


ICDAR 2023 (International Conference on Document Analysis and Recognition), as one of the most important international conferences in the field of document image analysis and recognition, has recently received exciting news:
iFlytek Research Institute of HKUST and the University of Science and Technology of China The National Engineering Research Center for Speech and Language Information Processing (hereinafter referred to as the Research Center) won four championships in three competitions: multi-line formula recognition, document information location and extraction, and structured text information extraction.
MLHMETop: Focus on "multi-line writing", breakthrough in complexity
MLHME (multi-line formula recognition competition) test input After an image containing a handwritten mathematical formula, the algorithm outputs the accuracy of the corresponding LaTex string. It is worth mentioning that compared with previous mathematical formula recognition competitions, this competition has set "multi-line writing" as the main challenge for the first time in the industry. And unlike the previous formulas for recognizing scanned and online handwriting, this time it will recognize photographed handwriting. Mainly multi-line formulas.

The image and text recognition team of iFlytek Research Institute won the championship with a score of 67.9%, and far exceeded other participating teams in the main evaluation indicator-formula recall rate
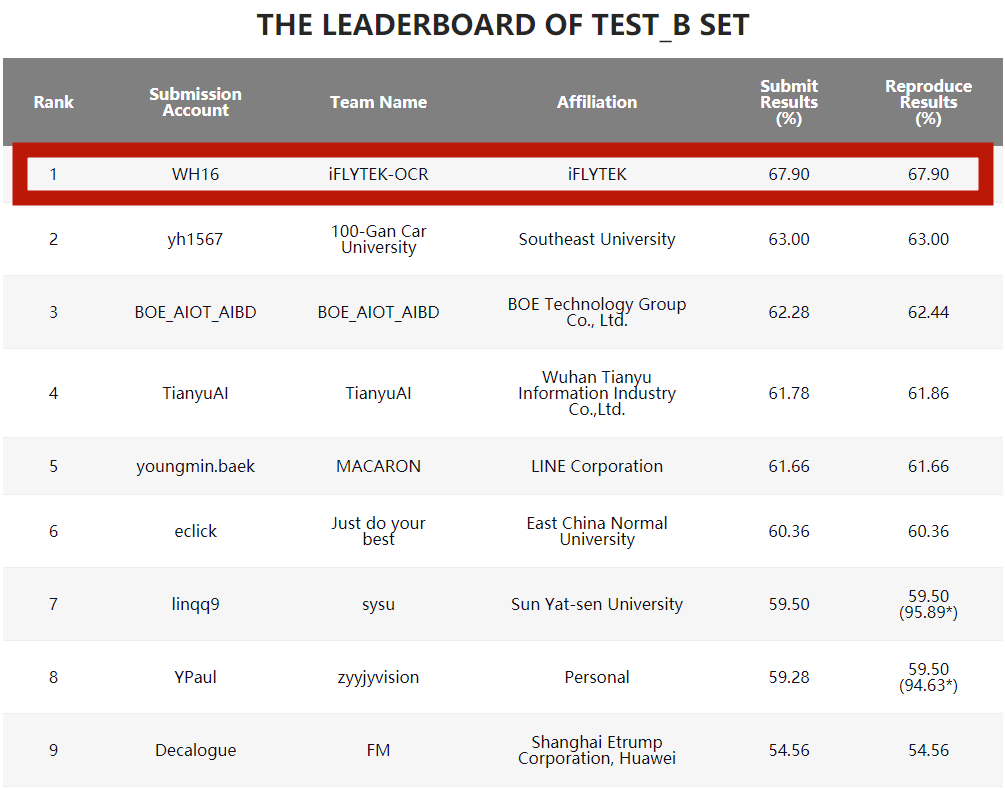
The recall rate of the formula corresponds to the Submit Results in the list
Multi-line formulas are more complex than single-line structures, and the same character appears more often in the formula The size will also change when it appears. At the same time, the data set used in the competition comes from real scenes, and the handwritten formula pictures taken have problems such as low quality, background interference, text interference, smearing and annotation interference. These factors make the game more difficult.
