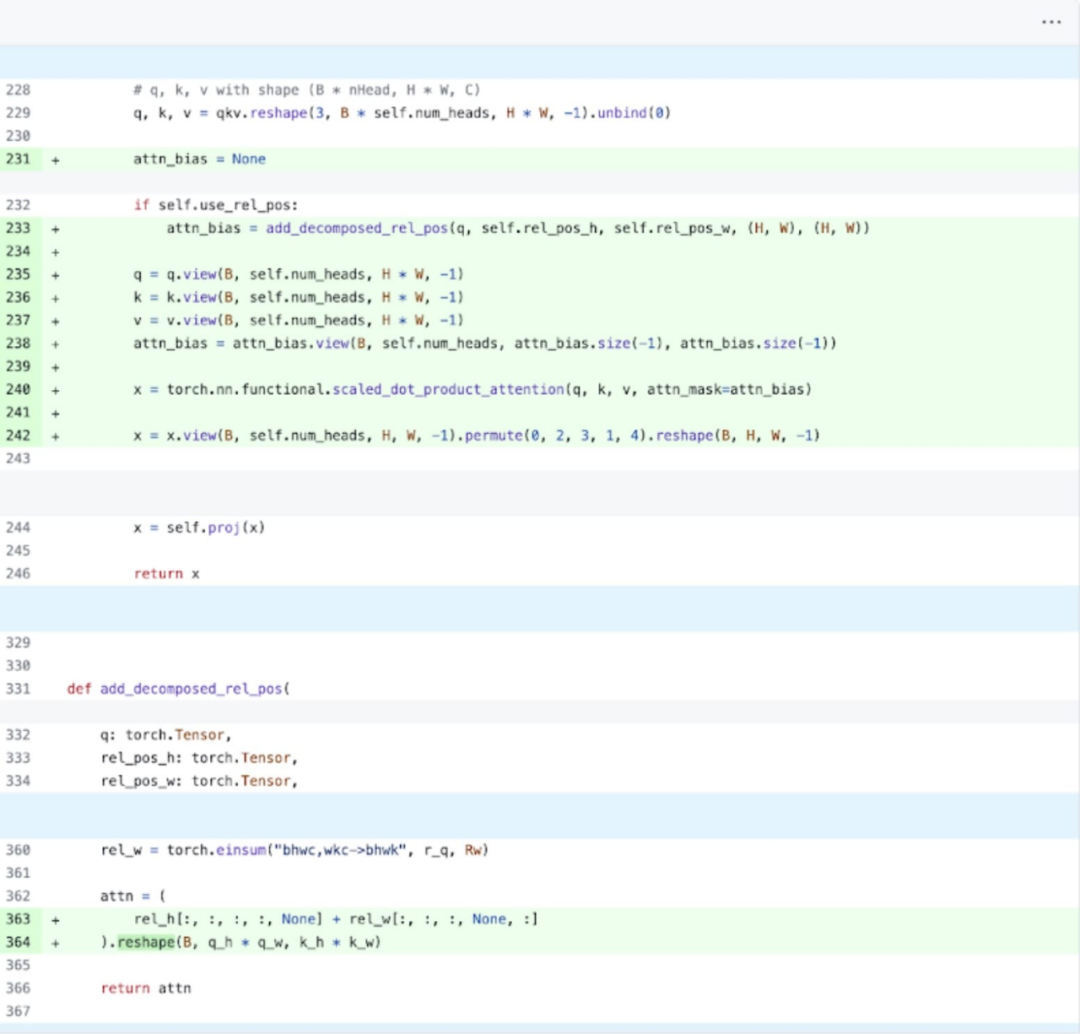
Specifically, it is easier to understand based on the picture above, the study found In the SAM image encoder, there are two variables q_coords and k_coords that act as coordinate scalers, and these variables are allocated and processed on the CPU. However, once these variables are used to index in rel_pos_resized, the indexing operation automatically moves these variables to the GPU, causing GPU synchronization issues. In order to solve this problem, the research pointed out that this part can be rewritten using the torch.where function to solve the problem, as shown above
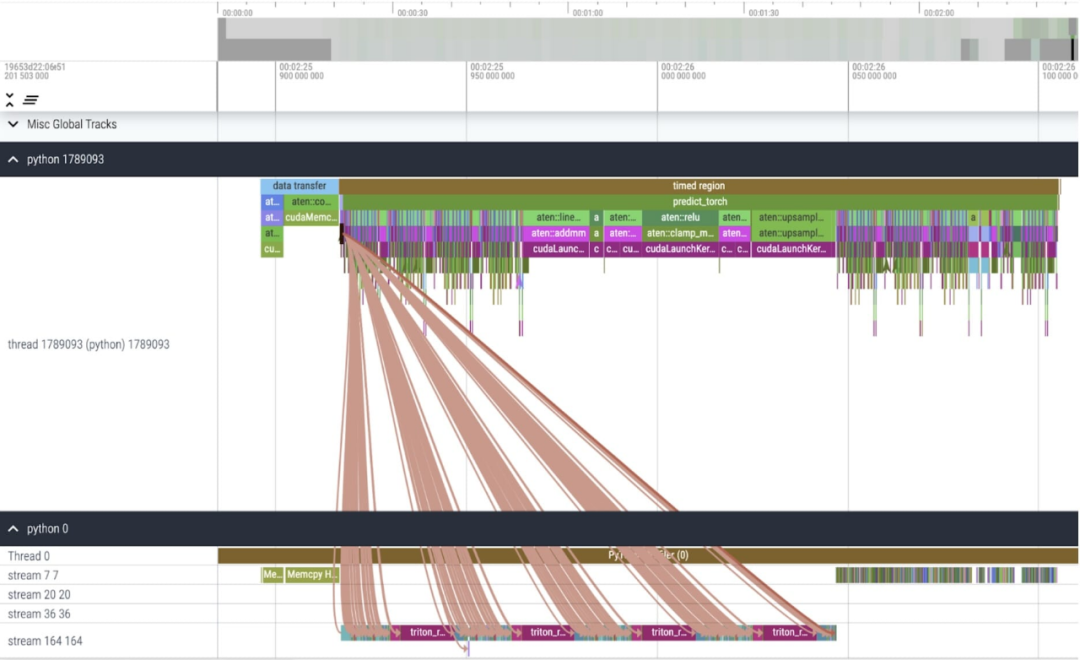
Core Tracking
After applying these changes, we noticed that there was a noticeable time gap between individual kernel calls, especially with small batch sizes (here 1). To gain a deeper understanding of this phenomenon, we begin performance analysis of SAM inference with a batch size of 8
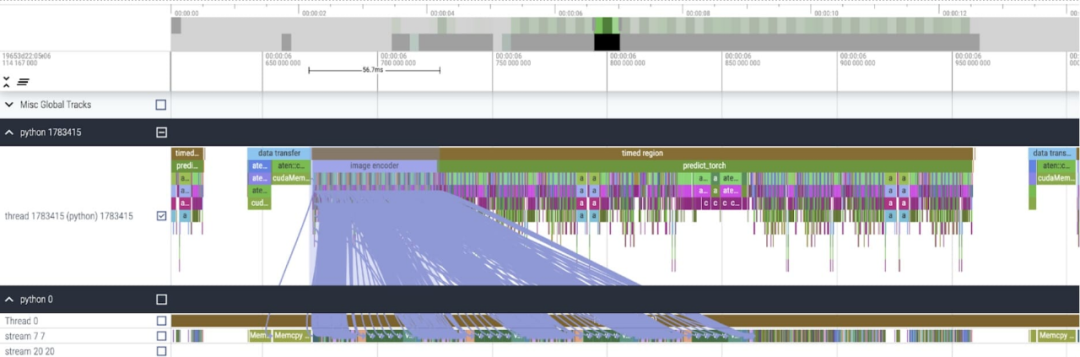
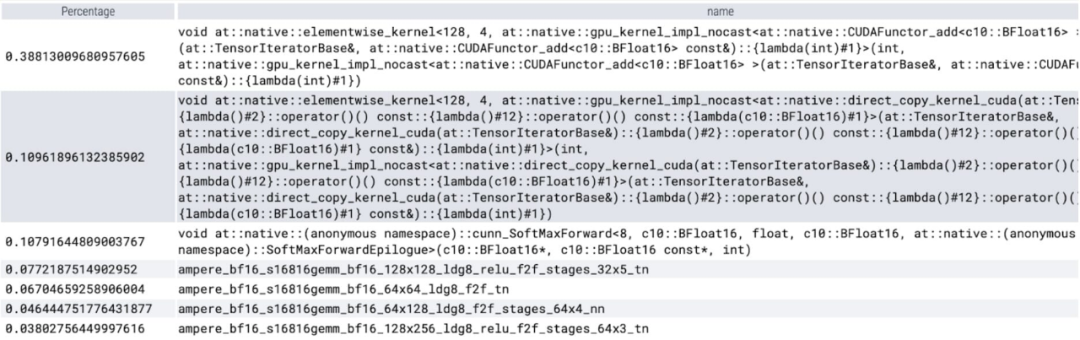
