


Large-scale models are making the leap between language and vision, promising to seamlessly understand and generate text and image content. In a series of recent studies, multimodal feature integration is not only a growing trend but has already led to key advances ranging from multimodal conversations to content creation tools. Large language models have demonstrated unparalleled capabilities in text understanding and generation. However, simultaneously generating images with coherent textual narratives is still an area to be developed
Recently, a research team from the University of California, Santa Cruz proposed MiniGPT-5, a method based on Innovative interleaved visual language generation technology based on the concept of "generative vote".

By combining the stable diffusion mechanism with LLM through a special visual token "generative vote", MiniGPT-5 heralds a path for skilled multi-modal generation. a new model. At the same time, the two-stage training method proposed in this article emphasizes the importance of the description-free basic stage, allowing the model to thrive even when data is scarce. The general phase of the method does not require domain-specific annotations, which makes our solution distinct from existing methods. In order to ensure that the generated text and images are harmonious, the double loss strategy of this article comes into play, and the generative vote method and classification method further enhance this effect
On the basis of these techniques , this work marks a transformative approach. By using ViT (Vision Transformer) and Qformer and a large language model, the research team converts multi-modal input into generative votes and seamlessly pairs them with high-resolution Stable Diffusion2.1 to achieve context-aware image generation. This paper combines images as auxiliary input with instruction adjustment methods and pioneers the use of text and image generation losses, thereby expanding the synergy between text and vision
MiniGPT-5 and CLIP Constraints and other models are matched, and the diffusion model is cleverly integrated with MiniGPT-4 to achieve better multi-modal results without relying on domain-specific annotations. Most importantly, our strategy can take advantage of advances in basic models of multimodal visual language and provide a new blueprint for enhancing multimodal generative capabilities.
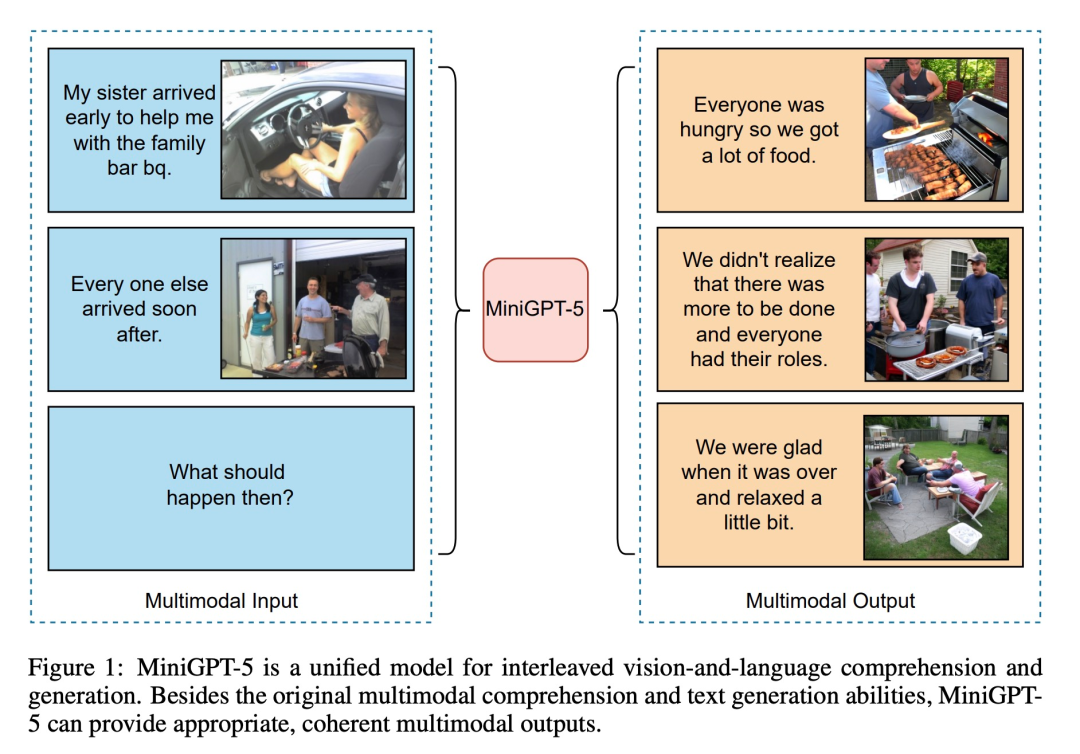
As shown in the figure below, in addition to the original multi-modal understanding and text generation capabilities, MiniGPT5 can also provide reasonable and coherent multi-modal output:
The contribution of this article is reflected in three aspects:
Now, let’s learn more about what this study is about
In order to enable large-scale language models to have multi-modal generation capabilities, researchers introduced a structured framework to integrate pre-trained multi-modal large-scale language models and text-to-image generation models. In order to solve the differences between different model fields, they introduced special visual symbols "generative votes" (generative votes), which can be trained directly on the original images. Additionally, a two-stage training method is advanced, combined with a classifier-free bootstrapping strategy, to further improve the generation quality.
