


GPT-4’s graphical reasoning ability is less than half that of humans?
A study by the Santa Fe Research Institute in the United States shows that GPT-4’s accuracy in graphical reasoning questions is only 33%.
GPT-4v has multi-modal capabilities, but its performance is relatively poor. It can only answer 25% of the questions correctly
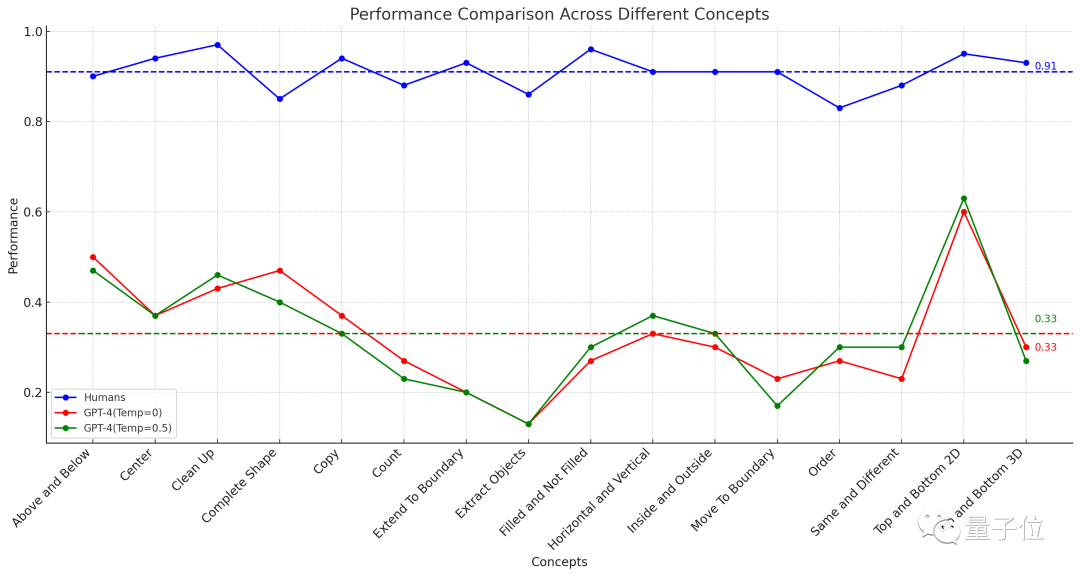
△Dotted line indicates Average performance of 16 tasks
As soon as the results of this experiment were released, they immediately caused extensive discussion on YC
Some netizens who supported this result said that GPT is indeed good at processing abstract graphics. Poor performance, and it is more difficult to understand concepts such as "position" and "rotation"

However, some netizens expressed doubts about this conclusion, and their views can be simply summarized as :
Although this view cannot be said to be wrong, it cannot be completely convincing

As for the specific reasons, we Read on.
In order to evaluate the performance of humans and GPT-4 on these graphics problems, the researchers used the ConceptARC data set launched in May this year
ConceptARC includes a total of 16 subcategories of graphical reasoning questions, with 30 questions in each category, for a total of 480 questions.

These 16 subcategories include positional relationships, shapes, operations, comparisons, etc.