at When analyzing the time spent per kernel, we notice that most of the GPU time for SAM is spent on element-wise kernels and softmax operations
#We can now see the relative small overhead of matrix multiplication A lot.
Combining GPU synchronization and bfloat16 optimization, SAM performance is improved by 3x.
Discovered during the study of SAM Many small operations were performed. Researchers believe that using a compiler to integrate these operations is very beneficial, so PyTorch made the following optimizations to torch.compile
Through these optimizations, the research reduced the number of GPU global memory roundtrips, thereby speeding up inference. We can now try torch.compile on SAM’s image encoder. To maximize performance, this article uses some advanced compilation techniques:

Core Tracking
## According to the results, torch.compile performs very well
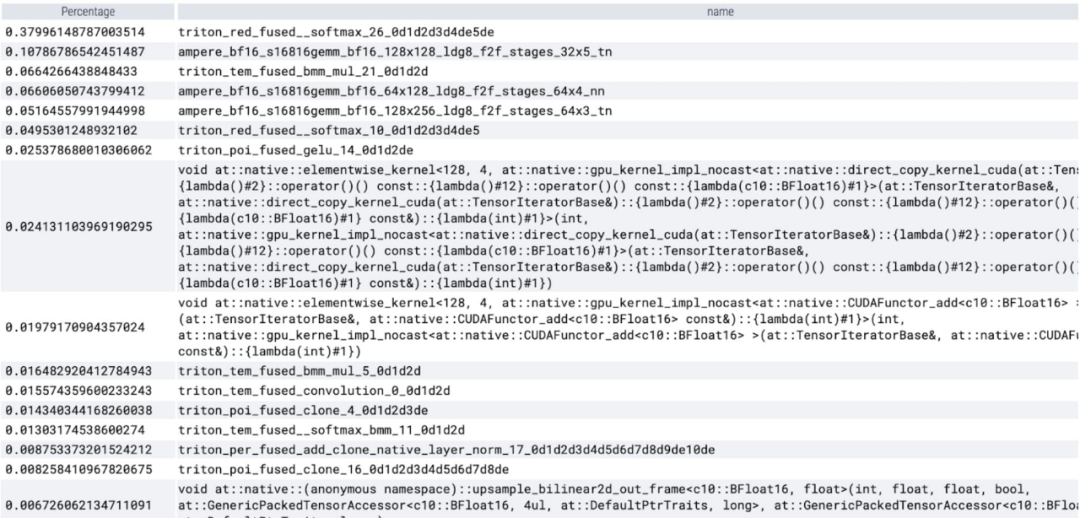
It can be observed that softmax takes up a large part of the time, followed by various GEMM variants . The following measurements are for batch sizes of 8 and above.
