


In the field of machine learning, relevant models may become overfitting and underfitting during the training process. To prevent this from happening, we use regularization operations in machine learning to properly fit the model on our test set. Generally speaking, regularization operations help everyone obtain the best model by reducing the possibility of overfitting and underfitting.
In this article, we will understand what is regularization, types of regularization. Additionally, we will discuss related concepts such as bias, variance, underfitting, and overfitting.
Let’s stop talking nonsense and get started!
Bias and Variance are used to describe the model we learned and the real model The two aspects of the gap
need to be rewritten: the definitions of the two are as follows:
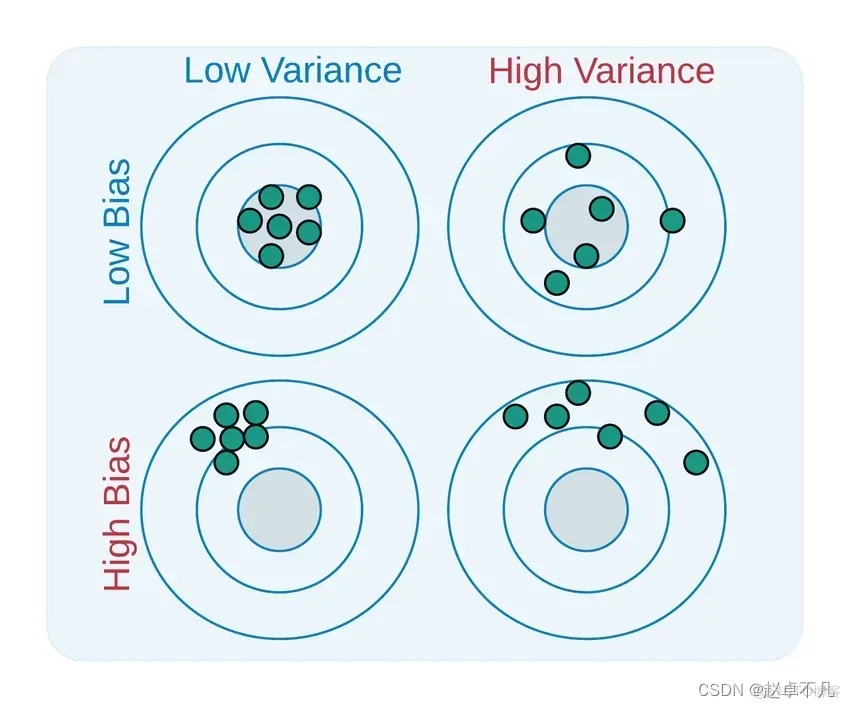
Bias reduces the sensitivity of the model to individual data points while increasing the generalization of the data , reducing the sensitivity of the model to isolated data points. Training time can also be reduced since the required functionality is less complex. High bias indicates that the target function is assumed to be more reliable, but sometimes results in underfitting the model
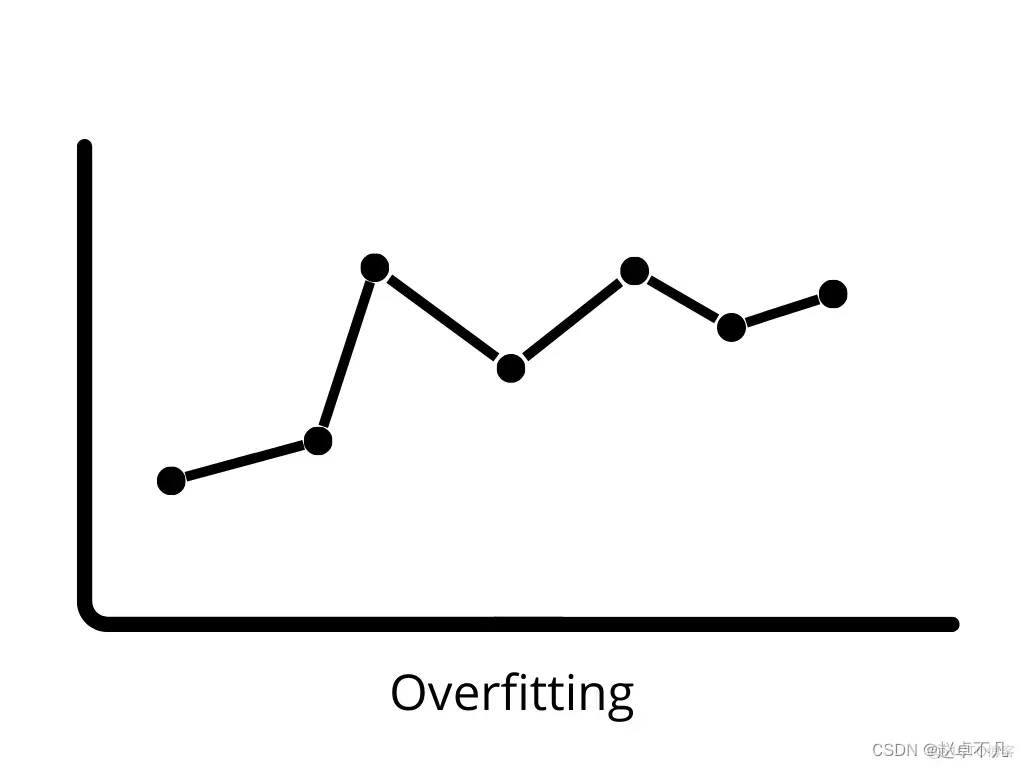
Variance (Variance) in machine learning refers to the sensitivity of the model to small changes in the data set. mistake. Since there is significant variation in the data set, the algorithm models noise and outliers in the training set. This situation is often called overfitting. When evaluated on a new data set, since the model essentially learns every data point, it cannot provide accurate predictions
A relatively balanced model will have low bias and low variance, while high bias and high variance will lead to underfitting and overfitting.
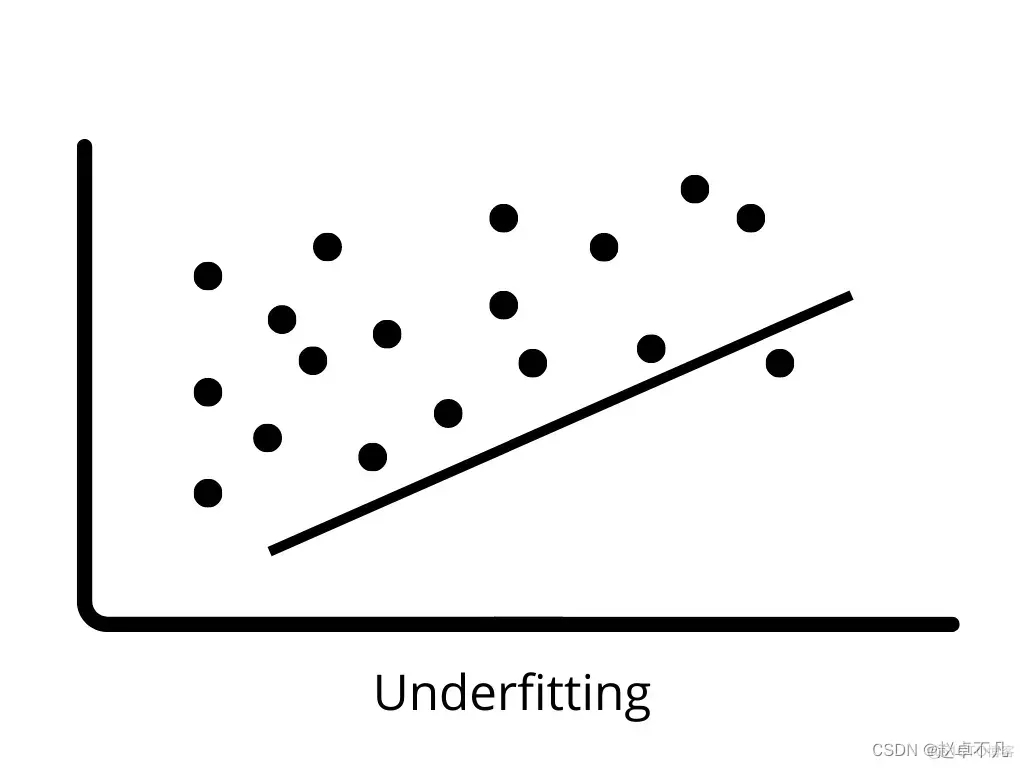
