


LoRAShear is a new method developed by Microsoft to optimize language model models (llm) and preserve knowledge. It enables structural pruning, reducing computational requirements and improving efficiency.

LHSPG technology (Lora Half-Space Projected Gradient) supports progressive structured pruning and dynamic knowledge recovery. Can be applied to various LLMs via dependency graph analysis and sparsity optimization
LoRAPrune combines LoRA with iterative structured pruning to achieve efficient fine-tuning of parameters. Even with heavy pruning on LLAMA v1, its performance remains comparable
In the ever-evolving field of artificial intelligence, language model models ( llm) has become a key tool for processing large amounts of text data, quickly retrieving relevant information, and enhancing knowledge accessibility. Their far-reaching impact spans fields ranging from enhancing search engines and question-answering systems to enabling data analytics, benefiting researchers, professionals and knowledge seekers alike.
The biggest problem at present is that LLM needs to continuously update knowledge to meet the dynamic requirements of information. Typically, developers fine-tune pretrained models using domain-specific data to keep them up to date and instill the latest insights into the model. Regular updates are critical for organizations and researchers to ensure that LLM keeps pace with the ever-changing information landscape. However, the cost of fine-tuning is high and the cycle is long.
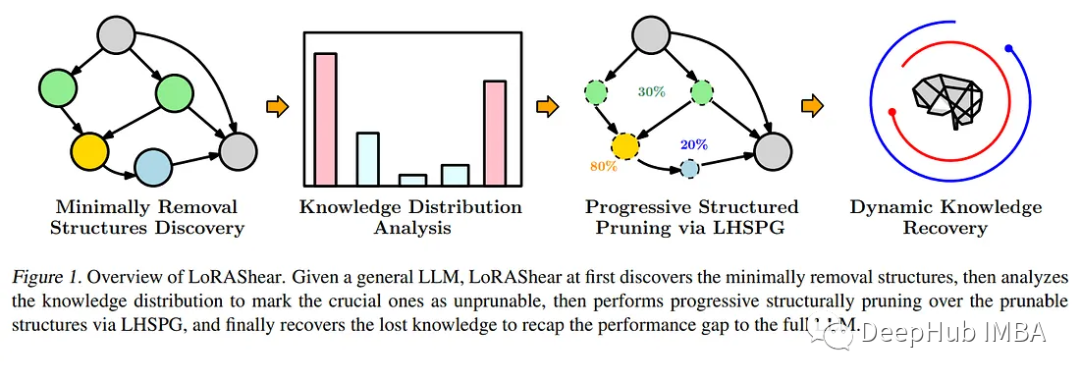
In response to this urgent need, Microsoft researchers launched a groundbreaking method-LoRAShear. This innovative approach not only simplifies LLM but also facilitates the recovery of structural knowledge. The core of structural pruning is to remove or reduce specific components in the neural network architecture to optimize efficiency, compactness and computational requirements.
Microsoft's LoRAShear uses LHSPG technology to support progressive structured pruning. This approach can seamlessly transfer knowledge between LoRA modules and also integrates a dynamic knowledge recovery stage. The fine-tuning process is similar to pre-training and guided fine-tuning to ensure that the LLM remains updated and relevant
Rewritten as: Leveraging dependency graph analysis, LoRAShear can be extended to LLM in general, especially in LoRA within the module's support range. This method uses original LLM and LoRA modules to create a dependency graph, and introduces a structured sparsity optimization algorithm that utilizes information from LoRA modules to enhance knowledge preservation during the weight update process
In the paper, an integrated technology called LoRAPrune is also mentioned, which combines LoRA with iterative structured pruning to achieve efficient fine-tuning of parameters and direct hardware acceleration. This memory-saving method relies entirely on LoRA's weights and gradients for pruning criteria. The specific process includes building a tracking graph, determining the node groups that need to be compressed, dividing the trainable variables, and finally returning them to LLM
The paper is implemented on the open source LLAMAv1, Proved the effectiveness of LoRAShear. Notably, LLAMAv1 with 20% pruning only suffers a 1% performance loss, while the model with 50% pruning retains 82% of performance on the evaluation benchmark.
LoRAShear represents a major advancement in the field of artificial intelligence. It not only simplifies the way LLM is used, making it more efficient, but also ensures the preservation of critical knowledge. It enables AI-driven applications to keep pace with the evolving information environment while optimizing computing resources. As organizations increasingly rely on artificial intelligence for data processing and knowledge retrieval, solutions like LoRAShear will play a key role in the market, providing efficiency and knowledge resiliency.
Paper address: https://arxiv.org/abs/2310.18356
The above is the detailed content of Microsoft's latest research explores LoRAShear technology for LLM pruning and knowledge recovery. For more information, please follow other related articles on the PHP Chinese website!
 Application of artificial intelligence in life
Application of artificial intelligence in life
 What is the basic concept of artificial intelligence
What is the basic concept of artificial intelligence
 How to set up a secure VPS
How to set up a secure VPS
 Introduction to the opening location of win8 running
Introduction to the opening location of win8 running
 disk recovery data
disk recovery data
 What does MLM coin mean? How long does it usually take to crash?
What does MLM coin mean? How long does it usually take to crash?
 Introduction to the usage of rowid in oracle
Introduction to the usage of rowid in oracle
 What are the basic data types in php
What are the basic data types in php








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