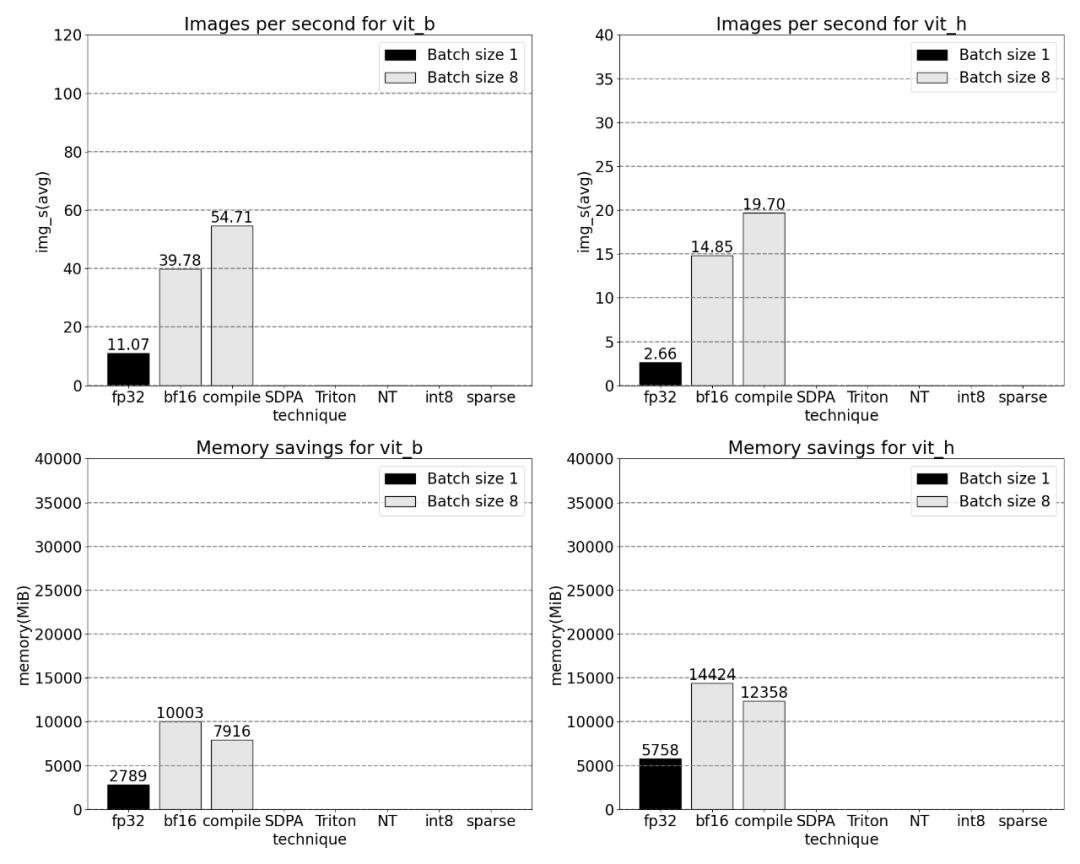
Core Tracking
Now available to watch The memory-efficient attention kernel takes up a lot of computation time on the GPU:
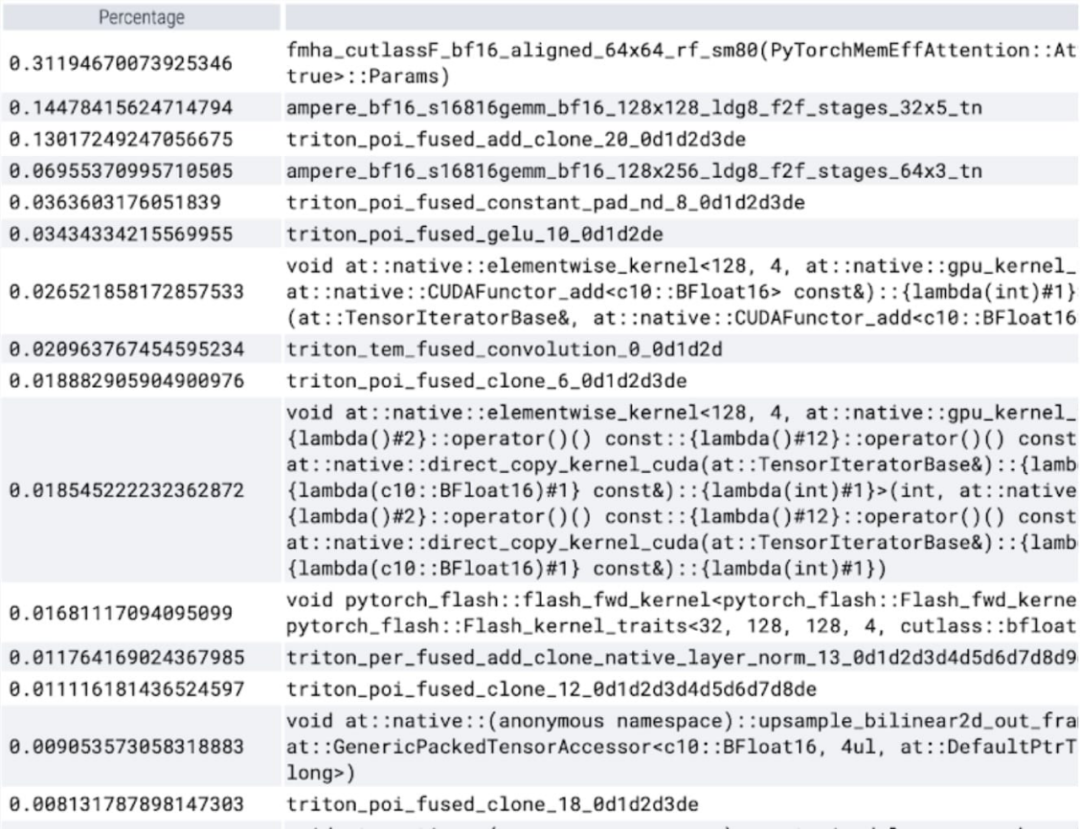
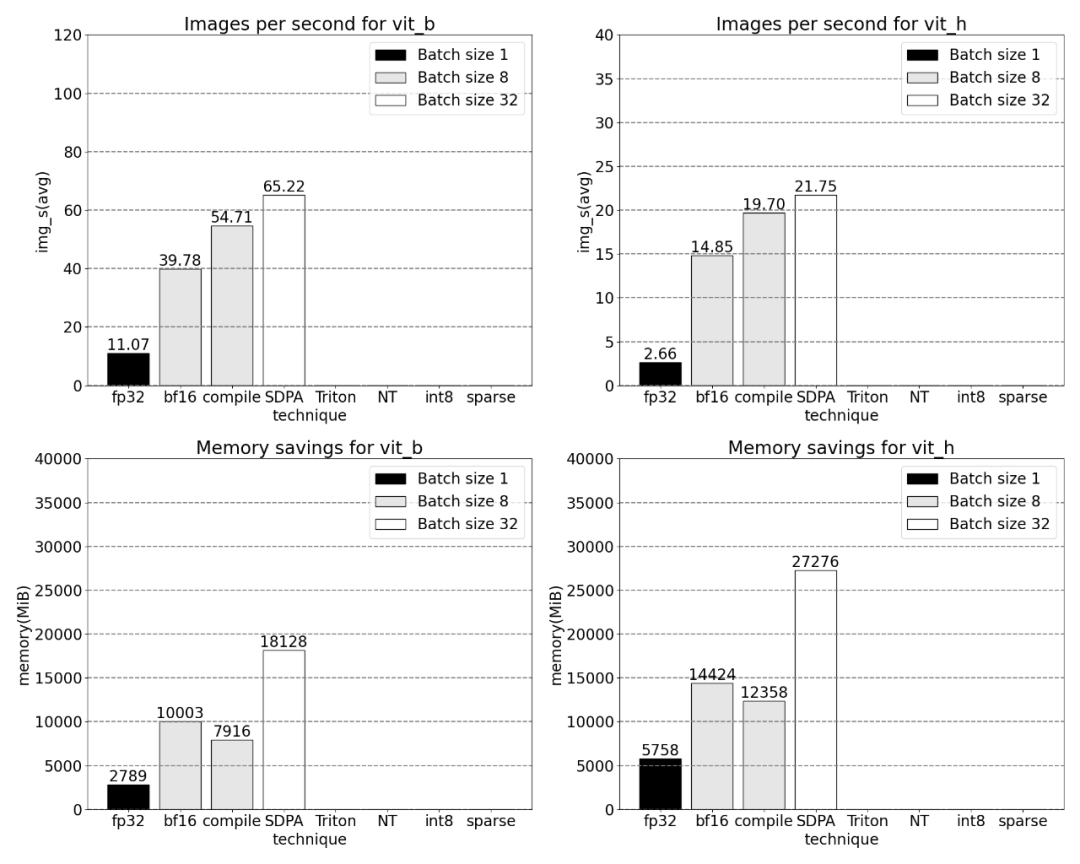
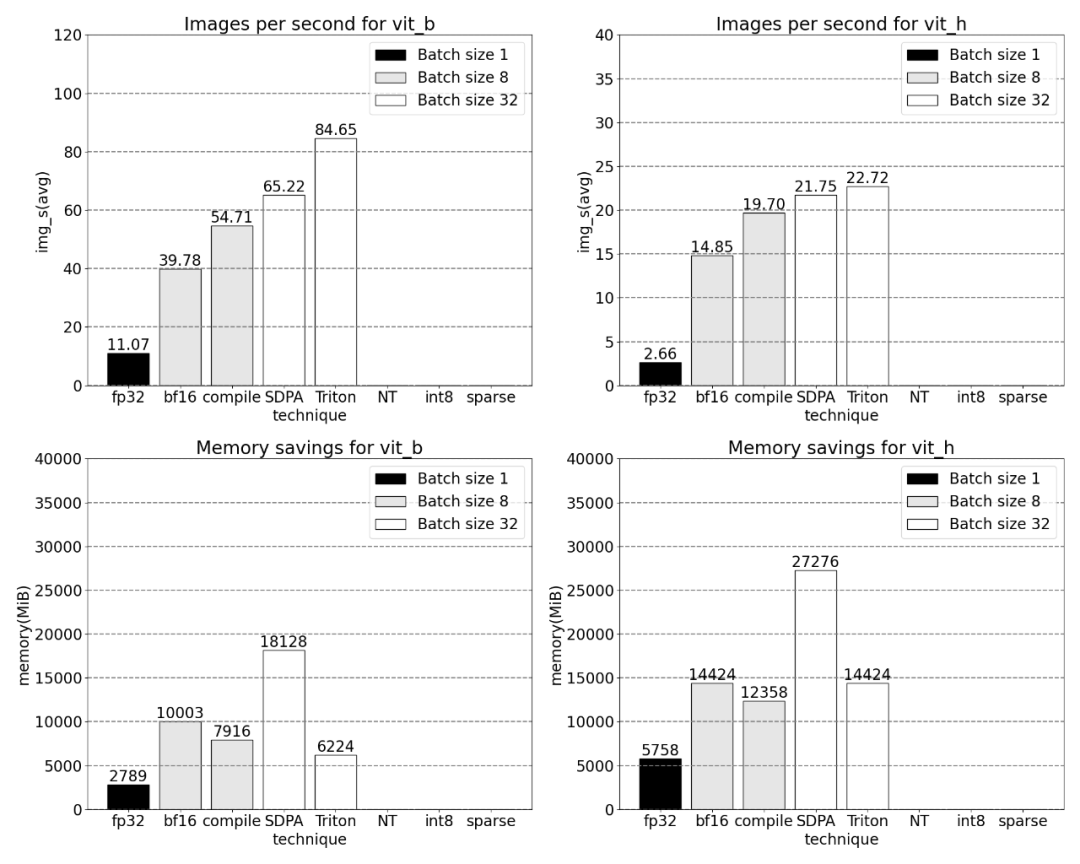
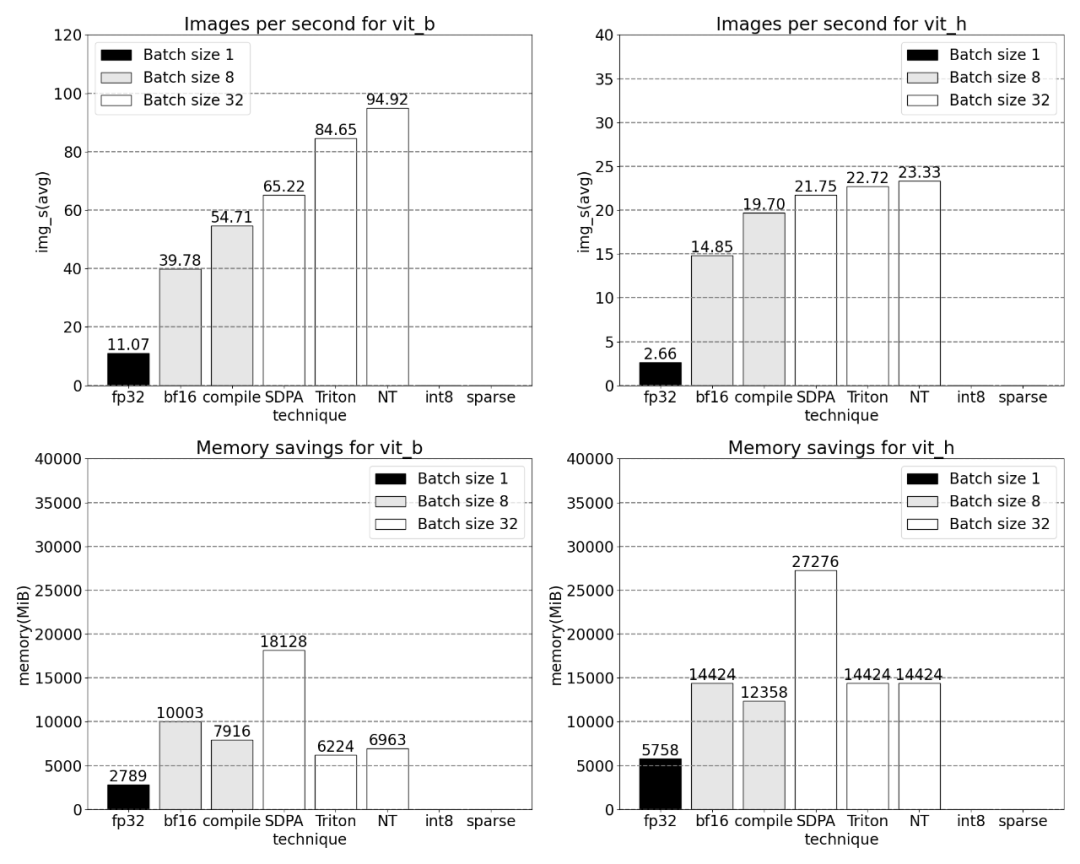
##Using PyTorch’s native scaled_dot_product_attention, batch sizes can be significantly increased. The graph below shows the changes for batch sizes of 32 and above.
