


This article is reprinted with the authorization of AI New Media Qubit (public account ID: QbitAI). Please contact the source for reprinting.
Under much attention, GPT4 finally launched vision-related functions today.
This afternoon I quickly tested GPT's image perception capabilities with my friends. Although we had expectations, we were still greatly shocked.
Core point of view:
I think that problems related to semantics in autonomous driving should have been solved well by large models, but the credibility of large models and Spatial perception remains unsatisfactory.
It should be more than enough to solve some so-called corner cases related to efficiency, but it is still very far away to completely rely on large models to complete driving independently and ensure safety.


△GPT4’s description
Accurate Part: 3 trucks were detected, the license plate number of the vehicle in front was basically correct (just ignore the Chinese characters), the weather and environment were correct, accurately identified the unknown obstacles ahead without any prompts.
Inaccurate parts: The position of the third truck is indistinguishable from left to right, and the text above the head of the second truck is a random guess (because of insufficient resolution?).
This is not enough, let’s continue to give a little hint to ask what this object is and whether it can be pressed over.
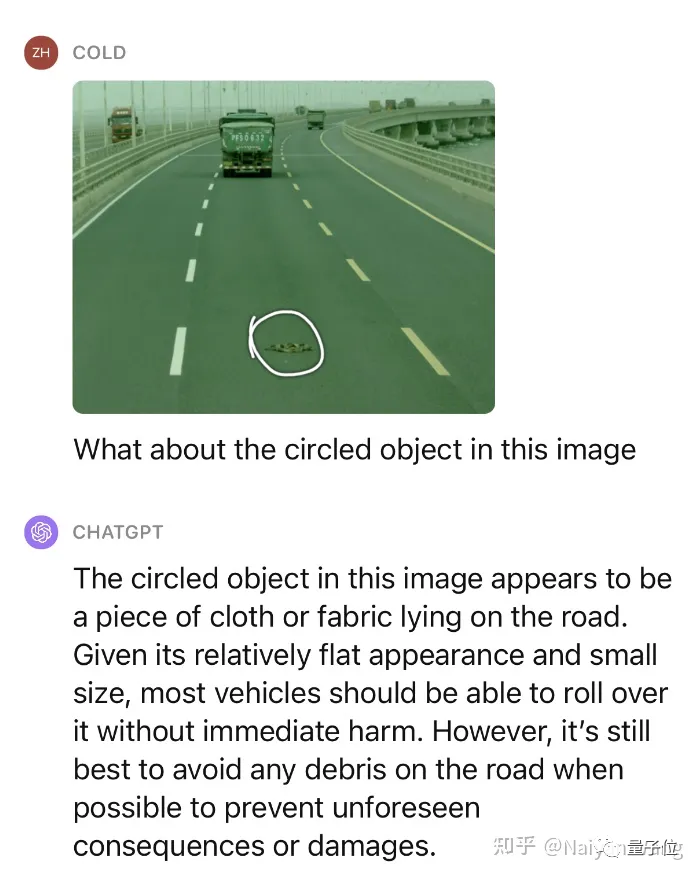
Impressive! We have tested multiple similar scenarios, and the performance on unknown obstacles can be said to be very amazing.
There is no prompt to automatically recognize the sign. This should be basic, let’s continue to give some hints.

I was shocked again. . . He could automatically tell the fog behind the truck and also mentioned the puddle, but once again said the direction was to the left. . . I feel that some prompt engineering may be needed here to better enable GPT to output the position and direction.

