



Currently, self-driving vehicles have been equipped with a variety of information collection sensors, such as lidar, millimeter-wave radar and camera sensors. From the current point of view, a variety of sensors have shown great development prospects in the perception tasks of autonomous driving. For example, the 2D image information collected by the camera captures rich semantic features, and the point cloud data collected by lidar can provide the accurate position information and geometric information of the object for the perception model. By making full use of the information obtained by different sensors, the occurrence of uncertainty factors in the autonomous driving perception process can be reduced, while the detection robustness of the perception model can be improved.
Today’s introduction is an article from Megvii Autonomous driving perception paper, and was selected for this year's ICCV2023 Vision Summit. The main feature of this article is an End-to-End BEV perception algorithm like PETR (it no longer requires the use of NMS post-processing operations to filter redundant perception results). frame), and at the same time additionally uses the point cloud information of lidar to improve the perception performance of the model. It is a very good paper on the direction of autonomous driving perception. The link to the article and the official open source warehouse link are as follows:
Next, we will give an overall introduction to the network structure of the CMT perception model, as shown in the following figure:
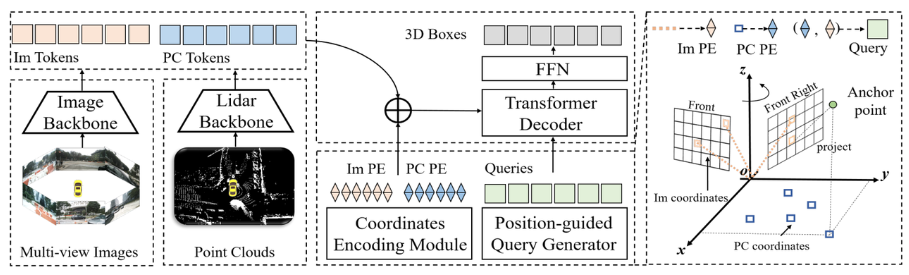
As can be seen from the entire algorithm block diagram, the entire algorithm model mainly consists of three parts
Introduces the overall structure of the network in detail After that, the three sub-parts mentioned above will be introduced in detail
Input: 16 times and 32 times downsampled feature maps output by the 2D Backbone
Output : Fusion of image features downsampled 16 times and 32 times to obtain feature map downsampled 16 times
Tensor([bs * N, 1024, H / 16 , W/16])
Tensor([bs * N, 2048, H/16, W/16])
The content that needs to be rewritten is: tensor ([bs * N, 256, H / 16, W / 16])
Rewrite content: Use ResNet-50 network to extract features of surround images
Output: Output image features downsampled 16 times and 32 times
Input tensor: Tensor([bs * N, 3, H, W])
Output tensor: Tensor([bs * N, 1024, H/16, W/16])
Output tensor: ``Tensor([bs * N, 2048, H/32, W/32])`
The content that needs to be rewritten is: 2D skeleton extraction image features
Neck (CEFPN)
According to the above introduction, the generation of position coding mainly includes three parts, namely image position embedding, point cloud position embedding and query embedding. The following will introduce their generation process one by one