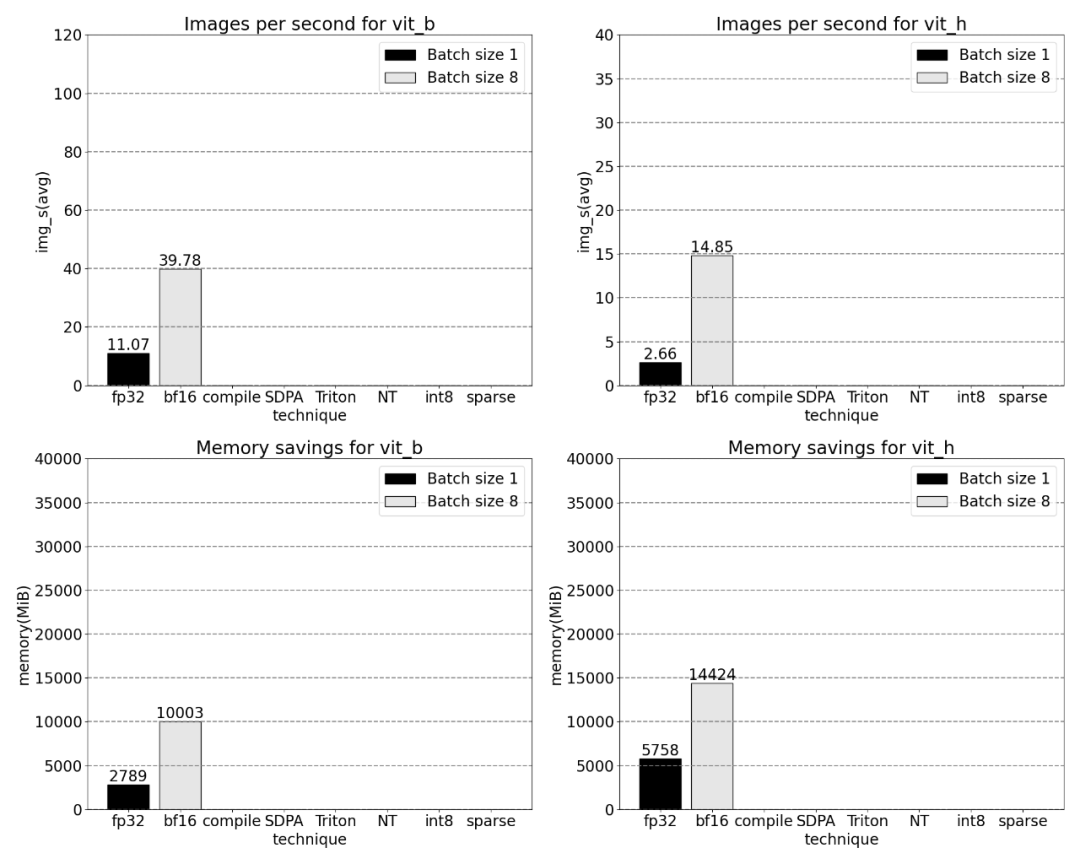
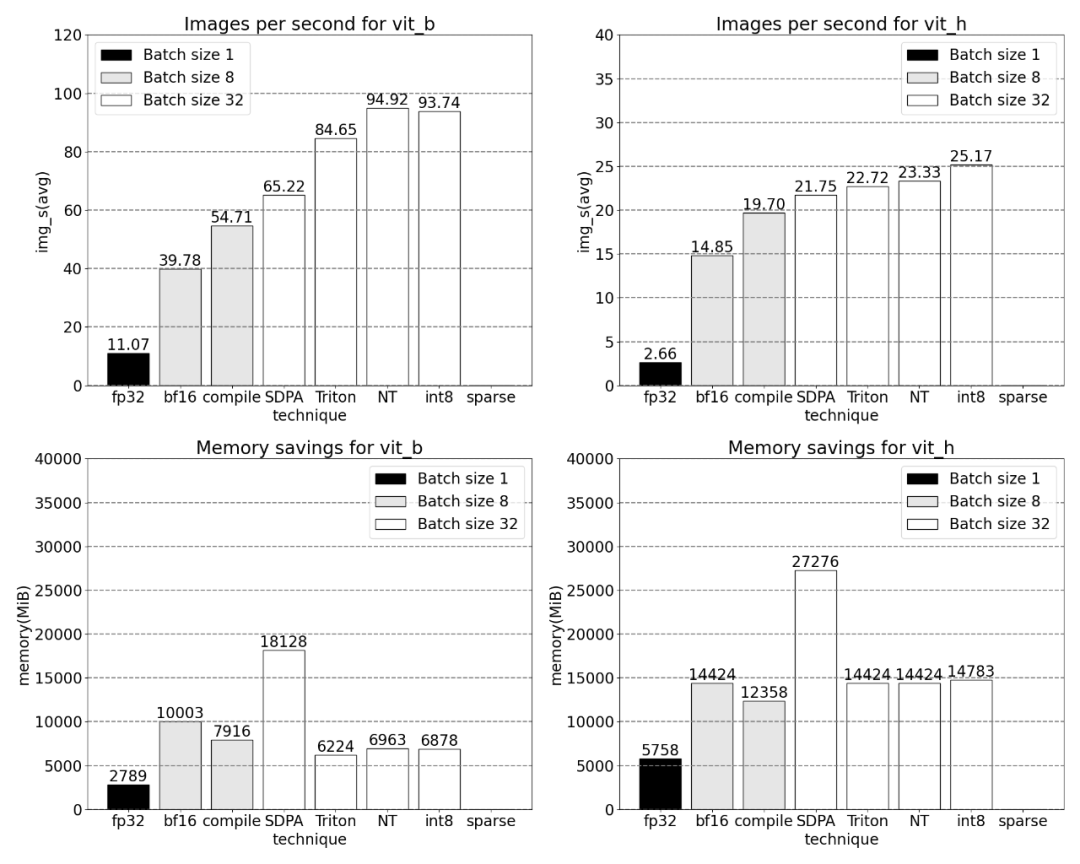
###############Next, the study was conducted on Triton, NestedTensor, batch Predict_torch, int8 quantization, semi-structured (2:4) sparsity Experiments on other operations############For example, this article uses a custom positional Triton kernel and observes measurement results with a batch size of 32. #####################Adopt Nested Tensor technology and adjust the batch size to 32 and above################ #####After adding quantization, the measurement results vary with batch size of 32 and above. ######################The end of the article is semi-structured sparsity. The study shows that matrix multiplication is still a bottleneck that needs to be faced. The solution is to use sparsification to approximate matrix multiplication. By sparse matrices (i.e. zeroing out the values) fewer bits can be used to store weights and activation tensors. The process of setting which weights in a tensor is set to zero is called pruning. Pruning out smaller weights can potentially reduce model size without significant loss of accuracy. ######There are many ways to prune, ranging from completely unstructured to highly structured. While unstructured pruning theoretically has minimal impact on accuracy, in the sparse case the