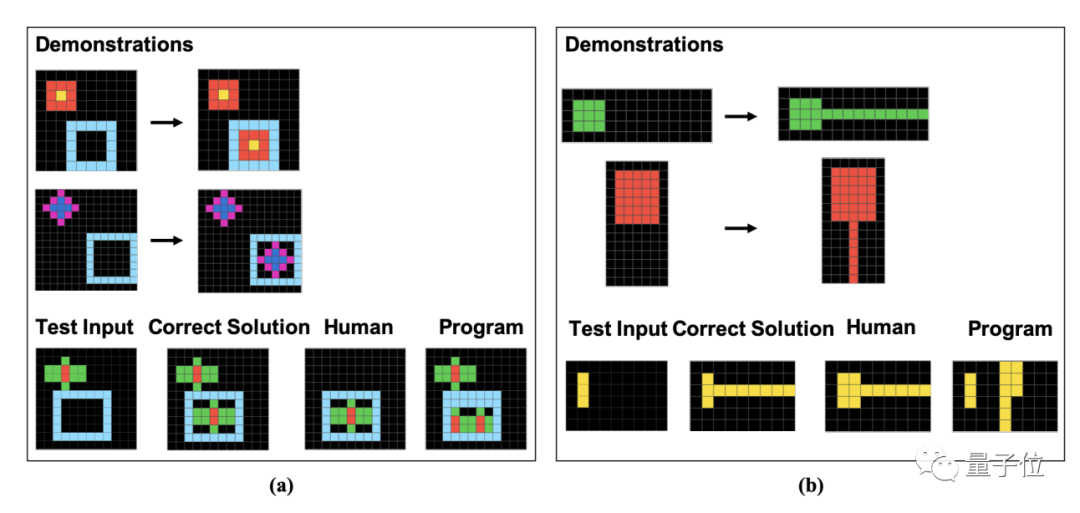
Specifically, these questions are composed of Made up of pixel blocks. Humans and GPT need to find patterns based on given examples and analyze the results of images processed in the same way
The author specifically shows examples of these 16 subcategories in the paper, one for each category.



The results showed that the average accuracy rate of 451 human subjects was no less than 83% in each sub-item. Taking the average of 16 tasks, it reaches 91%.
In the case where a question can be tried three times (if it is correct once, it is correct), the highest accuracy of GPT-4 (single sample) does not exceed 60%, and the average is only 33%
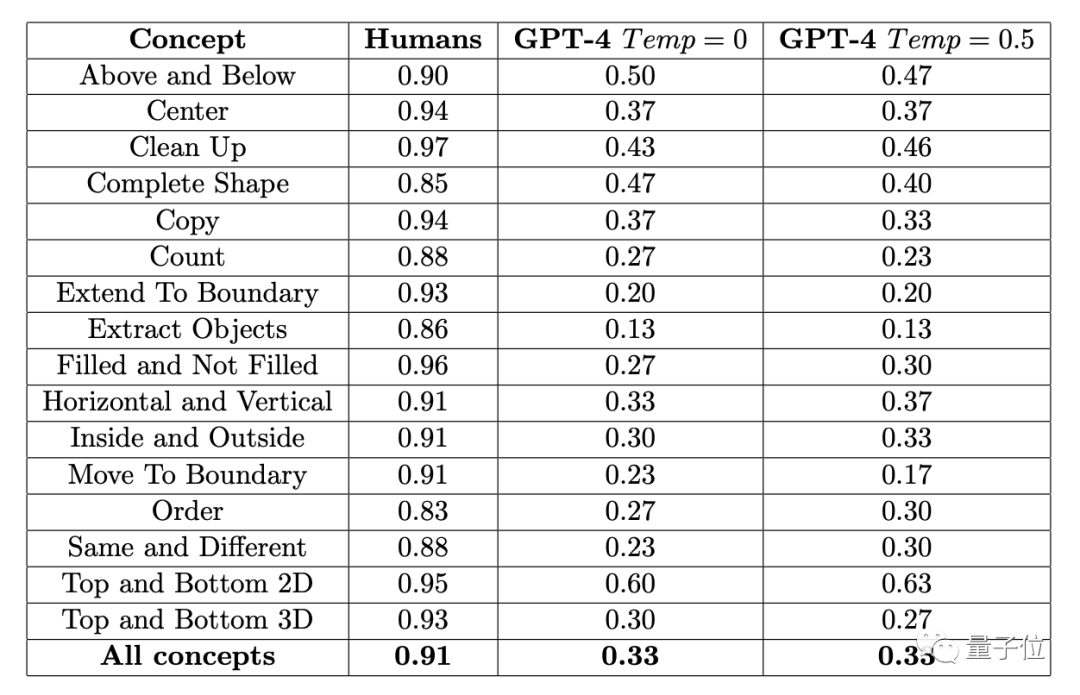
Earlier, the author of ConceptARC Benchmark involved in this experiment also conducted a similar experiment, but in GPT-4 it was zero sample Test, the average accuracy rate of 16 tasks is only 19%.

