


GPT-4V for target detection? Actual test by netizens: Not ready yet.
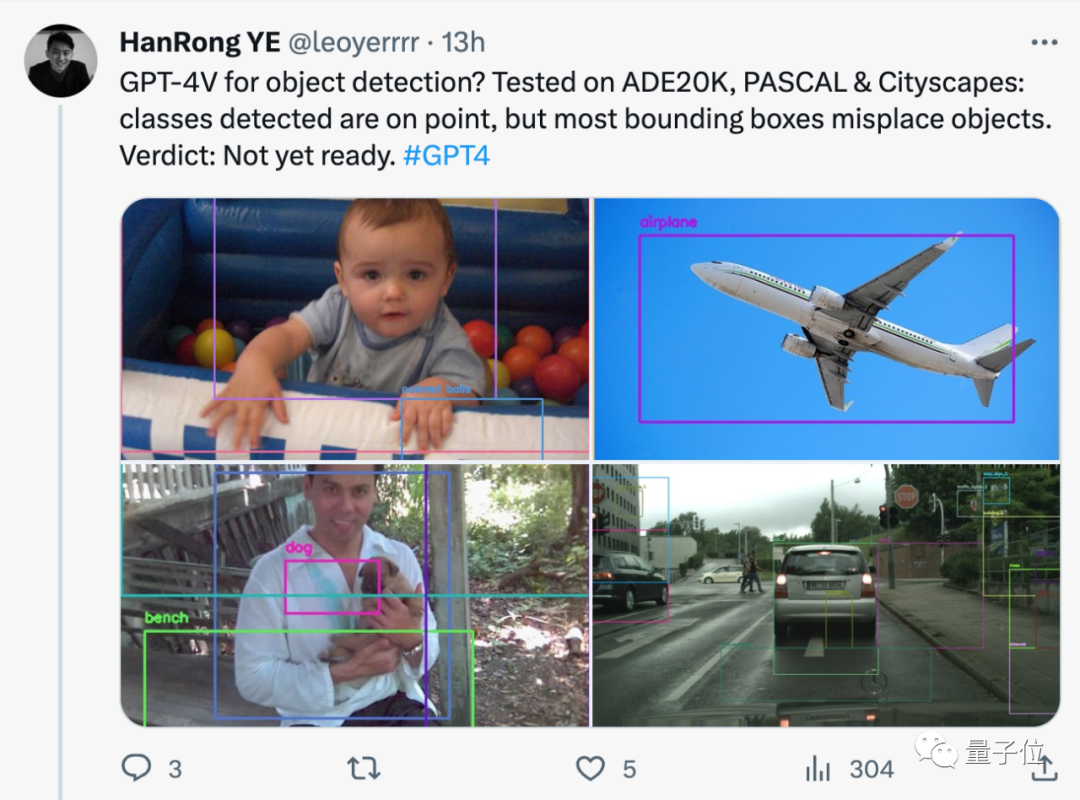
#While the detected categories are fine, most of the bounding boxes are misplaced.
It doesn’t matter, someone will take action!
The Mini GPT-4 that beat GPT-4 in image viewing ability by several months has been upgraded——MiniGPT-v2.
