


Researchers from Fudan University and Huawei's Noah's Ark Laboratory proposed an iterative solution for generating high-quality videos based on the image diffusion model (LDM) - VidRD (Reuse and Diffuse). This solution aims to make breakthroughs in the quality and sequence length of generated videos, and achieve high-quality, controllable video generation of long sequences. It effectively reduces the jitter problem between generated video frames, has high research and practical value, and contributes to the current hot AIGC community.
Latent diffusion model (LDM) is a generative model based on denoising autoencoder, which can generate high-quality data from randomly initialized data by gradually removing noise. sample. However, due to computational and memory limitations during both model training and inference, a single LDM can usually only generate a very limited number of video frames. Although existing work attempts to use a separate prediction model to generate more video frames, this also incurs additional training costs and produces frame-level jitter.
In this paper, inspired by the remarkable success of latent diffusion models (LDMs) in image synthesis, a framework called "Reuse and Diffuse", referred to as VidRD, is proposed. This framework can generate more video frames after the small number of video frames already generated by LDM, thereby iteratively generating longer, higher quality, and diverse video content. VidRD loads a pre-trained image LDM model for efficient training and uses a U-Net network with added temporal information for noise removal.

The main contributions of this article are as follows:
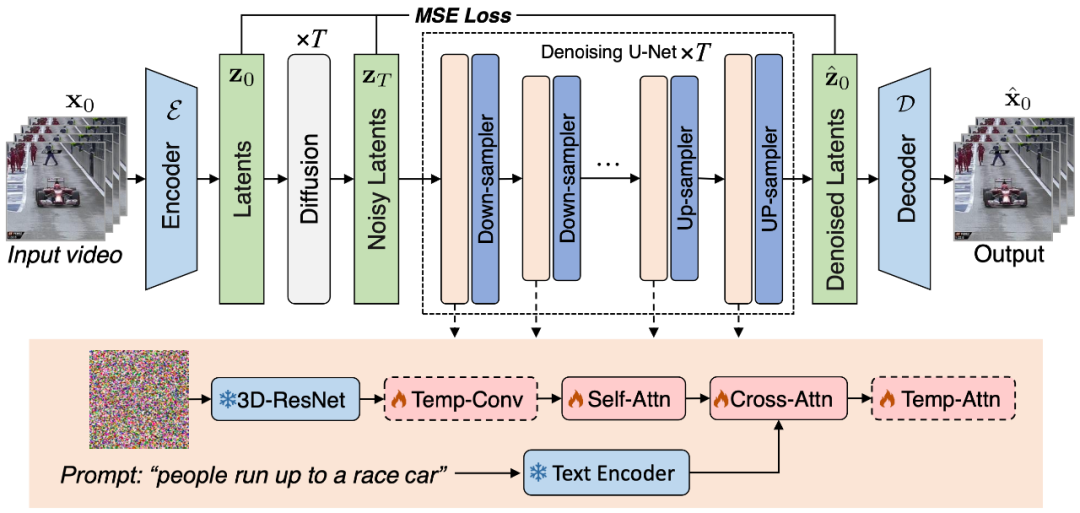
Figure 1. Schematic diagram of the VidRD video generation framework proposed in this article
This article believes that using pre-trained image LDM as the starting point for LDM training for high-quality video synthesis is an efficient and wise choice. At the same time, this view is further supported by research work such as [1, 2]. In this context, the carefully designed model in this article is built based on the pre-trained stable diffusion model, fully learning from and inheriting its excellent characteristics. These include a variational autoencoder (VAE) for accurate latent representation and a powerful denoising network U-Net. Figure 1 shows the overall architecture of the model in a clear and intuitive way.
In the model design of this article, a notable feature is the full utilization of the weights of the pre-trained model. Specifically, most network layers, including the components of VAE and the upsampling and downsampling layers of U-Net, are initialized using pre-trained weights of the stable diffusion model. This strategy not only significantly speeds up the model training process, but also ensures that the model exhibits good stability and reliability from the beginning. Our model can iteratively generate additional frames from an initial video clip containing a small number of frames by reusing the original latent features and mimicking the previous diffusion process. In addition, for the autoencoder used to convert between pixel space and latent space, we inject timing-related network layers into its decoder and fine-tune these layers to improve temporal consistency.