Underfitting occurs when the model cannot correctly learn the patterns in the training data and generalize to new data. . Underfitting models perform poorly on training data and can lead to incorrect predictions. When high bias and low variance occur, underfitting is prone to occur
##5. Regularization concept
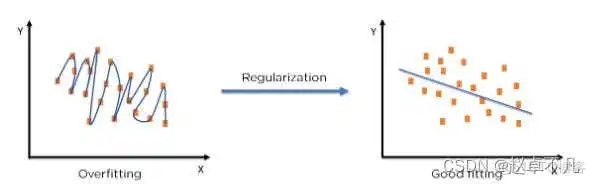
By using regularization techniques, we can make machine learning models more accurate Fit to a specific test set effectively, thereby effectively reducing the error in the test set
6. L1 regularization
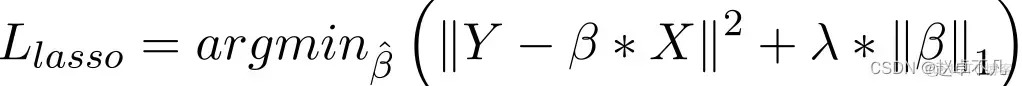
In the Lasso regression model, the penalty is increased by increasing the absolute value of the regression coefficient in a manner similar to ridge regression item to achieve. In addition, L1 regularization has good performance in improving the accuracy of linear regression models. At the same time, since L1 regularization penalizes all parameters equally, it can make some weights become zero, thus producing a sparse model that can remove certain features (a weight of 0 is equivalent to removal).
7. L2 regularization
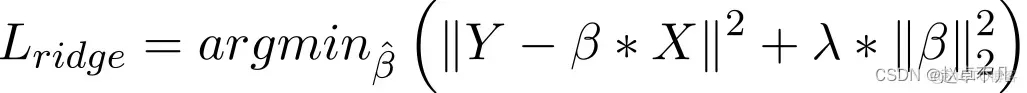
Generally speaking, it is considered a method to adopt when the data exhibits multicollinearity (independent variables are highly correlated). Although least squares estimates (OLS) in multicollinearity are unbiased, their large variances can cause observed values to differ significantly from actual values. L2 reduces the error of regression estimates to a certain extent. It usually uses shrinkage parameters to solve multicollinearity problems. L2 regularization reduces the fixed proportion of weights and smoothes the weights.
After the above analysis, the relevant regularization knowledge in this article is summarized as follows:
L1 regularization can generate a sparse weight matrix, that is, a sparse model, which can be used for feature selection;
L2 regularization can prevent model overfitting. To a certain extent, L1 can also prevent overfitting and improve the generalization ability of the model;
L1 (Lagrangian) regularization assumes that the prior distribution of parameters is the Laplace distribution, which can ensure the sparsity of the model. That is, some parameters are equal to 0;
The assumption of L2 (ridge regression) is that the prior distribution of the parameters is a Gaussian distribution, which can ensure the stability of the model, that is, the values of the parameters will not be too large or too small.
In practical applications, if the features are high-dimensional and sparse, L1 regularization should be used; if the features are low-dimensional and dense, L2 regularization should be used
The above is the detailed content of What is regularization in machine learning?. For more information, please follow other related articles on the PHP Chinese website!
 hdtunepro usage
hdtunepro usage
 How to set up Douyin to prevent everyone from viewing the work
How to set up Douyin to prevent everyone from viewing the work
 The difference between i5 and i7
The difference between i5 and i7
 How to unlock the password lock on your Apple phone if you forget it
How to unlock the password lock on your Apple phone if you forget it
 How to save programs written in pycharm
How to save programs written in pycharm
 The difference between JD.com's self-operated and official flagship stores
The difference between JD.com's self-operated and official flagship stores
 flac file conversion
flac file conversion
 Virtual number receives verification code
Virtual number receives verification code








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