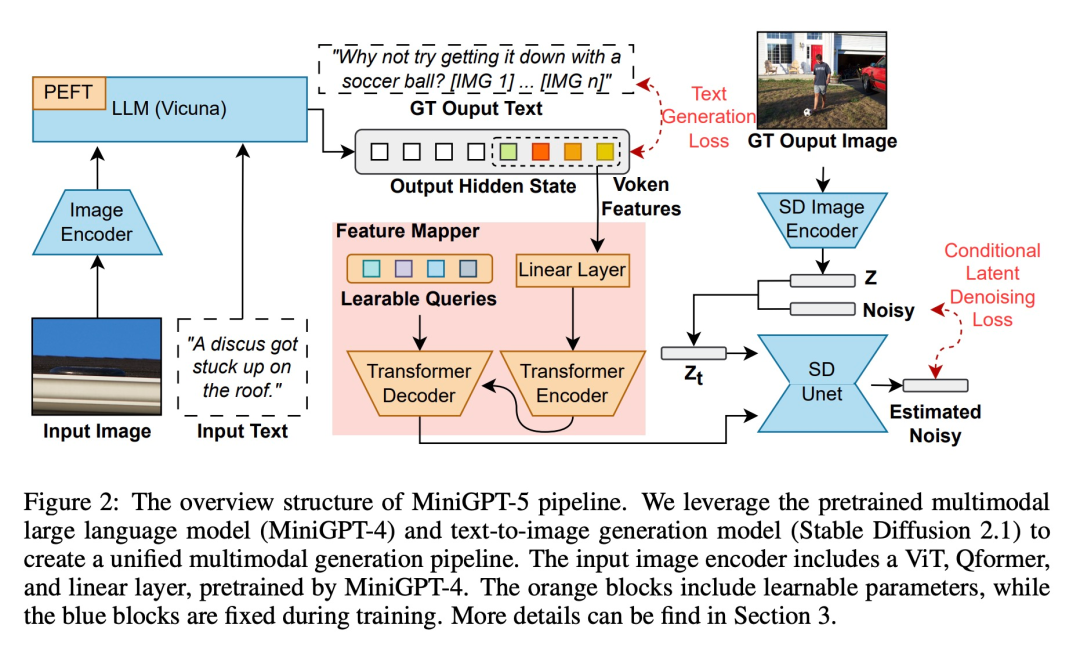
Multimodal input stage
Multimodal large model ( Recent advances such as MiniGPT-4 mainly focus on multi-modal understanding and are able to handle images as continuous input. To extend its functionality to multi-modal generation, researchers introduced generative Vokens specifically designed to output visual features. In addition, they also adopted parameter-efficient fine-tuning techniques within a large language model (LLM) framework for multi-modal output learning
Multi-modal output generation
To ensure that the generative tokens are accurately aligned with the generative model, the researchers developed a compact mapping module for dimension matching and introduced several supervised losses, including text Spatial loss and potential diffusion model loss. The text space loss helps the model accurately learn the location of tokens, while the latent diffusion loss directly aligns tokens with appropriate visual features. Since the features of generative symbols are directly guided by images, this method does not require complete image descriptions and achieves description-free learning
##Training strategy
Given that there is a non-negligible domain shift between the text domain and the image domain, the researchers found that training directly on a limited interleaved text and image dataset may lead to misalignment and Image quality deteriorates.
Therefore, they used two different training strategies to alleviate this problem. The first strategy involves employing classifier-free bootstrapping techniques to improve the effectiveness of generated tokens throughout the diffusion process; the second strategy unfolds in two phases: an initial pre-training phase focusing on rough feature alignment, followed by a fine-tuning phase Working on complex feature learning.