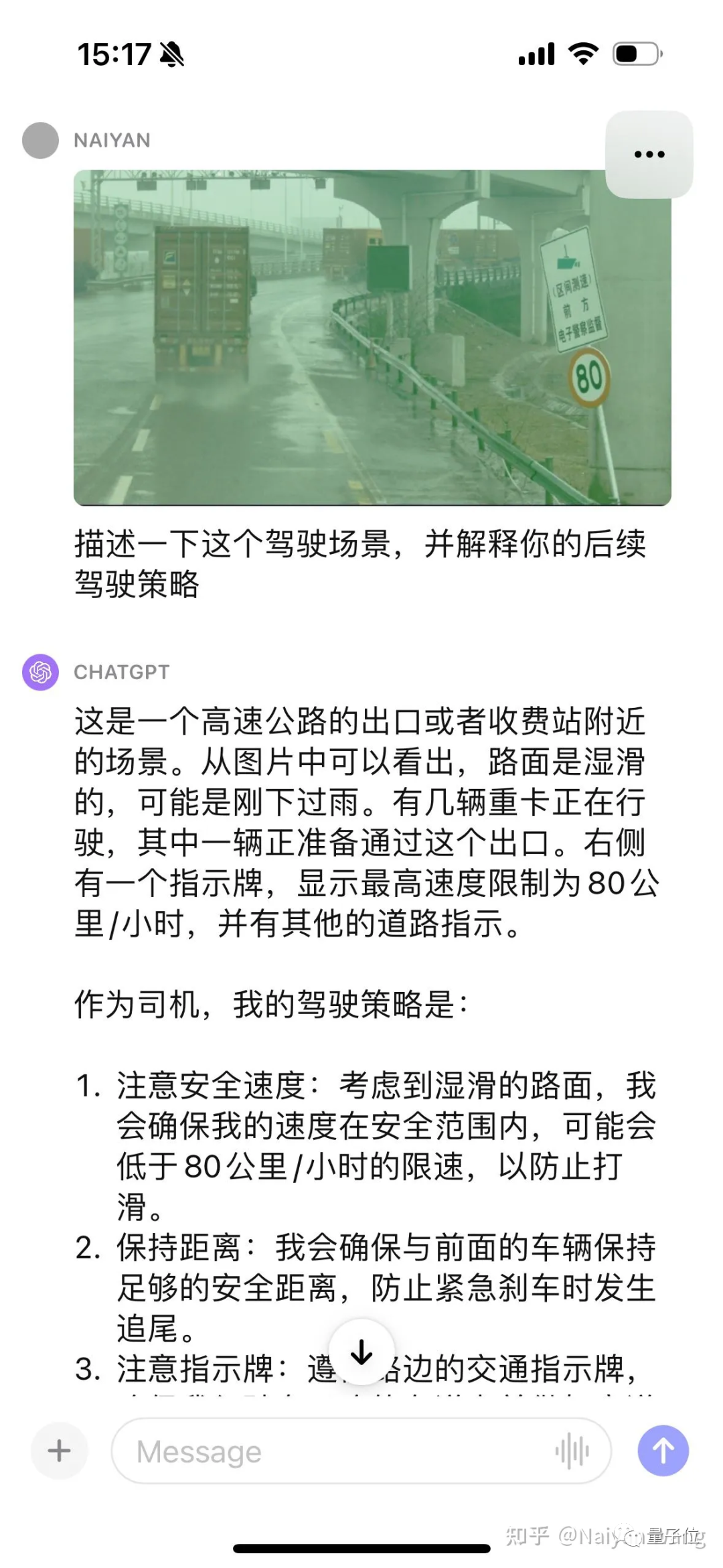
The first frame is input, because there is no timing information, just the truck on the right is regarded as It's docked. So here’s another frame:

You can tell it automatically. This car crashed through the guardrail and hovered at the edge of the road. It’s great. . . But instead the road signs that looked easier were wrong. . . All I can say is that this is a huge model. It will always shock you and you never know when it will make you cry. . . Another frame:

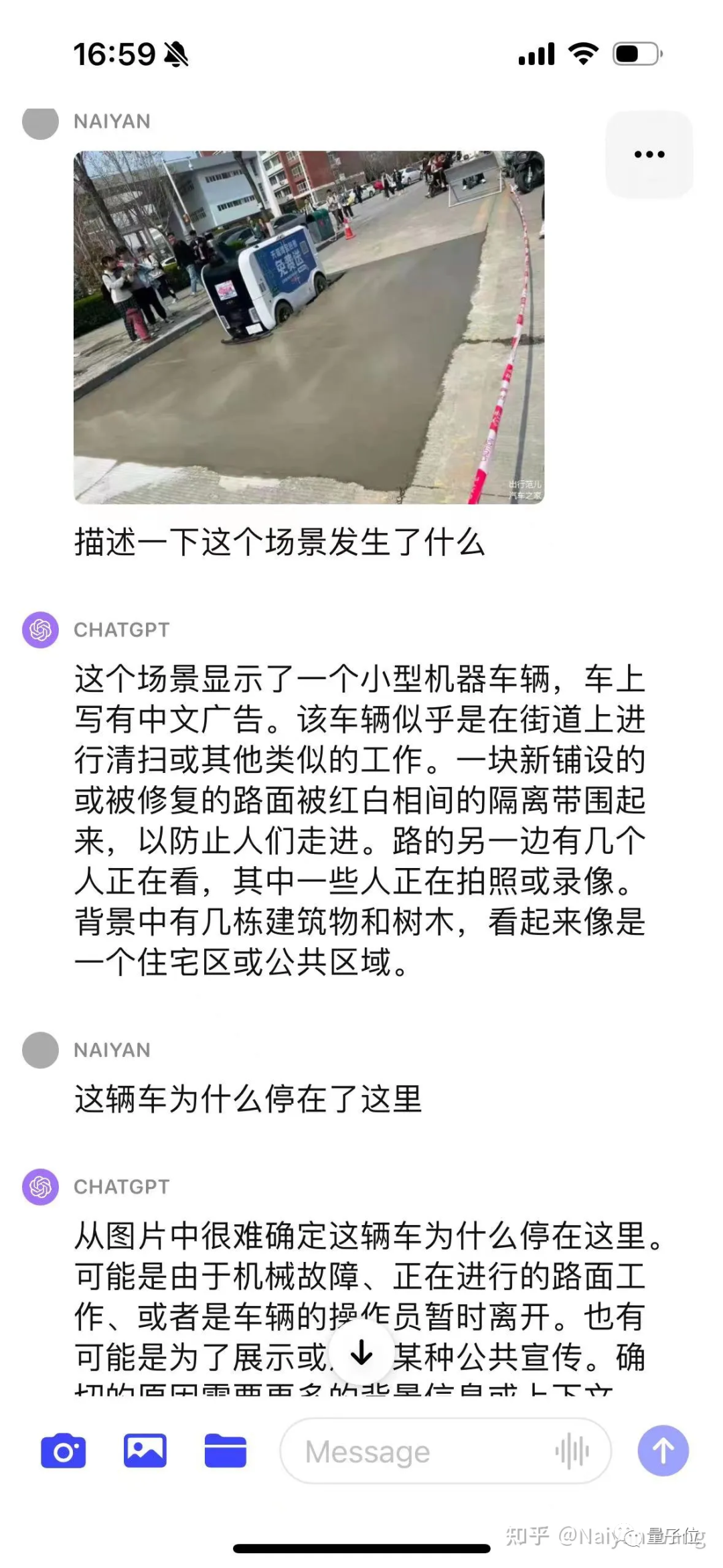
#This time, it talks directly about the debris on the road, and I admire it again. . . But once I named the arrow on the road wrong. . . Generally speaking, the information that requires special attention in this scene is covered. For issues such as road signs, the flaws are not concealed.

It can only be said that it is very accurate. In comparison, the case of "someone waved at you" that seemed extremely difficult before is like pediatrics, and the semantic corner case can be solved.



The above is the detailed content of 'Greatly shocked' a CTO: GPT-4V autonomous driving test for five consecutive times. For more information, please follow other related articles on the PHP Chinese website!
 What skills are needed to work in the PHP industry?
What skills are needed to work in the PHP industry?
 What is the impact of closing port 445?
What is the impact of closing port 445?
 Connected to wifi but unable to access the Internet
Connected to wifi but unable to access the Internet
 What are the commonly used functions of informix?
What are the commonly used functions of informix?
 What does liquidation mean?
What does liquidation mean?
 Today's Toutiao gold coin is equal to 1 yuan
Today's Toutiao gold coin is equal to 1 yuan
 The meaning of title in HTML
The meaning of title in HTML
 cmd command to clean up C drive junk
cmd command to clean up C drive junk








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