Use the pos2embed() function at the grid coordinate point in the BEV space to embed the two-dimensional horizontal and vertical The coordinate points are transformed into a high-dimensional feature space
# 点云位置编码`bev_pos_embeds`的生成bev_pos_embeds = self.bev_embedding(pos2embed(self.coords_bev.to(device), num_pos_feats=self.hidden_dim))def coords_bev(self):x_size, y_size = (grid_size[0] // downsample_scale,grid_size[1] // downsample_scale)meshgrid = [[0, y_size - 1, y_size], [0, x_size - 1, x_size]]batch_y, batch_x = torch.meshgrid(*[torch.linspace(it[0], it[1], it[2]) for it in meshgrid])batch_x = (batch_x + 0.5) / x_sizebatch_y = (batch_y + 0.5) / y_sizecoord_base = torch.cat([batch_x[None], batch_y[None]], dim=0) # 生成BEV网格.coord_base = coord_base.view(2, -1).transpose(1, 0)return coord_base# shape: (x_size *y_size, 2)def pos2embed(pos, num_pos_feats=256, temperature=10000):scale = 2 * math.pipos = pos * scaledim_t = torch.arange(num_pos_feats, dtype=torch.float32, device=pos.device)dim_t = temperature ** (2 * (dim_t // 2) / num_pos_feats)pos_x = pos[..., 0, None] / dim_tpos_y = pos[..., 1, None] / dim_tpos_x = torch.stack((pos_x[..., 0::2].sin(), pos_x[..., 1::2].cos()), dim=-1).flatten(-2)pos_y = torch.stack((pos_y[..., 0::2].sin(), pos_y[..., 1::2].cos()), dim=-1).flatten(-2)posemb = torch.cat((pos_y, pos_x), dim=-1)return posemb# 将二维的x,y坐标编码成512维的高维向量
by using a multi-layer perceptron (MLP) network Perform spatial transformation to ensure alignment of channel numbers
##Query embedding
bev_query_embeds generation logic
def _bev_query_embed(self, ref_points, img_metas):bev_embeds = self.bev_embedding(pos2embed(ref_points, num_pos_feats=self.hidden_dim))return bev_embeds# (bs, Num, 256)
rv_query_embeds generation logic needs to be rewritten
def _rv_query_embed(self, ref_points, img_metas):pad_h, pad_w = pad_shape# 由归一化坐标点映射回正常的roi range下的3D坐标点ref_points = ref_points * (pc_range[3:] - pc_range[:3]) + pc_range[:3]points = torch.cat([ref_points, ref_points.shape[:-1]], dim=-1)points = bda_mat.inverse().matmul(points)points = points.unsqueeze(1)points = sensor2ego_mats.inverse().matmul(points)points =intrin_mats.matmul(points)proj_points_clone = points.clone() # 选择有效的投影点z_mask = proj_points_clone[..., 2:3, :].detach() > 0proj_points_clone[..., :3, :] = points[..., :3, :] / (points[..., 2:3, :].detach() + z_mask * 1e-6 - (~z_mask) * 1e-6)proj_points_clone = ida_mats.matmul(proj_points_clone)proj_points_clone = proj_points_clone.squeeze(-1)mask = ((proj_points_clone[..., 0] = 0)& (proj_points_clone[..., 1] = 0))mask &= z_mask.view(*mask.shape)coords_d = (1 + torch.arange(depth_num).float() * (pc_range[4] - 1) / depth_num)projback_points = (ida_mats.inverse().matmul(proj_points_clone))projback_points = torch.einsum("bvnc, d -> bvndc", projback_points, coords_d)projback_points = torch.cat([projback_points[..., :3], projback_points.shape[:-1]], dim=-1)projback_points = (sensor2ego_mats.matmul(intrin_mats).matmul(projback_points))projback_points = (bda_mat@ projback_points)projback_points = (projback_points[..., :3] - pc_range[:3]) / (pc_range[3:] - self.pc_range[:3])rv_embeds = self.rv_embedding(projback_points)rv_embeds = (rv_embeds * mask).sum(dim=1)return rv_embedsFirst release the CMT For comparative experiments with other autonomous driving perception algorithms, the author of the paper conducted comparisons on the test and val sets of nuScenes respectively. The experimental results are as follows
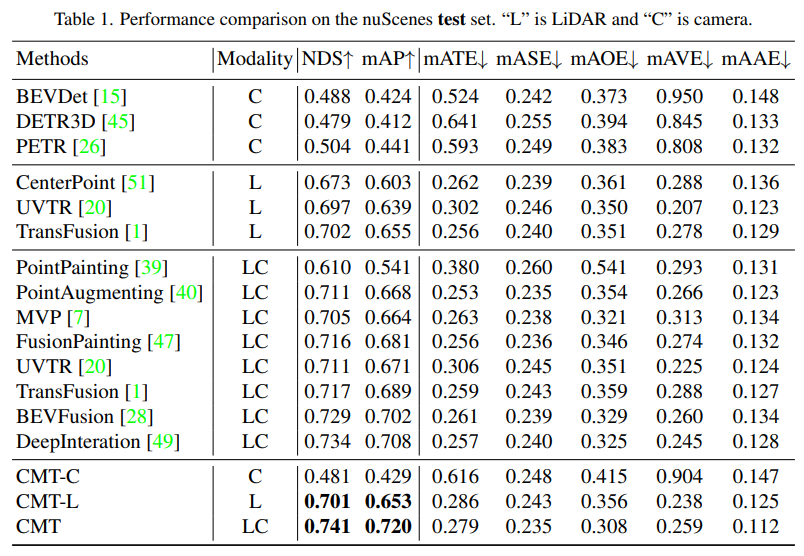
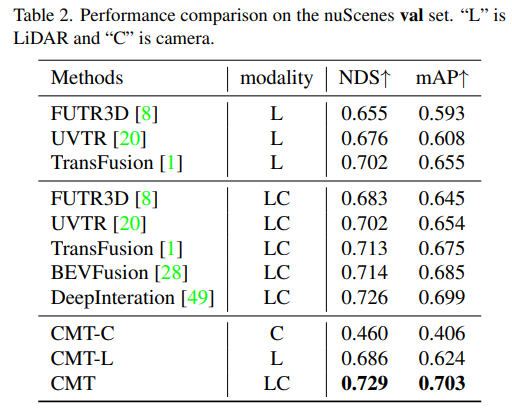
Next is the ablation experiment part of CMT innovation
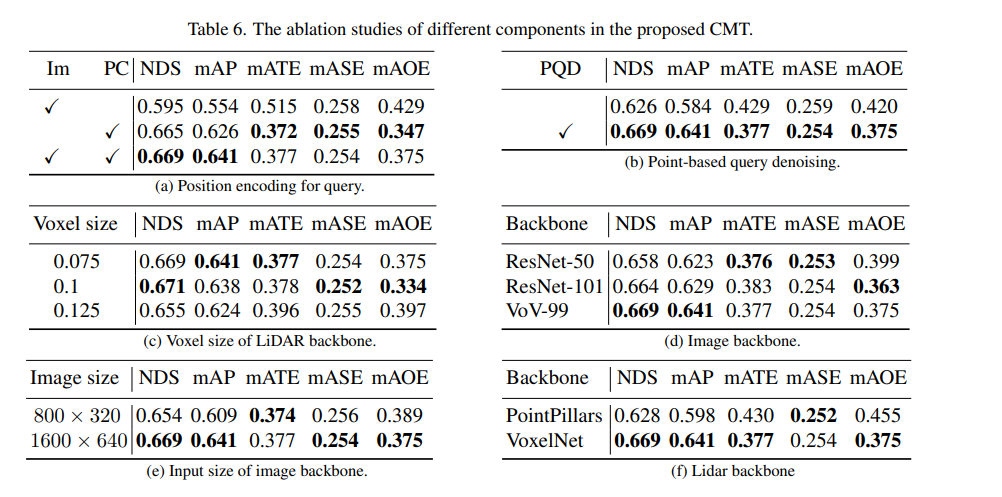
First, we conducted a series of ablation experiments to determine Whether to use positional encoding. Through experimental results, it was found that the NDS and mAP indicators achieve the best results when position encoding of images and lidar is used simultaneously. Next, in parts (c) and (f) of the ablation experiment, we experimented with different types and voxel sizes of the point cloud backbone network. In the ablation experiments in parts (d) and (e), we made different attempts on the type of camera backbone network and the size of the input resolution. The above is just a brief summary of the experimental content. If you want to know more detailed ablation experiments, please refer to the original article
Finally, let’s put a visual display of the CMT perception results on the nuScenes data set. Through the experimental results, you can It can be seen that CMT still has better perception results.

Currently, fusing various modalities together to improve the perceptual performance of the model has become a popular research Orientation (especially on self-driving cars, equipped with multiple sensors). Meanwhile, CMT is a fully end-to-end perception algorithm that requires no additional post-processing steps and achieves state-of-the-art accuracy on the nuScenes dataset. This article introduces this article in detail, I hope it will be helpful to everyone
The content that needs to be rewritten is: Original link: https://mp.weixin.qq.com/s/Fx7dkv8f2ibkfO66-5hEXA
The above is the detailed content of Cross-modal Transformer: for fast and robust 3D object detection. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