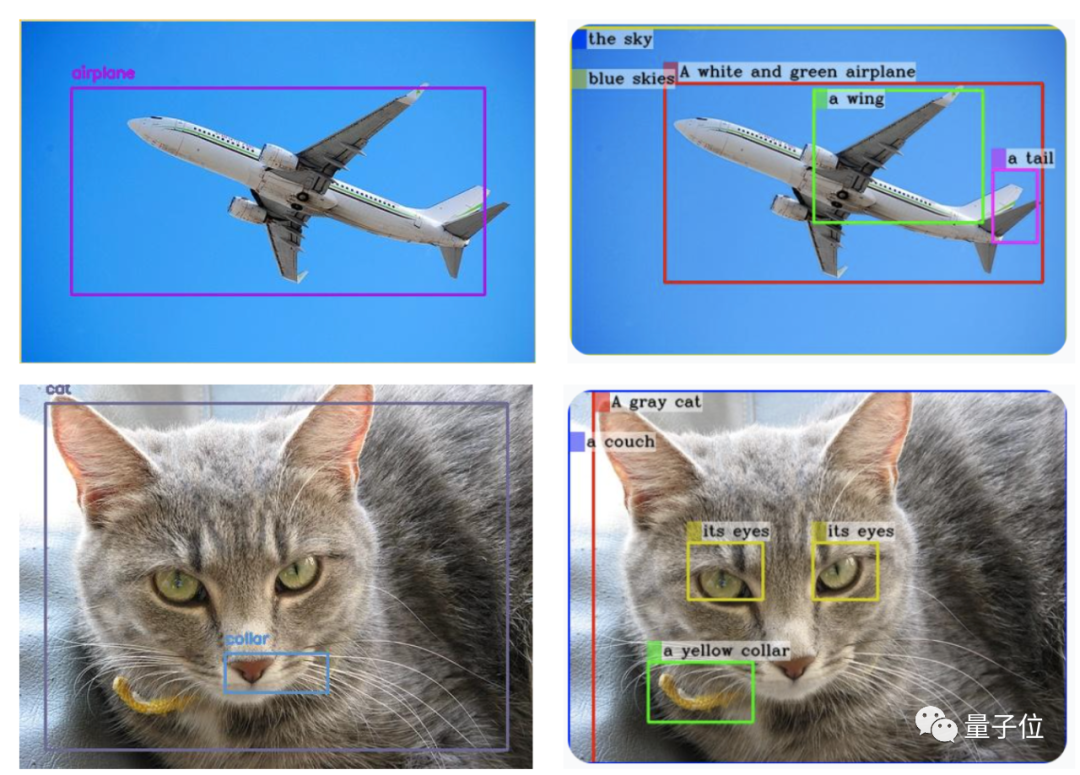
△ (GPT-4V is generated on the left and MiniGPT-v2 is generated on the right)
And it’s just a simple command: [grounding] describe This image in detail is the result achieved.
Not only that, it can also handle various visual tasks easily.
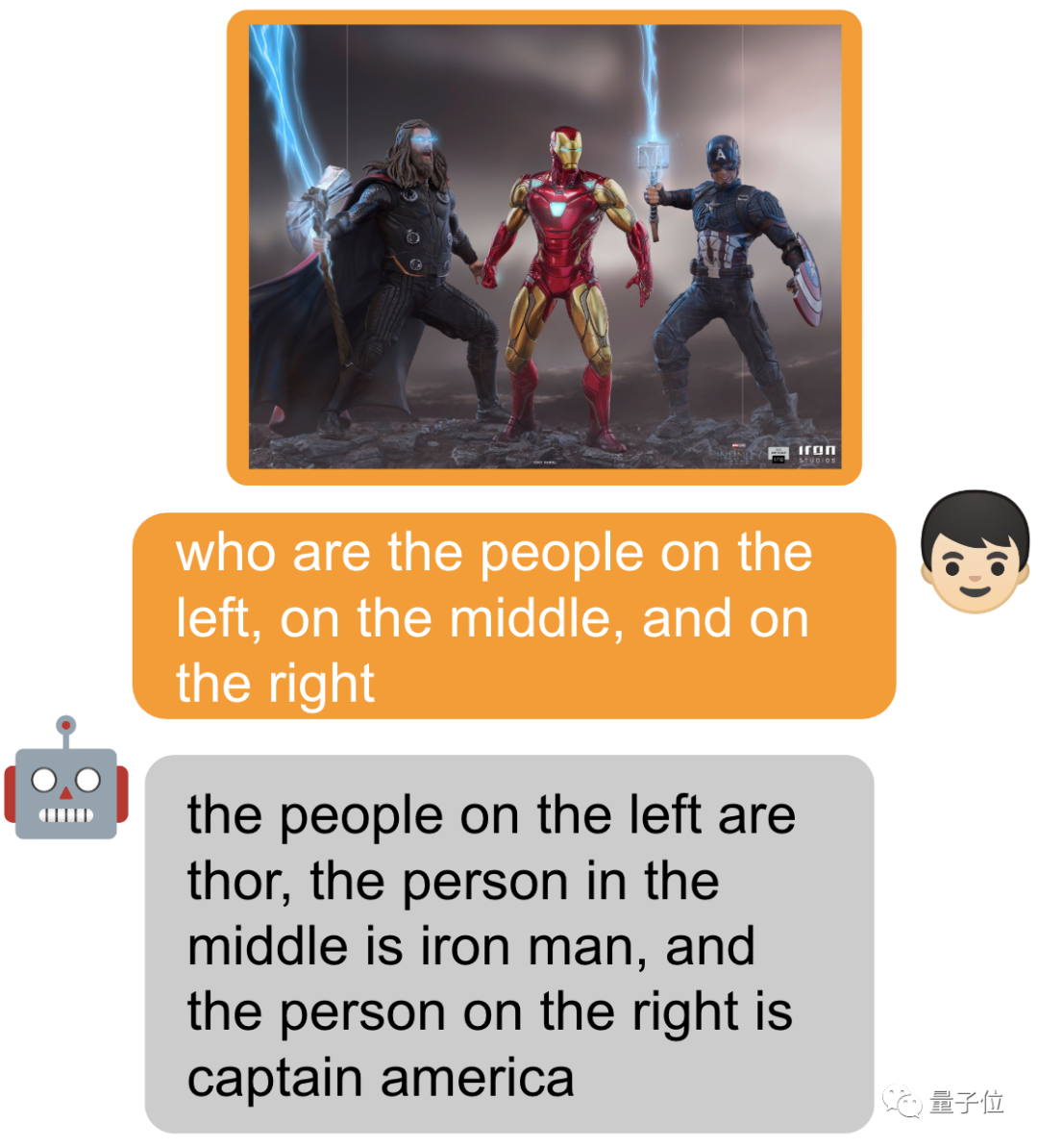
Circle an object and add [identify] in front of the prompt word to allow the model to directly identify the name of the object.

Of course, you can also add nothing and just ask~
MiniGPT-v2 is created by MiniGPT-4 Developed by the original team (KAUST King Abdullah University of Science and Technology) and five researchers from Meta.

Last time MiniGPT-4 attracted huge attention when it came out, and the server was overwhelmed for a while. Now the GitHub project has exceeded 22,000 stars.