In order to ensure the continuity between video frames, this article adds 3D Temp-conv and Temp-attn layers to the model. The Temp-conv layer follows the 3D ResNet, which implements 3D convolution operations to capture spatial and temporal correlations to understand the dynamics and continuity of video sequence aggregation. The Temp-Attn structure is similar to Self-attention and is used to analyze and understand the relationship between frames in the video sequence, allowing the model to accurately synchronize the running information between frames. These parameters are randomly initialized during training and are designed to provide the model with understanding and encoding of temporal structure. In addition, in order to adapt to the model structure, the data input has also been adapted and adjusted accordingly.
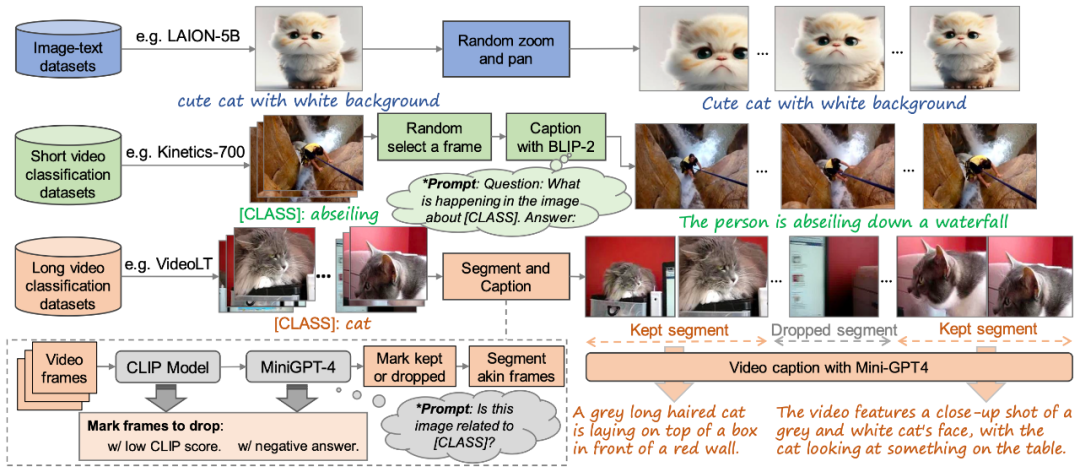
Figure 2. The high-quality “text-video” training data set construction method proposed in this article
In order to train the VidRD model, this article proposes a method of constructing a large-scale "text-video" training data set, as shown in Figure 2. This method can handle "text-image" data and "text-video" without description data. In addition, in order to achieve high-quality video generation, this article also attempts to remove watermarks on the training data.
Although high-quality video description datasets are relatively scarce in the current market, a large number of video classification datasets exist. These datasets have rich video content, and each video is accompanied by a classification label. For example, Moments-In-Time, Kinetics-700 and VideoLT are three representative large-scale video classification data sets. Kinetics-700 covers 700 human action categories and contains over 600,000 video clips. Moments-In-Time includes 339 action categories, with a total of more than one million video clips. VideoLT, on the other hand, contains 1,004 categories and 250,000 long, unedited videos.
In order to make full use of existing video data, this article attempts to automatically annotate these videos in more detail. This article uses multi-modal large language models such as BLIP-2 and MiniGPT4. By targeting key frames in the video and combining their original classification labels, this article designs many Prompts to generate annotations through model question and answer. This method not only enhances the speech information of video data, but also brings more comprehensive and detailed video descriptions to existing videos that do not have detailed descriptions, thereby enabling richer video tag generation to help the VidRD model bring better training effect.
In addition, for the existing very rich image data, this article also designed a detailed method to convert the image data into video format for training. The specific operation is to pan and zoom at different positions of the image at different speeds, thereby giving each image a unique dynamic presentation form and simulating the effect of moving a camera to capture still objects in real life. Through this method, existing image data can be effectively utilized for video training.
The description texts are: "Timelapse at the snow land with aurora in the sky.", "A candle is burning .", "An epic tornado attacking above a glowing city at night.", and "Aerial view of a white sandy beach on the shores of a beautiful sea." More visualizations can be found on the project homepage.

Figure 3. Visual comparison of the generation effect with existing methods
Finally, as shown in Figure 3 shows the visual comparison of the generated results of this article with the existing methods Make-A-Video [3] and Imagen Video [4] respectively, showing the better quality generation effect of the model in this article.
The above is the detailed content of Fudan University and Huawei Noah propose the VidRD framework to achieve iterative high-quality video generation. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