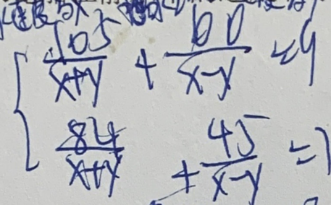
The formula structure is complex and takes up multiple lines
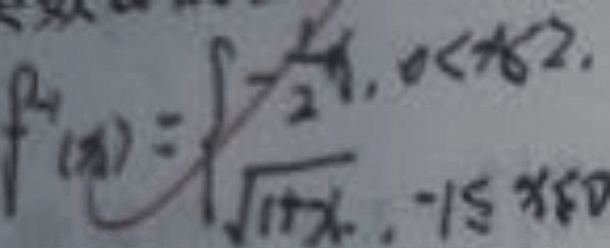
The picture quality is not high and correction interference
Aiming at the problem that the formula has a complex structure and occupies multiple lines, the team uses Conv2former with a large convolution kernel as the encoder structure, which expands the field of view of the model and better captures the structural characteristics of multi-line formulas; innovatively proposes structured sequence decoding based on transformer The SSD processor explicitly models the hierarchical relationships within multi-line formulas in a refined manner, which greatly improves the generalization of complex structures and better models structured semantics.
In response to the character ambiguity problem caused by picture quality problems, the team innovatively proposed a semantic-enhanced decoder training algorithm. Through joint training of semantics and vision, the decoder has intrinsic domain knowledge. When characters are difficult to identify, the model can adaptively use domain knowledge to make inferences and give the most reasonable recognition results.
In response to the problem of large changes in character size, the team proposed an adaptive character scale estimation algorithm and a multi-scale fusion decoding strategy, which greatly improved the model's robustness to changes in character size.
DocILEThe crown: "Pick one in the line", the two-track competition of document information positioning and extraction topped the list
DocILE (Document Information Location and Extraction Competition) evaluates the performance of machine learning methods in locating, extracting and identifying line items of key information in semi-structured business documents.
The competition is divided into two track tasks: KILE and LIR. The KILE task needs to locate the key information location of predefined categories in the document. On this basis, the LIR task further groups each key information into different line items (Line Item), such as a single object (quantity, price) in a row in the table. )wait. iFlytek and the Research Center finally won the championship in two tracks