With this upgrade, some netizens have already begun to use it~
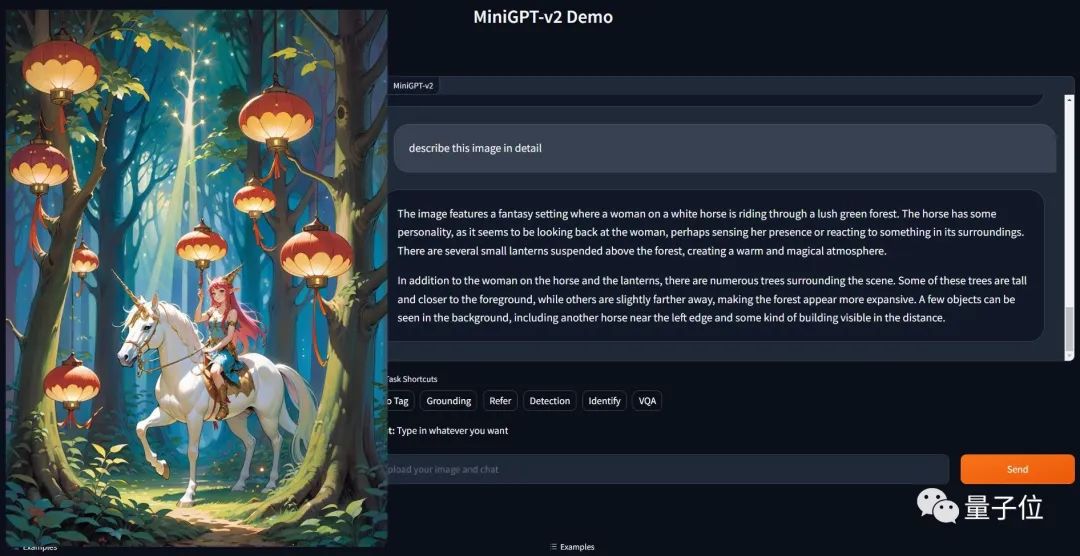
As a common interface for various text applications, large models are already commonplace. Inspired by this, the research team wants to build a unified interface that can be used for a variety of visual tasks, such as image description, visual question answering, etc.

"How to use simple multi-modal instructions to efficiently complete various tasks under the conditions of a single model?" has become a difficult problem that the team needs to solve.
Simply put, MiniGPT-v2 consists of three parts: visual backbone, linear layer and large language model.
