


Recently, the speed at which new papers are being published has been so fast that I feel like I can’t read them. It can be seen that the fusion of multi-modal large models for language and vision has become an industry consensus. This article on UniPad is more representative, with multi-modal input and a pre-trained base model of world-like models, while being easy to expand. to multiple traditional vision applications. It also solves the problem of applying the pre-training method of large language models to 3D scenes, thus providing the possibility of a unified large model of perceptual base.
UniPAD is a self-supervised learning method based on MAE and 3D rendering that can train a base model with excellent performance and then fine-tune and train downstream tasks on the model, such as depth estimation, object detection and segmentation. This study designed a unified 3D space representation method that can be easily integrated into 2D and 3D frameworks, showing greater flexibility and consistent with the positioning of the base model
What is the relationship between mask auto-encoding technology and 3D differentiable rendering technology? To put it simply: Masked autoencoding is to take advantage of Autoencoder’s self-supervised training capabilities, and rendering technology is to calculate the loss function between the generated image and the original image and conduct supervised training. So the logic is still very clear.
This article uses the base model pre-training method, and then fine-tunes the downstream detection method and segmentation method. This method can also help understand how the current large model works with downstream tasks.
Looks like is not combined with timing information. After all, NuScenes NDS of Pure Vision 50.2 is currently still weaker in comparison with timing detection methods (StreamPETR, Sparse4D, etc.). Therefore, the 4D MAE method is also worth trying. In fact, GAIA-1 has already mentioned a similar idea.
How about the calculation amount and memory usage?
UniPAD implicitly encodes 3D spatial information. This is mainly inspired by mask auto-encoding (MAE, VoxelMAE, etc.). This article uses A generative mask is used to complete the enhancement of voxel features, which is used to reconstruct the continuous 3D shape structure in the scene and their complex appearance features on the 2D plane.
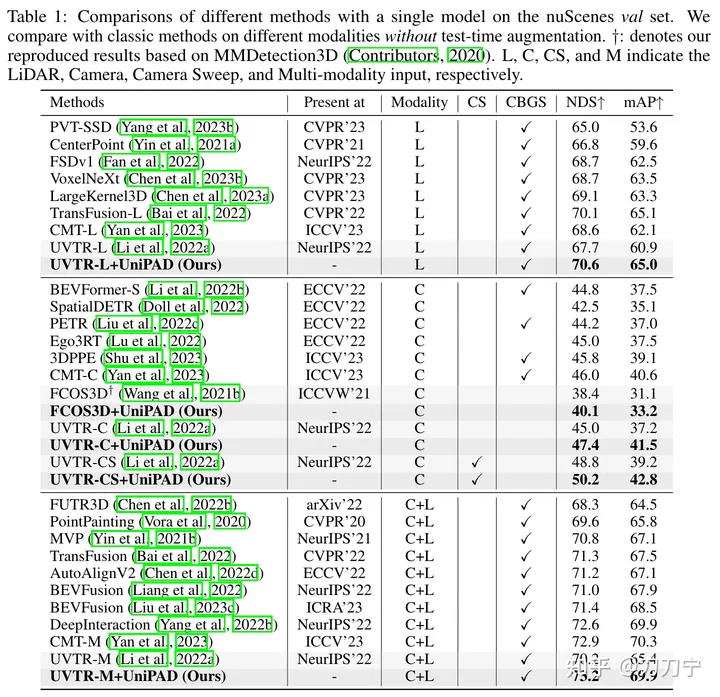
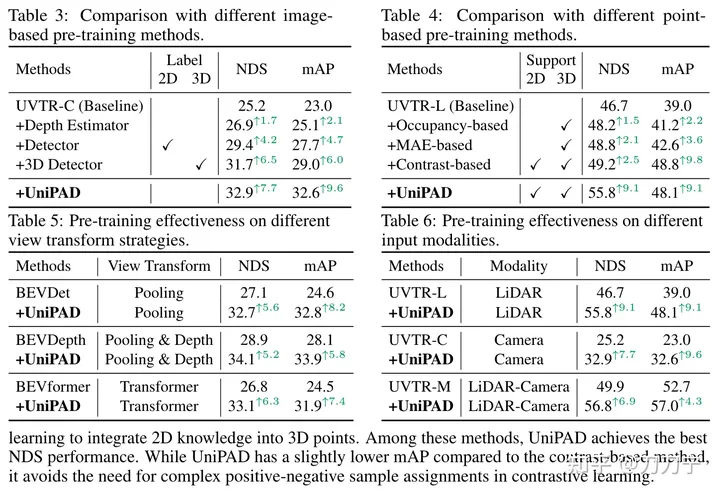
Our experimental results fully prove the superiority of UniPAD. Compared with traditional lidar, camera and lidar-camera fusion baselines, UniPAD's NDS improves by 9.1, 7.7 and 6.9 respectively. It is worth noting that on the nuScenes validation set, our pre-training pipeline achieved an NDS of 73.2, while achieving an mIoU score of 79.4 on the 3D semantic segmentation task, achieving the best results compared with previous methods
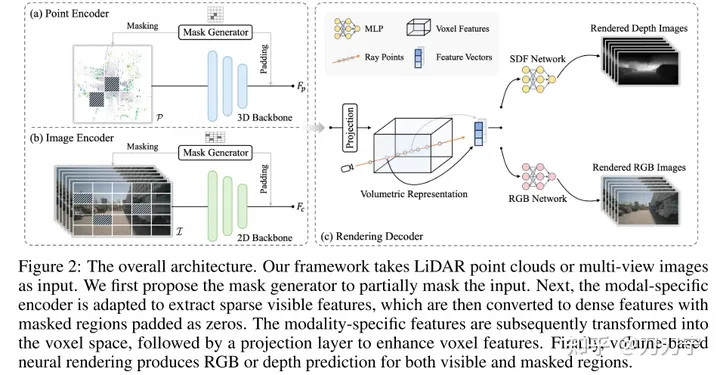
Overall architecture. The framework takes LiDar and multi-shot images as input, and these multi-modal data are filled with zeros through the Mask Generator. The masked embedding is converted to voxel space, and rendering techniques are used to generate RGB or depth predictions in this 3D space. At this time, the original image that is not obscured by the mask can be used as generated data for supervised learning.