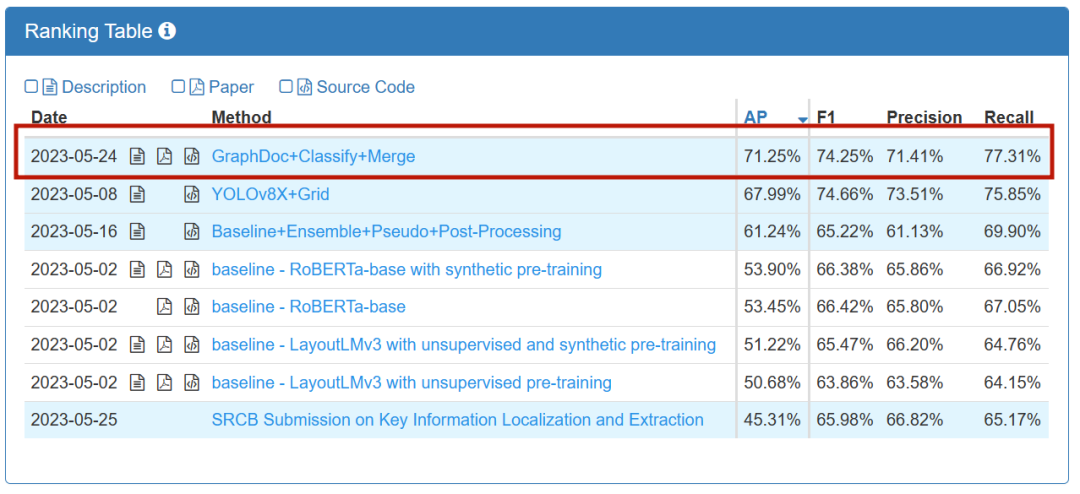 KILE track ranking
KILE track ranking
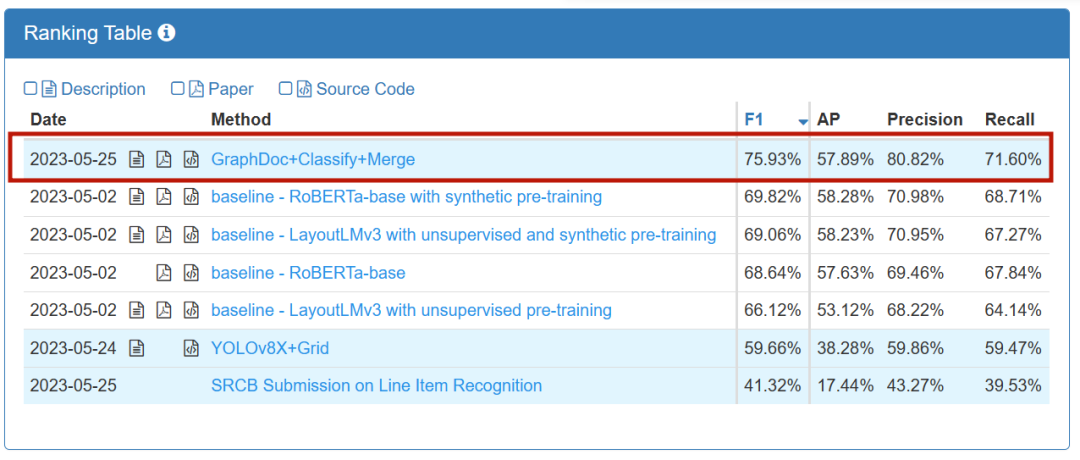
LIR track ranking

The left is the KILE track description, the right is the LIR track description
It can be seen from the task icon given by the official event that the information to be extracted from the document The variety is very diverse. Among them, the KILE task not only needs to extract key information of predefined categories, but also obtain the specific location of the key information; in the LIR task, a line item may have multiple lines of text in a single table. In addition, there are many types of information in the data set of this competition and the document formats are complex and diverse, which greatly increases the challenge.
The joint team proposed two technological innovation plans at the algorithm level:
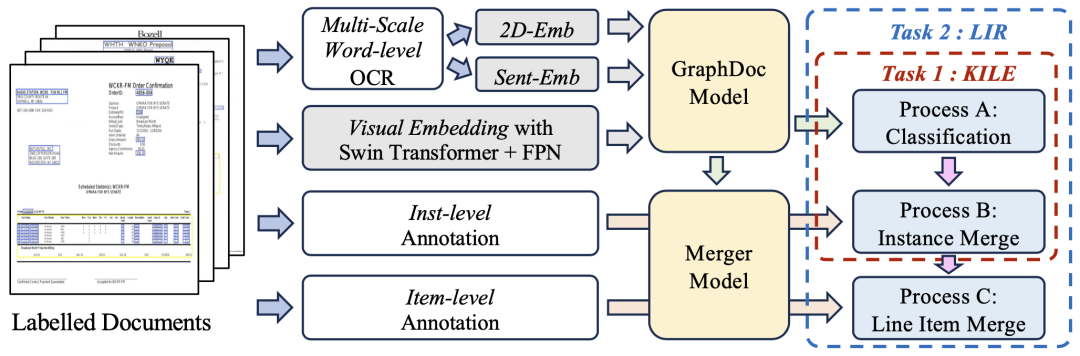
In the pre-training stage, we designed a document filter based on OCR quality by extracting 2.74 million pages of document images from unannotated documents provided by the organizer. Then, we use a pre-trained language model to obtain the semantic representation of each text line in the document, and use the masked sentence representation recovery task, pre-trained under different Top-K configurations (attention span of the document in the GraphDoc model A hyperparameter)
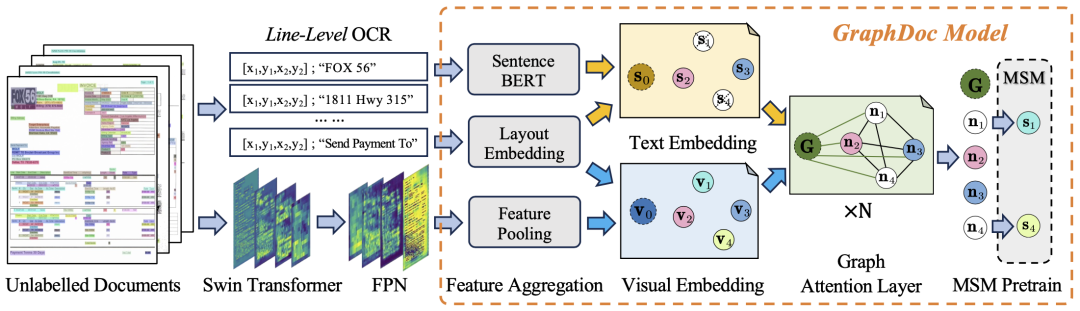
#In the data set fine-tuning stage, the team used the pre-trained GraphDoc to extract the multi-modal representation of the text box and perform classification operations. On the basis of the classification results, multi-modal representations are sent to the low-level attention fusion module for instance aggregation. Based on the instance aggregation, the high-level attention fusion module is used to realize the aggregation of line item instances. The proposed attention fusion The modules have the same structure but do not share parameters with each other. They can be used for both KILE and LIR tasks with good results.