In order to evaluate the effectiveness of the model, the researchers selected multiple benchmarks and conducted a series of evaluations. The purpose of the experiment is to address several key questions:
In order to evaluate the performance of the MiniGPT-5 model at different training stages, we conducted a quantitative analysis, and the results are shown in Figure 3:

To demonstrate the generality and robustness of the proposed model, we evaluated it covering both visual (image-related metrics) and language (text metrics) domains
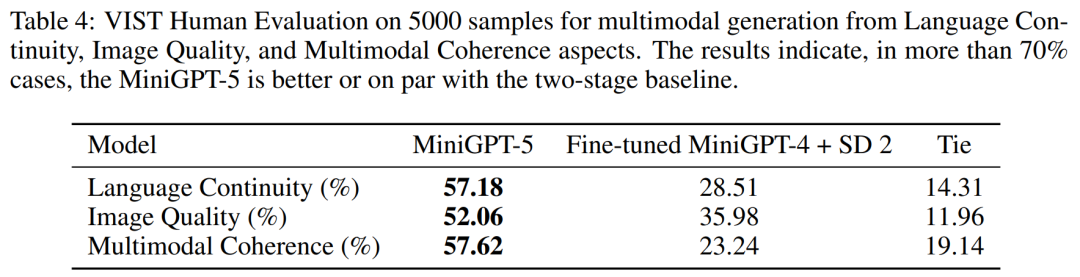
VIST Final-Step Evaluation
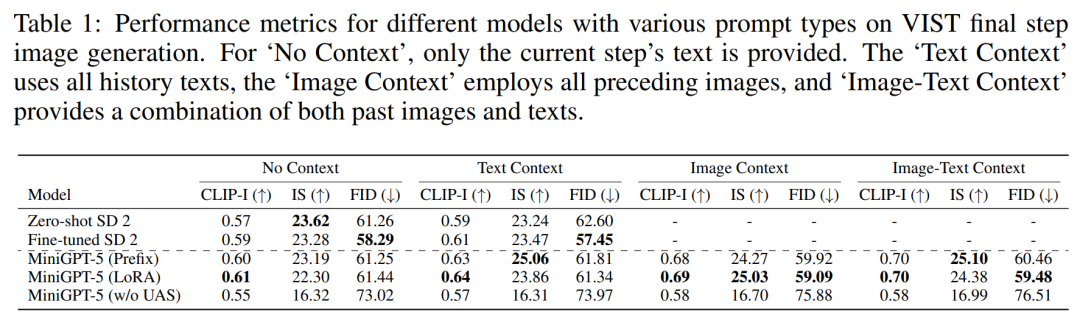
The first set of experiments involves single-step evaluation, i.e. The corresponding image is generated according to the prompt model in the last step, and the results are shown in Table 1.
MiniGPT-5 outperforms the fine-tuned SD 2 in all three settings. Notably, the CLIP score of the MiniGPT-5 (LoRA) model consistently outperforms other variants across multiple prompt types, especially when combining image and text prompts. On the other hand, the FID score highlights the competitiveness of the MiniGPT-5 (Prefix) model, indicating that there may be a trade-off between image embedding quality (reflected by the CLIP score) and image diversity and authenticity (reflected by the FID score). Compared to a model trained directly on VIST without including a single-modality registration stage (MiniGPT-5 w/o UAS), although the model retains the ability to generate meaningful images, image quality and consistency are significantly reduced . This observation highlights the importance of a two-stage training strategy
##VIST Multi-Step Evaluation
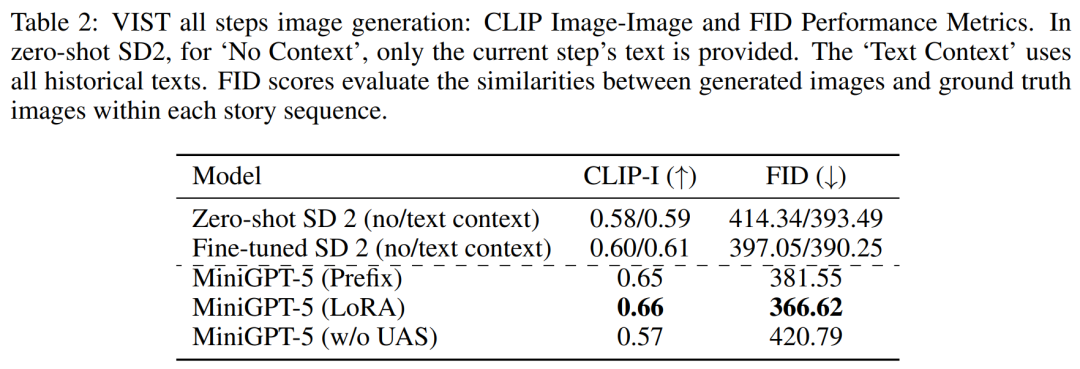
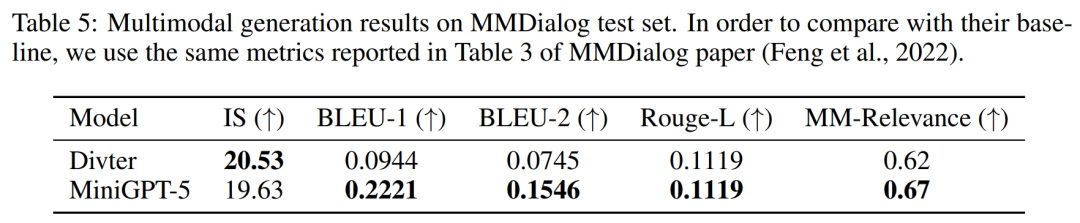
In a more detailed and comprehensive evaluation, the researchers systematically provided the model with prior historical context and subsequently evaluated the generated data at each step. Images and narratives are evaluated.Tables 2 and 3 summarize the results of these experiments, providing an overview of the performance on image and language metrics respectively. Experimental results show that MiniGPT-5 is able to exploit long-level multi-modal input cues to generate coherent, high-quality images across all data without compromising the multi-modal understanding capabilities of the original model. This highlights the effectiveness of MiniGPT-5 in different environments ##VIST Human Evaluation As shown in Table 4, MiniGPT-5 generated updates in 57.18% of the cases. Appropriate text narration provided better image