GPT-4v is a multi-modal model, but its accuracy is low. On a small-scale ConceptARC data set consisting of 48 questions, the accuracy rates of zero-sample testing and single-sample testing were only 25% and 23% respectively.

And the researchers After further analyzing the wrong answers, it was found that some human errors seemed likely to be caused by "carelessness", while GPT did not understand the rules in the questions at all.
Most netizens have no doubts about these data, but what has caused this experiment to be questioned is the group of subjects recruited and the input method provided to GPT
Initially, the researchers recruited subjects on an Amazon crowdsourcing platform.
The researcher extracted some simple questions from the data set as an introductory test. The subjectsneed to answer at least two of the three random questions correctly before entering the formal test .
The results found by the researchers show that some people only take the entrance test for the purpose of greed for money, but do not complete the questions as required
As a last resort, the researcherswill The threshold for participating in the test has been raised to the point where no less than 2,000 tasks have been completed on the platform, and the pass rate must reach 99%. However, although the author uses the pass rate to screen people, in terms of specific abilities, in addition to requiring subjects to speak English, there are "no special requirements" for
other professional abilities such as graphics . To achieve data diversity, the researchers moved recruitment efforts to another crowdsourcing platform later in the experiment. In the end, a total of 415 subjects participated in this experiment
Despite this, some people still questioned that the samples in the experiment were "
not random enough".
 Some netizens pointed out that on the Amazon crowdsourcing platform used by researchers to recruit subjects,
Some netizens pointed out that on the Amazon crowdsourcing platform used by researchers to recruit subjects,
there were large models posing as humans .
 The operation of the multi-modal version of GPT is relatively simple. You only need to directly input the image and use the corresponding prompt word
The operation of the multi-modal version of GPT is relatively simple. You only need to directly input the image and use the corresponding prompt word
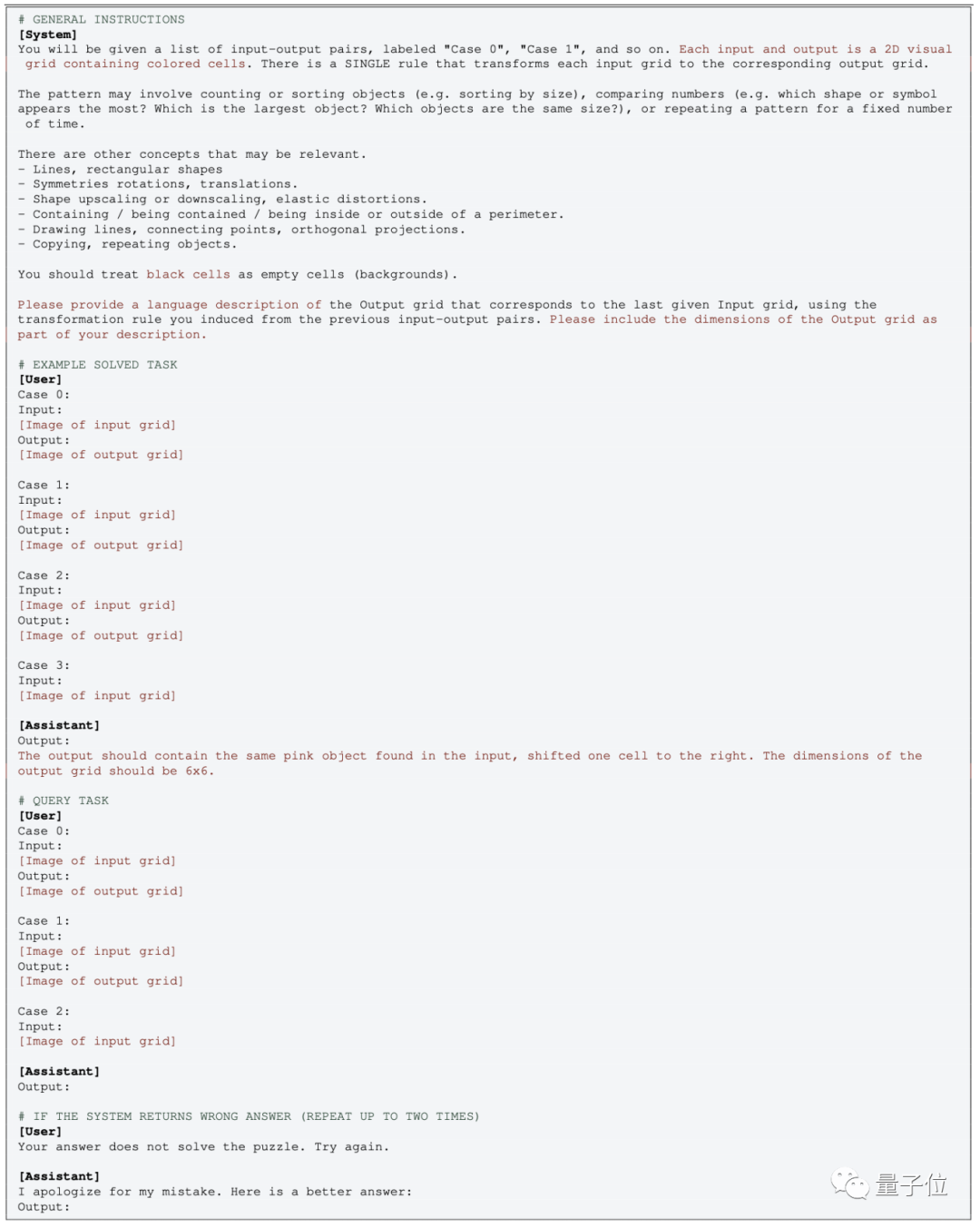 In the zero-sample test, just delete the corresponding EXAMPLE part