GPU may experience significant performance degradation, despite being very efficient when doing large dense matrix multiplications. One pruning method recently supported by PyTorch is semi-structured (or 2:4) sparsity, which aims to find a balance. This sparse storage method reduces the original tensor by 50% while producing a dense tensor output. Please refer to the figure below for explanation
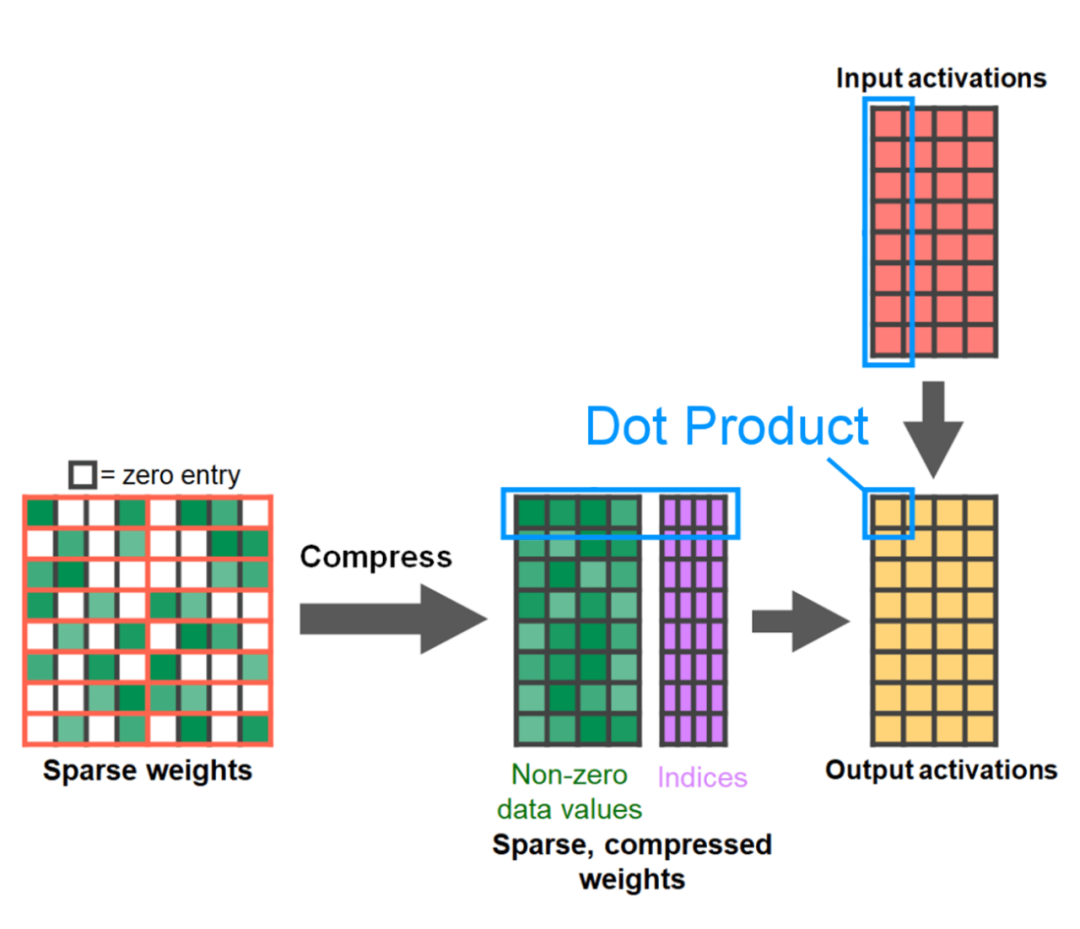
In order to use this sparse storage format and the associated fast kernel, the next thing to do is to prune the weights. This article selects the smallest two weights for pruning at a sparsity of 2:4. Changing the weights from the default PyTorch ("strided") layout to this new semi-structured sparse layout is easy. To implement apply_sparse (model), only 32 lines of Python code are needed:
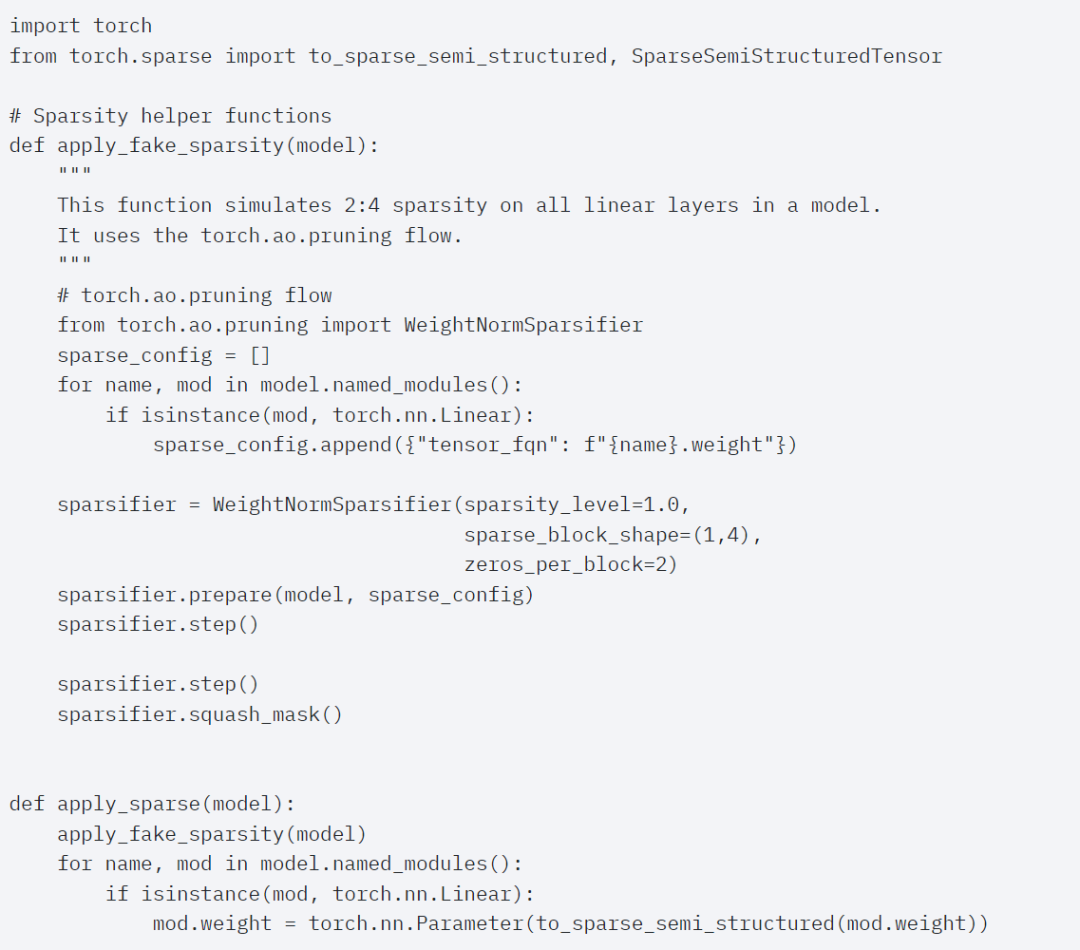
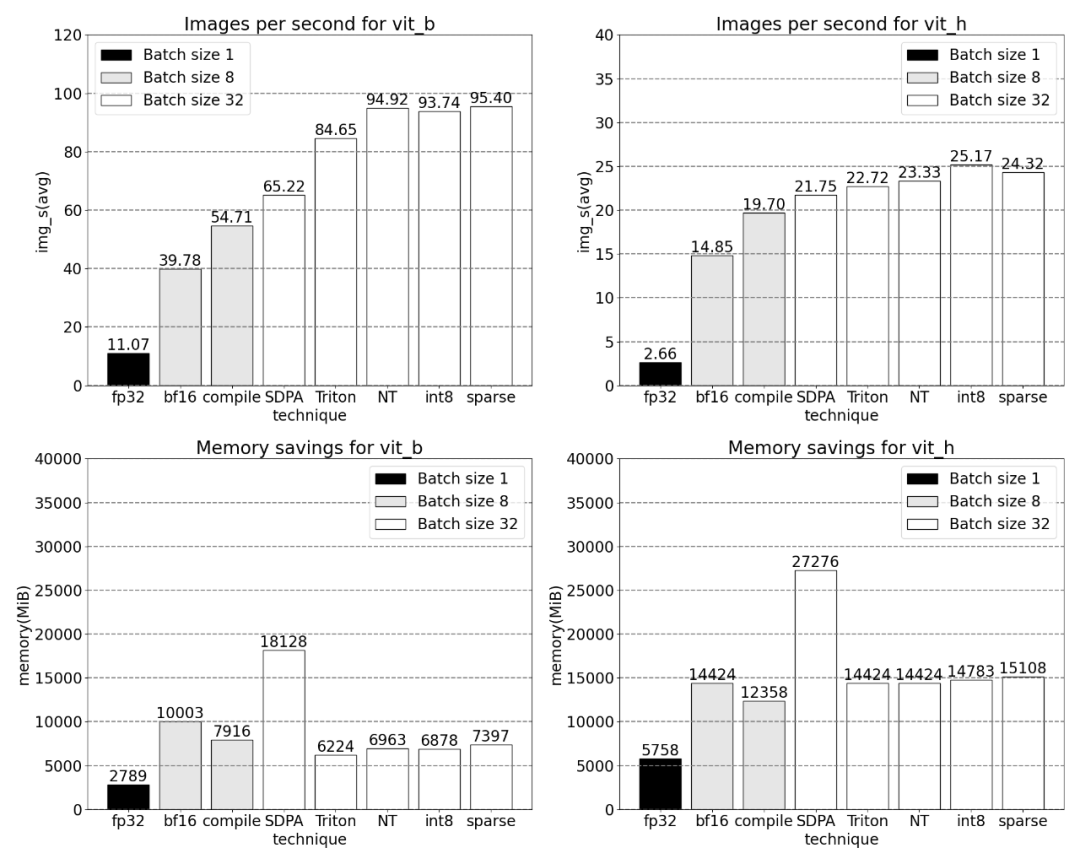
When the sparsity is 2:4, we observe that vit_b and SAM peak performance with batch size 32
Finally, the summary of this article is as follows: This article describes the implementation on PyTorch so far The fastest way to Segment Anything, with the help of a series of officially released new features, this article rewrites the original SAM in pure PyTorch without losing accuracy
For interested readers , you can check the original blog for more information
The above is the detailed content of The PyTorch team re-implemented the 'split everything” model eight times faster than the original implementation. For more information, please follow other related articles on the PHP Chinese website!
 How to restore videos that have been officially removed from Douyin
How to restore videos that have been officially removed from Douyin
 js method to generate random numbers
js method to generate random numbers
 How high will Ethereum go?
How high will Ethereum go?
 How to recover deleted files on computer
How to recover deleted files on computer
 How many years do you have to pay for medical insurance to enjoy lifelong medical insurance?
How many years do you have to pay for medical insurance to enjoy lifelong medical insurance?
 What to do if there is no cursor when clicking on the input box
What to do if there is no cursor when clicking on the input box
 What should I do if English letters appear when I turn on the computer and the computer cannot be turned on?
What should I do if English letters appear when I turn on the computer and the computer cannot be turned on?
 How to create virtual wifi in win7
How to create virtual wifi in win7








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