SVRDThe crown: No. 1 in zero-sample ticket structured information extraction task, pre-training model test
SVRD (Structured Text Information Extraction) competition is divided into 4 track sub-tasks. iFlytek and the research center are competing in the very difficult zero-sample structured information extraction sub-track (Task3: E2E zero-sample structured text extraction). Won first place
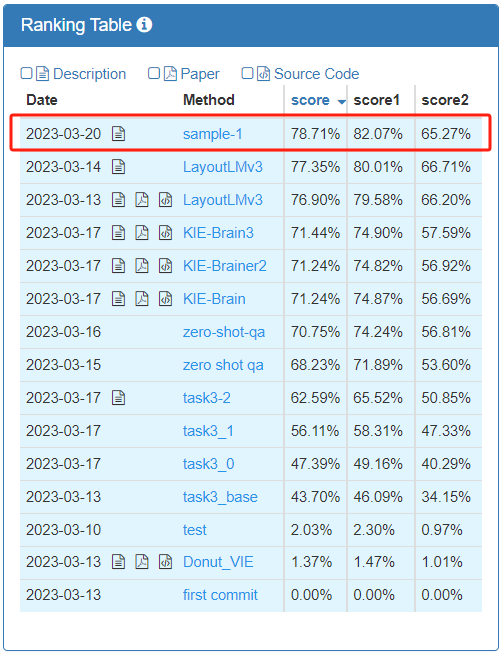
Ranking order
In the context of the official designation of key elements that need to be extracted for different types of invoices, this track requires participating teams to use model output The corresponding content of these key elements in the picture, "zero sample" means that the invoice types of the training set and the test set have no overlap; the end-to-end prediction accuracy of the track test model, the weighted average of score1 and score2 is used as the final evaluation index .
For pre-training models, zero samples put forward higher requirements. At the same time, there are various invoice formats used in the competition, and the names of the ride stops, departure times and other elements in each format are different. In addition, invoice photos have problems such as background interference, reflection, and text overlap, which further increases the difficulty of identification and extraction.

Invoices in different formats

The invoice is interfered by the striped background
The team initially adopted a copy-generate dual-branch decoding strategy to carry out the feature extraction model. When the confidence of the front-end OCR result is high, copy it directly OCR results; when the confidence level of the OCR results is low, new prediction results are generated to alleviate the recognition errors introduced by the front-end OCR model
In addition, the team also extracts sentence-level graphdoc features based on the OCR results As input to the feature extraction model, this feature integrates multi-modal features of image, text, location, and layout, and has a stronger feature representation than single-modal plain text input.
On this basis, the team also combined multiple element extraction models such as UniLM, LiLT, and DocPrompt to further improve the final element extraction effect and enable it to show better performance in different scenarios and languages. Advantages
Education, finance, medical care, etc. have been implemented to help large models improve multi-modal capabilities
This time I chose relevant events of ICDAR 2023 for the challenge, from iFlytek's real-life scenario needs in actual business; event-related technologies have also penetrated into education, finance, medical care, justice, intelligent hardware and other fields, empowering multiple businesses and products.