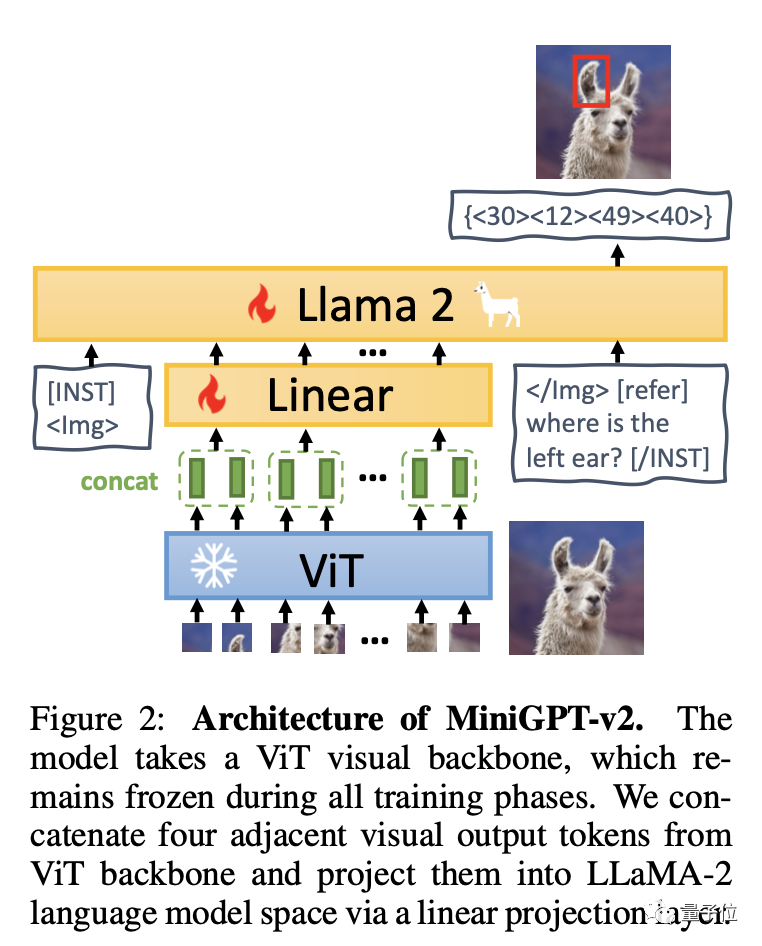
The model is based on the ViT visual backbone and remains unchanged during all training stages. Four adjacent visual output tokens are induced from ViT and projected into the LLaMA-2 language model space through linear layers.
The team recommends using unique identifiers for different tasks in the training model, so that large models can easily distinguish each task instruction and improve the learning efficiency of each task.
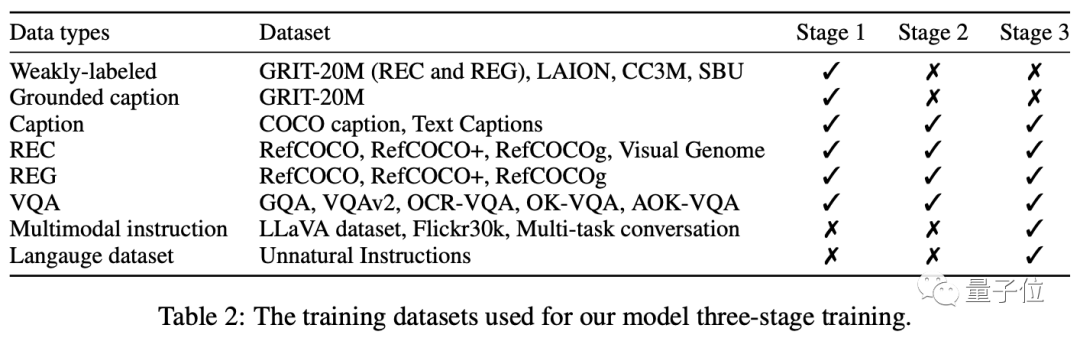
Training is mainly divided into three stages: pre-training - multi-task training - multi-mode instruction adjustment.