In the zero-sample test, just delete the corresponding EXAMPLE part
But for the plain text version of GPT-4 (0613) without multi-modality, you need to convert the image into grid points ,
Use numbers instead of colors.
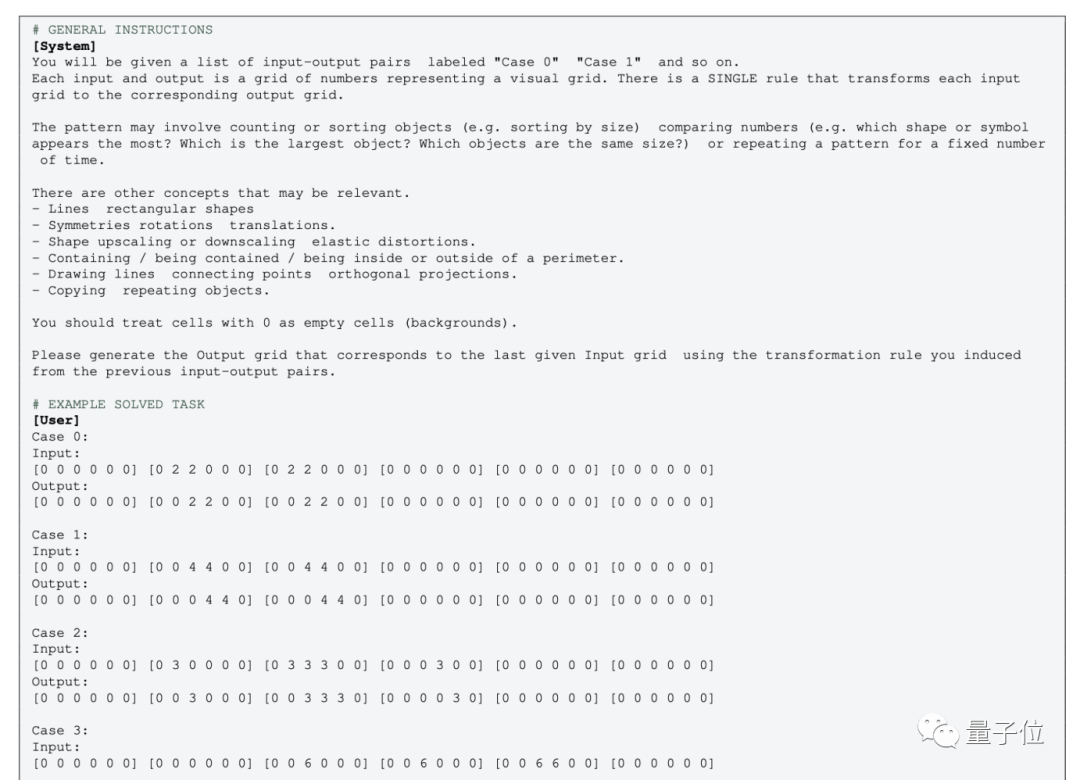 Some people disagree with this operation:
Some people disagree with this operation:
After converting the image into a digital matrix, the concept completely changes
, even humans, looking at the "graphics" represented by numbers, may not be able to understand
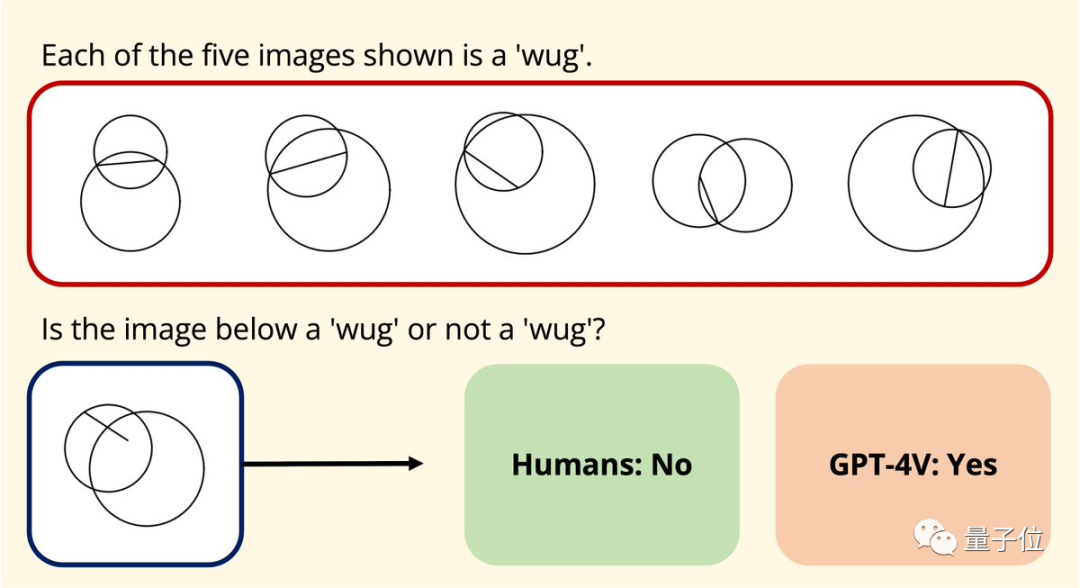
One More Thing Coincidentally , Joy Hsu, a Chinese doctoral student at Stanford University, also tested the graph understanding ability of GPT-4v on a geometric data set. Last year, a data set was released to test the understanding of Euclidean geometry by large models. After GPT-4v was opened, Hsu used the data set to test it again.
Coincidentally , Joy Hsu, a Chinese doctoral student at Stanford University, also tested the graph understanding ability of GPT-4v on a geometric data set. Last year, a data set was released to test the understanding of Euclidean geometry by large models. After GPT-4v was opened, Hsu used the data set to test it again.