In the field of education, the technical ability of handwritten formula recognition is frequently used, and machines can provide accurate identification, judgment and correction. For example, the personalized precision learning and AI diagnosis in iFlytek's AI learning machine; the "iFlytek Smart Window" teaching large screen used by teachers in class, and students' personalized learning manuals, etc., have all achieved great results;
Not long ago, the Spark Scientific Research Assistant was released on the iFlytek Global 1024 Developer Festival main forum. One of the three core functions of paper reading can realize intelligent interpretation of papers and quickly answer related questions. . Subsequently, on the basis of high-precision formula recognition, the effect of organic chemical structural formulas, graphics, icons, flow charts, tables and other structured scene recognition will be advanced. This function will also better help scientific researchers improve efficiency;

Document information positioning and extraction technology is widely used in the financial field, such as contract element extraction and review, bank bill element extraction, marketing content consumer protection review and other scenarios. These technologies can realize functions such as data analysis, information extraction and comparison review of documents or files, and help business data to be quickly entered, extracted and compared, thereby improving the efficiency of the review process and reducing costs
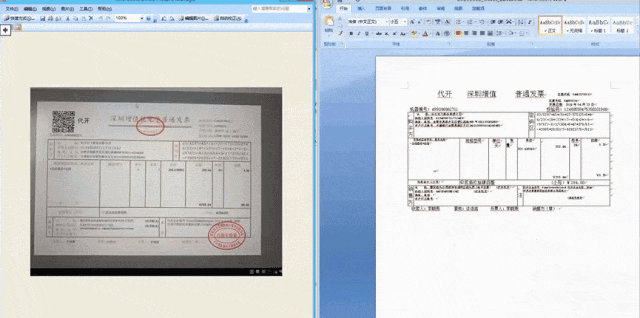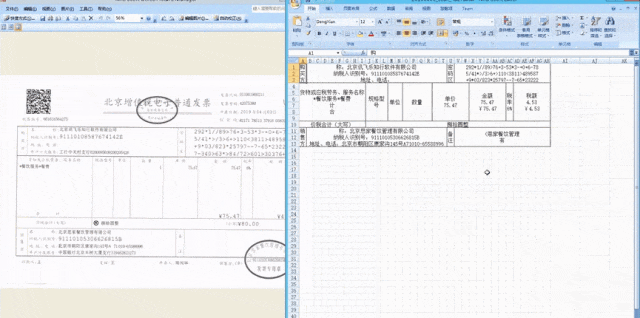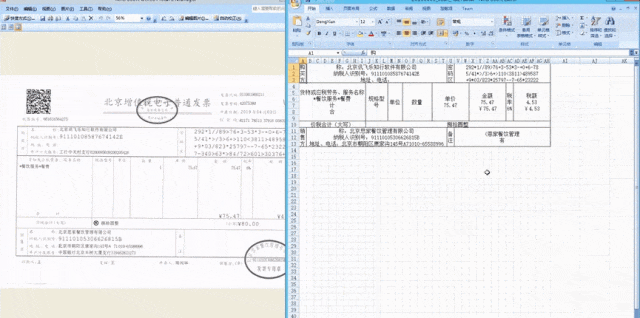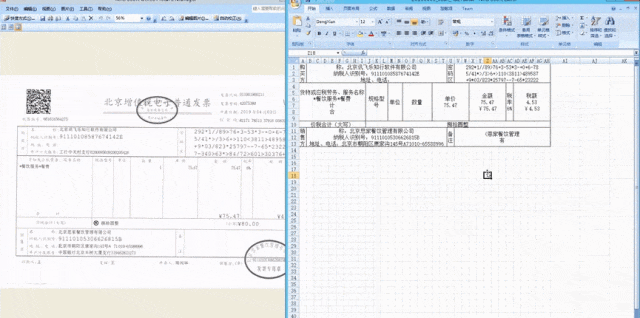
The personal AI health assistant released on this 1024 main forum is iFlytek Xiaoyi. It can not only scan checklists and test orders and give analysis and suggestions, but it can also scan pill boxes and make further inquiries and provide auxiliary medication suggestions. For physical examination reports, users can take photos and upload them, and iFlytek Xiaoyi can identify key information, comprehensively interpret abnormal indicators, proactively inquire and provide more help. This function relies on the support of document information positioning and extraction technology

iFlytek's image and text recognition technology continues to make breakthroughs in algorithms, from single word recognition to text line recognition. to more complex two-dimensional structure recognition and chapter-level recognition. More powerful image and text recognition technology can improve the effect and potential of multi-modal large models in image description, image question and answer, image recognition creation, document understanding and processing, etc.
At the same time, image and text recognition technology is also Combining speech recognition, speech synthesis, machine translation and other technologies to form a systematic innovation, the empowered product shows more powerful functions and more obvious value advantages after application. The related project also won the first prize of the 2022 Wu Wenjun Artificial Intelligence Technology Progress Award . In the new journey, "more blooms" in several ICDAR 2023 competitions are not only feedback from iFlytek's continuous progress in the depth of image and text recognition and understanding technology, but also affirmation of its continuous expansion in breadth.
The above is the detailed content of iFLYTEK ICDAR 2023: Image and text recognition achieves greater glory again, winning four championships. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