The mask in Masked AutoEncoder is generated by Mask Generator. It can be understood as improving the representation ability and generalization ability of the model by increasing the difficulty of training. A Mask generator is introduced to differentiate between point cloud data and image data by selectively occluding certain areas. In the point cloud data, the block masking strategy is adopted; for the image data, the sparse convolution method is used, and calculations are only performed in the visible area. When the input data is masked, the subsequent encoding features will be set to 0 in the corresponding masked area and ignored in the model processing. It also provides subsequent supervised learning with information that can be used to predict the target and the corresponding Groundtruth information
In order to make the pre-training method applicable to various data modalities, it is important to find a unified representation. Past methods such as BEV and OCC are looking for a unified form of identification. Projecting 3D points into the image plane will lead to the loss of depth information, and merging them into the BEV bird's-eye view will miss height-related details. Therefore, this article proposes to convert both modalities into 3D volume space, which is a 3D voxel space similar to OCC
Differentiable rendering technology This should be the biggest highlight of the paper according to the author. This paper uses NERF-like sampling rays to pass through multi-view images or point clouds, predict the color or depth of each 3D point through the neural network structure, and finally obtain 2D data through the path of the rays. of mapping. This can better utilize geometric or texture clues in images and improve the model's learning ability and application range.
We represent the scene as SDF (implicit signed distance function field). When the input is the 3D coordinate P of the sampling point (the corresponding depth D along the ray) and F (the feature embedding can be extracted from the volumetric representation by trilinear interpolation ), SDF can be regarded as an MLP to predict the SDF value of the sampling point. Here F can be understood as the encode code where point P is located. Then the output is obtained: N (condition the color field on the surface normal) and H (geometry feature vector). At this time, the RGB of the 3D sampling point can be obtained through an MLP with P, D, F, N, H as input. value and depth value, and then superimpose the 3D sampling points to the 2D space through rays to obtain the rendering result. The method of using Ray here is basically the same as that of Nerf.
The rendering method also needs to optimize the memory consumption, which is not listed here. However, this issue is a more critical implementation issue.
The essence of the Mask and rendering methods is to train a pre-trained model. The pre-trained model can be trained based on the predicted mask, even without subsequent branches. The subsequent work of the pre-training model generates RGB and depth predictions through different branches, and fine-tunes tasks such as target detection/semantic segmentation to achieve plug-and-play capabilities
Loss function is not complicated.


The above is the detailed content of UniPAD: Universal autonomous driving pre-training mode! Various perception tasks can be supported. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