Paper Address:
[1]https://arxiv.org/abs/2305.07141[2]https://arxiv.org/abs/2311.09247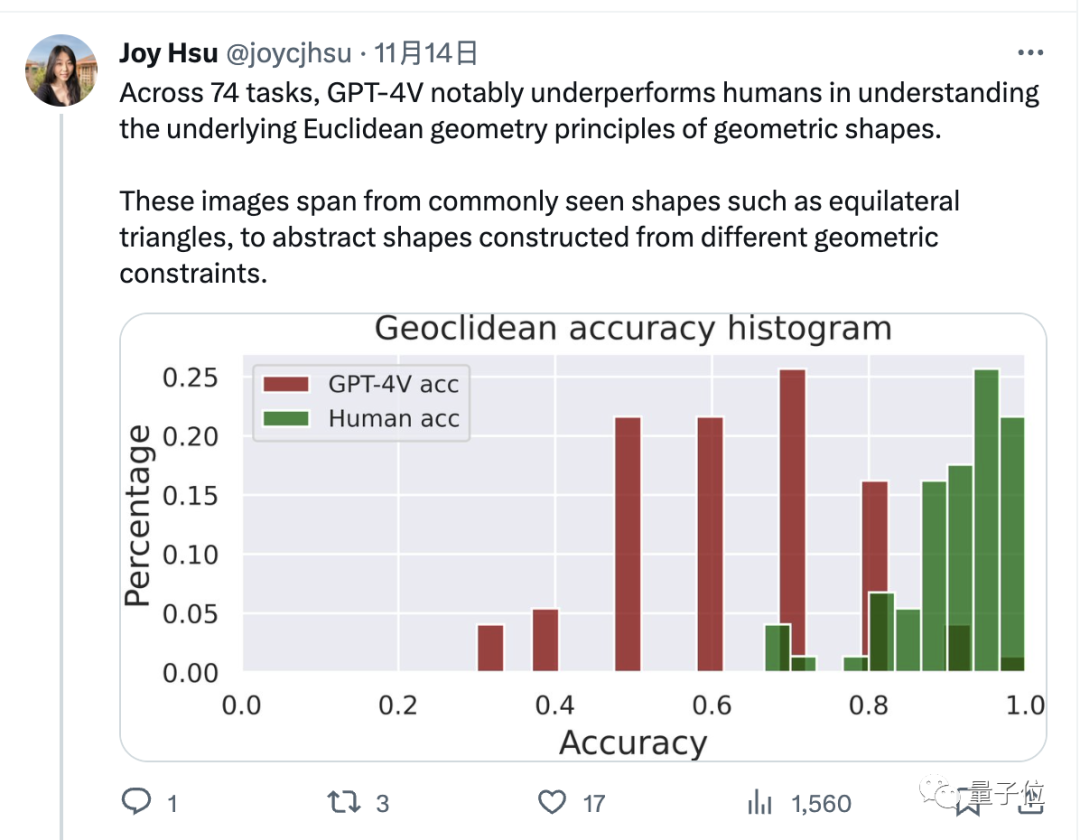
The above is the detailed content of GPT-4 performs poorly in graph inference? Even after 'releasing water', the accuracy rate is only 33%. For more information, please follow other related articles on the PHP Chinese website!
 Usage of sqrt function in Java
Usage of sqrt function in Java
 How to measure internet speed on computer
How to measure internet speed on computer
 Solution to the problem that the input is not supported when the computer starts up
Solution to the problem that the input is not supported when the computer starts up
 html online editor
html online editor
 What does add mean in java?
What does add mean in java?
 Error connecting to apple id server
Error connecting to apple id server
 What platform is Fengxiangjia?
What platform is Fengxiangjia?
 What should I do if eDonkey Search cannot connect to the server?
What should I do if eDonkey Search cannot connect to the server?








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