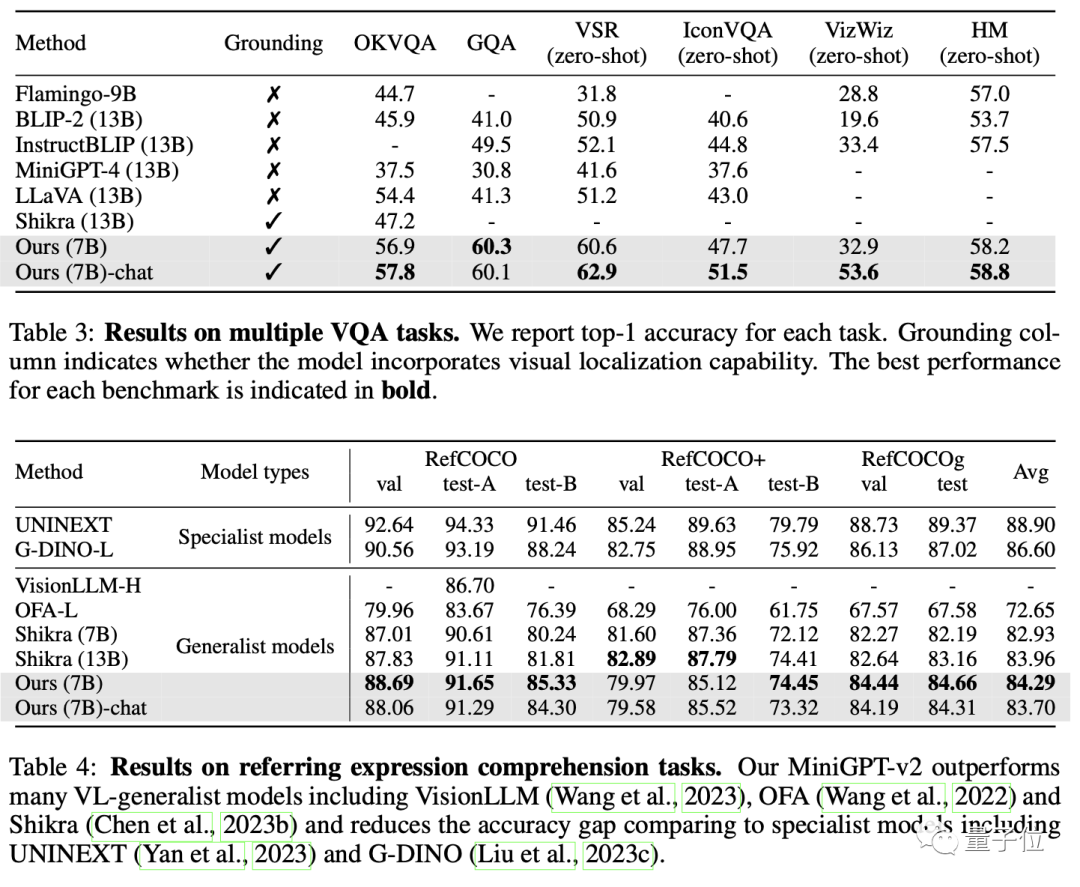
In the end, MiniGPT-v2 outperformed other visual language general models on many visual question answering and visual grounding benchmarks.
Ultimately, this model can complete a variety of visual tasks, such as target object description, visual localization, image description, visual question answering, and direct image parsing from given input text. object.

Interested friends can click on the Demo link below to experience it:
https://minigpt-v2.github.io/
https://huggingface.co/spaces/Vision-CAIR/MiniGPT-v2
Paper link: https://arxiv.org/abs/2310.09478
GitHub link: https://github.com/Vision-CAIR/MiniGPT-4
The above is the detailed content of The super popular mini GPT-4's visual capabilities have skyrocketed, with 20,000 stars on GitHub, produced by a Chinese team. For more information, please follow other related articles on the PHP Chinese website!
 What file is resource?
What file is resource?
 How to set a scheduled shutdown in UOS
How to set a scheduled shutdown in UOS
 Springcloud five major components
Springcloud five major components
 The role of math function in C language
The role of math function in C language
 What does wifi deactivated mean?
What does wifi deactivated mean?
 iPhone 4 jailbreak
iPhone 4 jailbreak
 The difference between arrow functions and ordinary functions
The difference between arrow functions and ordinary functions
 How to skip connecting to the Internet after booting up Windows 11
How to skip connecting to the Internet after booting up Windows 11








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