quality in 52.06% of cases and generated more coherent multi-modal output in 57.62% of scenes. Compared with a two-stage baseline that adopts text-to-image prompt narration without subjunctive mood, these data clearly demonstrate its stronger multi-modal generation capabilities. ##MMDialog Multiple rounds of evaluation##According to The results in Table 5 show that MiniGPT-5 is more accurate than the baseline model Divter in generating text replies. Although the generated images are of similar quality, MiniGPT-5 outperforms the baseline model in MM correlations, suggesting that it is better able to learn how to position image generation appropriately and generate highly consistent multi-modal responses

 Let’s take a look at the output of MiniGPT-5 and see how effective it is. Figure 7 below shows the comparison between MiniGPT-5 and the baseline model on the CC3M validation set
Let’s take a look at the output of MiniGPT-5 and see how effective it is. Figure 7 below shows the comparison between MiniGPT-5 and the baseline model on the CC3M validation set Figure 8 below shows Comparison of baseline models between MiniGPT-5 and VIST verification sets
Figure 8 below shows Comparison of baseline models between MiniGPT-5 and VIST verification sets ##Figure 9 below shows the MiniGPT-5 and MMDialog test sets Comparison of baseline models.
##Figure 9 below shows the MiniGPT-5 and MMDialog test sets Comparison of baseline models.  For more research details, please refer to the original paper.
For more research details, please refer to the original paper.
The above is the detailed content of MiniGPT-5, which unifies image and text generation, is here: Token becomes Voken, and the model can not only continue writing, but also automatically add pictures.. For more information, please follow other related articles on the PHP Chinese website!
 How to bind data in dropdownlist
How to bind data in dropdownlist
 Introduction to the method of intercepting strings in js
Introduction to the method of intercepting strings in js
 The difference between console cable and network cable
The difference between console cable and network cable
 Common tools for software testing
Common tools for software testing
 Solution to garbled characters when opening excel
Solution to garbled characters when opening excel
 Two-way data binding principle
Two-way data binding principle
 What to do if the Chinese socket is garbled?
What to do if the Chinese socket is garbled?
 Complete list of CSS color codes
Complete list of CSS color codes








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



